挖掘数据模式结构信息的混合数据分类方法
2019-05-082
2
(1.常州轻工职业技术学院 信息工程学院, 江苏 常州 213164;2.江南大学 数字媒体学院, 江苏 无锡 214122)
0 引言
数据分类通过训练带有标签信息的样本生成分类模型以预测未标记样本的归属类别,是模式识别、机器学习、数据挖掘及统计学等领域最基本、最重要的问题之一。传统的数据分类方法,如支持向量机(Support Vector Machine, SVM)[1-3]、随机森林(Random Forest, RF)[4]、k近邻算法(k-Nearest Neighbor, kNN)[5]、决策树(C4.5)[6]以及朴素贝叶斯(Naive Bayesian, NB)[7]等,在训练阶段利用数据的物理特征(如距离、相似性等)构建数据分类模型,在分类阶段,通过确定测试样本与所建立数据分类模型之间的相似性预测测试样本的真实标签类型。在大多数情况下,传统的分类方法仅仅依靠数据之间的距离、相似度等物理特征信息构建数据分类模型,事实上,实际数据集中的每个数据并不是孤立的,数据之间存在关联,数据整体上都会呈现一定的模式结构,而且数据模式结构中蕴含着丰富的数据关联信息[8-10]。Thiago等[11]提出一种基于网络的高层次数据分类方法,该方法在建立的复杂网络中通过挖掘数据相互间的关联信息探索网络的同质性、聚集系数以及度等网络属性捕捉隐藏的数据拓扑结构信息,将数据拓扑结构信息与数据物理特征相结合形成一种智能分类方法;Sun等[12]针对传统推荐系统并未考虑社交网络中各个用户之间的关系,提出社交正则化方法整合用户间的朋友等社交关系;Jiang等[13]研究时尚、建筑及漫画等不同数据模式,针对现有大部分风格分类方法从数据局部模式中提取的鉴别特征过于多样化导致较差的分类性能,提出赋予不同特征相应权重的一致风格聚集自动编码策略学习鲁棒数据风格特征表示。
图1展示了传统分类方法用于实际数据分类过程中存在的不足。假设有一数据集包含三类数据A、B及C,运用传统分类技术对这三类数据进行训练并构建数据分类模型。当向已建好的数据分类器输入测试样本A1-t时(图1(b)),由于传统分类方法仅仅利用数据物理特征信息构建数据分类器,从颜色特征角度看,测试样本A1-t与B1、C1样本有着相同的颜色特征,它们之间有着极高的相似度,此时A1-t将被归为红色一类而不能获得真实的标签类型A。如果在构建数据分类器的过程中还考虑到训练样本之间的模式结构关系,如从整体的角度看,A1、A2、A3它们都是圆,共同组成圆类A,它们之间的关联比较密切。将样本之间的关联信息用于数据分类模型的建立,构建的数据分类器将会正确地对测试样本A1-t进行分类。因此,将各种经典的分类技术用于实际数据分类时除了应考虑数据物理特征外还应有效地结合数据间的关联等这样一层模式结构关系,充分利用模式结构关系中数据间的关联作用信息,这样才能符合实际状况下数据分类并保证优越分类性能。
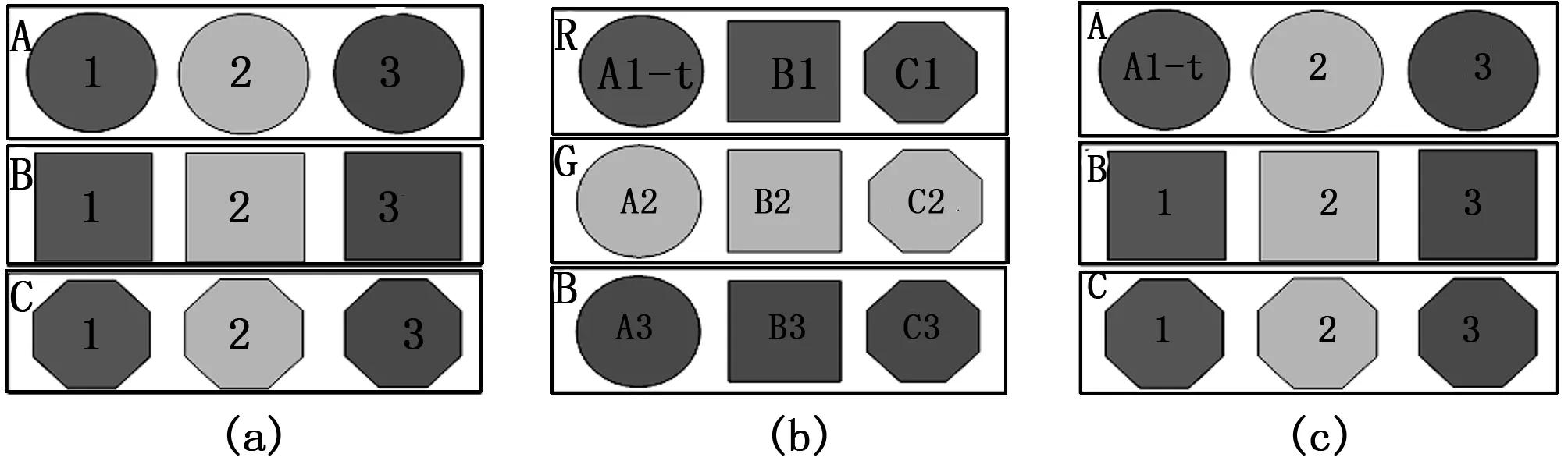
图1 传统分类方法的分类过程
