基于加权语义网的改进文本相似度计算方法
2019-05-04张弛张贯虹周艳玲
张弛,张贯虹,周艳玲
(合肥学院 计算机科学与技术系,安徽 合肥,230601)
随着互联网的普及和使用,互联网中文本数据的产生正在以指数级的速度在增长,如何有效的管理和维护好这些文本数据,能够实时、高效的从这些海量文本数据中挖掘对社会生产、生活有价值的信息,已经成为文本聚类、信息检索、问答系统等诸多研究领域知识管理者和研究者所要亟待解决的问题。
文本相似度计算是文本数据挖掘中需要解决的关键问题之一。传统的文本相似度计算方法是基于统计特征的TF-IDF算法[1-3],该方法是将文本表示为一个空间向量的形式,向量中每个元素值为特征词频(term frequency,TF)和逆文本频率(inverse document frequency,IDF)的乘积,这样就可以通过计算向量之间的差异来衡量文本之间的相似性。这种方法的优点简单,并且可以排除文本中低区分度词和高频词的干扰。但是这种方法也忽略了特征词本身一般都具备丰富的语义,而且词之间的语义关系、词的频率和词的上下文结构信息等都将影响着对文本相似度计算结果的准确性[4-6]。
近年来,随着复杂网络科学研究的发展,在自然语言处理研究领域中也发现了小世界特性[7],为国内外学者研究文本的相似度计算提供了新的思路。文献[8-10]等基于语义知识库的方法,将特征词映射成概念或义项,通过概念或义项的语义相似性、相关度和语义距离等来间接计算特征词之间的相似度,并通构建加权文本复杂网络,使用复杂网络的物理结构特征如节点度、介数、聚集系数等,进行关键词的提取研究。文献[11-12]根据特征词之间的语义关系构建文本复杂网络,然后利用复杂网络社区的结构特性,使用社区挖掘算法来进行特征选择。文献[13-14]引入相似性和相关性对词语语义关系进行复杂网络构建,通过调节各个参数的分配权重进行特征项选择。虽然这些研究已经取得较好的成果,但它们都未考虑节点对全局网络的影响,忽略了在文本复杂网络中特征词的位置、共现频率、全局统计信息等因素的重要性,导致文本网络构建中边权重计算方法不科学,结果不准确,使得最终计算结果存在较大偏差。
鉴于特征词本身具备的丰富语义特征,文章在综合考虑了特征词间的语义相似性、统计TF-IDF值以及共现频率等因素的基础上,提出了一种基于《知网(HowNet)》语义知识词典的改进文本加权语义网络构建和相似度计算方法。该方法首先对文本进行分词、去停用词操作,以特征词为节点,以特征词的TF-IDF值作为节点的初始权重,以特征词窗口共现与窗口滑动原理建立边,基于《知网(HowNet)》语义词典将特征词映射为词典中的概念,考虑到特征词在文本中的共现系数,融合共现系数和概念间语义距离计算特征词之间边的权重,充分利用了文本的结构信息和全局统计信息。最后使用EMD距离公式计算向量化文本之间的相似度,在标准数据集上对文本进行分类实验,验证了文中所构建的算法相较于传统算法,在聚类结果上得到了进一步的提升。
1 相关理论
1.1 复杂网络特性
复杂网络是指在结构、节点类型和连接形式等方面复杂的网络,该类网络具有明显小世界、无标度等特征[15]。在复杂网络中不同的统计量能够反映不同的物理含义,对复杂网络结构拓扑的分析,能够剖析系统演化的过程和内部存在的机制,文中主要使用如下的复杂网络物理统计特征量对节点的重要性进行评估。
1)节点加权度
