一种双视点图像拼接的静态手势识别方法
2019-05-10杨刘涛
杨刘涛,孙 瑾,张 哲
(南京航空航天大学 民航学院,南京 210016)
1 引 言
随着计算机科学的快速发展,对人机交互技术提出了新的挑战和更高的要求.传统的人机交互方式,如鼠标、键盘和触摸屏等,并非是一种自然的交互方式,所以寻找新的人机交互手段具有重要的意义[1],研究符合人类自然习惯的人机交互技术,尤其是手部交互技术成为国内外关注的热点.
基于手势的人机交互由于操作的灵巧性,更容易提供一种自然、和谐、智能的交互方式,被认为是下一代人机交互的趋势.目前手势交互主要采用接触式测量和非接触式测量两种方式.接触式测量是目前最为成功的人机交互技术,通过在手部安装传感器(例如电磁跟踪器)或者佩戴装有传感器的手套实现手部交互.这种方式一方面价格成本昂贵,更重要的是属于入侵性的交互方法,人的动作容易受到硬件设备的约束,阻碍人手进行自然的肢体动作,在自然性和精度方面受到限制,而且无法提供丰富感知.相比较,基于视觉的手部交互采用非接触式测量技术,具有非侵犯性、代价小、方面使用等优点,使自然和谐的人机交互成为可能.基于视觉的手势的人机交互的关键技术之一是手势识别.但由于图像特征受背景、光照等影响,干扰手部准确定位和识别,且人手由于自遮挡的问题,也会导致姿态识别的歧义性和多样性.手势识别分为静态手势识别与动态手势识别,静态手势识别研究的重点在于手势的姿态和手势的形状[2],于对单帧图像进行信息处理;动态的手势识别则是捕捉一个连贯的手势动作进行识别,包括手型的旋转、形变和运动轨迹[3,4].
近些年来,深度卷积网络在图像识别和分类领域取得了出色的成绩,而基于视觉的静态手势识别在本质上是也属于图像分类问题.本文将深度卷积网络引入静态手势识别中,旨在提高识别精度,克服摄像机视点变化等因素的影响.同时由于人手是典型的链式结构,指节、手掌和关节等各个部位之间必然发生复杂的遮挡和自遮挡关系,导致观测信息缺失.本通过建立双视点手势库,解决自遮挡问题,提高识别率.
2 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN))是一种端到端的学习模型,模型中的参数可以通过传统的梯度下降方法进行训练,经过训练的卷积神经网络能够学习到图像中的特征,并且完成对图像特征的提取和分类[5].
典型的卷积神经网络由输入层、卷积层、激活层、池化层和全连接层,最后在全连接层使用softmax函数输出分类结果.
网络的训练需设置损失函数,使用随机梯度下降法(SGD)等方法来最小化损失函数,通过误差的反向传播以及小批量随机(minibatch stochastic)实现对大批量样本的训练[6].
目前用于图像分类的卷积神经网络主要有AlexNet[7]、VGGNet[8]和GoogLeNet[9]等网络结构,本文方法选用GoogLeNet作为训练的网络结构,主要原因有以下两点:
1)GoogLeNet在传统卷积神经网络结构的基础上提出了Inception 结构.该结构采用不同大小的卷积核,可采集融合不同尺度的特征,同时在3×3和5×5的卷积核之前采用1×1卷积核来进行降维.这样的结构使网络具有稀疏的结构,在增加网络深度的同时,使用较少的连接参数,防止过拟合,加强泛化性能.
2)为了避免梯度消失,网络额外增加了2个辅助的softmax层用于向前传导梯度.这对于深层的网络结构具有很重要的意义,且本文将其用于手势识别,不同手势之间只有细微的差别,所以梯度本身较小,经实验发现,在如VGGNet等深层的网络中,梯度会在传播的过程消失,造成网络的不收敛.
3 双视点图像拼接方法
3.1 建立双视点手势库
建立一个可供网络训练与测试的大批量样本集是使用卷积神经网络进行分类的关键与难点之一.目前主要存在的大型图像库有:COCO[10]、ImageNet[11]、PASCAL[12]和SUN[13]等.这类大型图像库内容覆盖面广,但均没有含有手势细节的库,使其无法在手势识别中应用.文献[14]列出了现有22种手势库,但均为单视点手势库,不适用于本文方法.
人手是典型的链式结构,在单一视点下指节、手掌和关节等各个部位之间必然发生复杂的遮挡和自遮挡关系,导致观测信息缺失.如图1所示,假设在图1(a)的视点下使用摄像

