基于日常会话的司法话者非语音学识别特征挖掘研究
2019-04-22关鑫
关鑫
(肇庆学院,广东 肇庆 526061)
警方或法庭使用司法话者识别技术确定截获的罪犯的语音是否源于某一已知嫌疑人,目前为止,鉴定过程中常用的话者识别特征参数有语音学内的音段和超音段特征,如嗓音音质、基频等;有语言学特征,如话语标记语、词汇语法使用情况等;有非语言学特征,如有声停顿、笑声等[1-2]。以上提及的各类型的话者识别参数中,最常用的是语音听觉和语音声学特征。语音学特征的一个特点就是他们易受外界物理环境和话者生理及心理环境影响,不可避免地会产生语音变异现象;加之罪犯语音截获环境复杂,难以完全掌控,以语音学特征作为话者识别参数的识别结论效度和信度都大大降低。为了提高话者识别结论的效度和信度,相关研究者和从业者建议结合不同的识别方法[1,3-4],或者不同学术背景的研究者和从业者彼此合作[2],或者在试验中采用自然会话作为实验材料提取并验证识别参数的效度[5]。
在此背景下,本研究采用自然会话为实验材料,挖掘具有话者识别能力的非语音学特征,并验证其作为潜在话者识别参数的效度和信度。
1 理论依据、研究方法与研究问题
该部分首先阐释挖掘非语音学话者识别特征参数的理论依据,并介绍分析方法,提出研究问题。
1.1 话语行为的五个层面与语篇信息
SAPIR[6]提出话语行为包含由低至高五个层面。第一个层面是声音本身(the voice as such),即音质;第二个层面是话语的动态特征 (speech dynamics),如语调、韵律、流畅程度、语速;第三个层面是发音(pronunciation);第四个层面是词汇(vocabulary),指词语的选择;第五个层面是个人话语风格(the style of connected utterance),指“话者个人独有的遣词成句和谋篇布局的方法、策略”①定义原文:an individual method of arranging words into groups and of working these up into larger units,SAPIR[6]强调日常会话也好、深思熟虑的演说也好,每个人都有其个人话语风格,个人话语风格从来都不是随意和偶然发生的;SAPIR还认为话语行为的每个层面都有其社会属性和个人属性,分别决定话者的社会身份和个性身份。
目前,应用于司法实践的识别参数和司法话者识别相关研究挖掘、验证的识别参数主要是分布于话语行为前四个层面上的特征。本研究旨在依据语篇信息理论,采用语篇信息分析法,挖掘位于话语行为最高层面上的具有潜在话者识别能力的个人话语风格特征。
语篇信息理论源于法律语篇树状信息结构模式[7]。语篇信息理论认为语篇是一个层级结构,表层是语言形式,底层反应语篇生产者的认知,中间是信息——能够用于交际的最小完整意义单位的命题;相对于灵活多样的表层语言形式信息结构相对稳定,相对于不易触及分析的语篇生产者认知,信息结构更易于分析,比表层语言形式更能反映语篇生产者的认知。而且,基于体验哲学和认知语言学的基本思想“现实—认知—语言”,言语人的语言创造力是言语人的认知机能对从现实世界接受到的信息进行加工处理的结果[8]。也就是说,言语人的个性化言语是言语人对世界的个性化认知的结果。因此,基于语篇信息理论,采用语篇信息分析法分析话者的话语行为比采用其他分析语篇表层语言形式的分析方法更有可能挖掘出话语行为最高层面上具有潜在话者识别能力的个人话语风格特征。