基于互信息的立体匹配方法
2019-04-25杜思傲尹业安吴文俊
杜思傲,尹业安,吴文俊
基于互信息的立体匹配方法
杜思傲,尹业安*,吴文俊
(武汉纺织大学 数学与计算机学院,湖北 武汉 430200)
介绍一种基于灰度互信息的立体匹配方法,用于从双目图中获得视差图。该方法将灰度互信息作为衡量输入图像对相似度的指标,先构建单像素点的代价,再在代价聚合环节加入邻域点的约束,使用多方向的扫描线优化来优化代价聚合函数。反复地进行优化过程,让输出的视差图渐渐地接近于真实情况,使用随机图作为迭代初始状态,迭代固定次数后输出。灰度互信息作为代价标准,使得该方法在代价的计算环节比一般的全局匹配方法更快,并对光照具有一定鲁棒性,领域点的约束让视差图更加平滑稠密。
立体匹配;互信息;代价;优化
1 引言
获取场景深度是计算机视觉的重要课题之一,获得的深度图可以用于三维重建、SLAM、汽车导航、目标跟踪、非接触测量等。结构光、光度立体、SFM、双目立体视觉都是目前主流的方法,双目立体视觉相对于其他方法,具有设备简单、实现容易等特点。将两个同型号的摄像头并排固定,保证两个摄像头的成像平面在同一平面,控制其同时拍照成像,就构建了理想的双目立体视觉系统[1]。理论上,已知世界坐标系中某一点在双目图像中的位置,以及相机的内参和外参,计算两个点在像素尺寸上的差值,通过三角测距原理,就能获取该世界坐标系中点相对于相机的深度[1]。所以双目立体视觉的核心问题就是如何获取任一物理点在双目图像中的位置,及立体匹配。立体匹配的方法根据采用的最优化理论方法,主要分为两大类:局部匹配法和全局匹配法。
局部匹配算法主要对像素点周围小范围区域进行约束,将局部区域匹配代价最小或者匹配度最高的视差值作为输出值,特点是速度快、实现简单、精度高,但是局部匹配算法比较依赖图像中的纹理和特征,不适合低纹理区域的匹配,而且对噪声非常敏感,不具有鲁棒性。
全局匹配算法采用全局优化理论方法估计视差,Zhang Kang设计了一种一般化的代价聚合模型[2],先建立全局的代价函数,再通过最小化全局代价函数得到最优视差值作为输出值,代表性的全局算法有Graph cuts[3,4],belief propagation[5,6],DoubleBP[7]等。用于建立全局立体匹配的能量函数的方法有很多,包括水平滑动的模板匹配窗、最小生成树[8,9]、色彩权重[7]等,有些全局匹配方法在能量函数的建立上并不需要图像所有点都参与计算,通常这种做法也被称为也被称为并不需要图像括水平滑动的模板匹配窗、最小生成。
本文将使用灰度互信息构建能量函数,灰度互信息是一种评估匹配程度的标准,具有计算量小而且对光照具有鲁棒性的特点,优化方法将采用多方向的扫描线优化,多方向的扫描线可以减少扫描线优化所造成的条纹瑕疵。
2 熵和灰度互信息
2.1 随机变量的熵与条件熵
在信息论中使用熵来表示随机变量的不确定性[10],即变量的信息量,不确定性越强那么熵的值就会越大,连续变量的熵公式如下。

图像的熵则表示为图像的信息量,在使用255分度的灰度值作为变量值域时,熵表示为离散形式,离散变量的熵公式如下。

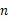
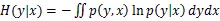



图1 双目图与联合熵图
2.2 相对熵和互信息
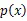
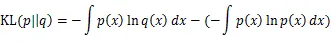
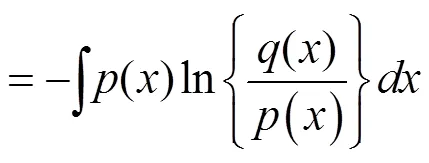

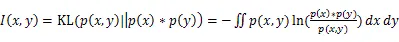

可以把互信息看成由于知道y值而造成的x的不确定性的减小,带入条件熵的公式,则获取互信息的熵和联合熵的表达式。
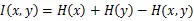
计算两幅图的灰度互信息是比较两幅图相似程度的重要指标,灰度互信息可以在计算机系统中构建256*256的查询表,所以使用灰度互信息构建每个像素的代价函数可以从256*256的表中查询对应的代价值,极大地降低了计算成本。
3 代价函数与代价聚合
连续系统的熵和联合熵为积分形式。
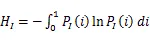
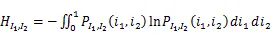
在灰度值只有0-255的图像系统中,熵和联合熵都可以简化为离散的求和形式,其中图像灰度值空间的熵如式(10)。

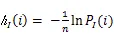
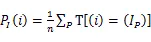
相似的联合熵也有对应的离散表达式。
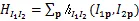
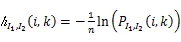
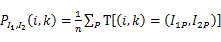
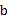
加入高斯滤波的熵和联合熵的公式如下。
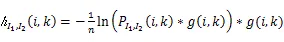
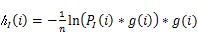
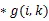