本文将仅仅利用数据物理特征信息的传统分类技术作为普通分类方法,将挖掘并采用数据关联信息的分类技术作为高级分类方法,基于这两种类型的分类方法,针对数据间相互关联的事实,提出一种挖掘数据模式结构信息的混合数据分类方法(HDCM)。HDCM将输入的训练样本映射成复杂网络,在复杂网络中挖掘数据模式结构信息(网络节点效率、影响力)用于构建高级分类方法。使用任意一种传统分类方法以及高级分类方法分别计算测试样本对所有数据类型的隶属度,利用模糊分类技术将测试样本归为具有最大隶属度的数据类中,从而实现数据分类。由于HDCM考虑了数据关联信息,数据分类的泛化性能也有了明显提高。
1 高级分类模型描述
本文所提的数据分类模型由传统分类方法和高级分类方法混合而成,这里主要介绍构建高级分类模型的基础工作,包括构建k近邻复杂网络、确定有别于数据物理特征的数据模式结构特征:网络节点与子网络的效率以及节点影响力。
1.1 复杂网络
在建立复杂网络用于数据分类的所有方法中,基于k近邻算法的复杂网络是最常使用的方法[8,11,14],且能够方便、简单地表达数据之间的关联,其过程可描述如下:对于输入的整个训练集X={x1,x2,…,xN}中某一样本xi,xi∈Rd,选取与其距离最小的前k个样本xj,这里的距离为欧氏距离。如果样本xi与样本xj有相同标签,即Lxi=Lxj,则样本xi可关联于样本xj,记为xi→xj,对应于复杂网络则可建立节点i到节点j的有向边eij,节点i为有向边eij的起始点,节点j为有向边eij的结束点。赋予复杂网络中不同有向边相应权重ωij,使得当节点间的距离越小时权重ωij越大,权重ωij定义如下:
(1)
其中:ωij取值范围为(0,1),N为复杂网络所有节点数,即训练样本总数,dij为节点i与节点j之间的距离。
当输入的数据集包含L类数据,即C={c1,c2,…,cL},由利用k近邻算法建立复杂网络的过程可知,建立的复杂网络包含L个子网络,即CN={cn1,cn2,…,cnL},且子网络之间无关联,网络中每个节点i与样本xi相对应。
1.2 模式结构效率特征
除了颜色、距离等物理特征信息外,数据的模式结构关系中蕴含着丰富的数据关联信息[15-17],应该挖掘并将数据关联信息用于数据分类。如上述描述传统方法分类的例子中(图1),如果仅依据颜色可将数据分为红、绿、蓝三类,建立的分类模型将不能正确分类测试样本A1-t,若进一步考虑数据间的关联作用,可将数据分为圆、正方形、正六边形三类,按照2.1节可建立圆之间的连接、正方形之间的连接以及正六边形之间的连接三个子网络组成复杂网络,从而建立的分类模型可使得测试样本A1-t获得真实标签类型。赋予复杂网络中每个节点效率概念以区别网络中的其他节点,建立数据模式结构关系中的网络效率特征。社交网络中最常采用PageRank方法[18-19]计算网络节点的声誉,其基本思想是网络中某个节点连接其他节点数越多,说明该节点声誉越高;网络中其他节点连接某个节点越多,说明该节点声誉越高,本文复杂网络的节点效率计算方法正是源于PageRank方法。为了充分考虑节点之间的关联作用,对于复杂网络中节点i的效率定义如下:
(2)

(3)
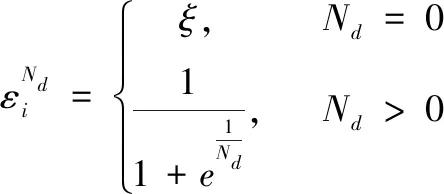
(4)
(5)