依据法律语篇树状信息结构模式,宏观上语篇的信息结构是由一个核心命题及其下层信息构成的层级结构,一个命题就是一个信息单位(information unit),信息单位之间的上下层关系用15类信息点(information knot)标示,用15 个缩写疑问词表示:WT(何事)、WB(何据)、WF(何事实)、WI(何推断)、WP(何处置)、WO(何人)、WH(何时)、WR(何地)、HW(何方式)、WY(何因)、WE(何效果)、WA(何态度)、WC(何条件)、WG(何变化)、WJ(何结论)[9]。 以如下语篇[9]为例:
a人类总是将自己的发展看得高于一切。b(WY)这不外乎两个原因。 c(WY)人类……;d (WY)人类……。
该语篇包含a、b、c、d四个命题。命题b表达人类将自己的发展看得高于一切的原因,从原因角度支撑命题a,与命题a之间是何因(WY)关系;命题c和d则发展命题b,给出两个原因的内容,与命题b之间都是何因(WY)关系。
微观上信息单位由信息成分构成,包括过程、个体和环境三大类;过程以信息单位命题的谓词为中心,个体是谓词所涉及的事物,环境指以谓词为中心的过程进行的环境;过程信息成分下又有8个子类,个体信息成分下有5个子类,环境信息成分下有12个子类[9]。以信息单位“被告人周某某的行为不构成犯罪。”为例,该信息单位由5个信息成分构成,依次为环境信息成分“被告人周某某”、个体信息成分“行为”、过程信息成分“不”和“构成”,个体信息成分“犯罪”。两个个体信息成分和两个过程信息成分分属于其下的两个不同子类。
不难看出,信息成分构成信息单位、信息单位构成语篇,因此,揭示语篇生产者语篇中的信息结构模式也就是揭示话者遣词成句、布局谋篇的方式、策略中的范式,所以,理论上讲,采用语篇信息分析法分析话语行为有望挖掘个人话语风格层面上的具有潜在话者识别能力的特征。
1.2 似然率方法
由于话者识别要确定的是检材(即罪犯的话语)和样本(即已知嫌疑人的话语)之间的相似性或差异性究竟是源于同一话者还是不同话者,在国际上以Rose和Morrison为代表、国内以张翠玲为代表的专家学者都认为似然率方法符合法庭比较科学证据鉴定的要求,倡导在似然率框架内进行话者识别研究、使用似然率方法表述识别结果,并取得了丰硕研究成果。
在似然率框架内通常采用交叉验证过程评估某一量化话者识别特征或由多个量化话者识别特征构建的话者识别系统的性能[10]。设计交叉验证过程需要两组数据,测试组和背景组。测试组数据中的每位话者至少提供两段会话,用于构建同对会话比较对(被比较的两段会话源于同一话者)和异对会话比较对(被比较的两段会话源于不同话者);背景组数据由能代表背景参考话者群体的话者的会话组成,为了保证似然率计算结果的信度,至少应该包含30位话者的会话[11]。交叉印证过程似然率的计算应用AITKEN等[12]验证的多变量核密度(Multivariate Kernel Density,MVKD)似然率计算公式计算,可以采用MORRISON[13]编写的程序软件在Matlab中完成计算。
某一话者识别特征或识别系统的性能可以用基于交叉印证程序得出的同对和异对会话比较的一组似然率值绘制的Tippett图评估[10];其效度可以用基于交叉印证程序得出的同对和异对会话比较的一组似然率值计算的Cllr(log-likelihood-ratio cost)值评估[10,14-16]。