图2 联合熵计算流程图
3.1 代价函数

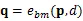
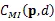

现在就有了图像中每个点对于不同视差值的代价函数,整体的匹配代价就是所有像素点代价的和。如果逐像素点地优化每个像素的代价函数使其最小化,将无法考虑邻域像素点间的约束,因为图像会受到光照和噪声的影响,左右图对同一位置的值可能不同,获得的视差图可能难以连续稠密,甚至产生大量误匹配的情况,所以需要将图像中像素间的约束加入到代价计算的环节,引入代价聚合环节。
3.2 代价聚合
如果不考虑像素间的约束,整体的代价就等于每个像素代价值的简单叠加,即下式。
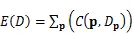


加入了正则化项的代价聚合函数如下。

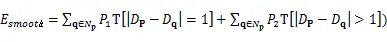
4 多方向的优化
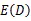
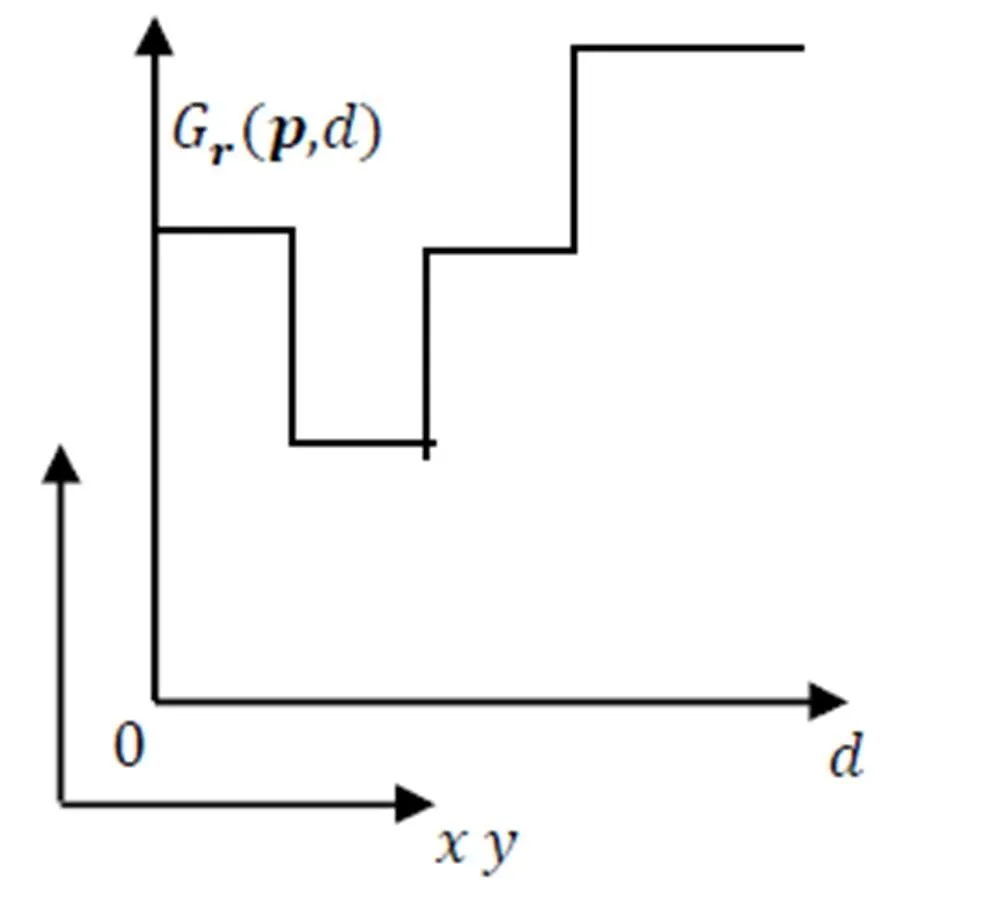
图3 单方向的扫描线优化图

图4 多方向的优化图

图5 WTA原理图



其中单方向的代价函数如下。

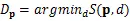
5 迭代和输出
5.1 迭代优化

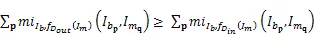
在迭代的第一步没有可用的视差图,所以迭代第一步的输入视差图可以是任意一张图,通常的做法是使用一张随机图作为迭代的初始条件,随机图可以保证迭代的第一步可以有效地使代价下降,使得后面的迭代可以向期望的方向进行,程序迭代流程图如下。
图6 程序迭代流程图
5.2 视差图输出
因为给定的初始条件不同和双目图像内容不同,所有每次迭代代价下降的趋势会有差异,但是通过实验数据观测,五次迭代后输出的视差图就没有显著变化,互信息值趋于稳定,所以本文实验选择相对保守的迭代次数,所有数据集都是迭代优化五次的结果。
6 实验数据
本文使用的双目图像数据集来自http://vision.middlebury.edu/stereo/eval/,硬件选用AMD Ryzen1600处理器,两路8G DDR4 2400Hz内存,显卡为GTX1050TI,软件平台为Ubuntu18.04操作系统,Cmake编译器,OpencCV3.2图像处理框架,未使用并行计算框架和算法。

