网络表示学习的研究与发展1
2019-04-22尹赢吉立新黄瑞阳杜立新
尹赢,吉立新,黄瑞阳,杜立新
网络表示学习的研究与发展1
尹赢1,吉立新1,黄瑞阳1,杜立新2
(1. 国家数字交换系统工程技术研究中心,河南 郑州 450003; 2. 解放军63898部队,河南 洛阳 471003)
网络表示学习旨在将网络中的节点表示成低维稠密且具有一定推理能力的向量,以运用于节点分类、社区发现和链路预测等社交网络应用任务中,是连接网络原始数据和网络应用任务的桥梁。传统的网络表示学习方法都是针对网络中节点和连边只有一种类型的同质信息网络的表示学习方法,而现实世界中的网络往往是具有多种节点和连边类型的异质信息网络。而且,从时间维度上来看,网络是不断变化的。因此,网络表示学习的研究方法随着网络数据的复杂化而不断变化。对近年来针对不同网络的网络表示学习方法进行了分类介绍,并阐述了网络表示学习的应用场景。
大规模信息网络;网络表示学习;网络嵌入;深度学习
1 引言
在大数据时代,网络数据在现实世界中无处不在。针对网络数据的研究与分析,已经受到社会各界的广泛关注。复杂而庞大的网络数据往往难以处理,将网络数据表示成一种高效合理的形式,并将其运用于节点分类、社区发现、链路预测和网络可视化等应用任务中,对解决现实网络中的实际应用问题具有重要意义。例如,在社交网络中,可以通过节点分类方法对用户进行分类来构建用户推荐系统;在通信网络中,可以通过社区发现来观察舆情传播进程;在生物网络中,可以通过链路预测推测蛋白质之间可能存在的相互作用关系以推动疾病的治疗。这些网络分析方法都依赖于网络的表示方式,通常利用网络邻接矩阵或者由网络中节点和连边构成的图来表示网络。但是,这样简单的表示方式往往存在以下问题。
1) 连边导致计算复杂度高
网络通常由节点集和连边集组成,节点代表实体对象,而连边则反映出节点间的关联关系。连边的存在使大多数网络处理器或网络分析算法是迭代的或组合爆炸的。例如,用两个节点之间的最短路径长度或平均路径长度表示它们之间的距离。要想使用传统的网络表示方法计算这样的距离,必须枚举出2个节点之间的所有可能路径,从本质上看,这是一个组合问题,计算复杂度高。因此,传统的网络表示方法不再适用。
2) 数据样本相互耦合导致低并行性
以传统方式表示的网络数据给并行和分布式算法的设计和实现带来了很大的困难。研究的难点在于:网络中由连边连接的节点彼此耦合,若将不同的节点分布在不同的计算单元上进行处理,往往会造成服务器之间高昂的通信代价。虽然通过对大规模图形进行巧妙分割得到子图,使并行化性得到一定的提高,但这种方法在很大程度上依赖于网络图形的拓扑特性。
3) 机器学习方法不适用
近年来,机器学习方法(特别是深度学习方法)在很多领域都有应用,并且取得了不错的效果。这些方法针对各类问题都提供了标准的、通用的、有效的解决途径。但对于传统网络数据的表示,大多数现有的机器学习方法往往是不适用的。虽然可以简单地用网络邻接矩阵中节点对应的行向量来表示该节点。但是这种表示往往具有很高的维度,使后续的网络处理和分析变得十分困难。