1.3 研究问题
任何类型的话者识别特征参数都要符合的一条最重要的标准是它应该具有高话者间差异性和低话者内变异性[17]。依据这条标准,首先所挖掘的特征应该具有高话者间差异性;其次所挖掘的特征应该具有低话者内变异性。因此本研究要回答的第一个和第二个研究问题分别是:(1)所挖掘的信息特征是否具有高话者间差异性;(2)筛选出的具有高话者间差异性的信息特征是否具有低话者内变异性。
挖掘出具有高话者间差异性低话者内变异性的体现话者个人话语风格的信息特征后,要在似然率框架内验证其作为话者识别参数的性能和效度,所以要回答的第三个和第四个研究问题分别是:(3)筛选出的话者个人话语风格特征作为验证话者识别参数的总体性能和效度如何;(4)筛选出的话者个人话语风格特征作为验证话者识别参数的信度如何。
2 对象与方法
本研究设计了四个实验依次回答提出的四个研究问题。实验所用话语为自然日常会话,即会话在其发生时的自然状态下被录制,录制时不对话者、录制环境、录制设备施加任何人为控制。
2.1 数据概况
本研究从法律信息处理系统语料库(CLIPS)的汉语自然会话子库中抽取了81位话者的233段自然会话。汉语自然会话子库中存储有每段会话的原始音频文件及标注了语篇信息宏观结构及微观结构的text文本文件。根据会话双方的亲疏程度及社会地位关系,库中的所有会话被归入5类会话情境:(1)彼此熟悉,社会地位平等;(2)彼此熟悉,社会地位不平等;(3)陌生人,社会地位平等;(4)陌生人,社会地位不平等;(5)好朋友或家人。
库中的所有会话都是由话者本人提供并授权用于研究使用。81位话者都是广东某高校的学生,包括27位年龄在19~21岁之间的本科生,58位年龄在21~25岁之间的硕士研究生,6位年龄在27~39岁之间的博士研究生。所有话者都说普通话,没有明显的地方方言口音。
取样的会话包括电话会话和面对面会话两种形式。话者确认所提供的会话是在其和对话人不知情的情况下用智能手机自动录音功能录制,或由第三人用录音笔、MP3播放器等录制工具录制;会话时没有刻意选择环境、话题及对话人;所提供会话音频没有经过任何编辑处理。
2.2 信息特征挖掘
首先,采用语篇信息分析法分析会话语篇信息的宏观结构和微观结构,挖掘可能具有潜在话者识别能力的个人话语风格信息特征。因为15类信息点的分布与语篇的长度密切相关,所以较短语篇中某些类信息点不会出现[9],为了保障所挖掘的语篇信息特征的高频出现率,先统计所抽样的233段会话语篇中信息点的分布情况。统计结果显示,所有会话中都包含WT(何事)信息点;而且WT(何事)信息点在233段会话包含的2 887个信息点中所占份额为51%,远远高于其他类型信息点;此外,所有会话语篇中都包含个体、过程和环境三类信息成分。
基于以上统计结果,本研究主要考察与WT(何事)信息点和信息成分相关的信息特征。JOHNSTONE[18]和BIBER[19]都指出,体现某一语言特征的有规律持续出现的绝对频率(absolute frequencies)能反映言语人的个性身份特征;AITKEN等[20]认为,相对频率(relative frequencies)作为统计数据证据更加有效;HOLLIEN[21]发现,语篇生产者无法有意识地控制语篇内的类次比(type-token ratio)②语篇类次比指语篇内不同类型的字的数量与字总数的比率。如某一语篇共包含81个字,其中“他”出现5次,“是”出现7次,“和”出现3次,其他字都只出现1次;则语篇中共包含69类字,类次比为69÷81≈0.85。特征,也就是语篇内的类次比特征可能具有验证语篇生产者的识别能力。基于以上研究成果,本研究通过考察语篇信息的频率特征和类次比特征,共挖掘了26个语篇信息频率和类次比特征。
