不完备数据的反馈式极限学习机填充算法
2019-04-28牛明航
文/牛明航
1 引言
在日益信息化的今天,每个邻域都会产生大量的数据,然而在数据采集过程中,但由于噪声或其他因素经常会造成采集中的数据丢失。因此如何处理丢失数据,怎样估算缺失数据,一直是广大国内外学者关注的热点问题。本文提出了反馈式极限学习机优化算法,对缺失属性进行估算填充。
2 反馈式极限学习机估值算法研究
2.1 反馈式极限学习机估值算法
极限学习机是黄广斌教授2003年提出一个新的神经网络。这个框架是随机选择输入权重的单层前馈网络,用Moore-Penros广义逆分析决定输出权重,为解决训练时间长且容易陷入局部极值的缺点,结合最小二乘法求最优的神经网络,学习和泛化能力得到较大提升。
本文反馈式极限学习机(FELM)对极限学习机进行改进的目的是为了估值并填充不完备数据集的缺失属性值。利用实际输出与预测输出之间计算得到的误差反馈调节输入层,填充值趋于接近缺失属性的原值,从而准确率。改进后的网络模型如图1所示。
设神经网络的输入参数为X=(x1,x2,...,xn),输出参数为Y=(y1,y2,...,yk),算法步骤。步骤如下:
步骤1 初始化网络参数:设置输入权值ω以及偏置值b对网络进行初始化,ω和b的初始化值取区间[-1,1]之间的随机数。
步骤2 确定输入向量和目标输出向量:通过样本离线训练法把输入向量和输出向量添加进模型之中。
步骤3 确定极限学习机功能:回归预测和分类。
步骤4 隐藏层输出矩阵的计算:根据上述提到的介绍,利用公式(3)计算隐藏层的输出矩阵H。
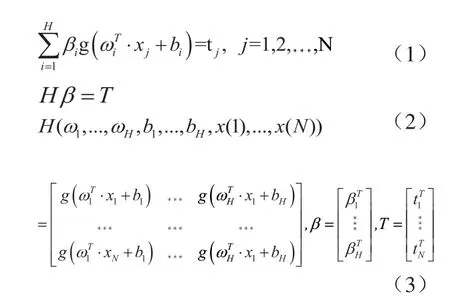
步骤5 计算输出权值:结合输出矩阵H以及期望输出值根据公式(4)对输出权重进行计算:

步骤6 误差反馈:根据实际输出值与预测输出值之间的误差,对误差进行反馈。设预测输出值为y,而实际输出值为Y,误差为E,公式如下:

步骤7 算法结束:比较求得的误差与训练样本得到误差的大小,若满足迭代停止要求,则填充缺失的属性值,否则重新调整填充值,返回步骤4。
2.2 训练原本的选取
2.2.1 互信息
在进行填补缺失属性之前对数据集中属性进行相应的处理可以避免一些属性的干扰,提高算法的准确率。因此本算法采用互信息作为属性间的衡量标准,互信息公式如下:

通过互信息的计算得到相关度较高属性,选择相关度较高的属性选择完备数据作为反馈式极限学习机的训练样本。
2.2.2 训练样本的选取
保证不完整数据至少含有一个完整属性,对于数据集中的不完备数据与任意数据的度量公式如下:

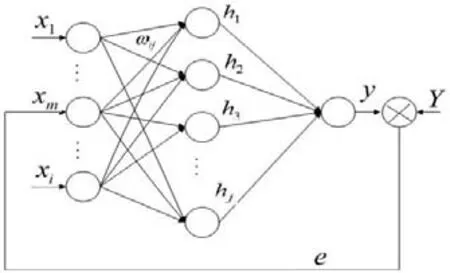
图1:反馈式极限学习机网络模型
3 结束语
本文提出一种估值填充不完备数据集缺失属性的FELM算法。该算法利用互信息进行特征评估,用卡尔曼滤波思想对极限学习机进行反馈。以完整数据作为网络模型的训练样本集,建立预测缺失属性的反馈式极限学习机(FELM)模型,基于此网络模型求得实际输出与期望输出之间的均误差,以此使用误差检索法调整填充值,提高缺失填充值准确性。