为了解决传统方法的缺陷,研究学者提出了一种新的网络表示方式:将网络中的节点表示成具有一定推理能力的向量映射到低维空间中,旨在以更加直观高效的方式尽可能地保留节点间的原始关系,从而便捷地作为机器学习模型的输入,运用于节点分类、链路预测和社区发现等社交网络分析应用中。将节点表示成向量映射到低维空间中,向量间的距离反映出原始网络中节点间的连边关系。这就解决了由网络中的连边带来的一系列网络分析问题。同时,这种网络表示方式不需要人工标注网络特征,而是自动从原始网络数据中提取出有用的网络表征,能够很好地保留原始网络中的信息实现网络重构。
2 网络表示学习的基本定义
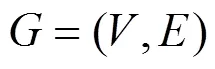
3 网络表示学习方法介绍
随着网络的规模化和复杂化,如何分析网络中包含的丰富信息是一项非常重要的研究任务。网络表示学习将网络中的节点表示成向量映射到低维空间,可以将其作为机器学习算法的输入来挖掘网络数据中蕴含的丰富信息。现有的网络表示学习方法主要针对同质信息网络和异质信息网络。接下来分别对基于这两种网络的表示学习方法进行分析。
3.1 针对同质信息网络的表示学习方法
基于网络表示学习方法所考虑的网络信息内容,本节将同质信息网络的表示学习方法分为两类:基于网络结构的网络表示学习和结合外部信息的网络表示学习。
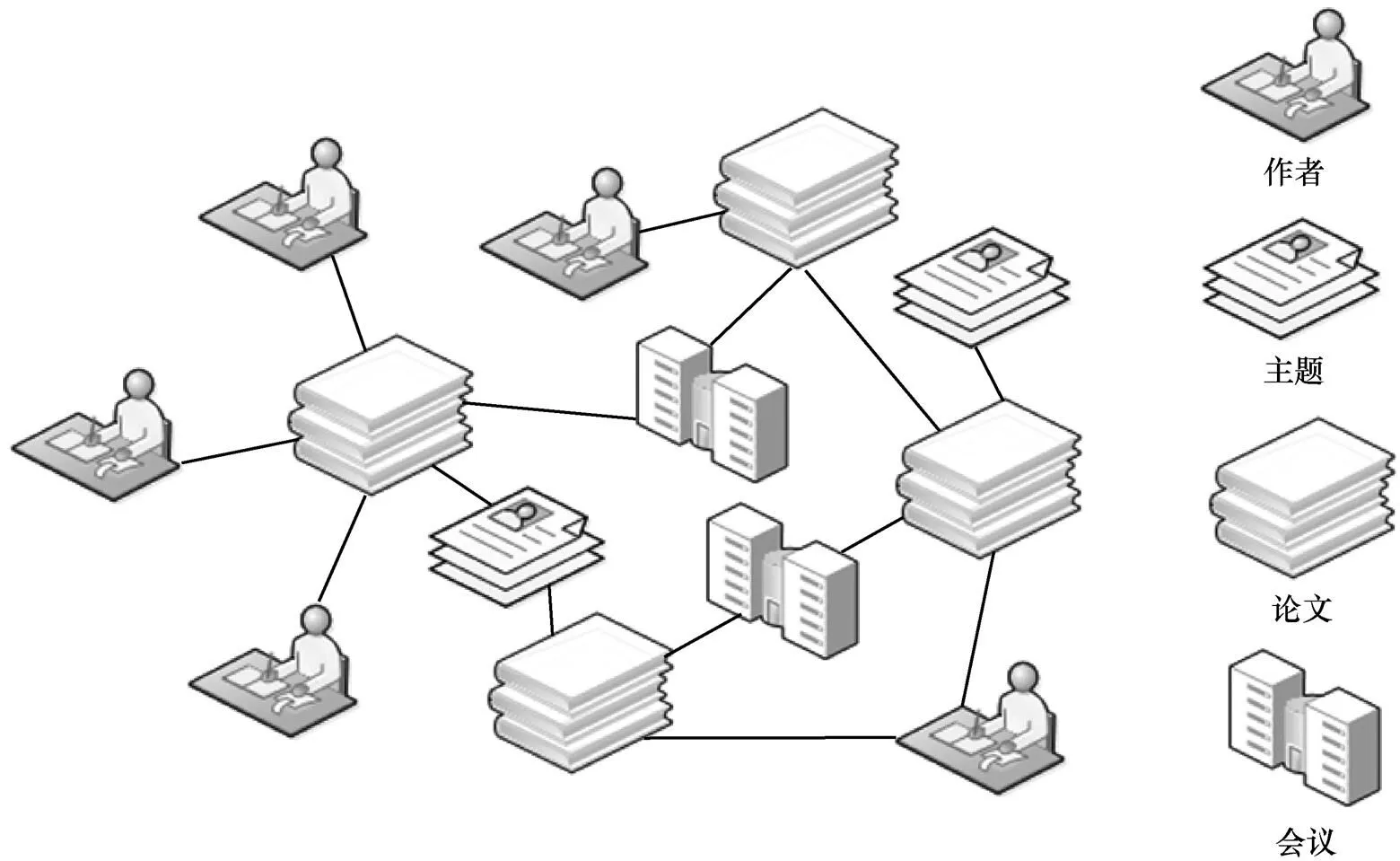
图1 异质信息网络实例
3.1.1 基于网络结构的同质网络表示学习
网络结构可以划分为以不同粒度呈现的不同组。网络表示学习中常用的网络结构包括邻域结构、高阶节点邻近结构和网络社团。依据算法基于的不同方法将其分为3类:基于矩阵特征向量和矩阵分解的方法、基于浅层神经网络的方法和基于深度学习的方法。
基于矩阵特征向量和矩阵分解的方法:早期的网络表示学习算法大多是基于矩阵特征向量和矩阵分解的方法,Saul等[2-3]提出局部线性表示,通过邻居节点的线性组合来表示当前节点,算法假设节点与其邻居节点位于同一流形区域。当前节点可表示为

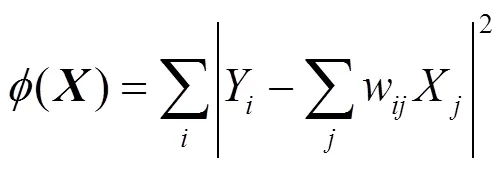

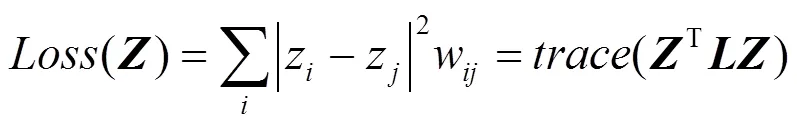

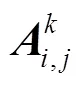

基于浅层神经网络的方法:受自然语言处理中Word2vec算法[11]的启发,Perozzi等[12]提出了DeepWalk算法用于学习网络中的节点表示,DeepWalk通过随机游走遍历网络中的节点,从而得到一个有序的节点序列,该过程实际是对网络中的节点进行采样的过程,在随机游走过程中,节点越邻近,共现的概率越大;在通过随机游走得到节点序列以后,该算法利用skip-gram模型由单个节点预测前后序列,学习得到该节点的向量表示。Grover等[13]提出的node2vec改进了DeepWalk中的随机游走过程。