基于级联端对端深度架构的交通标志识别方法
2019-05-08
(长安大学 信息工程学院,西安 710064)
0 引言
随着汽车保有量的连年增长,交通安全问题日益引起人们的重视。为此,世界各国展开了针对性研究,一些发达国家提出了智能交通系统(ITS),而美国更是提出自动驾驶理论并将相关领域研究列入国家战略发展计划项目。无论是智能交通系统(ITS)还是自动驾驶技术,都需要在复杂交通场景中对影响驾驶行为的相关目标进行正确、实时的捕捉与理解,而交通标志作为传递指示引导或警示信息的道路基础设施,对其进行正确识别是保证智能车辆规范行驶与道路交通安全的前提,因此,对交通标志识别进行研究具有重大意义。
传统的交通标志识别方法主要为基于颜色信息、形状信息[1]或基于两者结合[2-4]对其进行检测,再用模板匹配法[5-7]实现识别功能。
然而真实自然环境中的光照、旋转、遮挡、扭曲等影响使得交通标志识别成为一个极具挑战的任务。
机器学习的发展使得上述问题得到了解决,传统的机器学习方法目标特征仍根据先验知识进行人工设计,只是在分类中应用了分类器如支持向量机( Support Vector Machine,SVM)[8]、贝叶斯分类器[9]、随机森林,然而这种方法会导致识别结果易受特征设计质量的影响,且针对不同检测目标需设计不同的特征,识别效果不稳定且平移扩展性差。近年来,深度学习模型[10]已在计算机视觉领域受到广泛关注,卷积神经网络作为深度学习模型之一,对目标检测与识别有着良好的效果。近年来,出现了R-CNN[11]、Fast-rcnn[12]、Faster-rcnn[13]、FPN[14]、Yolo[15]、ResNet[16]、SSD[17]等区域卷积神经网络方法,在目标检测与识别领域取得了不俗的成绩,将卷积神经网络应用于交通标志识别是研究的热点。
在实际交通环境中,由于目标图像采集距离较远,采集到的交通标志图像往往表现出画质模糊、分辨率低等问题。鉴于此,本文提出一种级联ESPCN与RFCN的交通标志识别方法,通过引入ESPCN深度网络对采集到的图像进行超分辨率处理,再结合RFCN对超分辨图像进行目标检测与识别,实现低分辨率交通标志图像的高精度检测与识别。
1 基于ESPCN的图像超分辨率处理
由于智能车对交通标志反应时间与车辆自身运动的影响,智能车在真实交通环境中采集到的交通标志图片通常都存在识别率低问题,对智能车的规范行驶带来不良影响。为解决这一问题,本文提出用深度网络对原始采集图像做超分辨率预处理,提高识别网络输入图像分辨率。