其中:Ni代表以节点i为起始点的有向边个数,Nk代表以节点i为结束点的有向边个数,Nd代表节点i与其他节点相关联的有向边个数,即Nd=Ni+Nk,ξ为一较小值,赋予离群点或噪声点较小的效率,其对于分类样本所起的作用可忽略不计。
当计算出复杂网络每个节点效率后,与训练集每一类数据相对应的子网络cnl效率便可确定,子网络效率定义如下:
(6)
其中:φcnl代表与训练集第cl类数据相对应的子网络cnl的效率,Ncnl为子网络cnl包含的节点个数。复杂网络中节点及子网络的效率为基于挖掘数据模式结构信息的高级分类模型预测测试样本标签提供可靠依据,2.4节将有详细内容介绍。
1.3 模式结构影响力特征
在利用数据模式结构信息建立高级分类模型的过程中,训练集中的每个数据样本对分类未标记测试样本所起的作用大小各不相同,有的数据样本对预测结果可能起决定性作用,有的数据样本影响力可能很弱[18-19]。这里定义复杂网络节点影响力如下:
(7)
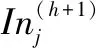
公式(7)中1/N表示训练样本是均匀分布的,而大多情况下实际数据集中的数据并不是均匀分布,每一个数据样本在一定距离范围内被不同个数的其他数据样本所包围[21],类似的,复杂网络中的节点在一定距离范围内被不同个数的其他节点所包围,由此产生节点在整个网络中的浓度概念。复杂网络中第i个节点浓度定义为:
(8)
其中:dc代表截断距离,可根据实际的数据分类效果手动确定,或者使节点在dc距离范围内被占复杂网络节点总数3%~5%的其他节点包围[21],当dij-dc<0时χ(·)=1,否则χ(·)=0。在复杂网络中以传播节点浓度的方式计算每个节点在整个网络中的真实影响力大小,定义如下:
(9)
当满足以下迭代条件时计算节点真实影响力的迭代过程将会停止。
(10)
其中:θ的取值可根据实际数据集分类的效果手动选取,根据大量的实验结果表明θ=10-4即可。
1.4 高级分类技术
经典的数据分类技术利用数据间的距离、相似性等物理特征实现数据分类,典型的方法如SVM及其改进方法。但是,实际数据集数据样本之间总会存在关联,当将数据集映射成复杂网络时这样的关联便显而易见,整体上数据样本具有一定的模式结构关系,并不是数据越靠近哪一类,它的标签就与该类相同,还应考虑数据的模式结构信息来确定数据的真实标签类型[8,22]。本文结合复杂网络在数据分类方面存在的优势,充分挖掘并利用蕴含在模式结构关系中的数据关联信息实现高级分类技术,定义如下:
(11)
其中:εcnl代表子网络cnl的效率,dtj为测试样本t与节点j间的欧氏距离,γ为平衡系数,用于平衡数据物理特征和数据模式结构关系之间的作用,γ越大则说明数据模式结构关系作用越大,反之则说明数据物理特征作用越大。
当输入一个未标记测试样本时,高级分类技术将依据Λt,j确定未标记测试样本与每个子网络的连接集,定义如下:
Ωcnl={j|j∈cnl&Λt,j>0}
(12)
两种情况可将子网络cnl中的节点j加入到连接集Ωcnl中:1)当测试样本与子网络cnl中节点j的Λt,j大于0时将节点j加入连接集Ωcnl中;2)当测试样本与每个子网络cnl中节点的Λt,j都小于0时,则将与最接近于0的Λt,j对应的节点j加入到连接集Ωcnl中。高级分类模型将依据测试样本与子网络连接集影响力之和来判断测试样本标签类别,最大连接集影响力之和定义如下:
(13)
高级分类模型将未标记测试样本归为与具有最大影响力之和的连接集所对应的类别中。
如图2所示演示了高级分类方法的详细分类过程。针对第2节高级分类模型的描述可知,高级分类方法涉及3个参数,即k近邻算法中的参数k,截断距离dc以及平衡系数γ。图2中3个参数分别设置为k=2、dc=3及γ=0.3。图2(a)为利用k近邻算法建立的复杂网络,包含两个独立的子网络:“■”类,标签为0;“·”类,标签为1。图2(b)展示了节点的属性内容:部分节点之间的欧氏距离(如d12=0.81)及节点的度(如deg2=3),可用于计算节点的效率。图2(c)为利用公式(2) ~ (5)计算出的节点效率(如ε1=1.76)及利用公式(6)计算出的子网络效率(如“■”类:φ0=1.57)。图2(d)展示了复杂网络中每个节点的影响力(如In1=0.60);根据公式(11)可建立测试样本(“▲”)与每个子网络的连接集,如图2(e)所示。最终将测试样本归入到与具有最大连接集节点影响力之和对应的类中,如图2(f)所示预测测试样本的标签类型为0。

图2 高级分类方法分类示例
2 混合数据分类方法
本文混合数据分类方法由普通分类方法和高级分类方法混合而成,一方面,普通分类方法(如SVM、RF及kNN等)依据数据的物理特征(如距离、相似性等)训练数据分类模型并预测测试样本的标签类型;另一方面,高级分类方法首先根据数据之间的关联作用将训练样本映射成复杂网络,在复杂网络中挖掘节点(每一个节点与数据样本相对应)的模式结构特征:节点及子网络效率和节点影响力,当输入一个测试样本时,根据高级分类技术(式(11))建立测试样本与每个子网络的连接集,最终将测试样本归为与具有最大影响力之和的连接集相对应的类中。所提混合分类模型定义如下:
(14)
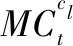
(15)

(16)

本文混合数据分类方法一方面能够在建立的复杂网络中探索并挖掘数据模式结构信息用于数据训练与分类;另一方面由公式(11)可知,从数据物理特征的角度,当一个测试样本的物理特征(如距离)与训练样本中的任何一类数据都不相似时,高级分类方法将起主要作用,从数据模式结构关系的角度,当一个测试样本的结构并不遵从训练样本中任何一类数据的结构关系时,普通分类方法将起主要作用。
3 实验与结果
为了验证所提混合数据分类方法的分类性能及其有效性,实验采用对比的方式将该方法与模糊SVM[1]、模糊C4.5[6]、加权的kNN[23]、模糊分类方法0-阶TSK及1-阶TSK[24-25]分别在人造数据集以及UCI真实数据集上进行实验,通过实验结果与分析突出所提混合分类方法与传统分类方法的区别。其中,SVM采用线性及高斯两种核类型的算法,为了公平起见,所有对比算法涉及的参数均采用网格搜索结合交叉验证的方法进行确定。所有对比算法均在Matlab软件平台上实现程序编写并在配置有处理器为Intel(R) Core(TM) i3-3240、CPU主频为3.40 GHz、内存大小为4.00 G、操作系统为windows 7 ultimate system的台式电脑上进行仿真。
