增强碰撞体算法优化的自编码神经网络
2019-05-05陈志国王凯宇
冯 文,陈志国,傅 毅,王凯宇
(江南大学 物联网工程学院,江苏 无锡 214122)
1 引 言
近些年来,人工神经网络成为了机器学习的研究热点,随着近些年不断的发展各种神经网络被提出,卷积神经网络、深度信念网络、自编码网络等都是常见的网络.自编码神经网络作为一种简单高效的网络,能有效的从数据中提取有效的信息用于分类,自编码利用编解码过程来求得最能表示原数据特征的参数,为提高其特征提取的能力,有很多的学者对其进行了改良和应用.Vincent 等人提出了去噪自编码[3],Chen M等人对去噪自编码进行改进提出了边缘化去噪自编码[8],南京大学周志华等人提出了基于树的自编码[10],剑桥大学O.Chen等人也提出了卷积自编码[4],在特征提取上也取得了良好的效果.自编码作为一种非监督学习,广泛的用在了计算机科学及其相关领域[9,12,13].
与此同时优化算法也发展迅速,并且被广泛的用于各种问题,优化算法可以被分类为两大类,第一类数学方法类,例如:拟牛顿法、动态规划等.另外一类就是元启发算法例如:粒子群算法、遗传算法、蚁群算法等.智能算法在求参数的最优解中有着良好的应用.而神经网络训练的过程也是利用一系列求参过程取得最优的参数,所以有很多工作将智能算法和神经网络相结合.Yin H等人将自编码和粒子群相结合用于预测股票的走势[11],吴志攀等人将粒子群算法和BP网络相结合用于车牌识别[5],董晴等人将自编码和粒子群算法结合提出了PDNN[1],将Extreme Learning Machine(EML)和自编码网络结合提出了EML优化的深度自编码[2].
董晴等人在将粒子群算法和自编码网络相融合用于邮件分类时,垃圾邮件的召回率较低.在该实验中将粒子群融入自编码网络的时候,先将自编码网络的参数求出后,再用softmax对所得到的数据分类.本文在针对垃圾邮件召回率较低的情况下利用碰撞算法来对自编码和softmax的参数进行寻参.碰撞算法相对于粒子群算法有着较大不同,粒子群算法在寻参过程中每个粒子是相互独立的互不影响,但是碰撞体算法在寻参过程中每个碰撞体是相互影响的.本文在融入方法上也采取了较为不同的方法,在融入过程中每对自编码的网络参数进行一次寻参后,都将对softmax进行寻参.通过在垃圾邮件分类数据库上与PDNN相对比本文的方法有着较好的性能.
2 相关工作
2.1 自编码神经网络
自编码神经网络是一个非监督模型的网络,可以从无标注的数据中学习特征,是一种以重构输入信号为目标的神经网络,他可以给出比原始数据更好的特征描述,具有较好的特征学习能力,在实际应用中经常用自编码神经网络生成的特征来取代原始数据,以得到更好的效果.一个自编码神经网络模块是一个三层神经网络,其中包含了L1输入层,L2隐藏层(也叫编码层),L3输出层(也叫解码层).输出层和输入层的维度相同,自编码网络的作用就是尽可能更好的去表征原始数据,为了较好的表征,一般情况下L2层的维度不等于L1层的维度.假设样本有m个属性(x1,x2,…,xm),编码层有n个神经元,解码层的输入为(y1,y2,…,yn).该自编码网络的结构图如图1所示.