2.3 方法
2.3.1 实验1
实验1的目的是回答第一个研究问题,检测所挖掘的信息特征是否具有高话者间差异性。具体实施步骤如图1所示,包括特征训练和特征验证两个基本步骤。
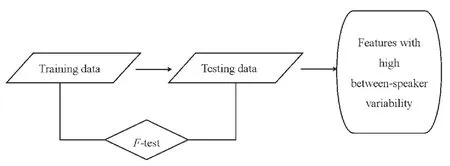
图1 实验1实施步骤
从233段会话中选取一组数据,训练所挖掘的信息特征;选取另外两组数据,用于验证经过训练的信息特征。训练数据由5位女性本科生话者的5段会话组成;第一组验证数据由22位女性研究生话者的22段会话组成;第二组验证数据包括4位男性研究生话者,每位话者贡献2段会话,同一话者的两段会话录制间隔时间最短为一个月。实验1数据的所有35段会话中,时长最短的会话长度为10 s③会话时长指会话录音的长度,包括会话双方的言语、会话过程中的沉默、停顿。,被考察话者会话语篇中包含4个信息点,共39个汉字;时长最长的会话长度为2 min 50 s;被考察话者会话语篇最多的包含25个信息点,共413个汉字。
选取具有高话者间差异性的潜在话者识别特征的常用方法是采用方差分析统计方法 (也称为F-test),以待考察特征值为因变量,考查方差分析结果中的F检验值(F-ratio),如果F值大于1,说明该特征值的组间差异大于组内差异,该特征可能具有潜在的话者识别能力[17,22-24]。基于此,实验1中采用单因素方差分析统计方法,分别以挖掘的26个待验证信息特征为因变量,使用训练数据和验证数据,在SPSS21统计分析软件中进行分析,筛选出符合如下零假设的信息特征。
零假设:该信息特征可以验证训练组数据和验证组数据中的会话都具有高话者间差异性。
如果以某一特征为因变量,分析测试数据组和验证数据组的3个单因素方差分析过程得出的F值都大于1,则说明如上零假设成立,表明被测试信息特征具有较高话者间差异性,具有潜在的话者识别能力;反之,则如上零假设被推翻,说明同一数据组中的多段会话可能源于同一话者,表明被测试信息特征不具有高话者间差异性,不具有潜在的话者识别能力。
2.3.2 实验2
实验2的目的是回答第二个研究问题,测试实验1中被验证具有具有高话者间差异性的信息特征是否具有低话者内变异性。从81位话者的233段会话中抽取24位话者的149段会话作为实验2的数据;每位话者的多段会话为一组数据,共24组数据;每个数据组中最多包含同一话者的11段会话,最少包含同一话者的4段会话;同一话者的多段会话录制间隔时间都在一周以上;源于同一话者的多段会话至少发生在2类会话情境中,最多发生在5类会话情境中,而且即使源于同一话者的发生情境相同的多段会话,它们的发生时间、对话人、话者的交际意图都不相同。
实验2采用单因素方差分析统计方法,以待验证的信息特征为因变量,使用SPSS21统计分析软件逐一分析每组数据,筛选出符合如下零假设的信息特征:
零假设:该信息特征可以验证所有24个数据组中的多段会话都源于同一话者。
