基于项目协同过滤算法的中国音乐数据库系统设计
2019-04-23
(宝鸡职业技术学院 学前教育教研室,宝鸡 721000)
0 引言
随着互联网的发展,信息超载[1]在人们的日常生活中越来越严重,信息超载的出现给生产和日常生活带来了太多的不便[2]。例如,越来越多的音乐曲目增加了搜索优选歌曲的难度,通常情况下,用户会随机听音乐播放器中已存在的音乐,但是当涉及到一些特殊场合时,随机模型可能无法满足用户的实际需求,这就需要特定的过滤算法,从海量的中国音乐数据库歌曲中进行提取,并为用户推荐特殊的个人播放列表。
基于用户的过滤和基于项目的过滤是传统使用的推荐算法。在音乐大数据推荐过程中,基于用户的过滤将用户提供的歌曲的评分与同一首歌曲上其他用户的评分进行比较[3],并且根据与该用户较高相似度的用户的偏好来预测用户喜欢的歌曲;基于用户和基于项目的过滤识别具有相似性,但基于项目的是根据音乐本身来区分的,即按照音乐的相似性为用户做出预测,该方式前提是乐曲间相似度关系的建立,建立用户/项目矩阵是这两种技术中的主要原始数据资源,如果用户或歌曲数量过多,同时出现严重的信息不足问题,则这是一个严重的稀疏矩阵。可惜的是,这两种技术在预测过程中并不能很好地解决严重的稀疏问题。
协作过滤(Collaborative Filtering,CF)是通过收集来自其他类似用户或项目的信息来自动预测用户的相关值的有效方法,该方法已被广泛应用于电子商务系统中,如亚马逊网络,易趣网等。实践证明,CF在推荐系统中取得了巨大的成功。国内外有关CF推荐的相关工作很多。Zhou[4]等结合了基于用户的方法和基于项目的方法,通过采用来自其他类似用户和类似Web服务的历史Web服务QoS数据来预测当前用户的服务质量(QoS)值;Dutta[5]等将线性组合用于项目评分相似度和项目属性相似度,以预测对目标用户的评分,但改文章缺乏足够的实验支持其假设;Sutheera等[6]提出了一种基于项目的协同过滤方法,该方法将项目的属性相似度与评分矩阵相似度相结合。在音乐海量数据库中为用户推荐合适的音乐对象,由于在音乐推荐过程中的用户/音乐矩阵比较稀疏,因此会造成信息量的不足,为此本文提出一种更为有效的用于音乐推荐,解决音乐大数据集推荐问题的协同过滤算法。
本文所提出的协同过滤算法通过导入权重因子,将基于项目的方法与基于用户的方法相结合。在实施过程中,经过几次实验,通过改变不同影响因素来检验不同预测方法的效率;并采取平均绝对误差(MAE)方法来评估实验结果,MAE越低,证明该方法的效果越好。