3.1 高级分类方法
为了详细地了解所提高级分类方法的分类性能,组织5组高斯数据集实验,如图3所示,每组高斯数据集包含3类数据,具有各自的数据模式结构,3类数据分别被标记为“·”类、“■”类及“▲”类,类之间有不同程度的交叉重叠,如图3(e)所示的高斯数据集中3类数据的交叉程度已达到80%,根据我们的知识和经验,这对于传统分类技术是一项十分具有挑战性的分类任务。
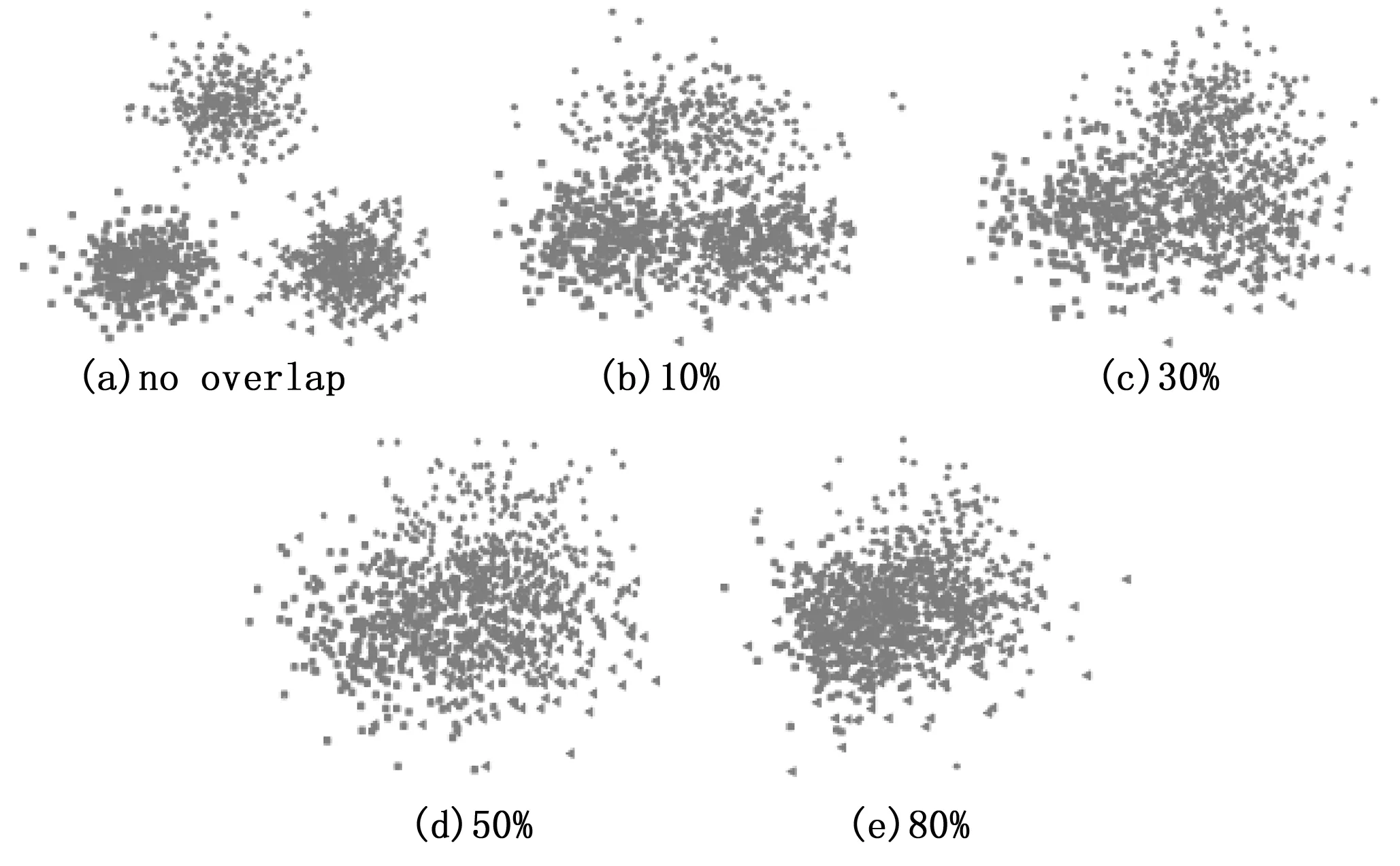
图3 5组高斯数据集
图4分别展示了利用高级分类技术对5组高斯数据集不同参数组合下的数据分类结果,其中,k的取值范围为[1,15][11],截断距离dc使得复杂网络中每个节点被周围占节点总数3%~5%的其他节点包围[21],取值范围为[0.01,0.1],设定平衡系数γ的取值范围为[0.1,1.5]。图中“Acc”代表分类精度,颜色条从下至上代表分类精度越来越高,所有实验结果均为运行程序10次后取得的平均结果。由图4实验结果可知,随着数据交叉程度的增加,数据分类精度逐渐降低,当数据交叉程度达到80%,由于能够挖掘并利用数据模式结构信息,所提高级分类方法依然能够取得较高的分类精度(如图4(e)所示的最高分类精度为70%),充分彰显了所提高级分类方法鲁棒的分类性能。

图4 5组高斯数据集不同参数组合下的分类结果
3.2 人造数据集仿真
挖掘并将数据模式结构信息用于数据分类的HDCM通过混合传统分类方法和高级分类方法两种类型的分类技术来弥补传统分类方法仅仅采用数据物理特征进行模型训练及分类的缺陷。HDCM包含的两种不同类型分类技术在数据分类过程中所起的作用不同,如图5所示,当数据之间关联紧密,数据具有典型的模式结构时(蓝色“■”类),HDCM在分类过程中将以高级分类方法为主导,即公式(14)中参数λ的取值偏大。这里将通过图5所示的数据集具体地演示参数λ如何平衡HDCM中两种不同类型分类器对数据分类所起的作用。图5所示的数据集“·”类包含500个样本,“■”类包含的样本数为40,实验中选取广泛使用的SVM作为比较算法[1],算法相关参数设置如下:对于线性SVM,惩罚系数C=28;高斯型SVM中惩罚系数C=28,核宽度σ=2-3;混合分类方法中截断距离dc=1,参数k=5以及公式(11)中平衡系数γ=0.1。表1记录了参数λ取不同值时采用不同分类方法计算的测试样本(“▲”)对于数据集中不同类数据的隶属度,其中,普通分类方法对应Blue列,HDCM对应Red列。

图5 HDCM的解释性示例
由图5可知,“·”类的样本数明显多于“■”类,且测试样本距离“·”类较近,如果使用传统分类方法,测试样本将被错误地归入到“·”类,即属于“·”类的模糊隶属度较大,如表1中当λ=0。随着λ值逐渐变大,混合分类方法中传统分类方法的作用逐渐减弱,由于“■”类数据呈现明显的模式结构,且HDCM能够有效地挖掘数据之间的关联作用信息并用于数据分类,因此,HDCM能够精确地预测测试样本的真实标签类型。结合图5和表1可知,当使用某种分类方法进行分类时,测试样本并不一定属于距离它较近的数据类,还应该考虑数据之间的关联。