DeepWalk选取随机游走序列中下一个节点的方式是均匀随机分布的,而Node2vec通过引入两个参数和,将宽度优先搜索和深度优先搜索引入了随机游走序列的生成过程。宽度优先搜索注重邻近节点并刻画了相对局部的一种网络表示,而深度优先搜索则反映了更高层面上节点间的同质性。Tang等[14]提出的LINE算法能够处理任意类型的大规模网络,包括有向和无向、有权重和无权重。该算法保留了网络中节点的一阶相似性和二阶相似性。一阶相似性是指有连边的节点之间的相似性,主要由连边权重决定,没有连边的节点间的相似性则为0。二阶相似性是指节点的邻近网络结构的相似性,若2个节点没有共同的一阶邻居,则二阶相似性为0。如图2所示,节点5和6的一阶相似性为0,但二者具有很强的二阶相似性,节点6和7具有一阶相似性但不具备二阶相似性。一阶相似性和二阶相似性互补,使该算法能够很好地保留网络的局部结构和全局结构。
基于深度学习的方法:SDNE算法[15]利用深度神经网络对网络的表示学习进行建模,该半监督的深度学习模型由多重的非线性映射函数组成,将输入的节点映射到高度非线性空间中以获取网络的结构信息。模型如图3所示,主要由两部分组成:一是由拉普拉斯矩阵监督的能保留局部信息的一阶相似度模块,二是基于无监督深度自编码器的能保留全局信息的二阶相似度模块。

图2 一阶相似性和二阶相似性实例
模型将一阶相似度和二阶相似度结合来同时保留网络结构的局部信息和全局信息,其目标函数可表示为
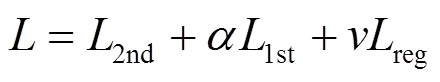
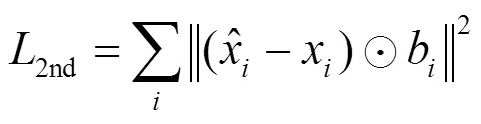
不同于传统的直推式网络表示学习算法,Hamilton等[16]提出一种适用于大规模网络的归纳式学习方法GraphSAGE。该算法通过聚集采样到的邻居节点表示来更新当前节点的特征表示,而不是像直推式方法将每个节点单独进行训练。在聚类过程中,网络第层聚集到的邻居即为宽度优先搜索(BFS)过程中第层的邻居。同时,作者在算法中利用了3种聚类策略:Mean、LSTM和MaxPooling。
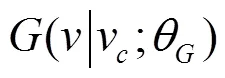
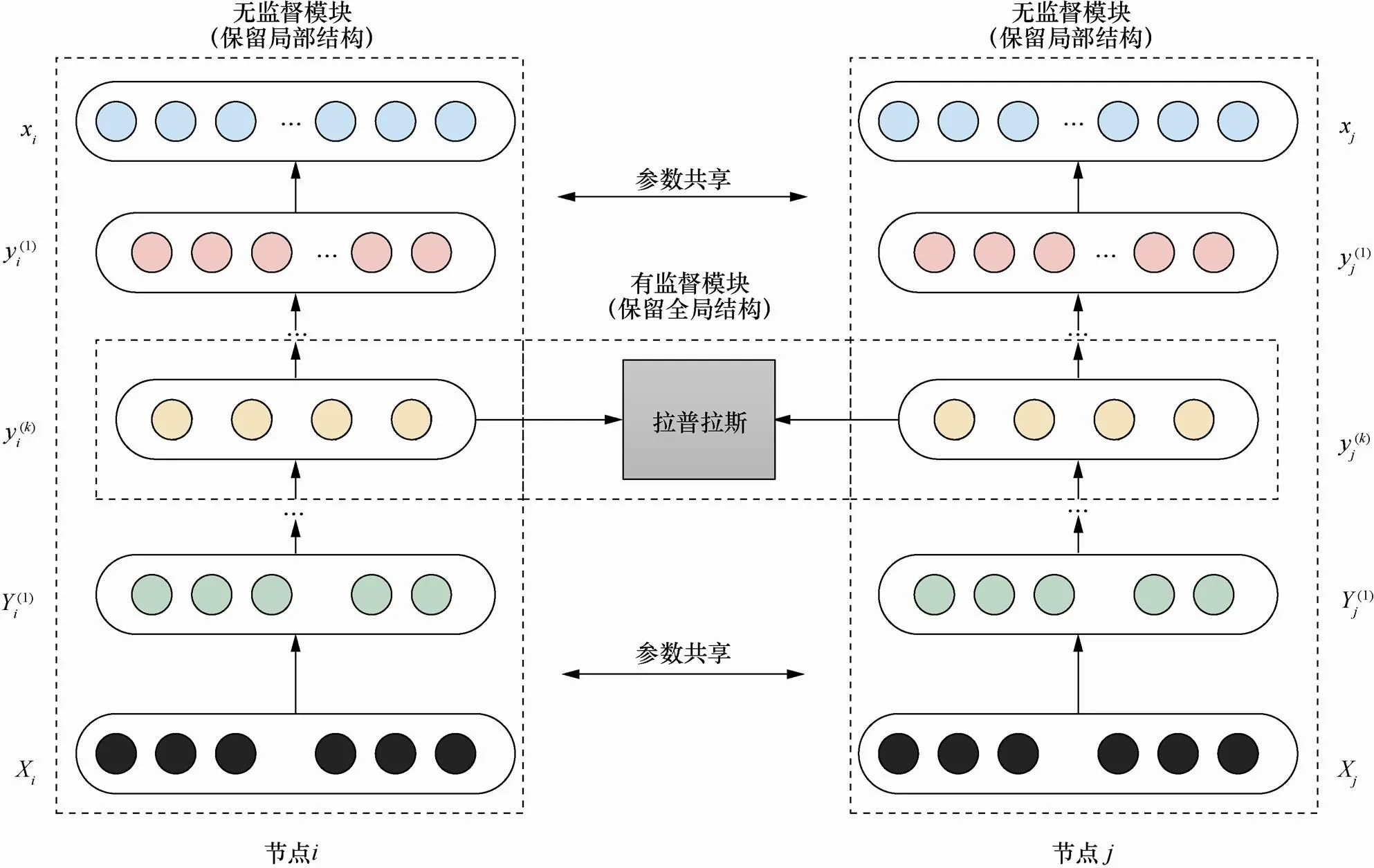
图3 SDNE算法模型框架
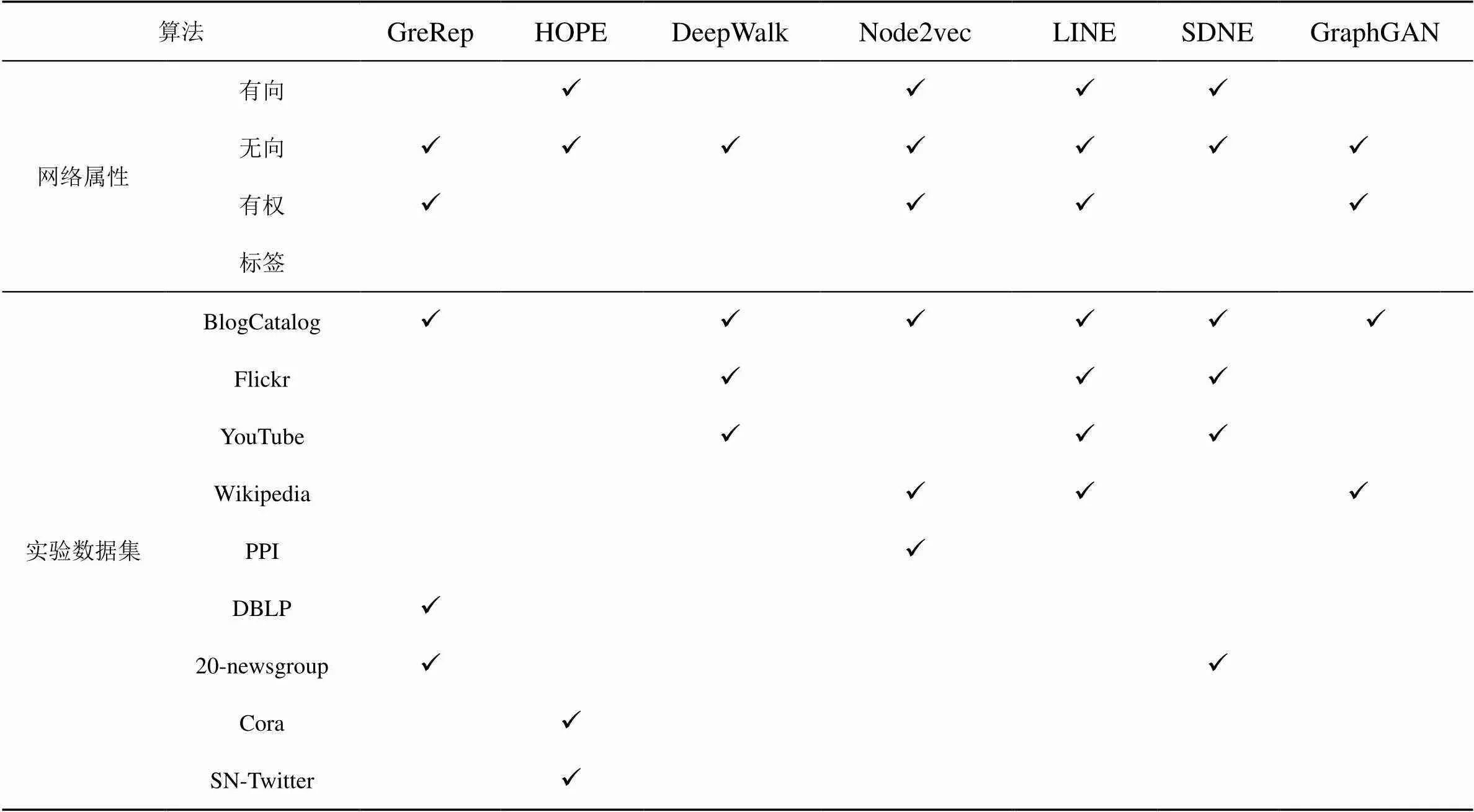
表1 算法适用网络及实验数据集
总之,判别器和生成器的训练过程是一个最大最小相互制约的过程,算法的目标函数可表示为
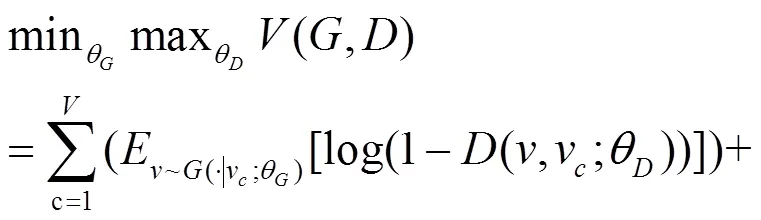
常见的基于网络结构的同质网络表示学习方法如表1所示。
3.1.2 结合外部信息的同质网络表示学习
传统的网络表示学习方法都是基于网络拓扑结构的方法,但除了网络拓扑结构,网络还包括标签和文本等重要的外部信息,这些外部信息也是网络表示学习的一个重要研究内容。
