基于MongoDB的数据分片与分配策略研究∗
2019-05-07熊峰刘宇
熊 峰 刘 宇
(1.武汉邮电科学研究院 武汉 430074)(2.南京烽火星空通信发展有限公司 南京 210019)
1 引言
如今的时代,是互联网的时代,是信息爆炸的时代,也是大数据的时代。而在大数据时代的背景下,根据Eric Brewer教授在PODC会议上提出的CAP 理论[1~3],表明为了追求系统可用性与数据一致性,传统的并行关系型数据库限制了其本身的扩展能力,不适用于海量数据的存储。基于此,在大数据管理的迫切需求下,拥有负载均衡的自适应特性,大多数复杂查询都能够灵活支持,并且有着高效读写效率的NoSQL(非关系型数据库)存储技术从众多大数据存储技术中脱颖而出[4~6],而 Mon⁃goDB作为最具代表性的NoSQL数据库,具有面向集合存储、使用BSON存储、支持动态查询和完全索引、自动分片、支持故障恢复、支持各种语言驱动程序,自动处理碎片等功能[7~9],能够适应现代Web应用飞速增长的海量数据,并且在分布式架构下可以达到很好的性能[10],是目前最有影响力的NoSQL数据库之一。
然而在分布式的系统架构下,如何将数据进行分片和分配[11~12]是必须要考虑的,因为两者策略的选择会直接影响到整个系统的扩展性以及负载均衡性能[13]。因此本文选择MongoDB数据库,通过剖析其工作机制以及自动分片的实现算法,提出了分片键选择机制来尝试提高集群的扩展性能;并在考虑了节点访问负载差异的情况下,尝试对内置的数据分配均衡策略[14~15]进行算法优化。
2 MongoDB自动分片集群系统
MongoDB自动分片(auto-sharding)集群由数据库分片(shard)、配置服务器和mongos路由进程组成,其体系架构图如图1所示。

图1 自动分片集群
1)分片:分片存储集合中的文档,可以是单个服务器,但为了在生产环境中提供高可用和数据一致性,应考虑使用副本集,它们提供分片的主副本和备份副本。
2)查询路由器:查询路由器运行一个mongos实例。它提供让客户端应用程序能够与集合交互的接口,并隐藏数据被分片的事实。查询路由器处理请求,将操作发送给分片,再将各个分片的响应合并成发送给客户端的单个响应。一个分片集群可包含多个查询路由器,在存在大量客户端请求时,这是一种极佳的负载均衡方式。
3)配置服务器:配置服务器存储有关分片集群的元数据,包含集群数据集到分片的映射。查询路由器根据这些元数据确定要将操作发送给哪些分片。查询路由器进程向配置服务器写入时,会使用两阶段提交。这能保证配置服务器之间的一致性。
3 MongoDB自动分片机制
MongoDB自动分片的基本思想就是将数据集合根据用户指定的分片键(shard key)来从逻辑上分割成小的数据块(chunk)。这些数据块相应的存储到各个分片中,每个片只负责这个集合数据的一部分。由于配置服务器的存在,应用程序在收到用户的查询指令后,不需要知道所要查询的数据在哪个片上,甚至不需要知道数据已经被拆分成块了,对应用来说,它仅知道连接了一个普通的mongod服务器(隐藏数据被分片的事实)。路由器知道数据与片的对应关系,能够转发请求到正确的片上。如果请求有了回应,路由器将其收集起来回送给应用。所以在分片之前查询路由器要运行一个路由进程,该进程名为mongos,这个路由器知道所有数据的存放位置,所以应用可以连接它来正常发送请求。
4 分片策略