图1 自编码神经网络的结构图Fig.1 Structure Autoencoder neural network
自编码网络的编码层的输入:
h=f(w1*x+b1)
(1)
其中参数w1是输入层到解码层的权值(是一个矩阵),b1是输入层到编码层的偏置(是一个向量),函数f为激活函数f(x)=1/(1+exp(-x))
解码层的输入:
y=f(w2*x+b2)
(2)
其中参数w2是编码层到解码层的权值,b2是编码层到解码层的偏置,函数f为激活函数f(x)=1/(1+exp(-x)).由于解码层是收到编码层的信号后去解码,尽量的还原原始信号,所以w2和w1互为转置.在编解码的过程中每个样本的代价函数为:
(3)
总的代价函数为:
(4)
其中参数t是样本的个数.在实际中很多时候是通过使总的代价函数最小来优化参数.
2.2 增强碰撞体算法(Enhanced Colliding Bodies Optimization,ECBO)
2.2.1 碰撞体算法(Colliding Bodies Optimization,CBO)
增强碰撞体算法是对碰撞体算法(Colliding Bodies Optimization)改进,碰撞体算法是Kaveh[6]等人2014年提出的一种简单高效的启发式算法.该算法是根据物理学中物体之间碰撞所产生的动能变化所得到的.该算法中每个候选解都是一个碰撞体,并且会对碰撞体赋予一个质量,碰撞体分为移动和静止的两组,移动的碰撞体将会去碰撞静止的碰撞体,这使得移动和静止的碰撞体就会移动到更好的位置.
碰撞体将会以下列公式初始:
xi=xmin+rand(xmax-xmin)i=1,2,3,…,n
(5)
其中xi是第i个碰撞体,xmax和xmin是变量的最大值和最小值,rand是取0到1的随机数,n是碰撞体的总数.
粒子的质量公式为:
(6)
其中fit(k)代表第k个碰撞体解的对于目标函数的误差,n是碰撞体的数量,从上述式子可以看出,当解的误差越小的时候,碰撞体的质量也会越大
将碰撞体按照解的误差升序排列,将排列后的碰撞体平均分成静止和移动的两部分,如图2(a)所示.其中移动的碰撞体都有一个与之相对应的静止碰撞体与之形成“碰撞对”(如图2(b)所示).误差小的部分被分为静止的部分,这些碰撞体在碰撞前的速度为0.
(7)

图2 (a)升序排列后的碰撞体,(b)碰撞对Fig.2 (a)CBs sorted in increasing order and(b)colliding object pairs
剩下部分的碰撞体就被划分体为移动部分,该部分的误差较大,移动的碰撞体会以一定的速度向静止的部分移动并碰撞静止的碰撞体,使得静止部分的碰撞体的位置发生改变.移动的碰撞体在与静止碰撞体之间发生碰撞之前速度为:
(8)
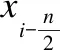
(9)

(10)

(11)
其中iter是当前循环次数,itermax是最大循环次数.从上式可以知道,随着循环次数的增加,碰撞体也会也越来越接近,这对于局部搜索和全局搜索都是一个很好的平衡.
当上诉碰撞发生后,各个碰撞体的位置也会发生改变,移动碰撞体在碰撞后的位置:
(12)

在碰撞之后静止碰撞体的位置如下:
(13)

图3 增强碰撞体算法的流程图Fig.3 Flow diagram of ECBO
2.2.2 增强碰撞体算法(Enhanced Colliding Bodies Optimization,ECBO):
增强碰撞体算法[7],是在碰撞体算法的基础上进行了升级,使得碰撞体算法收敛更快同时也能一定程度上解决局部最优问题.
加速收敛:在碰撞体每次碰撞前将历史最优的部分解的相关信息存储起来,用这些解来代替当前最差的解.
逃离局部最优:每次碰撞后随机生成一个随机数rnd,如果这个随机数小于一个特定参数pro(手动设定),那么碰撞体的某一维度就会根据下列公式发生改变:
Xij=Xj,min+rand*(Xj,max-Xj,min)
(14)
Xij是第i个碰撞体的第j个变量,Xj,max和Xj,min分别是该变量所能取值的上下限.为了保护碰撞体的结构只改变碰撞体的一个维度,这样的机制使得碰撞体可以向着更多的空间搜索,这就提供了更好的多样性.增强碰撞体的流程图如图3所示.
3 ECBO优化的自编码网络
在自编码网络中使用ECBO来寻找适合自编码网络表征输入特征的权值,在网络的后面加上一个softmax作为分类器.同时将自编码网络的代价函数和softmax的误差函数加权求和来作为碰撞体寻参时的一个指标.在[1]中,先将分类器的参数固定,利用指标函数将指导算法寻找一个适合自编码的权值矩阵,然后再用BP算法来求得softmax的参数.
Softmax是一种常见的分类器,是对sigmoid的一个扩展,在神经网络中是一种很常见的分类器,多用于多分类问题中.Softmax的输入是一系列的特征,softmax会根据训练所学到的参数对是输入的特征进行判断,假设是一个k分类问题,那么softmax就会对特征进行判断,给出属于每个类别的概率.若有样本[(X(1),Y(1)),(X(2),Y(2)),…,(X(n),Y(k))],n是训练样本的个数,k表示样本一共有k类.P=(Y=j|X;θ)表示在softmax的参数为θ时输入为X时,softmax将样本判断为类别j的概率为p,所以softmax的输出为:
(15)
θ为softmax的参数矩阵,是一个k行m列的矩阵,k是类别数,m是样本特征的维度,由(15)最终可以得到一个和为1的概率向量,该向量的每一行的值表示属于每个对应列的概率.在实际中为了以防θ的值过大导致过拟合,常常会对softmax的误差函数加入一个正则项,softmax的误差函数在加入正则项后为:
(16)