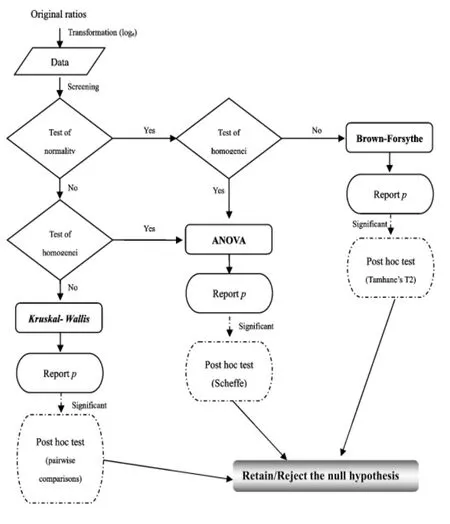
图2 实验2实施步骤
如果以某一信息特征为因变量,分析24组数据的所有24个单因素方差分析过程得出的相伴概率p值都大于显著水平0.01,则如上零假设成立,证明该信息特征不但具有高话者间差异性还具有低话者内变异性,能体现话者的个人话语风格,可以作为潜在的话者识别特征参数;如果24个单因素方差分析过程中的任何一个得出的相伴概率p值小于等于显著水平0.01,则如上零假设被推翻。
具体分析步骤如图2所示,首先把比率形式的语篇信息特征值转换成自然对数,以保证数据的正态分布[12];接下来,清洗数据,排除不符合条件的极端界外值;而后在SPSS21中检测清洗后数据的同质性和正态性,并根据验证结果采用相应的单因素方差分析过程进行分析。如果单因素方差分析过程的相伴概率p大于显著水平0.01,则证明利用该特征可以验证数据组中的多段会话源于同一话者。如果单因素方差分析过程的相伴概率小于等于显著水平0.01,则继续进行事后检验比较;如果事后检验比较过程结果显示,数据组中的任意两段会话间就待检验特征值而言都无显著差异,则说明单因素方差分析过程得出的小于等于显著水平0.01相伴概率p是由其他偶然性因素造成的,数据组中的会话还是源于同一话者。
2.3.3 实验3
实验3的目的是回答第三个研究问题,评估实验II筛选出的具有高话者间差异性、低话者内变异性的信息特征作为潜在话者识别特征的性能和效度。
为了实现这一研究目的,选用两组数据设计一个交叉验证过程。测试数据组中有24位话者,每位话者贡献两段会话,背景数据组中有30位话者,每位话者贡献一段会话。测试数据组中每位话者的第一段会话与自己的第二段会话配对比较,并分别与其他23位话者的第二段会话配对比较,也就是说,评估每一个信息特征值作为潜在话者识别特征的性能和效度的交叉验证过程共包含24对同对比较会话和552对异对比较会话。接下来,采用AITKENi等[12]提出的似然率计算公式(Multivariate Kernel Density LR),应用MORRISON[13]编写的程序软件在Matlab2012a中计算,得出每对比较会话的似然率值;而后,利用计算所得似然率值绘制每个信息特征Tippett图,评估其作为潜在话者识别特征的总体性能;并计算其Cllr值,评估其作为潜在话者识别特征的效度。
2.3.4 实验 4
实验4的目的是检验实验3中筛选出的具有潜在话者识别能力的信息特征的信度。为了实现该实验目的,首先利用实验3中性能和效度经过验证的信息特征构建一个由多个信息识别特征构成的话者识别系统,并评估所构建的话者识别系统的性能和效度。比较新构建的话者识别系统和以效度经过验证的双合元音或三合元音共振峰轨迹量化特征[25-26]为识别参数的话者识别系统的性能与效度。
首先分析所有81位话者的233段会话,找出出现频率最高的二合元音或三合元音,确定用于话者识别系统信度分析的数据组。通过统计发现74位话者的118段中包含了9个二合元音④ai, ao, ei, ou, ia, ua, uo, ie, üe和4个三合元音⑤iao,iou,uai,uei;接下来,继续考察这118段会话,找出一个出现频率最高的二合元音或三合元音。通过考察分析,最后确定[ɑu214] 为待考察的元音,含有该元音的源于9位话者的18段会话作为测试数据组,含有该元音的源于20位话者的20段会话作为背景数据组。