4.1 分片键选择机制
MongoDB的auto-sharding自动分片机制实现海量数据在各数据库节点上的分布式存储及各分片上的负载均衡,其性能主要由分片键的选取情况来决定。如果选择了合适的分片键,使得数据能够在每段片键上分配更均衡,并且数据量增长时也能够在每段上均匀分布,这样就能确保每个数据库实例的访问负载相当,不至于出现任何分片服务器负载过重的情况。而糟糕的片键选择则会严重影响系统性能,出现数据分布不均衡,单个数据库实例下存储了大量数据,进而造成单点负载过重,而其他数据库节点则基本处于闲置状态,极大地浪费了硬件资源。所以选择恰当的片键至关重要。然而大多数研究通常假定认为适当的分片键已被选定而专注于分片部署及实施策略,对于分片键的选择问题却鲜有渉及[16]。
故针对分片键,本文尝试提出基于以下几点的选择机制。
1)易于拆分:分片键应该易于将数据集分割成块。
2)随机性:MongoDB是基于范围分片的,故随机的片键可确保文档在分片之间的分配更加均衡,从而确保没有任何分片服务器负载过重。
3)复合键:应尽可能使用单字段片键,但如果没有合适的单字段片键,可选择使用复合片键。
4)基数:基数(cardinality)指的是字段值独一无二的程度。如果字段值是独一无二的(如社会保障卡号),字段的基数就很高;如果字段值独一无二的可能性较小(如眼睛颜色),字段的基数就很低,即分片键的取值个数有限,根据片键范围划分的单个块数据量会十分庞大。在MongoDB的分片机制中,是按块来进行存储及迁移的,若整个数据集仅分割成有限的几个块,那么根本就达不到将数据分布式存储的初衷。通常,基数较高的字段更适合用作片键。
5)以查询为导向:研究在程序使用中的查询。如果能够从单个分片收集到所有的数据,查询的性能将更佳。如果片键与常用的查询参数一致,将获得更佳的性能。许多应用访问新数据比老数据更频繁,所以我们希望数据大致上按照时间排序,但同时也要均匀分布。这样一来既能把我们正在读写的数据保持在内存中,又可以使负载均衡地分散在集群中。
基于上面的内容,我们可以概括出一个片键选择公式:
{coarseLocality:1,search :1}
即用准升序键加搜索键的复合片(compound shard key)策略来实现上面的目标。其中coarseLo⁃cality字段是基数较低的,最好此键的每个值能对应几十到几百个数据块,用来控制数据局部化(da⁃ta locality);而search字段则是基数较高的,是数据上常用到的一个检索字段。
4.2 片键公式应用实例
本文以某分析程序为例详细说明分片键选择公式的应用。在此分析程序中,用户会定期通过它访问过去一个月的数据,而我们希望能尽量保持数据易于使用。因此可以在{month:1,user:1}上分片,其中month是一个小基数的升序字段,即每个月它都会有一个更新更大的值。user适合作为第二个字段,因为我们会经常查询某个特定用户的数据。
从第一个数据块开始,组合区间是((-∞,-∞),(∞,∞))。当它被填满,将其分为两个块,分别是区间((-∞,-∞),(“2017-04”,“rex”))和((“2017-04”,“rex”),(∞,∞))。假设现在还是4月份(“2017-04”),则所有的写操作都会被均匀地分到两个数据块上来。所有用户名小于“rex”的用户都会被放在第一个块上,而所有用户名大于“rex”的用户都会被放在第二个块上。