在本文中,我们将使用ECBO来优化自编码网络的权值矩阵,同时由于在softmax中使用BP算法求解参数时往往会因为学习率的问题存在调参问题可能会错过最优解,所以本文中同时也利用ECBO来求得softmax的参数.本文中采取和[1]中一样的指示函数(将自编码网络的代价函数和softmax的误差函数加权求和):
C=ηSUM(X,Y)+μJ(θ)
(17)
同时因为指标函数中是受自编码代价函数softmax的参数共同影响的,所以在本文中采取了和[1]中不一样的做法.本文中将自编码和softmax置于一个大的循环中,每次自编码寻参过后都接着去寻找出softmax的当前最优参数,最后利用贪心的做法选出最优的参数组合.由于SUM(X,Y)的值较大,所以在实验中η的值会比较小,μ的值会比较大.
2)初始化n组碰撞体,其中每个碰撞体都是softmax的候选参数
3)由(17)来计算m组碰撞体中每个碰撞体的评价函数,对其升序排列,把碰撞体分成移动和静止的两个组,按照(6),(7),(8)对碰撞体进行质量和速度的计算,并记录下最优的几个碰撞体.
4)while iter<=itermax:
本文算法的描述如下:
1)初始化m组碰撞体,其中每个碰撞体都是自编码中的候选权值
① 发生碰撞根据(9),(10),(12),(13)来计算碰撞后的速度和位置
② 再次执行㈢并且利用最优的碰撞体来代替最差的碰撞体
③ 进入计算softmax参数部分:用公式(17)来计算n组碰撞体中每个碰撞体的评价函数,对其升序排列,把碰撞提分成移动和静止的两个组,按照(6),(7),(8)对碰撞体进行质量和速度的计算.
④ 发生碰撞根据(9),(10),(12),(13)来计算碰撞后的速度和位置
⑤ 再次执行③并且利用最优的碰撞体来代替最差的碰撞体.
End
5)分别得到碰撞体的最优解,作为自编码的权值和softmax的参数,最终得到一个基于ECBO的自编码网络.
算法的流程图如图4所示.
4 实验结果与分析
实验数据库
为了验证本文中所诉方法的有效性,本文的方法在几个公共数据库上进行了多次实验.本文所用的数据库有邮件分类问题中常用到的Ling-Spam数据,UCI的公共数据库iris和glass,表1对各个数据库进行基本的介绍.
本文中实验,iris和glass数据随机抽选2/3作为训练,剩下1/3作为测试.Ling-Spam数据库中正常邮件有2412封,垃圾邮件有481封,在实验中随机抽取其中320封作为训练(其中正常邮件160,垃圾邮件160),240封作为测试(正常邮件200,垃圾邮件40).
首先实验中,为了证明每次对自编码寻参后就去对softmax寻参比[1]中所用先确定自编码参数然后再去对softmax求参的效果好,在实验开始对iris和Ling-Spam进行测试.ECBONN*代表[1]中类似的做法,ECBONN代表本文的方法,在两个数据库中的结果如表2所示:数据是在Ling-Spam数据库中各自运行100次然后取平均值,参数pro都是取值0.35,η取值10-11,隐藏层神经元个数取10,碰撞体个数取10.μ取值为1迭代次数为200次,碰撞体对自编码权值求参时碰撞体的初始位置范围时[45,-45],碰撞体对softmax求参时碰撞体的初始位置范围是[4,-4],λ取值2*10-4.实验结果中发现本文中所采取方法能取得更好的效果,并且更稳定.而ECBONN*在运行100次中还存在不稳定的情况有时候会求参较差(出现效果差或者不学习的情况).
表1 实验中所用到的数据库的介绍
Table 1 Introduce of database