1 协作过滤算法介绍
基于用户的协同过滤和基于项目的协同过滤是基于内存过滤的两种常用的协同方法,两个方法的构建过程图,如图1所示。
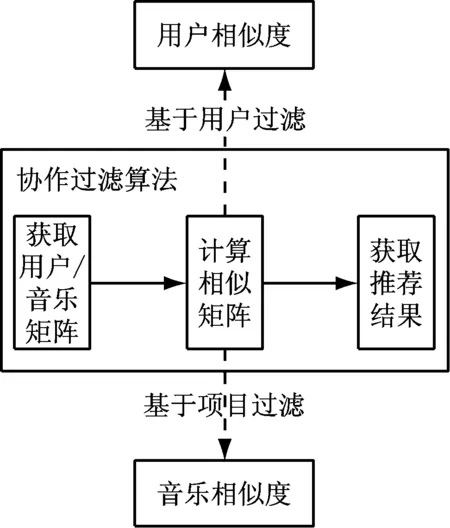
图1 协作过滤方法构建过程图
如图1所示,实施音乐推荐的一般协同过滤算法有3个主要步骤。首先,需要从原始数据集中获得用户音乐矩阵;其次,根据用户音乐矩阵计算相似度矩阵,在基于用户的协同过滤算法中,需要计算用户之间的相似度,同样,需要计算基于项目的过滤方法中音乐项目之间的相似度;最后,需要根据预测的评分值向用户推荐音乐项目。这两种算法的预测评分的计算方法是不同的,但共同目标即是获取准确的结果,以下分别对各步骤进行介绍[7-10]。
(1)获取用户音乐矩阵
从图1中可以看出,第一步是获取协同过滤算法中的用户音乐矩阵。主要数据集由用户信息和对应的音乐信息组成,描述了用户的偏好。R描述用户音乐信息,由第一用户评价的音乐的值存储在矩阵R的第一行中,当一些用户不评价音乐片段时,矩阵中相应位置的值将为零。评分矩阵如表1所示。
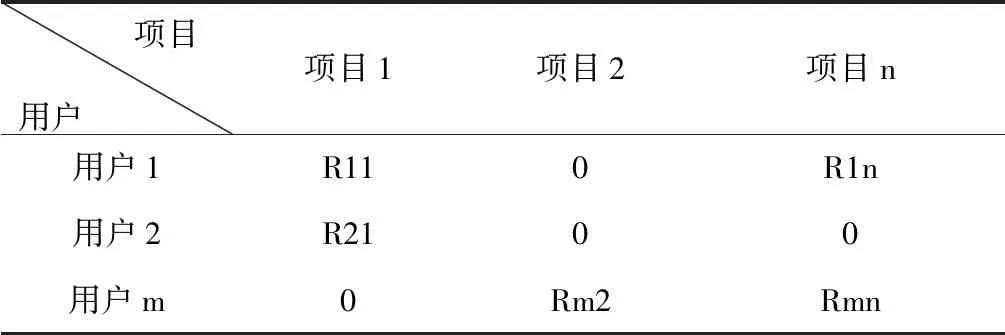
表1 评分矩阵表
(2)计算相似矩阵
第二步是计算相似度矩阵。这意味着需要找出目标用户/音乐的邻居用户/音乐项目。该步主要区别基于用户的方法和基于项目的方法,这个过程的本质是计算两个向量之间的相似性。Pearson相关性、余弦矢量相似性和调整余弦矢量相似性已经被广泛用于测量两个矢量之间的相似性。具体计算如式(1)所示。
Pearson相关性:
(1)
余弦相似性,如式(2)。
(2)
调整后的余弦相似度,如式(3)。
(3)
(3)获取推荐结果
最后一步既获取用户的最终推荐结果,通过获取的项目评级列表,并且推荐活跃用户可能评价更高值的项目。同样,有不同的技术可以预测与这两种方法相关的评级值。
基于用户的方案
在基于用户的方法中,根据用户的相似性预测评分,如下式(4)所示:
(4)
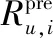
基于项目的方案
在基于项目的方法中,评分的预测与音乐项目的相似性有关,计算式如下式(5)所示。
(5)
2 一种新的推荐算法
2.1 算法介绍
本文提出一种基于用户和基于项目的共同协作算法,如式(6)为算法描述。
(6)

图2 算法程序实现图
2.2 实验分析