图7 本文实验结果的视差图

图8 局部匹配算法SAD的视差图
使用cvkit软件测试视差的数值,除了边缘误匹配点和无效匹配区域,大部分区域视差值的误差很小。


图10 本文算法使用不同输出的视差图
边缘的误匹配点的原因有很多,有可能来自于图像的噪声、算法的正则化项、代价模型等,在保持细节和保持完整稠密中本文算法选择了偏向后者。本文的视差图都是左视差图,所以视差图的左边区域会有大面积无效区域,属于正常情况。
7 结束语
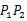
对于低纹理区域也能有比较好的效果,基本不会有局部匹配算法中低纹理区域匹配出现大面积空洞的情况,这是全局匹配对于局部匹配最明显的优势,将全局点都带入代价计算环节,在代价聚合环节加入邻域点的约束,让匹配算法可以像素点视差的计算考虑到图像整体的内容,除了邻域点的约束外Qingxiong Yang还提出一种多尺度间的约束方法[8],但是全局匹配的代价也是巨大的,参与代价计算的点会非常多,而且计算量会随着图像尺寸指数型增长,计算步骤也比较复杂,计算成本比较高,所以如果需要投入到实时的应用场景中,计算平台的优化和算法底层的优化就会十分重要。
单一的左图作为基准图右图作为匹配图的策略,对于右图中的遮拦点无法很好地估计视差,会出现错误匹配值,甚至是没有匹配结果,所以将左右图对应基准图和匹配图的策略调整,生成左、右视差图,然后通过视差图后处理[11],对遮拦区域的点进行估计,得到完整的视差图,这也是立体匹配算法领域中常用的手段,对于不同的匹配算法可以选择合适的后处理的方法,用来解决不同匹配算法的缺陷。
[1] Kaehler Adrian,Bradski Gary. Learning OpenCV3[M].O Reilly Media,2016. 704-710.
[2] Zhang Kang,Fang Yuqiang,Min Dongbo,et al.The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)[C]. 2014. 1590-1597.
[3] Boykov Y,Veksler O,Zabih R.Fast Approximate Energy Minimization via Graph Cuts[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2001,23(11).
[4] Kolmogorov V,Zabih R.Computing Visual Correspondence with Occlusions using Graph Cuts[J].IEEE International Conference on Computer Vision,2001,I:508-515.
[5] Sun J,Zheng N-N,Shum H-Y.Stereo Matching Using Belief Propagation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003,25(7).
[6] Sun J,Li Y,Kang S B,et al. Symmetric Stereo Matching for Occlusion Handling[J].IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2005,II:399-406.
[7] Yang Qingxiong,Yang Ruigang.Stereo Matching with Color-Weighted Correlation[J]. Hierarchical Belief Propagation and Occlusion Handling, IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(3).
[8] Yang Qingxiong. A non-local cost aggregation method for stereo matching[C].IEEE Conference on Computer Vision and Pattern Recognition, 2012.26.
[9] Yang Qingxiong. Stereo Matching Using Tree Filtering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015,37(4).
[10]Bishop Christopher M. pattern recognition and machine learning[M].London: Springer,2011.39-45.
[11]Egnal Geoffrey,Wildes Richard P. Detecting Binocular Half-Occlusions: Empirical Comparisons of Five Approaches[J].Pattern Analysis and Machine Intelligence,2002,24(8):1127-1133.
[12]范海瑞,杨帆,潘旭冉,等. 一种改进Census变换与梯度融合的立体匹配算法[J].光学学报,2018,(02).
[13]周文晖,林丽莉,顾伟康.一种鲁棒的基于互信息的实时立体匹配算法[J].传感技术学报,2006,(04).
[14]李金凤.立体匹配算法的研究[J].黑龙江科技信息,2015,(27).
[15]罗大思,王进华.基于双目视觉的立体匹配算法研究[J].微型机与应用,2016,(20).
Stereo Matching Method based on Mutual Information
DU Si-ao, YIN Ye-an, WU Wen-jun
(School of Mathematics and Computer Science, Wuhan Textile University, Wuhan Hubei 430200, China)
This paper introduces a stereo matching method based on grayscale mutual information, which is used to obtain disparity map from binocular map. In this method, the gray-scale mutual information is used as an index to measure the similarity of the input image, and the cost of the single-pixel point is constructed. Then the constraint of the neighborhood point is added in the cost aggregation, and finally the multi-directional sweep line optimization is used to optimize the cost aggregate function. Repeating the optimization process is to make the output disparity map gradually close to the real situation. This method uses a random graph as the initial state of the iteration, iterates a fixed number of times and output. Gray-scale mutual information as a cost criterion makes the method faster in the calculation of the cost than the general global matching method, and has certain robustness to illumination. The constraint of the domain point makes the disparity map more smooth and dense.
stereo matching; mutual information; cost; optimization
尹业安(1959-),男,教授,博士,研究方向:模式识别与计算机系统集成.
TP391.4
A
2095-414X(2019)02-0057-08