根据边权值是否存复杂网络在可分为无权网络和加权网络,节点的度是在无权网络的基础上定义的,是指与节点相连边的数量,反应了节点与其他邻接节点的连接情况。在加权网络中节点的加权度需是指与节点相连的节点之间边权值之和,节点的加权度可定量的表示为
(1)
其中:ωij表示加权复杂网络中节点i和j之间边的权值,节点加权度综合考虑了在加权复杂网络中节点与相邻节点之间边的数量和权重,体现了节点在网络中的局部重要性信息。
2)节点加权聚集系数
聚集系数是定义在节点三点组基础上,对于任意一个节点,聚集系数反映了在复杂网络中节点聚集情况,即节点的邻接节点之间有边的数量与它们可能存在边的数量的比值,可定量的表示为
(2)
其中:ki表示节点i的加权度;WKi为节点i的加权聚集系数,值为节点i的相邻节点之间边的权值之和,体现了复杂网络中节点间的连接强度和密度,体现了节点在加权复杂网络中的局部重要性信息。
3)节点介数
节点介数定义为在加权复杂网络中,任意两个节点之间经过特定节点的最短路径数量占所有最短路径数量的比例。节点介数反映了节点在网络连通中起到的作用,节点介数可定量表示为
(3)
其中:njk表示节点j和k之间的最短路径数量;njk(i)表示在节点j和k之间存在的最短路径中经过节点 i的路径数量。从公式(3)的定义可以看出,节点介数体现了节点在加权复杂网络中的全局重要性信息,
1.2 加权语义网
语义网是一个语义网络系统,它系统的描述了现实中词汇与词汇之间的各种语义关系[16]。因为词汇之间一般都具有丰富的语义关系,传统的直接计算文本特征词之间的语义关系是很困难的。目前,常用两种方法对特征词进行语义关系的计算,一种是基于大规模语料库的方法[17],一种是基于世界知识的方法[18],考虑到前者需要大量的语料作为训练集,使用中经常受到语料库规模的影响。文中选择了使用基于世界知识的《知网(HowNet)》语义词典进行语义复杂网络的构建,这种方法相对前者更加简单、有效。借助《知网(HowNet)》语义知识词典,将特征词转化为知识词典中的概念,这样每个特征词都将对应于《知网(HowNet)》知识库中的特定的概念。这样就可以使用概念之间的距离来间接度量特征词之间的语义联系,能够区别出不同文本特征词之间的语义相似性和差异性。借鉴文献[14]在概念层面上对距离的计算,文中对概念间距离的计算也使用语义距离、语义重合度、层次关系三个因素,利用概念间语义距离作为对应特征词之间关系强弱的衡量标准。如图1所示为基于《知网(HowNet)》语义词典的概念距离计算案例。
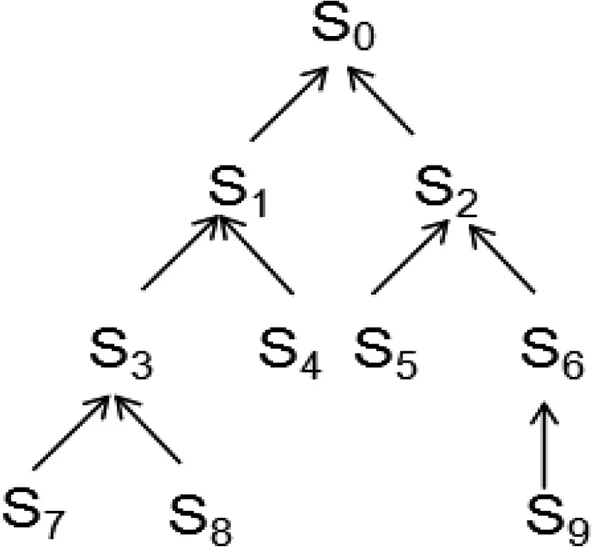
图1 语义词典中概念的距离计算案例Fig.1 A case of concept distance computation in semantic dictionary
语义距离:表示为在《知网(HowNet)》语义词典中两个概念之间的最短路径长度,文中用D(Si,Sj)表示两个概念Si和Sj之间的语义距离,值越小表示两个概念所对应特征词的间关系就越相近,以图1中节点S8和S4为例,D(S8,S4)=3。
语义重合度:表示为两个概念所拥有的共同父节点与祖先节点的数量,拥有的共同父节点数量越多,说明概念间关系越相近。使用C(Si,Sj)表示概念Si和Sj之间的语义重合度。以图1中节点S7和S4、S7和S8为例,C(S4,S8)=2,C(S7,S8)=3。
层次深度:用Hi和Hj表示两个概念Si和Sj的所在语义树中的层次深度,随着两个概念间的层次深度差增加,所对应词汇之间的的相似性就越小。
2 基于改进加权语义网络的文本相似度计算
2.1 文本特征词之间语义相似度计算