为了适应节点分类等机器学习任务,Tu等[18]提出了针对带标签网络的半监督网络表示学习模型MMDW。该模型基于矩阵分解,利用SVM 分类器和节点的标签信息来寻找优化的分类边界。通过优化SVM最大间隔分类器和转换为矩阵因子分解形式的DeepWalk模型,MMDW模型能学习到包含网络结构信息和标签信息的节点表示。
在网络数据中,节点除了包含标签信息,还包含一些文本信息。这些文本信息也可以作为网络信息的补充,有助于进行更加合理适用的网络表示学习。TADW[19]基于矩阵分解将节点的文本信息引入网络表示学习中,TADW模型框架如图4所示。
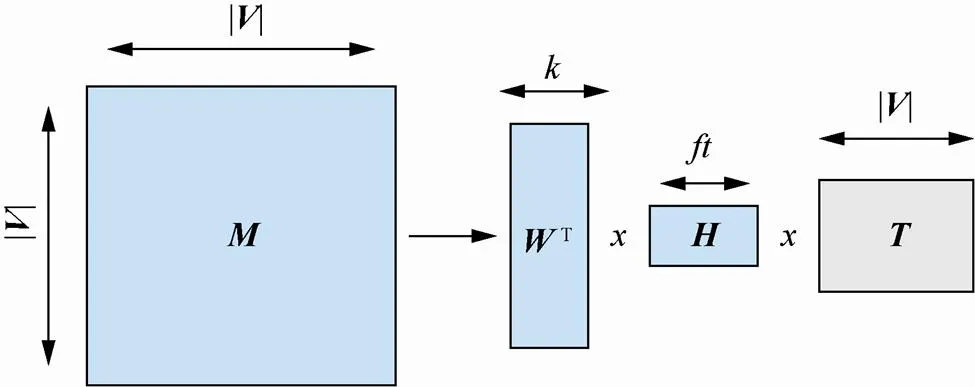
图4 TADW模型框架
模型将关系矩阵分解为、、这3个矩阵的乘积。其中,表示文本特征矩阵,和表示参数矩阵,算法通过梯度下降法来迭代更新参数矩阵。模型的目标函数可表示为

但是TADW算法的计算代价很高,而且算法只是将节点属性进行简单结合,这就造成了网络中语义信息的大量丢失。Sun等[20]提出一种新的CENE算法,将节点内容视为一种特殊的节点来扩展网络,如图5所示。扩展的网络中包含两种节点:原始网络节点和构造的“节点内容”节点。基于不同节点,扩展的网络也包括两种边:原始节点之间的连边和原始节点与“节点内容”之间的连边。算法使用逻辑回归函数学习扩展的网络,并通过负采样的方法优化目标函数。通过该算法得到的网络表示不仅可以保留网络结构特征,还可以保留节点和内容之间的语义信息。
Pan等提出一个能结合网络结构、节点内容和节点标签这3种网络信息的深度学习模型TriDNR[21],模型结构如图6所示,其目标函数可表示为
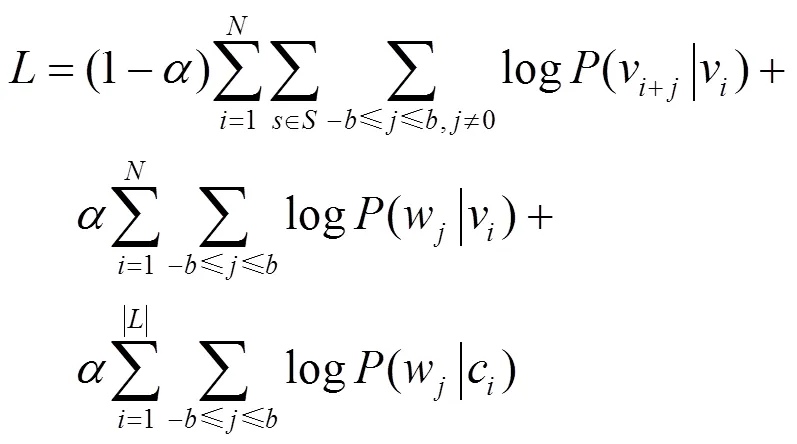
类似于DeepWalk模型,该模型通过随机游走生成节点的表示向量来保留节点在结构上的相似性;然后用另一个神经网络学习节点上下文的相关性;同时,将节点标签作为输入,直接在标签和上下文之间建模来学习标签向量和单词向量。
常见的结合外部信息的同质信息网络表示学习算法如表2所示。
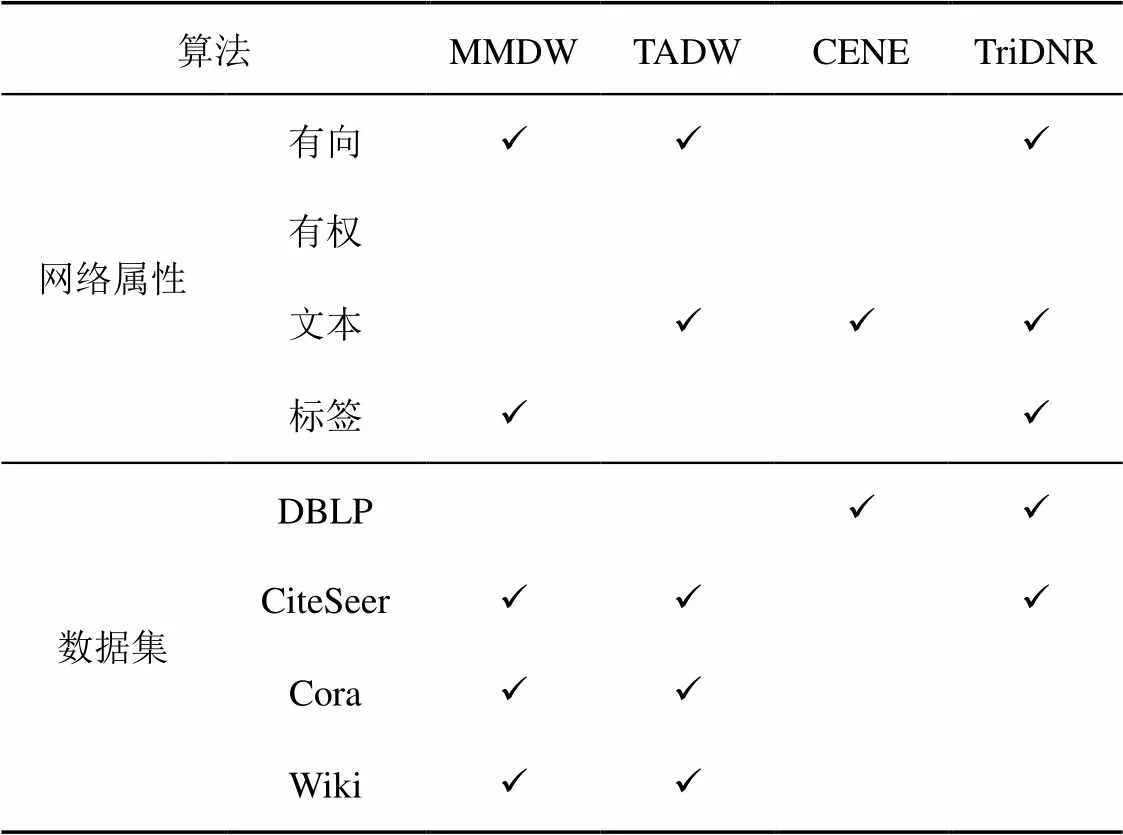
表2 算法适用网络及实验数据集
3.2 针对异质信息网络的表示学习方法
早期的网络表示学习算法是针对节点和边类型只有一种的同质信息网络,而将所有节点和连边视为同一类的同质网络忽略了网络中丰富的语义信息,并不能有效地反映现实世界中的网络。类型化、半结构化的异质信息网络建模可以捕获真实世界中最根本的语义信息[22]。目前,针对异质信息网络的表示学习方法研究相对较少,主要分为3类:基于随机游走的方法、基于分解的方法和结合应用任务的方法。
1) 基于随机游走的方法
Yu等[23]受同质网络中Node2vec算法的启发,提出了Metapath2vec算法,该方法通过在异质信息网络中进行随机游走来获取节点的邻居节点集合。不同于同质信息网络中的随机游走,Metapath2vec算法中的随机游走是在元路径[24]的指导下进行的,其跳转概率为
