增量式匿名化的隐私保护数据挖掘算法
2019-05-07欧立奇王红英罗小东李盼刘瀚
欧立奇,王红英,罗小东,李盼*,刘瀚
增量式匿名化的隐私保护数据挖掘算法
欧立奇1,王红英2,罗小东3,李盼1*,刘瀚1
1. 西京学院 商贸技术系, 陕西 西安 710123 2. 西安文理学院 陕西省表面工程与再制造重点实验室, 陕西 西安 710065 3. 西安石油大学 理学院, 陕西 西安 710065
在匿名隐私保护系统中增量式匿名化隐私保护数据具有容量大和分散性强的特点,导致挖掘的聚类性不好。提出一种基于互信熵特征提取的增量式匿名化隐私保护数据的挖掘算法,在云计算平台下分析增量式匿名化隐私保护数据的存储结构模型,结合闭频繁项集特征重组方法进行增量式匿名化隐私保护数据的离散化特征重构,在重构的Hadoop云计算平台中进行增量式匿名化隐私保护数据的关联特征提取,采用增量式支持向量机算法对提取的数据特征进行分类识别,根据分类结果实现增量式匿名化的隐私保护数据挖掘。仿真结果表明,采用该方法进行匿名化的隐私保护数据挖掘的准确性较高,特征提取精度较好,收敛性较强。
增量式; 匿名化; 隐私保护; 数据挖掘
随着信息技术的发展,大量的数据存储于网络空间中,需要对网络数据进行安全加密和隐私保护处理,提高信息的安全保护能力。在网络信息化存储平台中有大量的隐私保护数据,比如个人的身份信息数据、银行支付数据以及地理位置信息数据等,需要对隐私保护数据进行安全存储和调度,保障数据的安全性和隐私性,研究增量式匿名化的隐私保护数据挖掘方法,提高数据安全保护性能[1]。本文提出一种基于互信熵特征提取的增量式匿名化隐私保护数据的挖掘算法。在云计算平台下分析增量式匿名化隐私保护数据的存储结构模型,结合闭频繁项集特征重组方法进行增量式匿名化隐私保护数据的离散化特征重构,在重构的Hadoop云计算平台中进行增量式匿名化隐私保护数据的关联特征提取,实现隐私保护数据挖掘优化,最后进行仿真实验分析,展示了本文方法在提高数据挖掘能力的优越性能。
1 数据的分布结构模型与特征提取
1.1 增量式匿名化隐私保护数据的分布结构模型
为了实现增量式匿名化隐私保护数据的优化挖掘,需要首先构建云存储模式下增量式匿名化隐 私保护数据的分布式数据结构模型[2],用一个四元组表示增量式匿名化隐私保护数据的模糊分布式结存储中心,为=(,,,),假设为增量式匿名化隐私保护数据交互的相空间嵌入维数,采用Logistics映射方法构建隐私保护数据的明文序列,采用分段线性混沌映射方法构建隐私保护数据密文协议,采用混合加密协议方法进行隐私保护数据的循环加密设计,提高数据的隐私保护性,根据上述分析,得到增量式匿名化的隐私保护数据挖掘的总体设计结构模型如图1所示。

图 1 隐私保护数据的加密挖掘过程

根据融合系数采用模糊聚类实现自适应寻优,实现最优控制和增量式匿名化隐私保护数据共享挖掘,建立一种基于数据挖掘理论的增量式匿名化隐私保护数据共享挖掘数学模型,将待挖掘的增量式匿名化隐私保护数据按照5元组进行关联规则项特征重建,表述为:

其中N、N和N分别表示增量式匿名化隐私保护数据的平均互信息特征量和状态分布集。在云计算平台下分析增量式匿名化隐私保护数据的存储结构模型,描述为过程为:


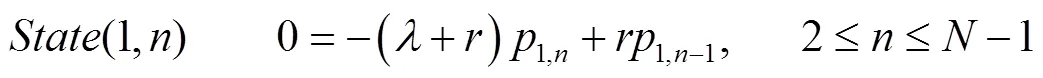
采用单变量特征提取方法得到待挖掘数据的决策项为(w,t),输出增量式匿名化隐私保护数据的公钥[åÎy]2=1/-D,|D|<2-K,引入优化的分类回归模型,得到观察数据集中的隐私保护数据的样本块序列123……x,则t=cÅx,={1,2…,}。
1.2 增量式匿名化隐私保护数据的关联规则集
采用C4.5决策树模型,构建增量式匿名化隐私保护数据的分类决策模型[4],所以当=1时, 采用相关检测器进行数据交换数字证书设计,得到|{åÎy]2·*}|Î(3/8,5/8),生成正确的消息认证码,假设匿名化隐私保护数据的关联规则集合S中有个样本,则:
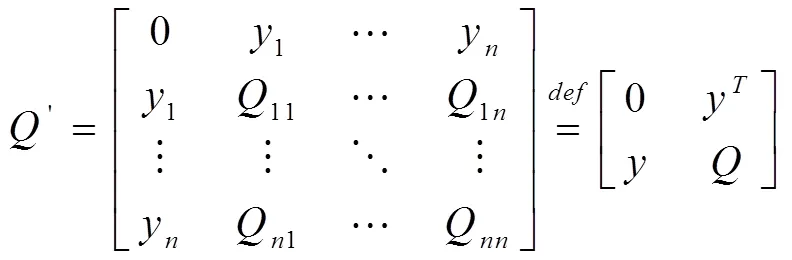
根据上述假设,得知匿名化隐私保护数据的关联规则矩阵正定,则存在的逆矩阵-1进行匿名化隐私保护数据的模糊规则集构造,并-1同时也为正定矩阵,采用混合相似度特征分析方法,对增量式匿名化隐私保护数据进行特征重组,描述为:


从而得证´总是存在逆矩阵,定义增量式匿名化隐私保护数据的簇中的信息分布模型为[,]=[(),(+)],得到模糊信息频繁项集,进行保护数据挖掘。
2 增量式匿名化隐私保护数据挖掘优化
2.1 互信熵特征提取
在云计算平台下分析增量式匿名化隐私保护数据的存储结构模型的基础上,进行数据挖掘算法优化,提出一种基于互信熵特征提取的增量式匿名化隐私保护数据的挖掘算法,得到关联规则矩阵,采用增量式支持向量机集合S进行特征重构,随着数据样本的增加,可得:

式中,为单位矩阵,当增量式匿名化隐私保护数据集合S随着样本的增大,在移出一个样本后,可得数据挖掘输出的特征量为:

上式表示,集合S在随着样本的移入,采用增量式学习方法进行自适应寻优[5],有ÎS,,且Î-S,。对于匿名化隐私保护数据的统计特征量ÎS,得:


根据上述分析,提取互信熵特征,采用增量式支持向量机算法对提取数据特征进行分类识别[6]。
2.2 数据挖掘输出
假设有一增量式匿名化的隐私保护数据样本ÎS,使,假设支持向量机模型学习过程中得到的3个模糊数据生成序列分别为:(13)


设()为实概率空间(W,,(),)中的有理积分,增量式匿名化隐私保护数据分类属性集为{1,…,u},根据分类关系进行信息融合处理[7],得到关联映射为:
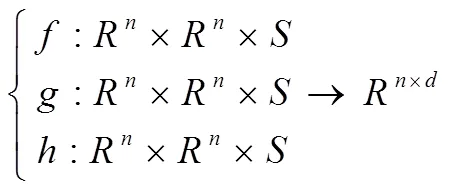


在非确定条件对合Cauchy-Hadamard型非线性系中进行最优挖掘向量重组[9],数据信息的特征值(k,k)<(1,1),假设表示增量式匿名化隐私保护数据的关联规则项,得到:

采用Lyapunov泛函进行挖掘过程的稳定性分析[10],得到:

在增量式学习下,数据挖掘的模糊迭代步数为:

根据Lyapunov稳定性原理,得到本文设计的增量式匿名化隐私保护数据的挖掘模型满足收敛性条件。
3 仿真实验分析
为了测试本文方法在实现增量式匿名化隐私保护数据挖掘中的应用性能,进行仿真实验,实验采用++和Matlab 7混合编程设计,在Simulink上建立匿名隐私保护系统,数据属性分布的最大相似度max=30,关联系数为0.23,数据分布的稀疏度为0.19,待挖掘的数据负载分布见表1。