常用的超分辨率深度网络有SRCNN[18]和DRCN[19],SRCNN在低分辨率输入图像上,先使用双三次插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。DRCN在低分辨率输入图像上采用递归卷积网络得到高分辨率图像输出。然而上述两种网络都是先通过上采样插值将低分辨率输入图像大小进行扩展再重建,对于实现超分辨的卷积操作而言,其处理速度直接依赖于输入图像的大小,因此这种在超分辨操作前增加图像大小的方法增加了计算复杂度,会降低效率,对智能车的实时性要求造成影响。因此本文采用ESPCN网络实现图像超分辨率处理。
1.1 ESPCN网络结构
ESPCN网络结构如图1所示。

图1 ESPCN网络架构
主要由卷积神经网络层与亚像素卷积层构成,在输入的低分辨率图像上应用一个L层卷积神经网络生成低分辨率特征图,然后应用亚像素卷积层对低分辨率特征图进行上采样生成高分辨率图像。
共L层的卷积神经网络其前L-1层可以描述为:
f1(ΙLR;W1;b1)=φ(W1*ΙLR+b1),
fl(ΙLR;W1:l;b1:l)=φ(Wl*fl-1(ΙLR)+bl)
(1)
其中:Wl,bl,l∈(1,L-1)分别是可学习的权重和偏置,Wl是大小为nl-1×nl×kl×kl的二维卷积张量,其中nl是第l层的特征数量,kl是第l层的卷积核数量,偏置bl是长度为nl的向量,激活函数φ逐元素应用且固定。在本文中,激活函数采用TanH函数,Tanh函数的零均值性与本文ESPCN网络层数低、梯度消失问题不明显的特征都使得Tanh函数可以满足训练与实用要求。在经过卷积神经网络层后,得到nl张与输入图像大小相同的特征图,将特征图送入亚像素卷积层进行上采样。
亚像素卷积层由两部分架构组成,一个卷积层及后续的排列像素结构。卷积层部分输出r2张与输入图像大小一致的低分辨率卷积特征图,其中r为上采样因子,即图像的放大倍数,再将特征图按照公式:
ΙSR=fL(ΙLR)=PS(WL*fL-1(ΙLR)+bL)
(2)
进行重新排列,其中ΡS是一个将大小为H×W·r2的元素重新排列为rH×rW大小的运算符,重排列ΡS的数学描述为:
PS(T)x,y=T|x/r|,|y/r|,r·mod(y,r)+mod(x,r)
(3)
其本质就是将低分辨率特征按照特定位置,周期性的插入到高分辨率图像中。这样总的像素数即可与希望得到的高分辨率图像像素数一致,将像素进行重新排列后即可得到高分辨率图像。
1.2 基于ESPCN的交通标志超分辨率预处理
交通标志由于采集距离存在低分辨率情况,考虑实时应用性,若卷积层数过多或图像放大倍数过高会造成实时性低,因此选取L=2,r=3。