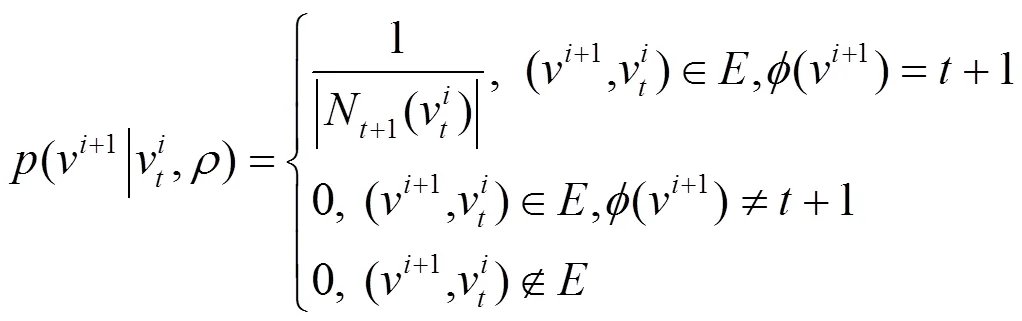
基于元路径进行随机游走得到的节点序列,不仅包含网络的结构信息,还包含网络中的语义信息。在得到节点序列之后,算法利用skip-gram模型得到节点的向量表示,并采用负采样的方法更新式(12)的目标函数。
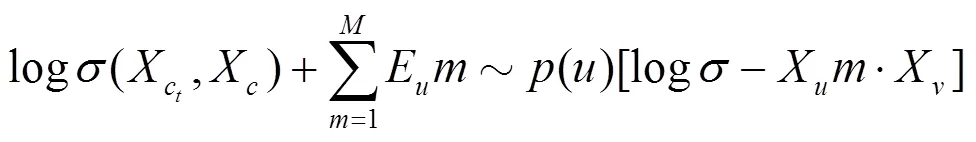
Metapath2vec算法在利用softmax函数进行归一化时,并没有考虑节点的类型,而是和同质网络表示学习算法DeepWalk、Node2vec的处理方式一样,是将所有节点的特征表示之和作为softmax函数的分母。作者在提出Metapath2vec的同时,提出了Metapath2vec++[23],该算法在Metapath2vec的基础上改进了softmax函数,如式(13)所示。Metapath2vec++对不同类型的节点分别进行归一化,相当于在浅层神经网络的输出层根据节点类型将整个异质信息网络分解成不同的同质信息网络。通过Metapath2vec++得到的节点表示在运用节点分类、聚类和相似性搜索等应用任务时,具有更高的精度和可靠性。
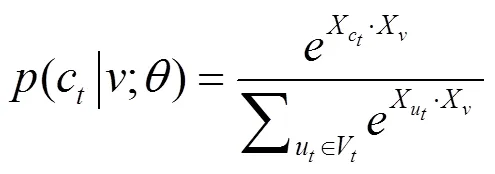
2) 基于分解的方法
从网络分解的角度对异质信息网络进行表示学习,往往有化繁为简的效果。Tang等提出的PTE算法[25],将包含词、文件、标签这3种节点类型的文本信息网络分解成3个不同的子网络:词−词网络、词−文件网络、词−标签网络。然后对这3个不同的网络进行表示学习,得到不同类型节点的向量表示。Shi等提出的HERec[26]模型基于元路径从异质信息网络中抽取出同类节点序列,相当于从异质信息网络中抽取出多个同质信息网络。基于不同元路径,该模型抽取出的同类节点序列有所不同。算法将基于不同元路径抽取出的同类节点分别进行表示学习,然后利用融合函数对节点的不同表示进行融合,并将向量整合到矩阵分解模型中,通过矩阵分解模型和融合函数一起对预测任务进行联合优化。该方法与基于卷积神经网络的监督方法相比调整参数更少。
3) 结合应用任务的方法
异质信息网络表示学习算法常和具体的数据挖掘任务相结合,Sun等[27]首先提出基于元路径评估异质信息网络中节点间相似性的算法PathSim,该算法基于对称元路径,可测量异质信息网络中同类型对象间的相似程度。Sun等[28]提出的Pathselclus算法利用用户提供的种子作为聚类的先验知识,提出一个基于聚类的生成模型来模拟节点间关系的生成,并通过评估元路径关系矩阵与基于先验知识的聚类结果的一致性来优化元路径权重和聚类效果。也有算法用于异质信息网络的节点分类,Luo等[29]提出的HetPathMine算法通过构建元路径选择模型来将异质信息网络中带标签的数据进行分类。Kong等[30]提出了一种适用于大规模网络的基于元路径的分类算法,该算法考虑了不同元路径所蕴含的不同语义,以捕获不同连接类型对实体对象间关联程度的影响,从而有效地对异质网络进行大规模集体分类。Fu等[31]提出的HIN2vec利用神经网络模型来实现异质信息网络中节点和边的表示。学习到的向量可以直接用于链路预测任务,并具有很好的效果。