其次,提取共振峰轨迹特征。共振峰数据的提取,采用Praat语音分析软件人工手动测量的方法测量共振峰在起点、中点、终点的频率值,如图3所示。因为所选取会话中多数[ɑu214] 音节的第四个共振峰边界非常模糊或缺失,数据提取时只测量每段会话中[ɑu214] 的前三个共振峰的频率。 每段会话中[ɑu214] 测量的音节数为2。之后,把从38段会话中提取的共振峰频率值转换为标准分数(z-scores),依据TABACHNICK 等[27]的研究方法,排除 z>±3.29(p<0.01)范围内的极端界外值,完成数据清洗。
第三步,设计一个交叉验证过程。交叉验证过程中,测试数据组中每位话者的第一段会话和其第二段会话配对比较,共产生9对同对比较会话;每位话者的第一段会话和排序在其前面的话者的第二段会话配对比较,共产生36对异对会话比较。而后,采用AITKEN等[12]提出的似然率计算公式,应用MORRISON[13]编写的程序软件在Matlab2012a中进行计算,分别得出构建的由多个信息特征构成的话者识别系统和以元音共振峰轨迹特征为识别特征的话者识别系统中每对比较会话的似然率值;之后利用所得似然率值绘制Tippett图,评估比较两个识别系统的总体性能;计算Cllr值,评估比较两个识别系统的效度。
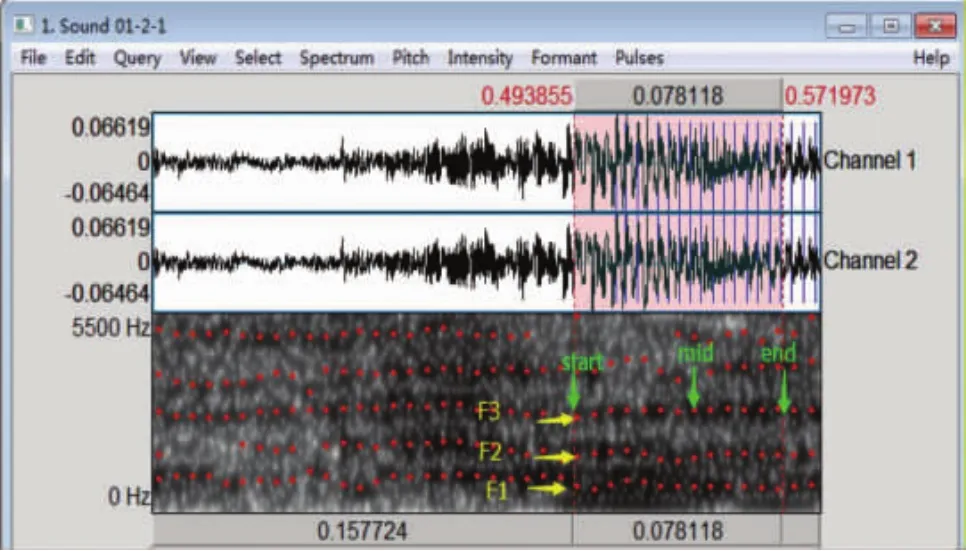
图3 [ɑu214] 共振峰测量方法
3 结果与讨论
实验1采用单因素方差分析过程训练并验证所挖掘的26个语篇信息频率特征和类次比特征。统计分析结果显示,挖掘的26个特征中有18个相对频率特征和类次比特征可以验证一个训练组和两个验证组数据中的话者都具有高话者间差异性,即对于这18个信息特征而言零假设成立,它们可能具有潜在的话者识别能力。
实验2分别以实验1中筛选出的18个信息特征为因变量进行的432(18×24)个单因素方差分析过程结果显示,其中的12个信息特征可以验证所有24个数据组中的多段会话源于同一话者,即这12个符合实验2所提出的零假设的信息特征具有低话者内变异性,体现话者的个人话语风格,它们的计算公式见表1。
图4是实验2中筛选出的12个信息特征的Tippett图。Tippett图中的实心曲线记录的是同对会话比较对的以10为底的似然率值,虚线记录的是异对会话比较对的以10为底的似然率值。被正确识别的同对会话比较对,其以10为底的似然率值应该大于0,值越大,支持正确认定的证据效力越强;被正确识别的异对会话比较对,其以10为底的似然率值应该小于0,值越小,支持正确排除的证据效力越强。基于此,某一识别特征的Tippett图上,实心曲线和虚线交叉点以上的部分分得愈开,交叉点以下部分靠得愈近,交叉点的值(等误率)越低,说明这个特征作为话者识别特征总体性能越好。从图4中的Tippett图的总体形态特征可以看出,信息特征P1和P3的总体性能最差,而P8、P10、P12的总体性能优于其他信息特征。此外,表2中的12个特征的Cllr值也显示P1和P3的效度最低。
基于对12个信息特征总体性能和效度的评估,选取除P1、P3之外的10个信息特征,尝试构建一个由多个识别特征构成的话者识别系统。