随着数据持续增长,这个方案还会持续有效。4月里后续创建的块都会移动到不同的分片上,从而确保了读写在集群中的负载均衡。等5月到来时,我们开始创建边界为“2017-05”的块。随着6月的到来,“2017-04”的块的访问频率已经很低,所以就可以将这些块安静地换出内存使之不再占用资源。尽管以后仍有可能因为历史原因再查看这些块,但是应该不需要再分割或迁移它们了。
综上所述,month+user的复合片键作为分片键的选择策略,既可以满足有足够的粒度进行块拆分,又能够将插入数据均匀分布到各个分片上,且保证了CRUD操作能够利用数据局部性,是恰当的分片键选择。
5 数据均衡策略
5.1 自动分片均衡策略的不足
在分片键确定后,MongoDB将按照用户指定的分片键对数据进行范围分区,形成一系列数据块(负载均衡器(balencer)进行数据迁移的基本单位)。当前的均衡算法下[17],均衡器会查询各分片内的总块数,若块数最多与块数最少的分片的块数之差超过某个设定值,负载均衡器将会迁移前者的数据块到后者。但问题在于,该均衡算法仅仅只是从各分片内的数据块数量差异这个角度进行了考虑,而没能将各个数据分片节点访问负载的大小差异情况考虑进来,从而无法在超高并发的数据访问状态下做到数据分配的实时均衡。基于此,本文对数据均衡算法进行了优化改进,提出基于节点负载差异的数据均衡算法,从数据量以及节点负载差异这两个方面实现均衡。
5.2 基于节点负载差异的数据均衡算法
5.2.1 算法思想
算法思想具体如下:
输入:集合命名空间ns;分片数n;
分片约束信息映射表shardToLimits;
分片分块映射表shardToChunks;
块均衡设定值α,负载选择比例β,
负载均衡设定值γ
输出:迁移源分片from;迁移目标分片to
1)首先定义最小分片列表minList以及存储即将耗尽等待移除分片集drainingShards,算法表达式为

2)接着遍历数据集命名空间内的所有分片来获取各分片s的信息,再通过分片s的信息来获取所在节点的负载,进而求和得出总负载,算法表达式为
For each shard s∈ns DO
shardLimits←shardToLimits.find(s)
load←getLoad(shardLimits)
sumLoad←sumLoad+load
3)逐项比较找出负载最高的分片,算法表达式为
IF s.load>maxLoad.load
ΤHEN maxLoad←s
4)若分片s满足块数既不是最大的也不是存储即将耗尽等待移除的分片的双重条件,则将其加入候选minList列表,算法表达式为
IF!isSizeMaxed(shardLimits)
AND!isDraining(shardLimits)
ΤHEN minList.add(s)
5)逐项比较找出块数最大的分片,找出存储即将耗尽分片加入drainingShards,求出平均负载,算法表达式为
IF s.size>max.size
ΤHEN max←s
IF isDraining(shardLimits)
ΤHEN drainingShards.add(s)
avgLoad←sumLoad/n
6)对 minList排序生成minSortedList,对同时满足分片s属于minSortedList以及分片s的排名位于分片总数前β比例的分片s集合进行遍历,逐项比较找出块数最小的分片,算法表达式为
