AM-CNN:一种基于注意力的卷积神经网络文本分类模型
2019-05-05王吉俐彭敦陆
王吉俐,彭敦陆,陈 章,刘 丛
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
文本分类是对现存的文本数据进行有效组织、信息检索和数据挖掘的基础,是自然语言处理领域中一个重要研究方向.传统的文本分类算法通常可以分为三个阶段:文本特征提取、分类器训练和预测.其中,采用特征工程进行文本特征提取一直以来是研究的重点.但是受限于文本语义特征提取的不完备,后续训练的分类器普遍存在泛化性不足的问题.
近年来,深度学习算法的高速发展为文本分类提供了新思路.绝大多数基于深度的模型具有自动提取深层文本特征的功能,摒弃了人工特征提取步骤,从而简化了算法的流程.词嵌入算法将语言模型用高维向量表达,使词向量蕴含语法和语义信息.由于文本是时序型数据,以往学界主要采用循环神经网络(RNN)捕捉文本的文法信息.RNN存在梯度爆炸和消失等问题,故Hochreiter等人提出改进的RNN结构LSTM,虽然从一定程度上缓解了上述问题,但随之而来计算量剧增[2].Kim Y等人最早将卷积神经网络(CNN)运用到文本分类任务中[1].相比起序列型模型,CNN采用稀疏连接和参数共享大大降低了参数个数.
监督学习领域,无论是传统的机器学习,还是基于深度的算法都依赖于数据集的质量.其中,数据平衡性是一项重要的指标.实际上,现实中绝大多数分类问题的类别在先验上是不平衡的.例如,信用卡欺诈、杀人罪等两分类问题都存在数据极端不平衡的情况.在不平衡数据集上直接训练,会使分类器倾向于将未知样本预测为先验概率较高的类别.以往大多数做法着重考虑数据集的预处理,人为地构建一个平衡的数据集,而忽略了相关算法的改进.
机器翻译领域中,Bahdanau等人提出了注意力机制使模型自动学习到区分句子中重点单词的能力,实验表明,效果较好[6].受到该机制的启发,本文提出了一种基于类别注意力的卷积神经网络,希望可以使模型根据样本的类别信息增强模型的判断.该模型利用LSTM提取文本的上下文特征,并结合Attention机制作用于类别特征向量上.假设这些得出的特征向量是类别相关的,可以影响对文本的判断,最后将这些特征向量整合起来作为CNN的卷积核.
2 相关工作
迄今,众多研究者对分类任务进行了深入研究,提出了一系列基于机器学习的分类算法.Sun A等人针对文本分类不平衡情况,提出了一种基于SVM的分类器来解决这个问题[11].姚立等人针对传统随机森林算法在维度高、噪声大的文本分类上效果较差的问题,提出了一种基于隐狄利克雷分配(LDA)主题模型的改进随机森林算法,实验表明分类结果较好[12].龚垒等人从训练集对文本分类性能影响的角度考虑,通过减小训练集合特征向量的类别资源分布不均衡,提出了一种基于特征类别均衡的文本分类方法,实验结果显示,该方法具有较好的结果[14].
传统的文本分类算法在小规模数据集的文本分类任务中体现了优越性,但对大规模数据集而言,分类结果并不理想.深度学习算法的兴起,为文本分类提供了新思路,出现了多种基于神经网络的文本分类的方法.不同于Kim Y等人将文本切分为词作为模型的输入的方法,Zhang X等人使用了字符级卷积网络(ConvNets)来处理文本分类任务[4].Zhou C等人使用CNN训练文本向量,将通过CNN得到一些序列作为词向量化的输出,再把这些序列输到LSTM中,完成文本的分类操作[3].Conneau A等人把深度残差网络应用于文本分类领域,将深度残差网络和卷积神经网络相结合,实验表明,分类结果较好[7].
近年来,注意力机制被大量的应用在文本分类模型中,其优点是可以在分类时分辨出文章每个词的不同重要程度.文献[5]提出在用层次化的结构保留文档结构的同时,在词和句子上使用Attention机制,分辨出各个句子和词对分类类别的重要性.不同于之前其他论文使用词或句子层面进行建模的方法,文献[8]使用两个神经网络分别建模句子和文档,采用一种自下向上的基于向量的文本表示模型,完成文本的分类.
本文试图利用循环神经网络捕捉文本特征之间的上下文信息,并引入注意力机制对其权重进行更新计算,得到文本类别的特征向量矩阵,突出类别向量的重要程度.然后,使用卷积神经网络模型完文本分类任务.实验结果表明,该方法比现有的文本分类算法在不平衡的数据集上具有更好的计算效率与分类效果.
3 文本预处理
针对本文所提出的算法,文本预处理大体上分为以下两步:1)类别相关的关键词提取2)文档编码.本节首先给出文本分类问题的定义以便后续章节的推导,再介绍文本的预处理过程.
3.1 术语解释
给出类别集合C={c1,c2,c3,…,ci,…,cm},分类器F将类别未知的样本pj预测为C中的某一类别,即F(pj)∈C.
表1中给出了下文将要用到的符号及所代表的含义.
3.2 类别相关的关键词抽取
FastText[13]中将文本词向量的均值作为该文本的语义信息,该方法简洁高效,并在分类任务上取得了较好的成绩.本文受到以上方法的启发,用类别特征词嵌入拼接而成的矩阵表示类别:采用tf-idf和交叉熵结合的方法对文本关键词与类别的相关度进行评价,给定关于类别的文档集为P={p1,p2,…,pL},为方便起见,在每个类别中选用相关系数排名前的关键词作为类别特征词.