(a)歧义视点下图像 (b)可能的手势种类
图1 自遮挡造成的歧义
Fig.1 Ambiguous gestures caused by self-occlusion
机采集手部图像,由于该视点下手的自遮挡造成了信息缺失、产生歧义,图1(b)中的各种手势都会采集到相同的图像,所以直接采用图1(a)视点图像进行识别时极易发生误判.此时就需要引入另一个视点,结合两个视点的信息来消除歧义,提高识别精度.
前述介绍的单视点手势识别样本库无法满足本文的双视点识别的需求.为此本文使用poser 8中的手部模型建立主视图C1,俯视图C2两个视点下的手势库.通过对手部模型进行三个方向的转动,对同一手势建立多幅特征图.依据人手可转动范围,如图2所示,设定X轴、Z轴转动角度在[-90°,90°],Y轴转动范围[-180°,90°],每次转动20°,每种手势有880种姿态展现.为验证本文方法对相似手势的识别能力,该手势库设置20种常见手势,如图4所示.其中包含多种相似手势,如1和6、2和7,以验证本文方法在自遮挡情况下对他们的识别能力.

图2 手模型的转动轴Fig.2 Axis of hand model
3.2 双视点手势的拼接
目前的卷积神经网络结构,单张的图像可视为一个三维张量D(i,j,k),其中i为红、绿、蓝三颜色通道索引,j、k为图像每个像素的空间索引.而在网络训练时则批量输入图像,则可视为增加一维图像样本索引s,即一个四维张量D(i,j,k,s).

图3 手势图像库中20种手势Fig.3 20 kinds of gesture in the dataset
在卷积层使用卷积核对上一层的数据进行卷积运算[6],如公式(1)所示:
(1)
公式(1)中,D′l,j,k为卷积的输出结果,代表在通道l上,位于第j行、第k列的像素值.Di,j+m-1,k+n-1为颜色通道i上,位于第j+m-1行、第k+n-1列的像素值.kl,i,m,n为卷积核K的元素.
由公式(1)可知,网络在进行卷积时,样本的空间位置及颜色通道由卷积核K的参数建立相互连接,但在网络计算过程中,每幅图像之间(即s通道)是相互独立的.而双视点的手势图像库中,每一个手势对应两个视点下的手势图像,若将两个视点下的图像分别输入同一网络,则无法建立两个视点间的连接关系.

由于poser 8中摄像机和手的相对位置固定,常规拼接方法会造成手势图像的大小与位置相对固定,而在对真实手势图像进行采集时,由于手的运动造成摄像机相对位置不固定,真实手的图像大小和位置与样本库有很大差异,这会造成训练后的网络即使能够正确识别模型手,但在识别真实手时出现很大误差,网络出现过拟合,泛化能力差.为模拟真实手势样本中手部图像位置与大小的变化,增强网络的泛化能力,本文提出以下拼接方法:
1)手势库中的手势图像大小为490×500,为了使拼接后图像不出现拉伸变形,首先设置宽高比为1:2的矩形窗口.如图4所示,由于手势1在手势库所有手势中,手相对于整张图像的占比最大,手的宽度为140,为此裁剪基准矩形窗口宽度应大于140,以保证窗口包含完整手势图像;由于宽高比为1:2,为保证窗口高度不超出图像范围,窗口宽度应小于250.设置窗口宽度在140~250之间随机取值(即窗口大小在图4中介于实线窗口与虚线窗口之间),140为图像中手势的宽度,用该矩形窗口遍历整个图像,并计算每一步窗口内的像素和S,如公式(2)所示:
(2)
其中I(i,j)为原始图像第i行、第j列的灰度值,由于手势样本为RGB图像,需先将该图像转换为灰度图后再计算(此处将手势样本转化为灰度图仅是用于确定矩形窗口位置,最终剪切后的样本仍为RGB图像);(k,l)为矩形窗口左上顶点的位置;width为矩形窗口宽度.