minSortedList←Sort(minList)
FOR each shard s∈minSortedList
AND s.rank<n×β DO
IF s.nodeload>min.nodeload
ΤHEN min←s
7)检查以下条件,确定迁移源分片:若分片内块数之差超过设定值,则确定源分片为块数最大的分片,算法表达式为
IF max.size-min.size>n×α
ΤHEN from←max;to←min
8)若7)不满足,检查以下条件,确定迁移源分片:若存在存储耗尽待删除分片集合,则从集合中选取一个分片作为源分片,算法表达式为
ELSE IF!drainingShards.IsEmpty()
ΤHEN from←drainingShards.get()
AND to←min
9)若8)不满足,则检查以下条件,确认是否需要进行迁移:若存在负载与平均负载之差超过额定值的分片,则确定过载分片中负载最高的分片为源分片,否则不需要进行迁移,算法表达式为
ELSE IF(maxLoad-avgLoad)/avgLoad>γ
ΤHEN from←maxLoad
AND to←min
ELSE return NULL
图2展示了算法的详细流程。
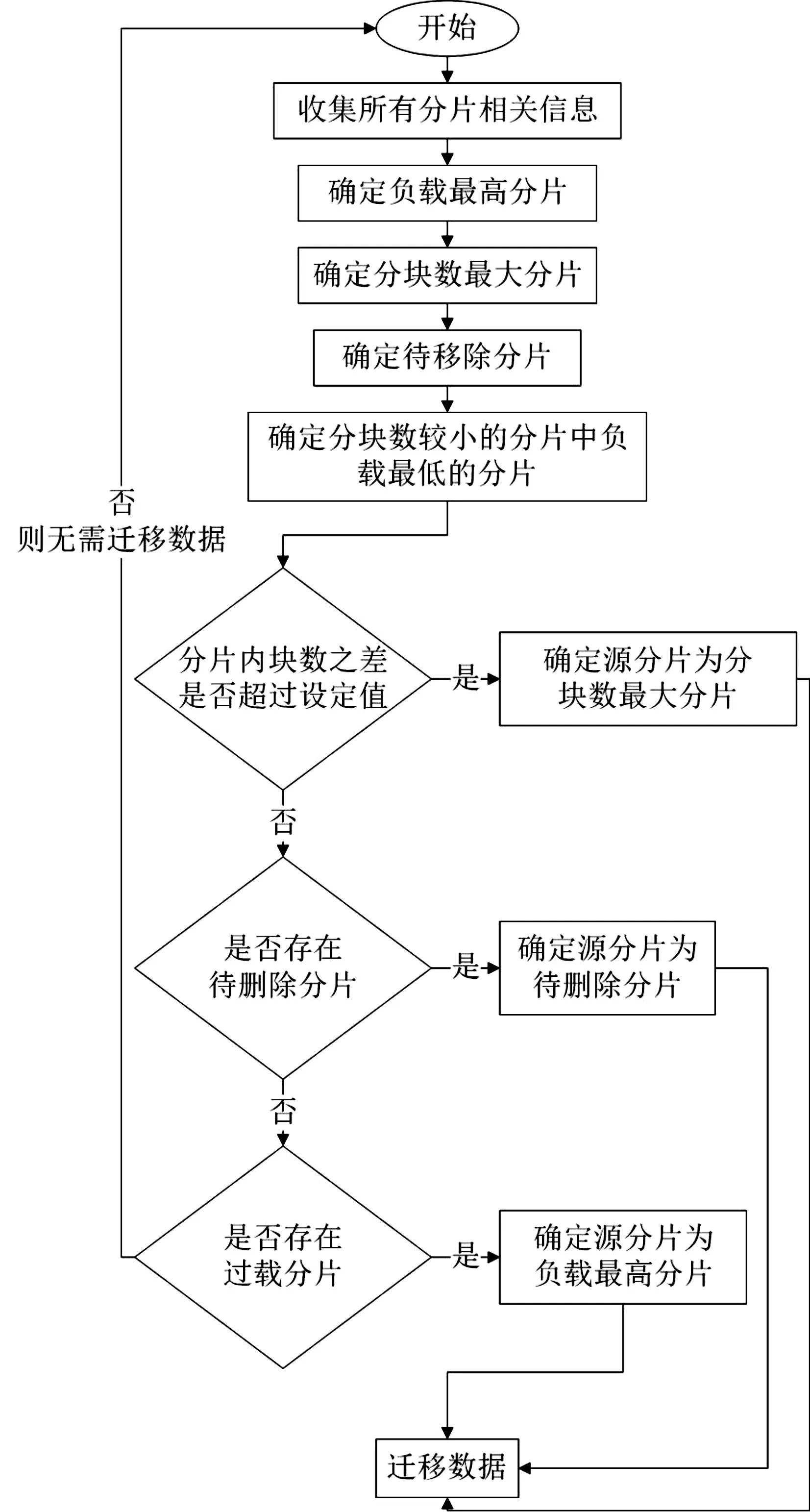
图2 数据平衡负载流程图
5.2.2 算法性能测试
测试场景基于MongoDB集群,由12台虚拟机组成,每台虚拟机配置均为8GB内存+1T硬盘,且均安装了redhat enterprise linux7.0操作系统,虚拟机间通过100Mbps局域网互连。MongoDB采用分片模式,共3个分片,由于是测试用,为简化操作,故没有采用复制集模式。MongoDB版本为3.4.0,开启3个mongos查询路由服务。
将新的基于节点负载差异的数据均衡算法在MongoDB中实现,并比较新旧两种算法的并发读写性能。为模拟真实环境,测试数据均参照真实互联网节点采集系统数据格式随机生成,数据总量为30000000条。实验首先验证了新旧算法下Mon⁃goDB集群的高并发写性能,在不同的并发数下,保持数据总量不变。集群在不同的并发数下,将所有测试数据均插入完毕所用耗时如表1所示,表中单位为s。表中的数据是在相同的条件下,取5次测试的平均值所得。图3给出了两种算法写性能的对比情况。

表1 并发写性能比较

图3 并发写性能比较
保持测试中的并发数与数据总量不变的条件下,将新旧两种算法进行比较,测试集群的并发读性能。读取完所有测试数据所用耗时如表2所示,表中单位为s。集群的并发读性能对比图如图4所示。

表2 并发读性能比较

图4 并发读性能比较
6 结语
针对大数据环境下,对于分布式存储系统扩展性及负载均衡性能至关重要的数据分片及分配问题,以MongoDB为研究对象,提出了分片键选择机制,并证明了该片键选择策略的有效性,既可以满足字段基数足够进行块拆分,又能使插入数据在各个片上均匀分布,且CRUD操作亦能够利用数据局部性;而针对MongoDB现有的负载均衡策略未考虑实际负载的情况,提出了基于节点负载差异的数据均衡算法,并通过实验验证了自动分片集群在并发情况下读写性能相比旧的算法有着明显的提升。
下一步工作主要是将数据分片、数据分配以及负载执行三个相互关联的课题进行关系建模与归纳,对影响数据分布问题的三大要素数据、负载和节点进行着重分析,研究自动数据分布的可行方案。