表1 不同λ值对分类的影响
挖掘数据模式结构信息的混合数据分类方法在考虑数据物理特征的基础上,还通过构建复杂网络并探索数据的模式结构,并将数据模式结构信息用于数据分类。这里利用三组人造数据集来验证HDCM的数据分类性能。三组人造数据集分别为Circles、Moons以及Rectangle,如图6所示,Circles中三类包含的样本数分别为2001、1001及601;Moons中两类包含的样本数分别为1001、501;Rectangle中两类包含的样本数分别为500、1000。每组数据集中的数据呈现明显的模式结构,分别为圆、月牙形以及长方形,不同数据类之间有重复交叉且包含不平衡样本数,即一类包含的样本数明显多于另一类,如Moons中左类样本数为1001,而右类样本数只有501,这样的数据集对于传统分类方法具有一定挑战性。

图6 三组人造数据集
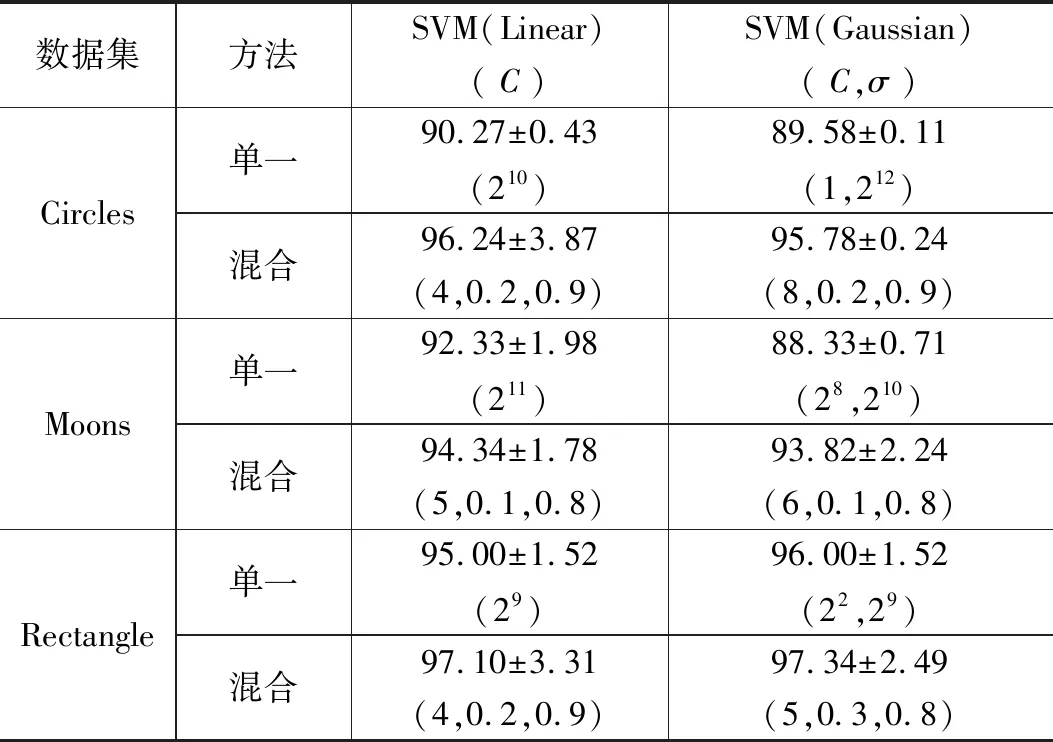
数据集方法SVM(Linear)(C)SVM(Gaussian)(C,σ)Circles单一90.27±0.43(210)89.58±0.11(1,212)混合96.24±3.87(4,0.2,0.9)95.78±0.24(8,0.2,0.9)Moons单一92.33±1.98(211)88.33±0.71(28,210)混合94.34±1.78(5,0.1,0.8)93.82±2.24(6,0.1,0.8)Rectangle单一95.00±1.52(29)96.00±1.52(22,29)混合97.10±3.31(4,0.2,0.9)97.34±2.49(5,0.3,0.8)
实验中,对于每一组人造数据集,随机选取样本总数的80%作为训练样本,其余作为测试样本。仍然选取最为经典的分类方法SVM作为比较方法,这里使用模糊SVM方法[1]。针对Circles、Moons以及Rectangle,HDCM中截断距离dc大小具体设置为0.7、0.1及0.2,算法涉及最优参数经网格搜索结合5折交叉验证的方法获得,具体参数设置如表2所示。实验所得数据为运行程序5次后的平均结果。
表2列出了所有对比算法在人造数据集上的详细数据分类结果,其中,“单一”表示只使用某一种传统方法进行数据分类,“混合”表示使用本文HDCM进行数据分类,分类精度及其标准差、算法最优参数分别表示为**±**(**)。
由于图6三组人造数据集中的数据之间关联紧密,数据整体上呈现典型的模式结构,即使在发生明显数据重叠的情况下,使用本文所提的混合数据分类技术取得的分类结果普遍优于传统分类方法。人造数据集上的实验结果表明HDCM能够有效地挖掘数据之间的关联信息,也正因为将数据模式结构信息用于分类模型的训练及数据分类,使得HDCM具备良好的数据分类性能。
3.3 真实数据集仿真
除了人造数据集仿真实验,本文还将HDCM在UCI真实数据集[26]上进行实验,观察所提混合分类方法的实际分类性能。UCI真实数据集的详细介绍如表3所示,其中,数据集中的样本数范围为178 ~ 4174,最大和最小的数据特征维数分别为3、18,数据集包含的类别数最小为2,最大为28。综上所述,所选取的真实数据集配置符合验证HDCM实际分类性能的需求。