图4 遍历图像的窗口大小设置Fig.4 Size of window
2)由于背景为黑色,灰度值为0,当S值为最大时,窗口包含了整个手部图像.分别选取两个视点中使S最大的矩形窗口位置(k,l).此处矩形窗口位置(k,l)不唯一,(k,l)值不同时,手在窗口中的相对位置也不同.随机选取其中一个(k,l),剪切该窗口位置的图像.
3)对两个视点下图像分别按照步骤2的方法进行剪切,最后将拼接图像的大小缩放为统一的大小,本文实验中使用GoogLeNet,所以缩放到其输入层的图像大小为224×224,拼接流程如图5所示.由于矩形窗口大小和窗口左上顶点位置(k,l)的随机选取,手的大小和位置也具有随机性,以此来模拟手与摄像机相对位置的变化、消除样本大小和位置过于固定带来的过拟合问题.
4)对每个样本进行两次上述步骤1至步骤3的操作,由于取值的随机性,每次操作都会有不同的图像,实现对手势库的进一步扩充.
按照上述步骤完成双视点手势的拼接后,每种手势1760张手势图,20种手势共35200个样本,将手势库分为训练集与测试集(测试集与训练集的划分方式将在4.1与4.2中详细说明),使用训练集训练GoogLeNet,使用测试集测试其分类的准确率.

图5 手势样本剪切拼接流程Fig.5 Process to cut and stitch gesture
4 实验与结论
本文使用python 2.7与Berkeley AI Research 发布的Caffe[15](Convolutional Architecture for Fast Feature Embedding)构建GoogLeNet网络模型,在CPU为Intel(R) Xeon(TM) E5-2609 v4 1.70GHz,内存32.00 GB,GPU为NVIDIA 1070Ti的PC机上进行训练.训练时使用带动量的随机梯度下降法,以加速训练,参照GoogLeNet[9]中的参数设置,动量值定为0.9;经多次实验,基础学习率为0.0001时,网络收敛效果最佳,并在迭代次数为70000次左右时,损失函数不再明显下降,所以选取学习率为0.0001,最大迭代次数为70000次.
4.1 单视点和双视点下识别精度对比
为验证本文方法对自遮挡手势的识别能力,我们分别用单视点手势库和本文的双视点方法训练网络.在实验时,共设置两个测试集,测试集1挑选每种手势中信息基本完整、自遮挡现象不明显的姿态加入测试集,包含4400个样本;测试集2则挑选4400个存在自遮挡的手势样本.其余26400个样本为训练集,即训练集占总样本数的3/4.
在使用训练集对网络完成训练后,用两个测试集分别测试C1、C2视点与双视点下的识别精度.测试结果如图6所示.由图6可知,使用测试集1进行测试时,本文方法对各类手势的识别精度达到97%以上,均高于单视点下;在使用测试集2时,由于自遮挡导致的信息不足,两种方法识别精度都有所下降,但相比于单视点,使用本文方法识别精度得到了大幅提高.其中,第6类与第8类手势的识别精度明显下降,此两种手势识别错误的图像如图7所示,由于第6类与第8类手势即使在双视点下,也会大量出现自遮挡的情况,图像本身的信息不足导致了识别精度下降,若继续增加视点,补充信息,就能提高识别率.同时,本文方法以图像拼接来融合多视点信息,增加视点并不会增加网络复杂程度与计算量.

图6 使用不同测试集的20种手势识别精度对比Fig.6 Accuracy comparison using different test sets
4.2 真实手部识别实验
为验证本文方法的泛化能力,使用与4.1相同的训练集训练,使用真实手图像进行测试,使用样本如图8所示,分类结果如图9,其纵坐标为网络最后一个softmax层的输出,表示分类的概率,当某一类概率最大时,则将该样本识别为此类,由于输出中大部分结果数值很小,为能比较这些值的差异,对其取对数后绘图.图9对本文方法和传统拼接方法进行了对比,并标记出了分类概率最大的点.可以看出使用传统拼接方法对样本1和样本4的分类出现了错误,而本文方法对图中手势都得出了正确的分类.由此可见两种方法在泛化能力上的差异: 真实手势图像进行采集时,由于手的运动造成摄像机相对位置不固定,真实手的图像大小和位置与传统拼接方法的样本库有很大差异,在对真实手势图像进行识别时会出现很大误差;而本文拼接方法在建库时,对手势大小和位置两个量进行随机取值,模拟真实手势图像,使得本文方法有更好的泛化能力.