卷积神经网络结构如图2所示(这里的卷积网络包括卷积网络层及亚像素卷积层中的卷积网络部份),经过卷积后得到32共9张特征图,从每张特征图同一空间位置各取一个像素进行重新排列,拼接形成一个3*3的区域,对应于高分辨率图像中的一个3*3大小的子块如图3所示。
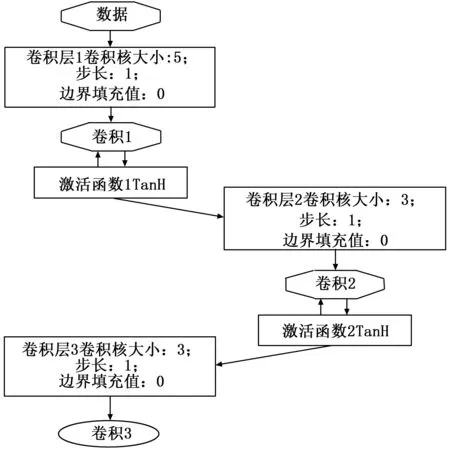
图2 卷积神经网络层结构图
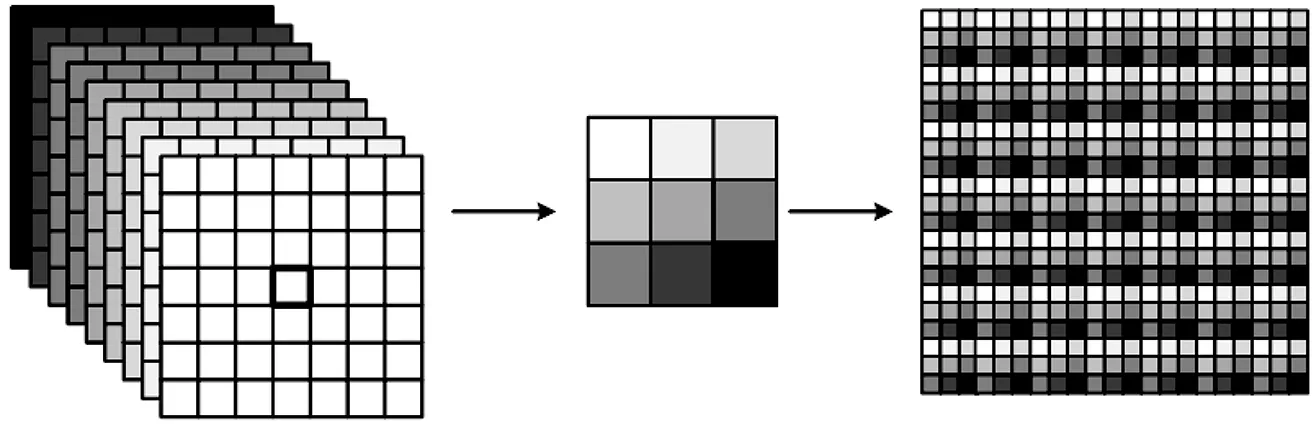
图3 重排列示意图
通过使用亚像素卷积层,实现了图像从低分辨率到高分辨率放大的过程。由于在网络输出层才进行了上采样,与在输入层网络直接上采样的其余超分辨网络架构相比,本文方法在训练和测试时都大大降低了复杂度,效率较高。
2 基于RFCN的交通标志识别
2.1 RFCN网络结构
本文采用RFCN深度架构作为交通标志识别网络,RFCN网络是一种基于区域的全卷积深度网络结构,经典的区域卷积网络Faster-rcnn[13],实际上是将整个网络结构分成了3个子网络,用于在整张图像上做卷积提取特征的子网络1与用于产生感兴趣区域候选框的子网络2都与区域无关,只有用于分类或对候选框进行回归的子网络3基于区域, ROI 池化层用于将前两层子网络与第三层网络衔接起来,但ROI池化层的插入会导致网络结构不再具备平移不变性,影响目标的检测,为解决这一问题,RFCN在提取特征的卷积层与生成候选区域的RPN网络之间加入位置敏感得分映射,生成位置相关特征并将目标的位置信息融合进ROI池化层,使得ROI 池化层前后网络都具备平移不变性,对分类需要的特征平移不变性与检测需要的目标平移不变性都做出准确响应,提升网络检测效果。同时,由于RFCN是完全卷积的,几乎所有的计算都在整个图像上共享,其检测速度较于Faster-rcnn也有很大提高。
RFCN网络结构如图4所示,整体结构与Faster-rcnn相近,采用RPN结合检测两个部分,分别进行候选区域提取与检测,细分为基础卷积层、位置敏感预测层、RPN层、ROI pooling层与决策层,RPN层与原始设计类似,进行前景背景分离,而在RFCN结尾连接着ROI池化层,用于产生对应于每一个ROI区域的分数。
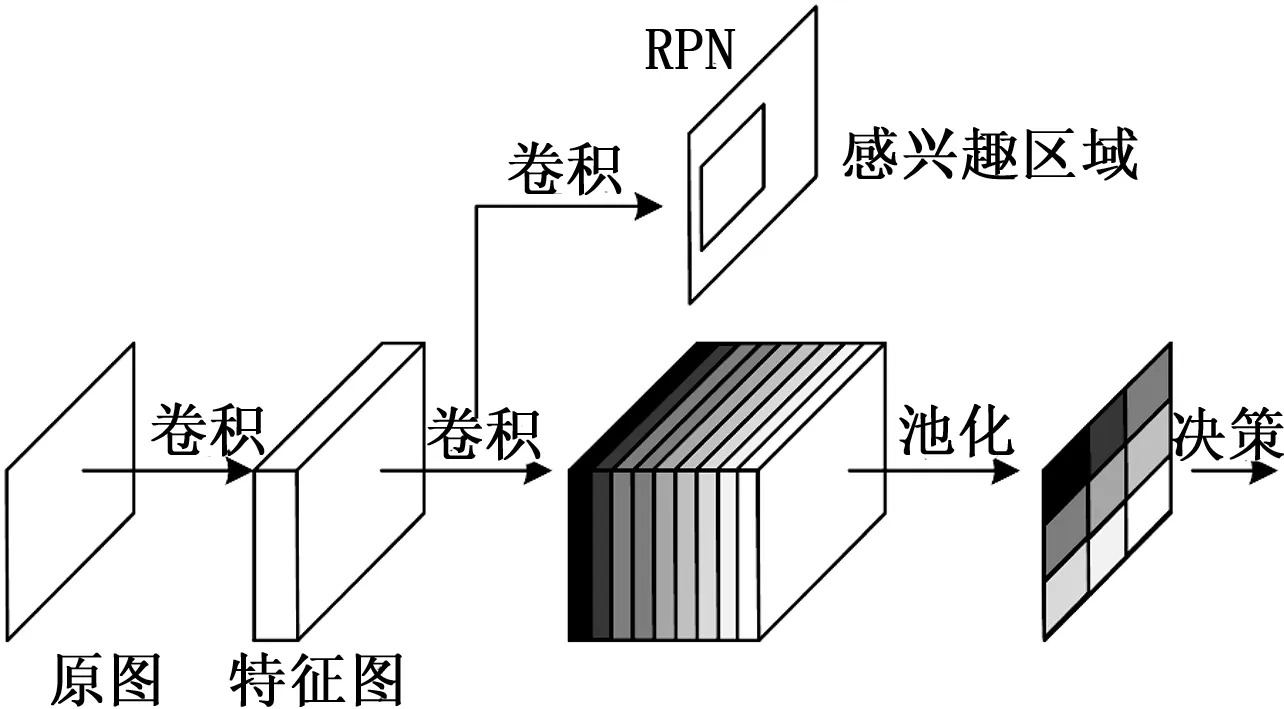
图4 RFCN网络结构
在ResNet101的基础上,去除原有的平均池化层与最后的全卷积层,只保留前100层的卷积层并在后面接一个1*1*1024的全卷积层生成改进ResNet101作为基础网络。卷积层最后,在特征图上用k2(C+1)个1024*1*1的卷积核去卷积即可得到k2(C+1)个大小为W×H的位置敏感分数图,其中C+1表示ROI可能属于的目标类别(其中C为数据集中类别数目,1为背景类)。