数据集名称样本数属性数分类数Iris15043glass214106Ling-Spam289352
表2 Ling-Spam数据库下ECBONN*和ECBONN的对比
Table 2 Results of ECBONN* and ECBONN in Ling-Spam

算法指标Ling-Spam正常邮件垃圾邮件ECBONN∗查准率98.02%83.01%召回率91.1%89.9%F192.9%85.4%ECBONN查准率98.71%91.92%召回率98.33%93.55%F198.52%92.70%
因为iris数据库的属性数量比较少,所以在iris上也进行了测试,比较二者的稳定性和学习能力,对iris数据各自运行100次后,取accuracy的均值,结果如表3所示.结果为在iris数据库中各自运行100次然后取平均值,参数pro都是取值0.1,η取值10-8,隐藏层神经元个数取20,碰撞体个数取10.μ取值为1迭代次数为400次,碰撞体对自编码权值求参时碰撞体的初始位置范围是[4,-4],碰撞体softmax求参时碰撞体的初始位置范围时[9,-9],λ取值10-4.实验结果中发现本文中所采取方法在属性数量较少时能取得更好的效果,并且更稳定.实验中还发现η的取值较大时,100次中的结果波动较大,当η取值较小时波动会更小.
表3 iris数据库下ECBONN*和ECBONN的对比
Table 3 Results of ECBONN* and ECBONN in iris

算法accuracyECBONN∗85%ECBONN96.04%
将本次实验在Ling-Spam的结果与[1]在Ling-Spam中的实验数据相比较如表4所示,发现本文的方法拥有更好的结果,特别是在垃圾邮件的召回率上有了很大的提升,除了垃圾邮件的查准率略比PDNN低一点,其他指标都有一定的提升.实验中指标函数(17)的值随着循环次数的变化如图5所示.Ling-Spam数据库实验中参数所取参数和表2做对比实验时所取的参数一样.
表4 本次实验在Ling-Spam上的结果与[1]中的相对比
Table 4 Results in Ling-Spam compare with the results of [1]

算法指标Ling-Spam正常邮件垃圾邮件PDNN查准率94.98%92.01%召回率97.85%74.25%F196.39%82.18%RBFNN查准率93.75%84.38%召回率97.50%67.50%F195.59%75.00%BPNN查准率94.54%70.64%召回率91.20%69.00%F195.59%69.81%ECBONN查准率98.71%91.92%召回率98.33%93.55%F198.52%92.72%
将本次实验数据在iris和glass数据库上的结果和[2]中的实验数据相比较如表5所示,iris和glass在实验时指标函数的值随着循环次数的变化如图5所示.
表5 iris和glass数据库的实验结果
Table 5 Results in iris and glass

数据库DELMEDBNRBFELMECBONNiris95.78%94%97.46%95.68%96.0.4%glass80.87%81.27%74.51%68.00%83.52%

图5 实验时,指标函数值随着循环次数的变化Fig.5 Change of indicator function while the iteration growing
iris在实验中和表3做对比实验时参数相同.glass实验结果是在glass数据库中各自运行100次后取平均值,参数pro都是取值0.1,η取值10-9,隐藏层神经元个数取30,碰撞体个数取10.μ取值为1迭代次数为400次,碰撞体对自编码权值求参时碰撞体的初始位置范围时[6,-6],碰撞体对softmax求参时碰撞体的初始位置范围时[6,-6],λ取值2*10-4.
5 结束语
本文结合增强碰撞算法提出了ECBONN,利用碰撞算法来优化自编码机的权值和softmax的权值,利用碰撞算法中各个粒子的相关性来求得适合自编码机和softmax的权值,通过在一些公共数据库上进行实验,验证了算法的可行性,与其他方法相对比有着较好的性能.