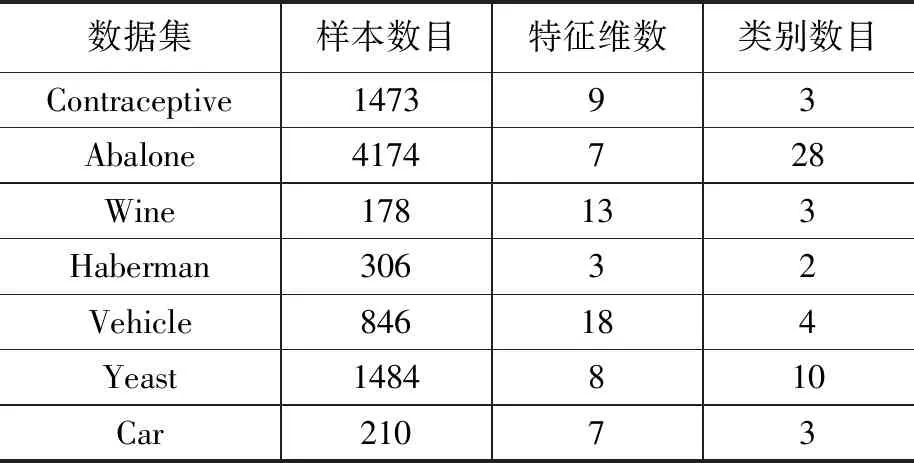
表3 UCI真实数据集
实验中,对于每一组真实数据集,随机选取样本总数的80%作为训练样本,其余当作测试样本。所有对比算法参数设置作如下介绍:HDCM算法共涉及四个参数,即高级分类方法中的k、dc、γ以及混合分类技术中用于平衡数据物理特征与模式结构关系特征作用的系数λ。由于截断距离dc使得复杂网络中的节点被占节点总数3%~5%的其他节点包围,这里主要设置参数k、γ及λ。根据大量的实验结果,k、γ及λ的取值可分别在{1,2,…,14,15}、{0.1,0.2,…,2.9,3}以及{0,0.1,…,0.9,1}范围内进行搜索,另外,针对参数dc,表1中的真实数据集从上往下分别设置为3.3、0.08、2.9、4.1、0.6、0.2以及0.8。线性SVM中的惩罚系数C取值范围为{2-3,2-2,…,211,212},高斯型SVM的性能除了与惩罚系数C相关外,还与核宽度σ的设置有关,其取值范围为{2-3,2-2,…,211,212}。加权的k近邻算法中参数k的设置与HDCM相同,其分类结果主要取决于测试样本与其所有近邻的加权之和,这里的权值大小为测试样本与其近邻之间欧氏距离的倒数。经典模糊分类方法TSK的数据分类性能主要与模糊规则数R及正则化参数τ相关,实验中这两个参数的取值搜索范围分别设置为{5,10,…,195,200}及{10-5,10-4,…,104,105}。模糊C4.5[6]及对比算法的其他参数均采用默认设置。实验中的算法最优参数均由网格搜索结合5折的交叉验证方法确定,实验数据为运行程序15次后取得的平均结果,分类精度及其标准差、算法最优参数分别表示为**±**(**)。表4给出的混合分类方法最优参数为(k,γ,λ),“-” 代表参数的取值为空,表明HDCM中高级分类方法对分类结果未起作用。另外,为了探讨高级分类方法的实际分类性能,表4最后一列给出在UCI真实数据集上单一使用高级分类方法的分类效果,“---”表示无需使用HDCM进行分类。
如表4所示,通过对比算法在UCI真实数据集上的实验结果可得出以下几点分析:1)当传统分类方法与HDCM所取得的数据分类结果一致时,在混合分类技术分类过程中传统分类方法将起主导作用,HDCM可智能地弱化高级分类方法的作用,即公式(14)中的参数λ=0,如高斯型SVM对于数据集Vehicle、加权的kNN对于数据集Contraceptive等;2)当传统分类方法在真实数据集上所取得的分类精度较低时,公式(14)中参数λ的值将等于或接近1,HDCM中的高级分类方法将对预测测试样本的标签类型起决定性作用,如线性SVM对于数据集Abalone、加权的kNN对于数据集Contraceptive、模糊C4.5对于数据集Abalone等;3)对于每一组真实数据集,混合分类方法都给出了不同的γ值,表明数据集中数据之间的确存在关联作用信息,且所提方法能够有效挖掘并利用这些不同于数据物理特征的数据信息来提高传统分类方法的分类性能;4)当单一使用高级分类方法时,通过与普通分类方法相比较,高级分类方法表现出了具有竞争力的分类性能,表明挖掘并使用数据模式结构信息确实能够有助于改善分类方法的性能。