为了将位置信息显式编码到每个ROI中,用一个规则的网格将每个ROI区域划分成k×k个块,在第(i,j)个块中,仅在第(i,j)个得分图上进行位置敏感ROI池化操作:
(4)
其中:rc(i,j)是第(i,j)个块对第C类的池化响应,zi,j,c是k2(C+1)张分数图中的一张,(x0,y0)是ROI的左上角块,n是块中的像素个数,θ是所有可学习的网络参数。在图4中可以看到,位置敏感分数图用k2个色块表示,分别与ROI中的k2个区域相对应。然后得到的k2个池化位置敏感分数图上进行投票决策,得到最终分类。
同时,采用一个4k2维卷积层作为边界框回归。在这4k2图上做位置敏感ROI池化,再每个ROI上得到一个4k2维的向量,再通过平均投票转换为一个4维向量。这个四维向量是边界框回归t=(tx,ty,tw,th)的参数。综合上述预测每类的置信度就得到了物体类别与坐标位置。
2.2 基于RFCN的交通标志识别
与1.2节中做同样需求考虑,本文取k=3,则得到9×(C+1)个位置敏感分数图,用9个颜色不同、大小为W×H的色块表示,每个色块的厚度为C+1,如图5所示。
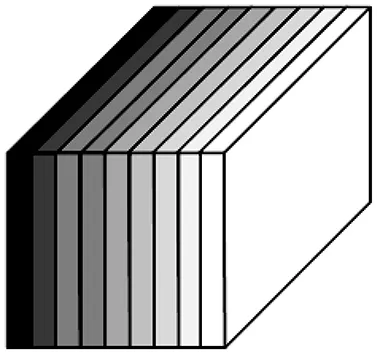
图5 色块示意图
9个色块对应于ROI中的9个位置区域,上左、上中、上右、中左、中中、中右、下左、下中、下右,且表示不同位置目标存在的概率值,最左边色块对应表示上左位置,最右边色块对应表示下右位置。得到某个ROI对应的色块集合后,在每个色块中取出其相应位置区域的一个小方块,将这9个小方块按照其对应位置组成新的立方块,即可得到一个厚度为C+1的k2大小的立方块,对这个新的立方块进行池化,得到k2大小的方块,如图6所示。

图6 位置敏感预测与池化层示意图
为了简化计算,投票决策选用简单的平均分算法,对于每个ROI得到一个C+1维的向量:
rc(θ)=∑i,jrc(i,j|θ)
(5)
然后我们计算不同类别的softmax响应:
(6)
通过这样的方式得到每个类的最终得分,实现目标分类识别。
同时,根据边界回归框可以确定每个检测框的左上角顶点位置及其长宽—即确定出检测框的具体位置,结合目标分类结果即可得到交通标志的位置及其类别,实现交通标志的识别。
3 实验结果与分析
3.1 实验数据集
3.1.1 数据集建立