表3记录了拟用于构建话者识别系统的10个信息特征之间的Pearson相关系数。该表显示,信息特征P2和P9显著相关,P8分别与P5和P12显著相关。基于Pearson相关分析的结果,首先,把总体性能和效度最优的 P4、P8、P10、P11 和 P12 特征分为两组,以保证每组内的特征不显著相关。第一组包括P4、P10、P11、P12,第二组包括 P4、P8、P10、P11;接下来,分别以这两组参数为核心识别特征,构建话者识别系统。先把总体性能较好和效度较高的P2和P7依次与两组核心特征组合(鉴于P5、P6、P9的效度较低,因此不依次与两组核心特征组合),而后再依次加入其他特征,共构建了如表4所示的11个候选话者识别系统。
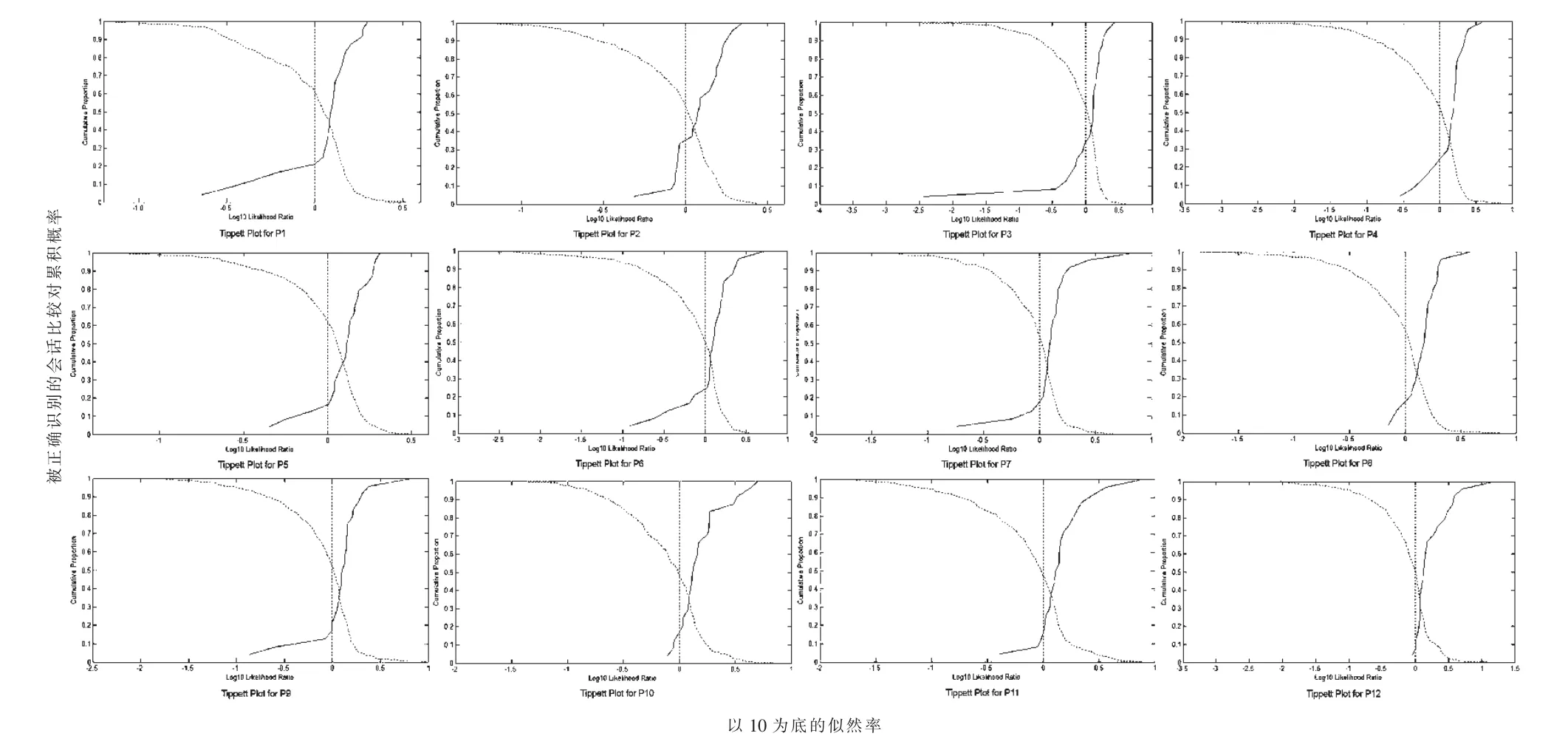
图4 实验2中筛选出12个信息特征的Tippett图

表1 实验2筛选出的具有高话者间差异性和低话者内变异性的信息特征参数及计算公式

表2 实验2中筛选出的12个信息特征的Cllr值
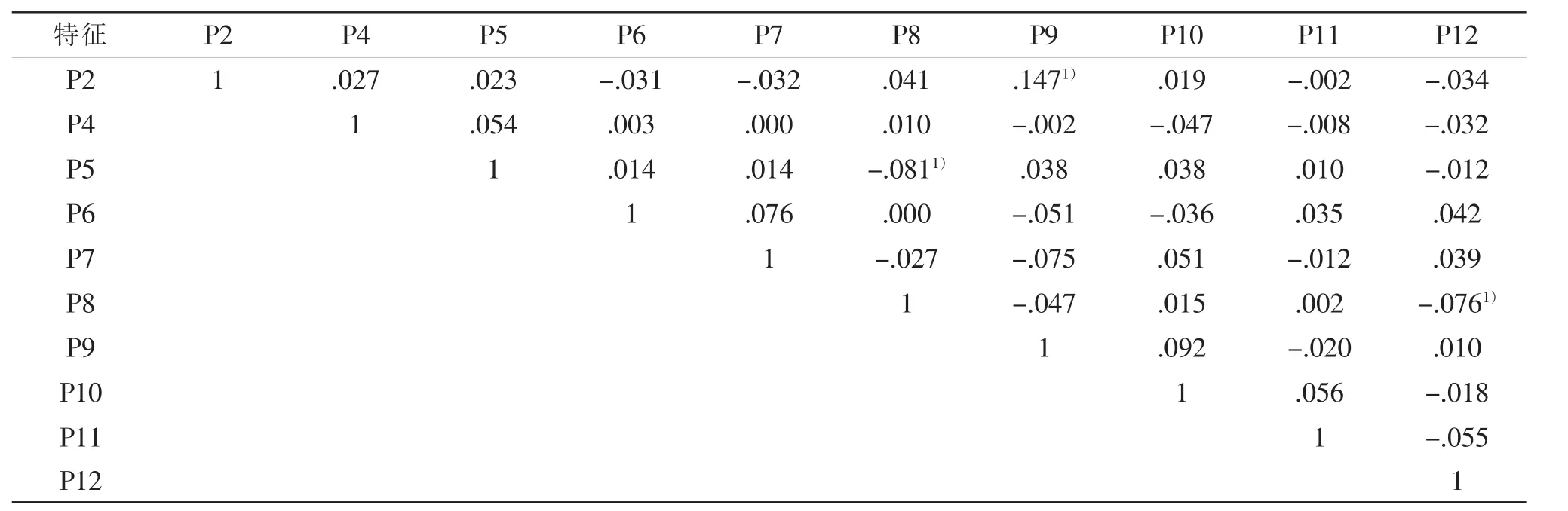
表3 拟用于构建话者识别系统的10个信息特征的相关关系
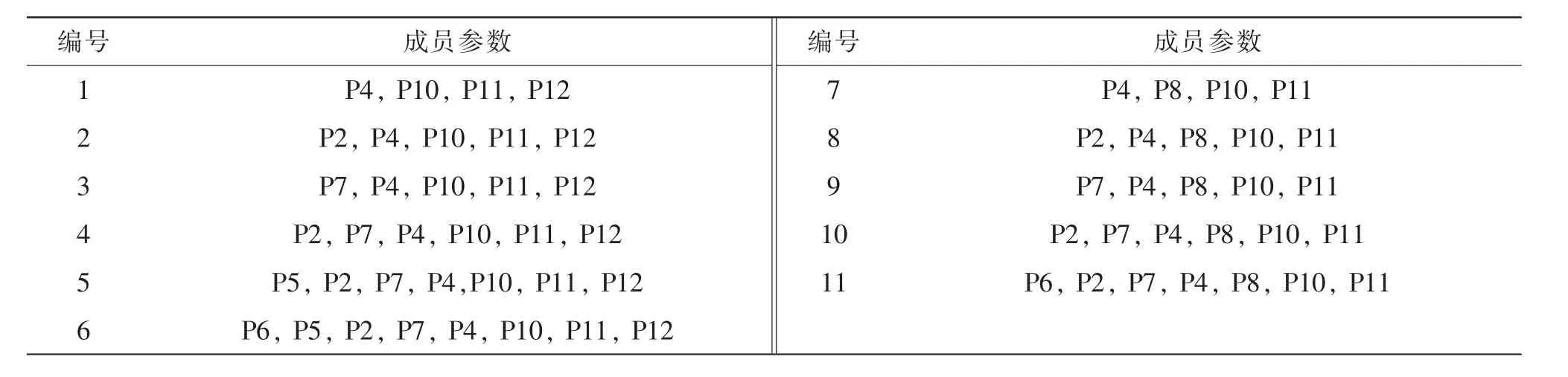
表 4 11个候选话者识别系统的识别特征构成
为了评估所构建的候选话者识别系统的总体性能和效度,把实验3中计算所得的识别系统内成员信息特征的似然率值相乘,即得出该话者识别系统的似然率值[17];而后在Matlab2012a中绘制每个话者识别系统的Tippett图(图5),并计算其Cllr值(表 5)。

表 5 11个候选话者识别系统的Cllr值
图5中的Tippett图显示,首先包含多个特征的11个候选话者识别系统的总体性能都大大优于单个信息特征;其次所有候选识别系统的等误率都低于28%,高于性能最优的特征P12的等误率(EER=31%)。此外,图5中的Tippett图的整体形态显示,以P4、P10、P11、P12为核心特征的候选话者识别系统(第 1~6 号识别系统)性能略优于以 P4、P8、P10、P11为核心特征的候选话者识别系统(第7~11号识别系统);而且,在以 P4、P10、P11、P12 为核心特征的6个候选话者识别系统中,第1、3、4号系统的总体性能优于其他3个系统;在第1、3、4号候选话者识别系统中,第4号系统的等误率为23%,低于其他两个系统(EER=26%),表明第4号话者识别系统的准确度略高于第1、3号识别系统。
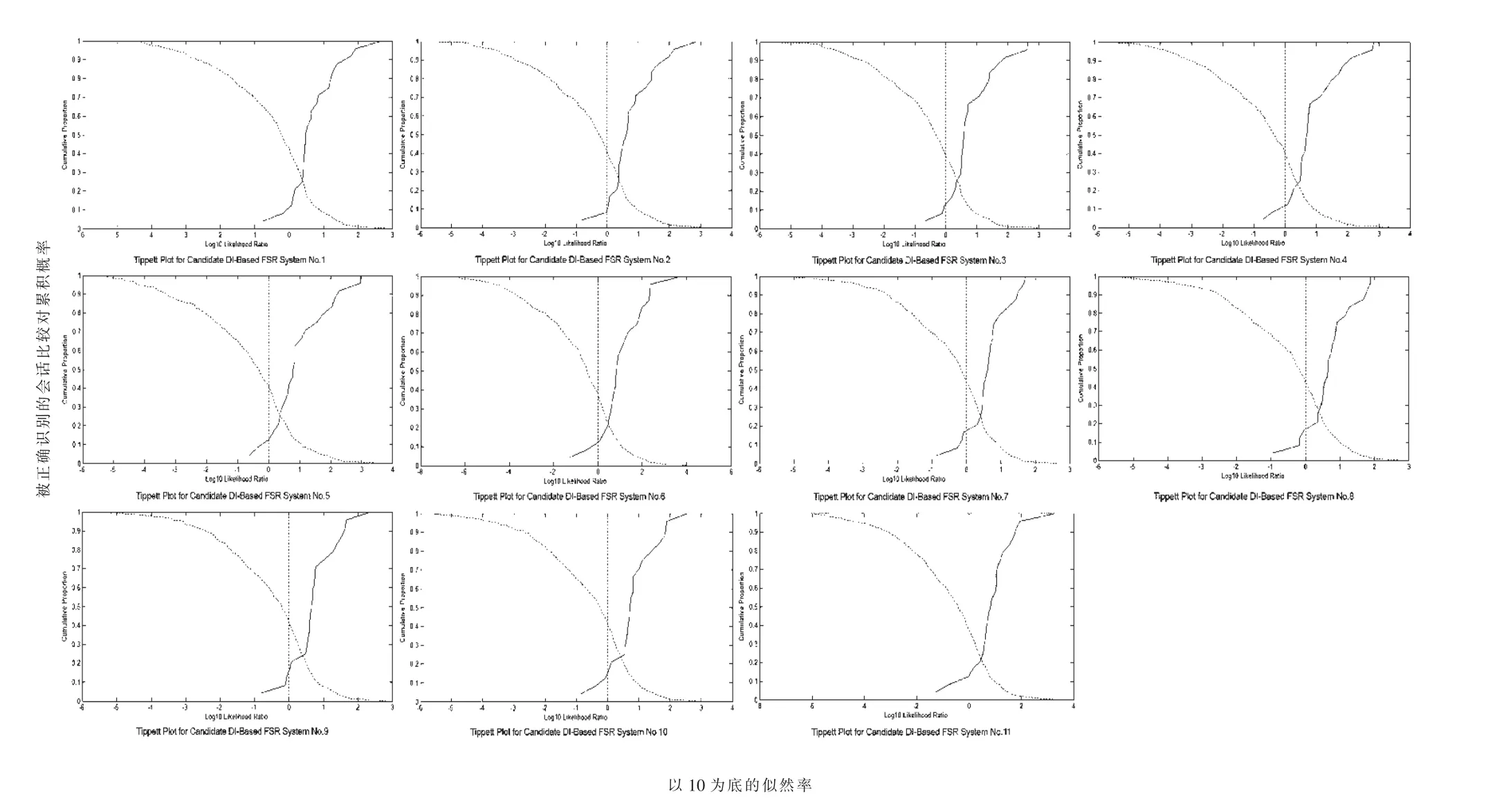
图5 11个候选话者识别系统的Tippett图
此外,表5中的11个候选话者识别系统的Cllr值也显示,第3、4号识别系统的效度略高于其他候选识别系统。综合考虑候选话者识别系统的总体性能和效度,选定第4号系统为要建立的话者识别系统。
图6分别是基于9对同对会话比较和36对异对会话比较的交叉验证过程计算所得的似然率值绘制的基于信息特征的4号话者识别系统和基于[ɑu214] 共振峰轨迹特征的话者识别系统的Tippett图。左侧的是以[ɑu214] 共振峰轨迹特征为识别特征的话者识别系统的Tippett图,右侧是以6个信息特征为识别特征的4号话者识别系统的Tippett图。不难看出,以信息特征为识别特征的话者识别系统的总体性能优于以共振峰轨迹特征为识别特征的话者识别系统。而且前者的等误率约为46%,后者的约为30.5%,表明以信息特征为识别参数的话者识别系统准确性更高些。