通过MATLAB分析及比较了本文所提出的算法以及传统的基于用户和基于项目的算法,从百度音乐网站获取数据,根据实时统计在某时刻该音乐网站数据集合包含2 231 093个独立用户,1 474 996条MSD曲目和145 384 582条播放记录,在本文的研究中选取894个用户和884首歌曲以及相应的播放记录作为所研究的数据集。假设播放次数代表了用户对音乐作品的偏好,即如果用户对于某一首歌曲相比其他歌曲播放更多次数,则用户更喜欢该音乐,并假设任何人没有播放的歌曲的评分值为零,转换规则如表2所示。
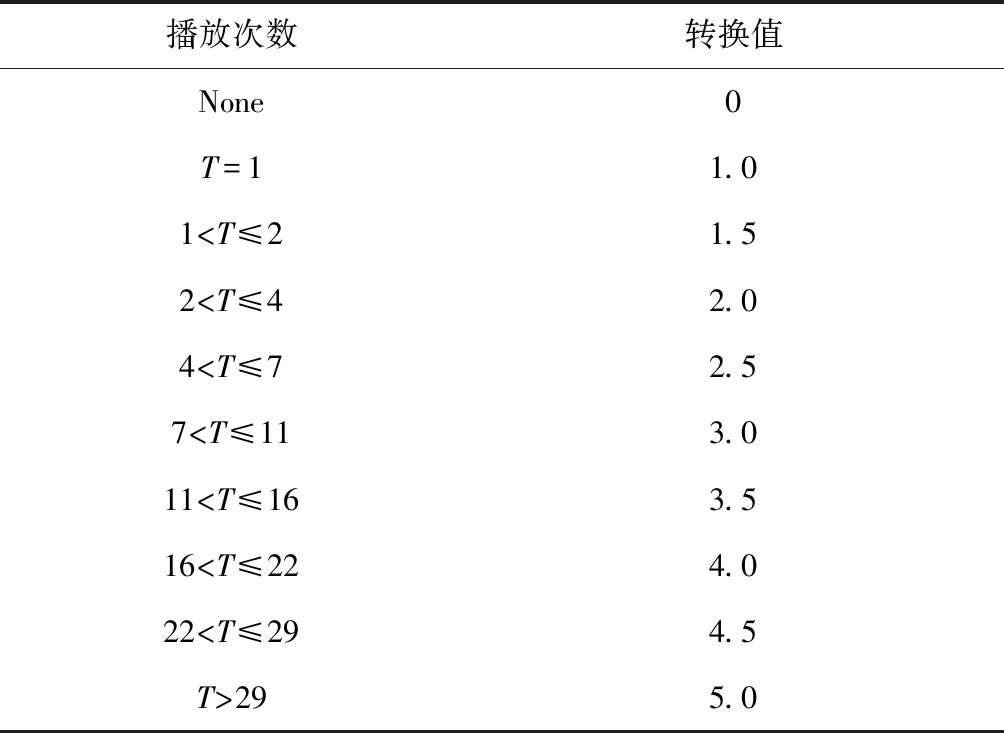
表2 转换规则表
获取用户音乐信息评分矩阵后,通过从原始数据集中随机获取训练集和测试集。然后通过使用这套训练集和测试集来进行完成实验。在实验过程中,通过本文所提出的协作过滤算法和基于用户及基于项目的过滤算法进行预测结果,在计算用户和音乐片段之间的相似度的过程中使用了调整后的余弦矢量相似度。
在以下的实验过程中采用平均绝对误差(MAE)来评估预测的准确性,MAE通过比较其预测值来评估预测的准确性。MAE的值越小,预测算法越准确。MAE的计算定义如下:
(7)
有几个因素会影响预测的准确性,例如不同的预测方法,预测过程中邻居的数量以及数据集中测试数据的百分比。
(1)邻居数量的影响结果
为了找到实验中邻居数量的影响,将其他变量设置为常量。改变所有这些预测方法的邻居数量,得到了如图3所示的结果。
(2)测试数据的百分比影响结果
在实验过程中,将邻居的数量设置为常量。并且选择了测试数据的百分比作为变量,然后得到了所有三种方法的结果,如图4所示。
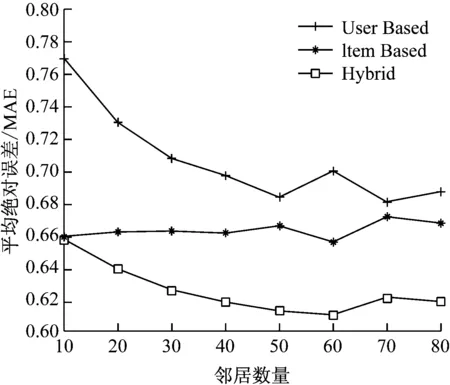
图3 三种方法的MAE随着邻居的增加而变化图
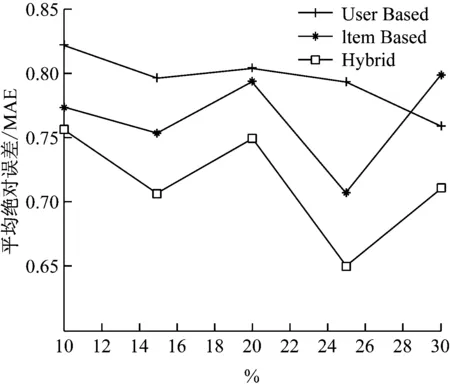
图4 三种方法的MAE随着试验数据的百分比的增加而变化图
3 总结
本文提出一种用于音乐数据库推荐的协同过滤算法,该算法将基于用户的协同过滤方法和基于项目的协同过滤方法进行结合,从理论上该方法可以通过导入权重因子参数来减少稀疏矩阵的负面影响。通过实验证明,该方法可以改进推荐效果。通过结果分析,该方法的平均绝对误差分别低于基于用户的方法和基于项目的方法,表明预测评分的准确性会提高。同时,随着邻居数量的增加,平均绝对误差得到优化;随着测试数据比例的增加而变化,MAE非单调下降;但是,当百分比为25%时,预测精度是最优的。