图7 识别错误的手势图像示例Fig.7 Examples of images that fail to be recognized

图8 真实手的双视点样本Fig.8 Real-hand simples
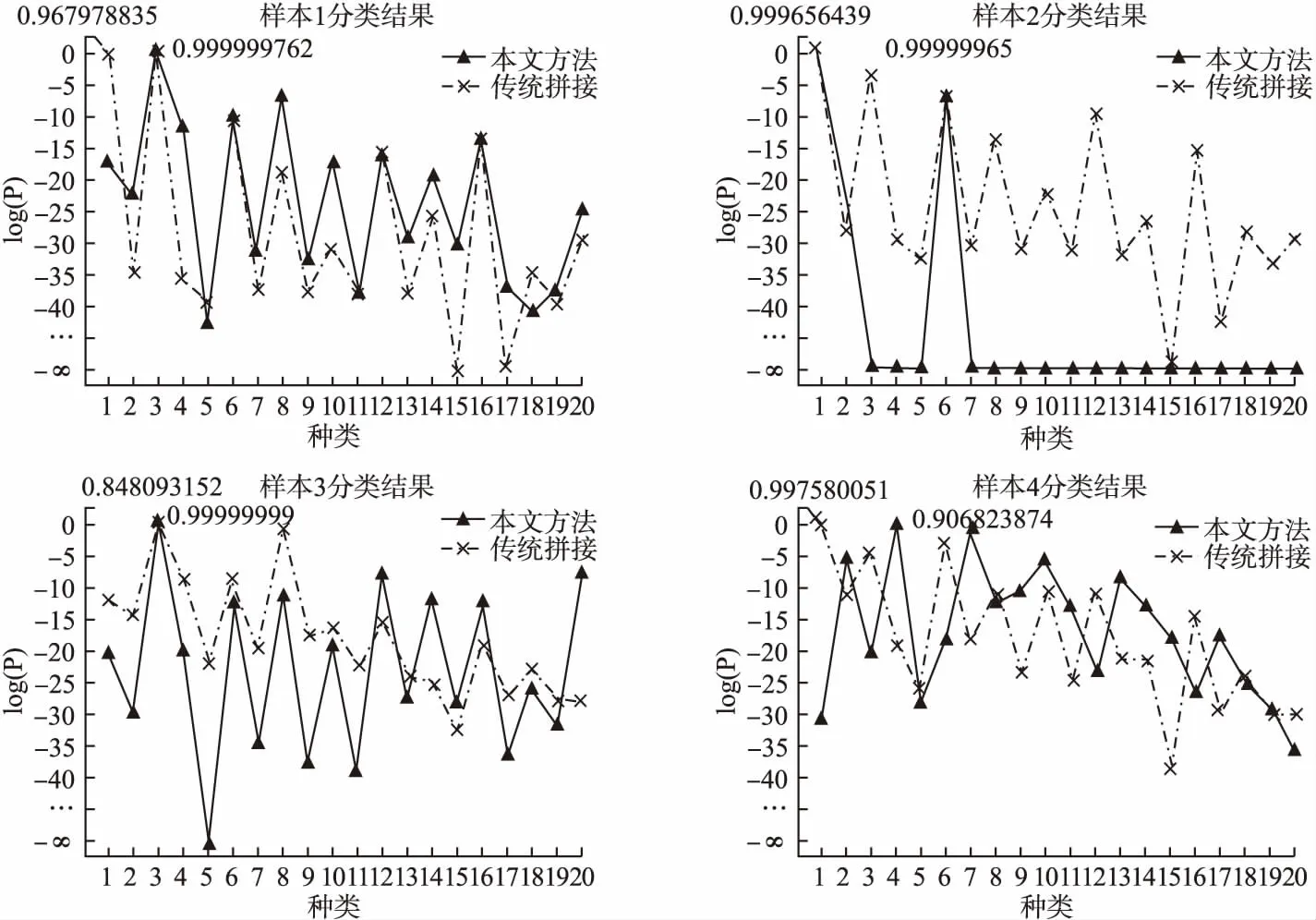
图9 真实手的分类结果Fig.9 Results of real-hand image classification
5 结 语
手势识别技术是实现基于手势的人机交互的关键技术之一.但人手的结构复杂,会出现手势的自遮挡,引起信息丢失.同时,近年来卷积神经网络在图像分类识别方面有出色的表现,本文将该方法引入静态手势识别之中.首先利用poser 8建立手势库,并针对卷积神经网络的单通道结构,对双视点下的手势图像提出新的剪切拼接方法,使用 GoogLeNet进行训练,并对训练完成的网络进行实验,验证了本文方法对自遮挡手势的识别能力和泛化能力.