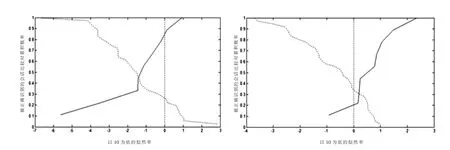
图6 基于信息特征和基于共振峰轨迹特征的话者识别系统Tippett图
而且,以信息特征为识别特征的话者识别系统的 Cllr值为 0.775,以[ɑu214] 共振峰轨迹特征为识别特征的话者识别系统的Cllr值为3.145,不但远远高于以信息特征为识别特征的话者识别系统的Cllr值,而且远远大于1,说明以共振峰轨迹特征为识别特征的话者识别系统的效度很低。
张翠玲等[26]测试二合元音和三合元音共振峰轨迹特征是比单元音效度更高的话者识别声学语音学特征,这与本研究实验结果相差甚远。导致本研究实验中共振峰轨迹特征的总体性能和信度都不理想的根本原因是本实验所用会话材料为自然话语。张翠玲等[26]实验所用元音[ɑi55] 源于同一个字“哀”,由被试朗读指定含有被测试音节的词组,并在实验室完成录制;而本研究所用会话是在不控制任何条件下录制的自然日常会话,该研究实验中的被测试音节[ɑu214] 并不是源于同一个字,在此条件下,为了保证取样音节的语音环境尽量相近似,在该实验数据中最多能保证每段对话中抽取2个音节。 张翠玲等[26]测试的元音为[ɑi55] 和[iɑo55] ,而本研究实验如果选用这两个元音,则会导致用作交叉验证过程的测试组数据和背景组数据样本量过小,严重影响实验结果的效度和信度。本实验选取[ɑu214] 作为被测试音节,首先是因为它是118段含有二合元音和三合元音会话中出现频率高,又能保证数据样本量的元音;其次,ZHANG等[28]的实验证明[iɑu55] 是比[ai55] 效度更高的识别参数。
以上实验数据和分析一方面证明语音学特征话者识别参数受现实环境诸多因素影响,话者内自身变异性大,另一方面也说明本实验挖掘的信息特征经验证体现话者的个人话语风格,受现实环境诸多因素影响小,话者内自身变异性小,可以作为话者识别特征。
4 结论
本研究的目的是挖掘在现实环境条件下话者内变异性低的量化话者识别特征。基于SAPIR提出的话语行为构成层面及它们的属性和语篇信息分析理论,采用语篇信息分析方法,以不人为施加任何控制的日常自然会话为实验材料,挖掘并验证话者的个人话语风格特征作为话者识别特征的总体性能、效度和信度。
本研究基于研究目的设计了四个环环相扣的实验,先筛选出具有高话者间差异性的信息特征,再从中筛选出具有低话者内变异性的信息特征,而后在似然率框架内检验所筛选出的具有潜在话者识别能力的个人话语风格特征作为话者识别特征的总体性能和效度,构建话者识别系统。最后比较所构建的话者识别系统和效度经过验证的元音共振峰轨迹特征的总体性能和效度,验证所挖掘的个人话语风格特征作为话者识别参数的信度。
该研究发现,首先话语行为的个人话语风格层面上的话者识别特征可以采用语篇信息分析方法分析挖掘;其次实验验证影响语音学特征的现实环境等因素和话者个人因素对个人话语风格特征基本无影响。此外,该研究还发现现实环境因素对语音学参数的影响主要表现在两方面,一是由于无法控制话者的交际意图,无法保证待考察音段的高频出现率;二是无法控制物理环境因素,使受传输信道、录制设备等影响较大的高效度语音学识别特征的信度大大降低。
基于以上发现,在司法实践中如果非语音学的个人话语风格特征能与话语行为其他层面上的高性能高效度识别特征,尤其是语音学特征,相互印证、互为补充,符合整体论原理,识别结论的信度会大大提高。