4 应用场景
常见的网络表示学习应用场景主要有节点分类、链路预测、社区发现和可视化等。
1) 节点分类
在进行网络数据处理时,往往需要将网络中的节点进行合理分类。例如,在社交网络中,可以根据用户的兴趣爱好对用户分类以进行相关推荐。用户的兴趣爱好是将用户进行分类的类别标注信息,是对用户进行分类的依据。然而实际数据中的类别标注信息十分稀疏,可以利用网络表示学习算法来对节点进行编码,使在标注信息很少的情况下也能得到很好的分类效果。
2) 链路预测
链路预测是指对网络中丢失的边或者潜在的边进行预测,可以帮助分析数据缺失的网络以及网络的演化,其在现实生活中具有广泛的运用。例如,可以利用链路预测方法基于当前网络结构预测可能成为朋友的用户,从而对用户进行好友推荐。链路预测的常见评价指标为AUC值,当在样本集中随机挑选一个正样本以及一个负样本,分类算法根据计算得到的正样本分数值高于负样本分数值的概率就是AUC值。
3) 社区发现
社区发现是指将网络中相似的节点划分到同一社区,与节点分类的不同之处在于,社区发现不依靠任何标记的数据,而是直接对网络中的节点进行无监督的聚类。社区发现是一个自由度较高的网络应用任务,可以结合网络表示学习利用社区发现算法对网络中的用户进行自动分组。
4) 可视化
可视化是指利用一定的计算机技术将数据转换成图形或者图像直观地呈现出来,从而清晰有效地表达出信息。通过网络表示学习,可以在低维向量空间得到网络节点的表示向量,而这些向量可以直接用于网络的可视化,使网络可视化变得高效便捷。
5 结束语
网络表示学习的研究方法随着网络数据的复杂化而不断变化,保留网络结构和网络属性是网络表示学习的基础。如果网络表示学习方法没有很好地保留网络结构和属性,那么当节点映射到低维向量空间中时,会造成严重的信息丢失。此外,也可以考虑将某些领域知识作为高级信息来辅助网络表示学习。从现有的网络表示学习工作来看,该领域是一个新兴的且非常具有前景的研究方向。近年来,网络表示学习取得了丰硕的研究成果,但仍存在以下挑战。
1) 现实网络是蕴含庞大数据量的大规模复杂网络,如何高效处理这些庞大的数据,是网络表示学习亟待解决的一个难点。
2) 动态网络的研究相对较少,如何从时间维度上综合考虑网络的重构是网络表示学习一个研究难点。
3) 现有的网络表示学习算法只能适用于一般的网络应用任务,如节点分类和链路预测等,这些方法主要针对一般的网络结构,对一些具体的网络应用任务可能并不适用。
[1] SUN Y, HAN J. Mining heterogeneous information networks: a structural analysis approach[J]. ACM Sigkdd Explorations Newsletter, 2013, 14(2): 20-28.