文中综合考虑词汇的共现频率权重、语义距离、语义重合度和层次深度这四个方面的因素作为语义复杂网络中边的权重。
共现频率是指两个特征词在同一个窗口中共现的次数,共现次数越多,说明在该文本中这两个词汇之间的联系也就越紧密,共现系数的计算如公式(4)所示。
(4)
其中:fij表示在文本中窗口跨度为2时特征词i和j在同一个窗口中共现的次数;fij(k)表示特征词i和j在第k篇文档中共现的次数。综上所述,文中对文献[12]提出的特征词相似度计算方法进行了改进,融合特征词共现系数,提出了在语义文本网络中特征词间的语义相似度计算如公式(5)所示。
(5)
2.2 文本特征项的加权语义复杂网络构建
加权语义复杂网络可以表示为G=(N,E,W,M)。其中N表示特征词节点的集合,N={n1,n2,…,nk},ni表示文本复杂网络中标号为i的特征词节点,k表示节点集合N中元素的个数,Si表示第i个特征词在语义词典中对应的概念。E表示文本复杂网络中边的集合,E={eij=(ni,nj)|ni,nj∈N},根据语言复杂网络的小世界特征,定义两个原始特征词若共现在一个长度大小为2的窗口中,则这两个特征词之间就存在一条边[5]。W表示边的权重集合,W={w11,w12,…,wij,…},wij表示特征词节点i和j之间边的权重,表示为特征词间联系的紧密程度。M为特征词节点的权重,Mi表示第i个特征词节点的权重。加权语义网的具体构建步骤如下:
1)对文本进行分词和去停用词后,统计特征词的TF-IDF值,作为特征词节点的初始权重。
2)按照标点符号对文本进行句子识别,在句子中定义窗口大小为2,构建特征词节点间的边。
3)使用语义词典对特征词进行概念映射,以特征词的TF-IDF值作为特征词节点的权重,以文中3.1节介绍的文本特征词间语义相似度计算方法作为边权值。
2.3 文本特征项权值计算
在文本复杂网络中,特征节点的重要性评估往往需要综合考虑各种指标,鉴于此,文中改进了文献[9]提出的特征节点重要性评估函数,在复杂网络特征基础上,又考虑了特征词的统计量,对特征节点的权重评估函数进行了改进,改进后的文本特征词权重计算如公式(6)所示。
CFi=(β1WDi+β2WCi+β3PCi)·TIFi
(6)
其中:CFi为文本中第i个特征词的综合特征权重指数,对WDi、WCi、PCi进行归一化处理;TIFi表示特征词的TF×IDF值;βi(1≤i≤3)为可调节参数,代表各个部分的权重,且β1+β2+β3=1。
2.4 文本相似度计算
传统文本相似度计算方法通常经过分词、去停用词后,将特征词以向量形式进行表征,然后以余弦相似度或者欧式距离公式进行衡量相似度。但是这种衡量的方法会带来一定的语义损失,造成计算的结果存在偏差。文中引入搬土距离(earth mover’s distance,EMD)[19]来对文本的相似度进行衡量,以减少计算中存在的语义信息缺失。
该方法是为了解决货物运输问题而提出的,该方法假设某种物资有m个产地分别为{A1,A2,…,Am},产量分别为{a1,a2,…,am},n个目的地分别为{B1,B2,…,Bm},需求量为{b1,b2,…,bn}。假设从产地i生产的物资运输到目的地j的运输成本为cij,运输量为xij。目标是最小化Cost(A,B),使最终的运输成本最小化。
(7)
借鉴该模型思想,可以把测试集中的文本特征词当做物资产地,词的权重作为运输量,训练集中文本特征词作为目的地,词的权重作为需求量,特征词间的相似度作为运输成本,那么将测试集中一个文本全部特征词映射到训练集中任意一个文本,所经距离总和的最小值作为文本之间的语义相似度。