表1 算法中所用到的符号说明Table 1 Explanation of words used in paper
s=s1∘s2…∘sk
(1)
S={s1,s2,…,sL}
(2)
其中S为类别矩阵.符号∘为拼接运算,例如,某个类别特征词嵌入为s1,s2,…,sk,通过拼接运算可以得到s∈Rk×d.
算法1描述了关键词抽取的算法(图1).算法首先采用结巴分词器对每篇文本进行分词(第2行).分词后利用word2vec生成词向量(第3行).第4-5行是使用tf-idf方法得算法1.关键词抽取算法

到每个类别文章的高频词,再通过交叉熵将这个类别的高频词与其他类别的高频词作对比,判断这个类别的高频词是否在其他类别中出现频率高.第6行得到关于这个类别的个关键词,最后这前个关键词拼接成类别特征向量(第7行).
3.3 文档编码
中文不像英文文本是天然分词的,在运用深度学习算法之前需要对其做进行分词处理.给定需要处理的文档集P={p1,p2,…,pD},对于每篇文档pj通过分词和词嵌入后可以得到文档的编码u={u1,u2,…,ul}.
4 文本分类的神经网络算法(AM-CNN)
本节主要介绍AM-CNN模型实现文本分类的具体过程,AM-CNN的架构如图2所示.由图2可见,该模型从下至上,首先采用了RNN的变种LSTM对文本的上下文特征进行捕捉,将得出的特征向量参与类别向量的Attention选择,并整合成类别特征矩阵作为CNN的卷积核.
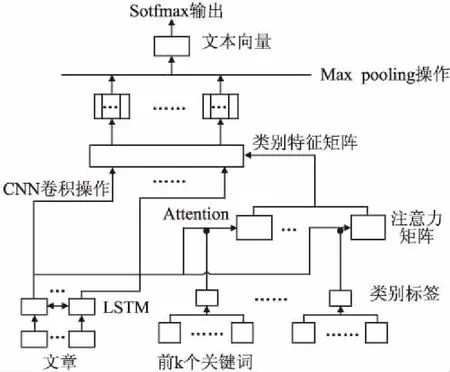
图2 AM-CNN分类模型架构Fig.2 Architecture of AM-CNN model
4.1 基于LSTM模型的优化向量表示
在文档p以词向量形式表示后,输入到LSTM模型中,通过三重门,即输入门、遗忘门和输出门.不同于原始的RNN结构,当信息进入基于LSTM的循环神经网络中,可以根据规则来判断是否有用.只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘.输入的词向量通过LSTM模型后,形成新的词向量表示.文档p对文档的约定做一定修改:
u=u1,u2,…,ul
(3)
h=LSTM(u)
(4)
h={h1,h2,…,ht,…,hl}
(5)
算法2.捕获上下文信息的LSTM模型
输入:文章的词向量u=u1,u2,…,ul
输出:LSTM的隐含状态向量h

这里,ht为t时刻的LSTM的隐含状态向量.本文将隐含层信息作为后续类别特征选择的凭证.