为了验证提出网络的有效性,构建GTSDB与TSD-max数据集混合的联合数据集作为训练与检测数据集,GTSDB是德国交通标志检测基准库,包含43组共1509张标志图像及900张实景图像,其中有794张标志图像与国内交通标志一致或相似性大,选取共530张标志图像及600张实景图像为训练数据集,264张标志图像及300张实景图像为测试数据集,TSD-max数据集是由西安交通大学车载摄像机实时采集,从中选取交通信号标志检测的数据,共包含120组实景图像,每组图像数量平均为40张,选取其中80组图像作为训练数据集,40组图像作为检测数据集,初始数据集共有训练数据4330张,测试数据2164张,数据量较小,会导致训练模型分类性能不好。
3.1.2 数据集增强
为了提升网络识别性能与泛化能力并防止过拟合,对训练数据集进行数据增强。选用旋转变换、随机裁剪两种方式进行数据增强,具体增强方式为对标志数据做旋转增强与裁剪增强,对实景图像只做旋转增强。旋转变换指的是对训练数据集中图像进行随机任意角度(0-360°)的旋转,结合实际应用需求,本文选择旋转角度为-45°~45°,一个数据图像经过旋转增强会增加6个数据;随机裁剪指的是选择一定大小的窗口对原始图像进行剪切,对于大小为W*H的输入图像,我们选择0.5 W*0.5 H大小的窗口实现裁剪,一个数据图像经过随机裁剪增强会增加6个数据。
经过数据增强处理后,原始数据集被扩充为包含303103张训练数据,15148张测试数据的扩展数据集,扩展数据集的数据量可以训练一个性能较好的模型架构。
3.2 网络训练策略
交通标志数据通常由很多类别组成,而其中部分类别如限速标志、指示标志等含有大量图像,而部分禁令标志类包含图像极少,以本文选用的GTSDB标志类数据为例,各类标志数量情况如下。
因此,若将所有训练图像放入一个图像列表依次进行训练,由于小数量类别图像较于大数量类别图像参与训练的机会更少,训练后的模型对大数量类别的检测识别性能远优于小数量类别。本文选用平衡采样策略解决这一问题,在训练时,把所有训练图像按照类别进行分组,每一类生成一个图像列表,从各个类别所对应的图像列表中随机选择图像进行训练以保证每个类别参与训练的机会较为均衡。
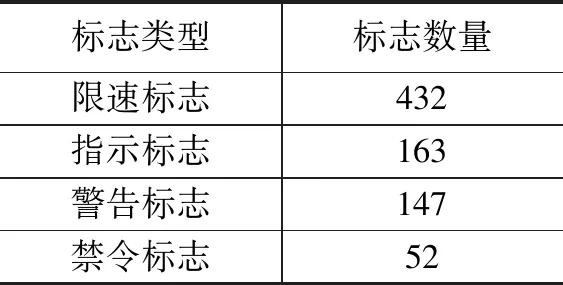
表1 GTSDB标志类数据数量情况
同时,交通标志采集的位置不同会导致数据集中样本目标大小相差较大,造成识别结果不鲁棒,本文选用多尺度训练作为网络训练策略。对于一幅给定的待训练图像,将图像缩放到不同尺度(本文选择放缩至6个不同尺度)作为训练图像送入网络进行训练。通过这种多尺度训练策略,使得参与训练的交通标志目标大小分布更为均衡,进而模型对不同尺度的目标检测识别时更具鲁棒性。
本文在网络训练时选取的各训练参数如表2所示。

表2 训练参数
3.3 评价参数