(8)
相应的约束条件为
(9)
(10)
其中:Tij≥0表示文本D中的特征词wi流向文本D′中特征词wj的数值。其中c(wi,wj)为两个特征词wi和wj的语义相似度,dwi=CFi,dwj=CFj为特征词wi和wj在各自文本中的权重评估函数值。
2.5 算法流程
使用文中所提出的文本复杂网络构建和特征词权重计算方法,对文本的特征词进行特征权重计算,提高文本相似度计算结果的精度,算法描述如下:
输入:带有类标签的训练文本集 D1 和测试文本集 D2。
输出:带有类标签的测试文本集 D2。
1)对训练集D1和测试集D2分别进行分词和去停用词操作,得到初始训练集和测试集特征词集合。
2)按照3.2节介绍的方法分别对训练集D1中和D2进行加权语义网络构建。
3)对训练集D1中每篇文档的特征词,基于构建的加权语义网络计算综合特征指数CFi,并选取CFi排名靠前的m个特征词作为该文档的特征集,形成训练集数据词典。
4)对测试集中的每篇文档,按照步骤3的方法计算待分类的测试集数据字典。
5)根据步骤(4)得到的待分类测试集数据字典的每个文档特征集,使用公式(8)计算其与训练数据字典中的每一个文档的相似度,选取训练集中相似度最大的标签作为该文本的标签。
6)对测试集 D2中的每个文档特征向量,循环重复步骤(5),直到测试集中的每篇文档都确定一个类别标签为止。
3 实验验证分析
3.1 实验数据及方法
文中实验环境使用的是64位win7操作系统,CPU是Intel(R)Core(TM)i5-7200U@2.50GHz 2.60GHz,内存为8G,开发工具为jupyter notebook下的Python3.7,分词软件使用北大最新开源分词工具pkuseg-python,实验数据选取复旦大学李荣陆课题组提供的中文新闻语料作为测试数据集,从中选取农业、政治、经济、体育和环境五个类别,每个类别中各随机选取800篇。选取哈尔滨工业大学的中文停用词表,包含767个停用词,并使用《知网(HowNet)》计算中文特征词之间的相似度。
文中设置了两组实验,第一组为三种算法在同一个数据集上的对比实验,验证不同文本表示对相似度计算结果的影响;第二组实验使用三种不同的距离度量方法,分析不同距离度量对聚类结果的影响。
3.2 实验评价方法
F1值是对分类结果的综合评价指标,F1值综合考虑了查全率(precision,P)和查准率(recall,R),是两者的加权平均,其值越大表明分类的效果就越好,定义如公式(11)、(12)所示。
(11)
(12)
其中:a表示被正确分类的文档数量;b表示被判定为属于某个类别实际却不属于该类别的文档数量;c表示被判定不属于某个类别实际却属于该类别的文档数量。
3.3 实验结果与分析
3.3.1 不同文本表示的相似度计算结果
为了验证本算法的可行性,第一组实验使用三种算法进行对比实验,分别是文中所提出的基于加权语义的方法、文献[12]提出的基于复杂网络特性的方法和文献[1]提出的基于向量空间模型的方法,三种方法分别标记为:N-EMD-1、N-NET-2、N-VSM-3。实验中公式βi采用文献[8]的取值,即β1为0.4、β2为0.3、β3为0.3,特征维数取值为1 200,实验时采用 5 折交叉验证法,取这五次的F1平均值作为最终的分类结果。三种实验的文本聚类结果在各类别中的F1值和平均值如表1所示。
表1 三种算法的实验F1值结果对比