4.2 利用Attention模型突出特征信息码
前一节给出了通过序列模型获取上下文信息的更新过程.在此基础上,引入注意力机制对文本类别的特征向量矩阵进行计算.注意力机制的特点是动态地分配权重,以便将注意力资源分配到更有效的信息上.
本文将序列模型隐含状态向量的均值h′作为辅助信息:
(6)
为更好地突出类别之间的差异,在类别层级上采用注意力机制:
mj=vTtanh(WSSj+Whh′+b)
(7)
(8)
c=∑Laisj
(9)
类别特征通过上述的注意力机制得到一系列特征信息码c1,c2,…,ck∈Rk×1.其中ai表示对类别标签向量的注意力概率权重.v,W为权重矩阵,sj为关键词向量,而mj表示的是sj与h′之间的匹配得分.
算法3.Attention模型算法
输入:序列模型隐含层状态向量的均值h′,类别关键词特征sj
输出:特征信息码c

算法3展示了Attention机制的算法(图4).第2-4行是将序列模型隐含层状态向量的均值h′和类别关键词向量作为输入,通过公式(7)和公式(8)得到文章关于每个类别的注意力权重矩阵.第5行通过公式(9)计算得到最终的语义编码表示.
4.3 采用CNN模型构建文本向量
CNN模型的卷积核通常是经过CNN模型的训练过程得到,即卷积核是CNN模型训练参数之一.文献[5]通过引入LSTM与注意力机制对文本类别的特征向量矩阵进行计算,达到文本分类的目的.不同于上述文献[5]将注意力机制的结果构成文本向量做分类的操作,AM-CNN算法的核心思想是:将基于LSTM与注意力机制计算得到的特征向量作为CNN模型的卷积核参与计算,通过与文章的词向量矩阵进行卷积,在此基础上,通过CNN的计算实现文本分类.
首先,在类别层级上采用注意力机制,得到的特征向量作为CNN模型的卷积核.其中,CNN卷积的步长选择为1,卷积核的大小为L×1×d,使用CNN的目的是对文档进行特征提取,再根据提取出的特征对其进行分类.通过卷积操作可以得到关于文档的特征向量f∈RL×1.CNN模型图如图5所示.

图5 CNN算法图Fig.5 Convolutional neural network algorithm
在得到特征向量后,希望能够利用这些向量做分类,但由于计算量过大且容易拟合,所以选择对这些特征矩阵进行池化,在这里选择的是最大池化(max pooling).
在池化过后,得到L个提取特征的向量,将这L个向量拼接起来,就是最终所需的文本向量.最后的工作就是将得到的文本向量通过softmax来判断这个文本属于哪一类.
在本文,设softmax函数的输入数据d是维的向量ZP,这样softmax函数结果也是一个d维的向量(设为Y),每维的值是0到1之间.softmax函数是一个归一化的指数函数,其定义如下:
(10)
利用该函数输出L个取值在0到1之间的数值,这个数值代表了输入文章的样本属于某个类别的概率.选择输出概率最大的,作为文本分类的结果.
5 实 验
5.1 数据集
实验所用数据集是某省高级人民法院网站公开的法律文书(即判决书),为真实数据集.数据集涵盖了刑事、民事、商事、行政共计200000多篇案件文本.为保证计算的有效性和规范性,在进行关键词提取和文本分类之前,先对原始数据进行了处理,剔除掉乱码等无效的文本片段,最后获得有201458个有效文本段.在这个数据集中存在数据不平衡的情况,例如诈骗、盗窃类别文章篇数较多,故意杀人、重婚等篇数较少,为了验证本模型计算的有效性,将这些有效文本中的80%作为训练集,20%作为测试集.
5.2 评价指标
实验采用内部自动评测方法来评价文本分类模型的性能.以Precision(精确率)、Recall(召回率)、F1-Score为评价指标对文本分类效果进行测评.
准确率是分类器准确识别文本的一个统计测量,计算公式如(11)所示:
(11)
召回率是指检索出的相关文档数和文档库中所有相关文档数的比率,计算公式如(12)所示:
(12)
F1值则是衡量分类器分类的准确性的指标,计算公式如(13)所示:
(13)
其中,XM表示模型分类的文本;YQ表示人工分类的文本.
5.3 实验结果分析
实验1.抽取给定类别的关键词.
在本实验中,为了获得论文中所描述的类别标签,选择文中所给出的tf-idf模型和交叉熵结合的方式抽取关键词.对于给定的数据集,确定了包括婚姻家事、盗窃、诈骗、电商等12种类别的案件.对于每个类别,使用tf-idf和交叉熵方法得到的最能代表每个类别的k个关键词,在实验中选取k为3,表2列举了几种类别案件的关键词.