为了验证与分析模型的优劣性,本文采用识别率、召回率、识别时间及PR曲线(P表示精度(查准率)、R表示召回率(查全率))作为评价参数分析本文模型的识别效果,识别率代表所有正确被检测数据占所有实际被检测数据的比例,召回率代表所有正确被检测数据占所有应该检测到数据的比例,其具体计算如下:
其中:TP为真阳率,即检测图像中为交通标志且被正确识别为交通标志的图像比率,FP为假阳率,即检测图像中不是交通标志但被识别为交通标志的图像比率,FN为假阴率,即检测图像中为交通标志但被错误识别为其他类别的图像比率。
3.4 实验结果及分析
选取单块GPU作为测试硬件平台,具体环境配置为Ubuntu 16.04系统、CUDA 8.0和cudnn,框架为caffe框架。
本文采用的是级联ESPCN与RFCN的识别方法,ESPCN网络用于对模糊的输入图像做超分辨率处理,将交通标志部分提取出来,输入图像与处理后图像对比如图7所示。

图7 交通标志处理对比图
由处理结果可以看出,经过ESPCN网络的超分辨率处理,检测目标-道路交通标志从低分辨率变为高分辨率,基于ESPCN的超分辨率处理同时应用于训练图像与测试图像,基于高分辨率图像的网络训练提升网络识别性能,同时高分辨输入测试图像大大提高了检测与识别精度。
基于RFCN的目标检测识别效果如图8所示。

图8 部分检测识别结果图
由检测识别结果可看出,本文提出的算法对交通标志目标具有良好的检测识别效果。
在相同的训练集、测试集及硬件配置条件下,根据精度、召回率及识别时间三个评价参数对本文算法与经典深度学习算法进行对比,结果如表3所示。
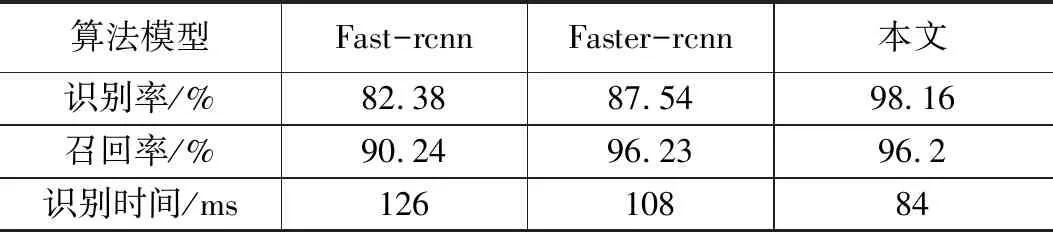
表3 不同算法检测效果对比
为了更全面的表征各算法间检测识别效果的对比,作PR曲线如图9所示。
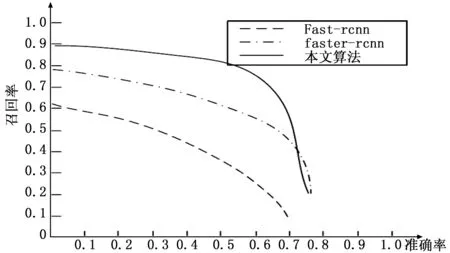
图9 各检测算法pr曲线对比图
4 结束语
复杂交通场景中的交通标志检测与识别是实现智能交通系统(ITS)与自动驾驶技术的关键与基础,针对智能车真实交通环境中采集的交通标志图片通常较为模糊的问题且识别率低的问题,本文提出一种级联ESPCN与RFCN的交通标志检测与识别方法,首先对输入图像进行超分辨率处理,再利用深度网络架构对其进行检测与识别。针对训练过程,采用数据增强的方法对训练数据集进行扩展,同时选用平衡采样和多尺度训练的网络训练策略。实验结果表明,针对模糊的交通标志目标图像,采用本文方法可以得到较好的识别效果,与现有其余基于深度学习的网络架构相比,其检测精度较高且实时性更好,可以满足智能驾驶中对交通标志的检测要求,为智能驾驶的决策与控制提供了重要依据。