Table 1 The experimental result comparison of F1 values in three algorithms
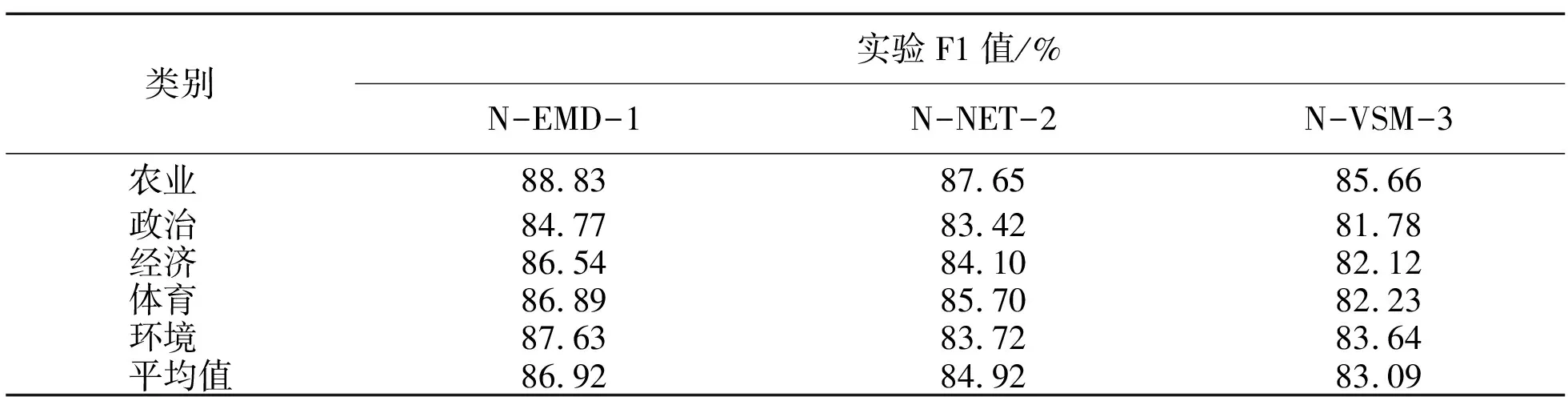
类别实验F1值/%N-EMD-1N-NET-2N-VSM-3农业 88.8387.6585.66政治 84.7783.4281.78经济 86.5484.1082.12体育 86.8985.7082.23环境 87.6383.7283.64平均值86.9284.9283.09
将实验结果的F1平均值绘制成柱状图,如图2所示。

图2 三种算法的结果对比Fig.2 The experimental result comparison of F1 values in three algorithms
从表1和图2可以看出,三种实验的结果呈现递减趋势,原因是实验N-VSM-3是基于传统统计的方法,该方法只考虑了词语出现频率信息,未考虑到词语之间的语义信息和结构信息;实验N-NET-2虽然是基于加权语义复杂网络的方法,但是该算法未充分考虑词语之间的语义信息,以及特征词的共现因素,并且需要调节的参数较多,增加了算法的时间复杂度。文中提出的N-EMD-1算法,综合考虑了词频、词共现频率特征,并且使用了EMD距离计算方法,保证了文本之间词语的是映射到语义最相近的词语,避免了实验N-NET-2综合权值相加取均值造成的结果偏差,最大程度保证了语义的集中,实验结果表明文中所提方法相较传统方法得到了一定的改进。
3.3.2 不同距离度量对文本相似度计算的影响
文章设置了第二组实验,以验证不同相似度度量公式对文本聚类最终结果的影响,分别是EMD距离公式、余弦相似度和欧式距离三种距离度量方法进行实验对比,观察它们对文本聚类结果的影响,三种距离度量分别记为N-EMD、N-Cos和N-ED。特征词向量采用全部特征词,向量元素值为对应特征词在文本中的综合特征指数,数据使用第一组实验选择的五个类别的文本,评价指标为公式(11)和公式(12)中的查全率、查准率和F1值三个指标,实验结果见表2。
表2 不同距离度量的F1值结果对比
Table 2 The result comparison of F1 values of different distance metric

方法P/%R/%F1/%N-EMD84.3889.0286.64N-ED78.6576.2677.44N-Cos72.8164.6968.51
从表2的测评结果可以看出,文中使用的EMD距离方法比其他两种相似度度量方法要好,这是因为EMD距离方法在计算相似度时充分考虑了词语之间的相似性,而不是特征词语之间相似度的简单叠加,在一定程度上保留了文本的结构信息,缩小了文本间的语义差异性,提高了聚类结果。
4 结语
文章提出了一种改进的加权语义复杂网络文本相似度计算方法,首先利用文本的统计信息,融合特征词的共现频率和语义距离特性,构建加权语义复杂网络;其次基于该语义网络,结合复杂网络的相关特性计算文本的特征词综合指数;再次根据综合特征指数值的大小,对特征项向量进行选降维处理,使用EMD距离公式对文本进行相似度计算;最后通过对不同算法和不同距离度量公式的实验结果对比分析,验证了文中所提出的方法能够充分利用文本网络中特征词节点间的语义信息、结构信息和统计信息,提高相似度计算结果的准确性。但是鉴于文本相似度计算的复杂性,本研究还有一定的局限性,例如特征词词性、词语以及词语与句子的关系等因素,还都有待于进一步的研究。