表2 类别关键词选取情况Table 2 Selection of category keywords
实验2.LSTM模型维度参数对文本分类结果的影响.
对给出的文本进行分词,并将得到的词通过word2vec转化成词向量.在用LSTM模型处理词向量时,为了验证不同的词向量维度对文本分类的影响,做了以下的实验:在输入的时候,统一将初始的词向量从100维开始调节,采用深度学习框架keras1进行实验,分别选取100,150,200,250,300,350,400这7个维度数进行实验,以选取最优的向量维度.图6给出了AM-CNN模型在不同向量维度值下各自的准确率Precision、召回率Recall和值的对比情况.图7则是取不同向量维度下AM-CNN模型运行的时间对比图.


图6 不同向量维度分类效果对比Fig.6 Classification in different vector dimensions图7 不同向量维度下的运行时间对比Fig.7 Classification in different vector dimensions vs. runtime
由图6可以看到,随着向量维度的增加,分类效果有较明显的上升,但当增加到300维之后,再往上增加F1值只提高0.17%和0.3%,分类效果的提升并不明显.结合图7,在向量维度增加到300维之后,同样花费的时间也较多,计算的效率相对较低.因此,考虑到计算效率和分类效果方面,在后续实验中,统一将向量维度调整为300维.
实验3.CNN卷积核大小对文本分类效果的影响.
为了验证本文中计算出的卷积核是否比直接训练的(即不通过注意力机制直接通过LSTM模型后训练给出卷积核)更合适,对卷积过后的分类结果进行了比对.
实验中选取2×2、3×3、4×4及5×5的卷积核与AM-CNN的卷积核进行比对,得到的准确率、召回率和F1值结果如图8.该图显示,对于训练给出的2×2、3×3、4×4及5×5卷积核,4×4的卷积核F1值相对较高,为82.7%,但相比起AM-CNN卷积核的结果,F1值相差2.1%,结果证明本文模型的卷积核是可行的且效果较好.
实验4.AM-CNN模型与其他分类算法的比较
为了验证本文提出的AM-CNN模型与其他分类算法相比,在不平衡数据集的分类效果上是否具有优势,本组实验选取了C-LSTM模型[3]、WL模型[9]、RA模型[10]进行分类.图9给出了AM-CNN模型与其他三种模型的分类效果对比.
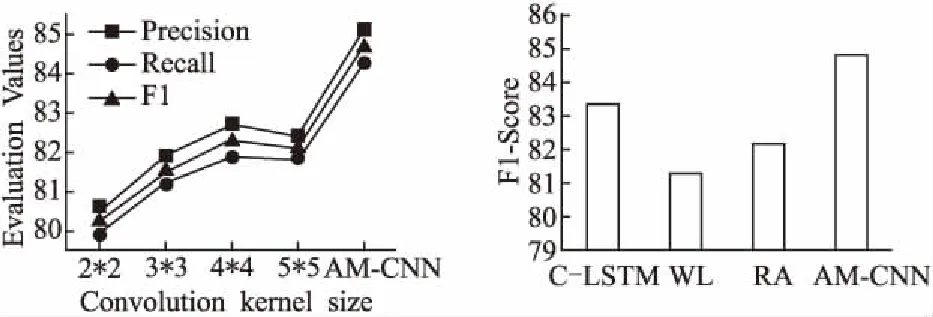

图8 不同卷积核的分类效果对比Fig.8 Classification in different convolution kernels图9 不同模型的分类效果对比Fig.9 Text classification in different algrithms
统计不同算法的F1值得出:AM-CNN算法模型相比C-LSTM模型、WL模型、RA模型的F1值分别高出1.4%、3.5%和2.6%,表明这个分类模型是有效的.AM-CNN通过突出类别特征向量改善了在不平衡数据集上小类别数据分类不准确的情况,使分类效果进一步得到优化.
6 结 论
针对大规模真实文本数据集中,类别数据不平衡而导致大多数文本分类模型训练存在偏差,分类结果不准确的情况,本文提出一种注意力机制支持下卷积神经网络模型AM-CNN,实现对大规模的不平衡文本数据进行分类.在真实的法律文本数据集上,通过与现有的C-LSTM模型、WL模型和RA模型进行实验比较可知,采用本文提出的AM-CNN模型,在不平衡数据上的分类效果上体现出一定优势.在下一步的工作中,将研究如何对本文所提算法进行改进,以支持大规模文本的信息抽取技术.