[2] ROWEIS S T, SAUL L K. Nonlinear dimensionality reduction by locally linear embedding[J]. Science, 2000, 290(5500): 2323-2326.
[3] SAUL L K, ROWEIS S T. An introduction to locally linear embedding[J]. Journal of Machine Learning Research, 2008.
[4] BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering[J]. Advances in Neural Information Processing Systems, 2002, 14(6): 585-591.
[5] HE X, NIYOGI P. Locality preserving projections[C]//Advances in Neural Information Processing Systems. 2004: 153-160.
[6] AHMED A, SHERVASHIDZE N, NARAYANAMURTHY S, et al. Distributed large-scale natural graph factorization[C]// International Conference on World Wide Web. ACM, 2013: 37-48.
[7] CAO S, LU W, XU Q. GraRep: learning graph representations with global structural information[C]//ACM International on Conference on Information and Knowledge Management. 2015: 891-900.
[8] CHENG W, GREAVES C, WARREN M. From-gram to skipgram to concgram[J]. International Journal of Corpus Linguistics, 2006, 11(4):411-433.
[9] OU M, CUI P, PEI J, et al. Asymmetric transitivity preserving graph embedding[C]//The 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016: 1105-1114.
[10] KATZ L. A new status index derived from sociometric analysis[J]. Psychometrika, 1953, 18(1): 39-43.