表5给出了两种典型的传统分类器与所提分类技术在数据集Wine、Contraceptive以及Haberman上的算法运行时间对比。由表2结合表4可知HDCM分类精度均高于普

表5 算法运行时间分析
通分类方法,但由于所提混合数据分类方法结合普通分类方法与高级分类方法,因此,从算法复杂度角度,HDCM并不占明显优势。
3.4 工业应用案例
本文还进行工业应用案例分析,将HDCM应用于人脸识别。如图7所示,选取的6组人脸图像来自Pointing’04 ICPR Workshop[27],它所包含的人脸图像均为基准的人脸识别数据集。每一组人脸图像包含15幅序列图像,图像中的人脸姿势以15°的间隔在[-90° 90°]范围内变化,实验中选取序列图像的前7或者后7幅图像组成人脸图像数据集。每一幅人脸图像的分辨率定为80(120,且利用主成分分析法(Principle Component Analysis, PCA)对图像特征进行降维[28],根据实验效果维度大小设置为30。实验中选取每一组人脸图像的前5幅作为训练样本,其他图像作为测试样本。由图7可知,由于每个人脸的特征不同(如发型、面部表情等),且每个人脸姿势或朝右或朝左,因此,对应于每个不同人脸的数据整体上会呈现明显的模式结构,十分适合验证挖掘并利用数据模式结构信息的混合分类方法的有效性及其分类性能。实验中,HDCM的参数dc=6,对比算法给出的所有最优参数均由网格搜索结合5折的交叉验证方法获得,实验数据为运行程序15次后所取的平均结果(表4最后一行数据)。

图7 人脸识别数据集
由实验结果可知,SVM等传统分类方法因在构建分类模型以及分类的过程中依赖单一的数据物理特征而忽略了数据之间存在关联信息的事实,在人脸识别数据集上的分类精度明显低于所提的混合分类方法,尤其当使用0-阶TSK及1-阶TSK模糊分类方法时实验对比效果更加明显。人脸识别数据集上的对比实验结果充分证明了HDCM不仅能够挖掘数据之间的关联信息、识别数据的模式结构关系,而且可有效地结合传统分类方法和高级分类方法两种不同类型的分类技术进行数据分类。
4 结束语
数据集中数据之间往往存在关联,数据并不是孤立的存在,在构建数据分类模型以及分类的过程中应考虑这样一种有别于数据物理特征的数据关联信息。本文所提的混合数据分类方法一方面兼顾了数据的物理特征,另一方还能够有效地识别数据的模式结构,并将数据之间的关联作用信息用于训练数据分类模型及数据分类。人造数据集及真实数据集上的仿真实验结果证明了HDCM的有效性,HDCM实际分类性能优于传统的分类方法。实验中发现,HDCM还能够解决数样本比例不平衡情况下的数据分类[29],如人造数据集Moons及真实数据集Yeast,样本比例分别为2、2.46,因此,在今后的工作中将对此作进一步研究。另外,根据图论知识,一个复杂网络除了节点的度等常见属性外,还包含有同质性、聚类系数等[30],如何将除了度之外其他属性结合进来探索复杂网络局部与全局特征作为数据分类的辅助信息[31]也将是今后的研究内容。