表 1 数据负载量分布
根据上述仿真环境和参数设定,进行增量式匿名化隐私保护数据挖掘,得到图2所示数据。
分析图2得知,采用本文方法进行数据挖掘的收敛性较好,挖掘输出的特征分辨能力较强,测试数据挖掘的收敛性能,得到对比结果如图3所示。
分析图3得知,采用本文方法进行增量式匿名化隐私保护数据的挖掘的迭代步数较低,特征提取精度较好,收敛性较强。

图 2 数据挖掘时域波形输出

图 3 数据挖掘性能对比
4 结语
本文提出一种基于互信熵特征提取的增量式匿名化隐私保护数据的挖掘算法,在云计算平台下分析增量式匿名化隐私保护数据的存储结构模型,结合闭频繁项集特征重组方法进行增量式匿名化隐私保护数据的离散化特征重构,在重构的Hadoop云计算平台中进行增量式匿名化隐私保护数据的关联特征提取,采用增量式支持向量机算法对提取的数据特征进行分类识别,根据分类结果实现增量式匿名化的隐私保护数据挖掘。研究得知,采用本文方法进行匿名化的隐私保护数据挖掘的准确性较高,特征提取精度较好,收敛性较强,在隐私保护数据挖掘中具有很好的价值。
[1] Farnadi G, Bach SH, Mones MF,. Soft quantification in statistical relational learning[J]. Machine Learning, 2017,106(12):1971-1991
[2] Rames A, Rodriguez M, Getoor L. Multi-relational influence models for online professional networks[C]// Proceedings of the 2017 International Conference on Web Intelligence. New York: ACM, 2017:291-298
[3] 马晴,王桂霞,李联和.八次对称二维准晶Ⅱ型单边裂纹的动力学问题[J].应用数学和力学,2018,39(10):1180-1188
[4] 丘小玲,贾文生.Berge极大值逆定理与Nash平衡定理[J].应用数学学报,2018,41(2):280-288
[5] Arbabi E, Arbabi A, Kamali SM,. Multiwavelength polarization-insensitive lenses based on dielectric metasurfaces with meta-molecules[J]. Optica, 2016,3(6):628-633
[6] 刘保见,张效义,李青.基于演化博弈论的无线传感网监测节点分群算法[J].计算机应用,2016,36(8):2157-2162
[7] 亚玲,李春阳,崔蔚,等.基于Docker的PaaS平台建设[J].计算机系统应用,2016,25(3):72-77
[8] 王楚捷,王好贤.M-CORD下无线接入网络资源分配研究[J].计算机工程与应用,2018,54(22):92-98
[9] 庞晓琼,任孟琦,王田琪,等.一种支持完美隐私保护的批处理数据拥有性证明方案[J].计算机科学,2018,45(11):130-137,154
[10] 朱利民,赵丽.基于改进ACO与分布式社区检测的WSN路由协议[J].计算机工程与应用,2018,54(22):119-126
The Algorithm for Data Mining of Incremental Anonymous Privacy
OU Li-qi1, WANG Hong-ying2, LUO Xiao-dong3, LI Pan1*, LIU Han1
1.710123,2.710065,3.710065,
In the anonymous privacy protection system, incremental anonymous privacy protection data has the characteristics of large capacity and strong dispersion, which leads to poor clustering of mining. An incremental anonymous privacy data mining algorithm based on mutual trust entropy feature extraction was proposed. In the cloud computing platform, the storage structure model of incremental anonymous privacy protection data was analyzed, and the discrete feature reconstruction of incremental anonymous privacy protection data was carried out by combining the closed frequent itemset feature reorganization method. In the reconstructed Hadoop cloud computing platform, incremental anonymous privacy protection data association feature extraction was carried out, and incremental support vector machine algorithm was used to classify and recognize the extracted data features. The privacy protection data mining based on incremental anonymity was realized according to the classification results. The simulation results showed that the proposed method was accurate, accurate and convergent.
Incremental; anonymous; privacy protection; data mining
TP391;O234
A
1000-2324(2019)02-0259-05
10.3969/j.issn.1000-2324.2019.02.019
2018-06-21
2018-07-09
欧立奇(1980-),男.硕士,讲师. 研究方向:计算机软件与理论,数据挖掘. E-mail:jinder44@sina.com
Author for correspondence. E-mail:lipan5528@163.com