[11] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[J]. Computer Science, 2013.
[12] PEROZZI B, AL-RFOU R, SKIENA S. DeepWalk:online learning of social representations[C]//ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2014: 701-710.
[13] GROVER A, LESKOVEC J. node2vec: scalable feature learning for networks[C]//The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016: 855-864.
[14] TANG J, QU M, WANG M, et al. LINE: large-scale information network embedding[C]//International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2015: 1067-1077.
[15] WANG D, CUI P, ZHU W. structural deep network embedding[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016: 1225-1234.
[16] HAMILTON W, YING Z, LESKOVEC J. Inductive representation learning on large graphs[C]//Advances in Neural Information Processing Systems. 2017: 1024-1034.
[17] WANG H, WANG J, WANG J, et al. GraphGAN: graph representation learning with generative adversarial nets[C]//Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[18] TU C, ZHANG W, LIU Z, et al. Max-margin DeepWalk: discriminative learning of network representation[C]//International Joint Conference on Artificial Intelligence. AAAI Press, 2016. 3889: 3895.
[19] YANG C, ZHAO D, ZHAO D, et al. Network representation learning with rich text information[C]// International Conference on Artificial Intelligence. AAAI Press, 2015: 2111-2117.
[20] SUN X, GUO J, DING X, et al. A general framework for content-enhanced network representation learning[J]. arXiv preprint arXiv:1610.02906,2016.
[21] PAN S, WU J, ZHU X, et al. Tri-party deep network representation[C]//International Joint Conference on Artificial Intelligence. AAAI Press, 2016:1895-1901.
[22] 孙艺洲, 韩家炜. 异构信息网络挖掘原理与方法[M]. 北京: 机械工业出版社, 2016,2. SUN Y Z, HAN J W. Principles and methods of heterogeneous information network mining[M]. Beijing: Machinery Industry Press, 2016.
[23] DONG Y, CHAWLA N V , SWAMI A, et al. metapath2vec: scalable representation learning for heterogeneous networks[C]// ACM Sigkdd International Conference on Knowledge Discovery & Data Mining. 2017:135-144.
[24] SUN G, ZHANG X. Graph embedding with rich information through heterogeneous network[J]. arXiv preprint arXiv: 1710.06879, 2017.
[25] TANG J, QU M, MEI Q. Pte: Predictive text embedding through large-scale heterogeneous text networks[C]//The 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2015: 1165-1174.
[26] SHI C, HU B, ZHAO X, et al. Heterogeneous information network embedding for recommendation[J]. IEEE Transactions on Knowledge and Data Engineering, 2019, 31(2): 357-370.
[27] SUN Y, HAN J, YAN X, et al. Pathsim: meta path-based top-similarity search in heterogeneous information networks[J]. Proceedings of the VLDB Endowment, 2011, 4(11): 992-1003.
[28] SUN Y, NORICK B, HAN J, et al. PathSelClus: integrating meta-path selection with user-guided object clustering in heterogeneous information networks[J]. ACM Transactions on Knowledge Discovery from Data, 2013, 7(3): 1-23.
[29] LUO C, GUAN R, WANG Z, et al. Hetpathmine: a novel transductive classification algorithm on heterogeneous information networks[C]//European Conference on Information Retrieval. 2014: 210-221.
[30] KONG X, YU P S, DING Y, et al. Meta path-based collective classification in heterogeneous information networks[J]. 2012: 1567-1571.
[31] FU T Y, LEE W C, LEI Z. HIN2Vec: explore meta-paths in heterogeneous information networks for representation learning[C]//ACM, 2017: 1797-1806.
Research and development of network representation learning
YIN Ying1, JI Lixin1, HUANG Ruiyang1, DU Lixin2
1. China National Digital Switching System Engineering & Technological Center, Zhengzhou 450003, China 2. The 63898 Troop of PLA, Luoyang 471003, China
Network representation learning is a bridge between network raw data and network application tasks which aims to map nodes in the network to vectors in the low-dimensional space. These vectors can be used as input to the machine learning model for social network application tasks such as node classification, community discovery, and link prediction. The traditional network representation learning methods are based on homogeneous information network. In the real world, the network is often heterogeneous with multiple types of nodes and edges. Moreover, from the perspective of time, the network is constantly changing. Therefore, the research method of network representation learning is continuously optimized with the complexity of network data. Different kinds of network representation learning methods based on different networks were introduced and the application scenarios of network representation learning were expounded.
large-scale information network, network representation learning, network embedding, deep learning
The National Natural Science Foundation for Creative Research Groups of China(No.61521003)
TP391.4
A
10.11959/j.issn.2096-109x.2019019
尹赢(1994− ),女,四川绵竹人,国家数字交换系统工程技术研究中心硕士生,主要研究方向为复杂网络、网络表示学习。

吉立新(1969− ),男,江苏淮安人,国家数字交换系统工程技术研究中心研究员,主要研究方向为通信网信息安全。
黄瑞阳(1986− ),男,福建漳州人,国家数字交换系统工程技术研究中心助理研究员,主要研究方向为文本挖掘、图挖掘。

杜立新(1996− ),男,甘肃武威人,主要研究方向为大数据分析。
2018−10−25;
2018−12−20
尹赢,15883880517@163.com
国家自然科学基金创新群体资助项目(No.61521003)
尹赢, 吉立新, 黄瑞阳, 等. 网络表示学习的研究与发展[J]. 网络与信息安全学报, 2019, 5(2): 77-87.
YIN Y, JI L X, HUANG R Y, et al. Research and development of network representation learning[J]. Chinese Journal of Network and Information Security, 2019, 5(2): 77-87.
