东北财经大学利用大数据构建学生征信体系
2019-04-18范宇辰陈伟
文/范宇辰 陈伟
近年,“校园贷”问题的出现凸显出高校大学生对消费金融产品的强大需求以及信用教育缺失的问题。各大网贷平台五花八门,缺乏统一的监管体系。各个贷款机构为了抢夺市场,随意调整大学生借贷政策,降低门槛等以吸引更多学生来借款,且一些不良机构利用学生的知识盲点,编写高额利息和高额违约金的合同,使学生陷入校园贷的陷阱中。银监会、教育部等部门多次下发了一系列通知,规范、整治校园贷业务,“一律暂停网贷机构开展校园贷业务”。
以阿里、腾讯为首的互联网金融机构依托其自有数据基础纷纷切入学生信贷领域,推出“芝麻信用”、“花呗”等产品,一定程度缓解此问题,但存在覆盖面不够、利息较高等缺点。其他持牌正规金融机构,因为数据缺失问题无法有效评估学生征信,其优质的消费金融产品无法服务于广大学生群体。
此次研究在学校多维度、高精准的特殊数据环境下,探索了结合大数据、机器学习技术建立起适合大学生的信用评价体系——“油菜花信用”,从而辅助金融机构向大学生提供定制化、规范化的金融服务,控制风险、获取利润。同时,在校内利用信用模型的展现、运营帮助大学生培养正确的信用意识、风险意识和防范意识,疏堵结合,有效推进“校园贷”问题解决,同时为构建信用社会奠定基础。
问题分析
高校和互联网金融机构建立模型都基于大数据基础,机构的模型经过市场检验更加成熟。相较于互联网金融机构,依托于高校大数据环境建立学生征信模型拥有诸多优势。
数据维度的差异
在校大学生移动支付占比近92%,信用卡持卡人数少,缺少历史信用记录。一般金融机构只能从移动支付和互联网社交方面收集大学生的信息。
而高校作为学生最主要的生活场所,拥有完整且多方面的学生信息,例如学生基本信息、成绩记录、校园卡消费记录、图书借阅记录、上网记录等等。涉及维度广泛且健全,对建立信用评估模型十分有利,而这方面的数据往往是金融机构易忽视且难以获取的。
数据准确性的差异
高校比金融机构更了解大学生,数据基础更好。大学生的日常行为信息是客观地被记录,个人无法修改也无法作伪。而金融机构所采用的大学生数据真实性需要经过鉴别。在数据准确性上,高校的征信模型比金融机构自建征信模型具有更大优势。
服务方式的差异
金融机构自建征信模型主要用于自身业务场景需要,为其业务提供风险评估和信用分析。
高校建立征信模型是第三方独立征信体系,为学生个人建立信用档案,依法采集、客观记录其信用信息,并依法对外提供信用信息服务。作为专业化的信用信息服务平台,不仅仅服务于金融机构,还可服务于其他任何有需要的社会机构,如招聘单位、共享经济类互联网企业等等,前景广阔。
设计实现
“油菜花信用”是一个基于东北财经大学学生大数据环境下的信用评分模型。数据来自于学校数据中心整合的学生基本信息数据、教务成绩数据、一卡通消费数据、图书借还数据和奖惩助贷数据等多维度数据资源,以身份、成绩、消费、履约和奖惩五个维度作为衡量标准,通过使用专家打分法、逻辑回归两种方式建立模型,对学生在校行为进行打分评价,分数范围从350分至950分。
数据环境
信用评分模型的训练数据和预测数据分别来自学校学工、教务、一卡通及图书馆等平台。具体包括学生的基本信息、成绩信息、消费信息、借还书信息及奖惩信息。数据在学校数据中心进行集成,经过数据清洗整合,选取部分信息完整度较高的大四学生(供158名)数据进行建模。
模型构建
1. 多维评分体系
FICO评分是Fair Isaac公司开发的信用评分系统,也是目前美国应用得最广泛的一种,FICO分数已是被公认的衡量消费者信用等级的指标。FICO 评分系统得出的信用分数范围在 300~850 分之间,分数越高,说明客户的信用风险越小,它采集客户多维度信息,通过逻辑回归模型计算客户的还款能力,预测客户在未来一年违约的概率。
参考FICO评级模型,参考信用风险领域的要素分析法等理论体系,设计多维度的指标体系,经过多次迭代测算,确定各指标权重,计算用户信用得分。
目前指标体系包括学校财富a、履约情况b、经济情况c、消费情况d、其他e,设定不同指标权重后,计算公式如下:
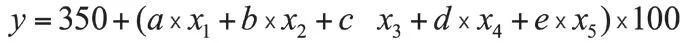
以横轴为信用分数,纵轴为人数百分比绘制评分图,由多维评分分布图得知,615~700得分的分布人数最多,这部分人群信用一般;550~615得分区间分布着大约12%的人群,信用较差;5%以下的人群得分小于550,信用极差;700~750得分的人群信用较好,占大约10%;750分以上信用极好,人群比例大约5%比。从目前的分析结果看,信用结果分布良好,基本符合正态分布。
2.机器学习——逻辑回归算法
机器学习采用经典的逻辑回归,选取158名学生的绩点、图书逾期时间、一卡通余额平均值、总消费、获奖等级及平均逾期率作为特征向量,将学生是否有过逾期行为作为是否违约的分类依据,有过违约行为为1,从未有过违约行为为0。按照3:1的比例对数据集进行随机划分,训练数据占比75%(共118条数据),测试数据占比25%(共40条数据)。得到测试数据的40名学生的违约概率p,然后对概率值 p 进行线性计算(350 + 600* (1-p)),得到最终的信用分数。在参数选择上,选用L2正则化方法,训练采用网格法进行超参数搜索,最终得到最优的超参数C=10。由于特征向量量纲维度不同,在做分析之前统一对数据集进行样本归一化处理。处理后数据使用python语言进行编程测试。得到结果如下:
逻辑回归评分分布仍符合正态分布,结果完全达到可用目标。
为了评估模型,用该预测结果计算了TPR与FPR值,绘制了ROC曲线并计算了AUC值。计算结果如下:
TPR值为:

图1 TPR值表
FPR值:

图2 FPR值表
AUC值为0.942。测试集的精准率为87.5%,召回率为78.6%,f1值为81.5%。
采用ROC曲线是因为:人群的违约情况中经常会出现类不平衡现象,而ROC有个很好的特性,测试集中的正负样本的分布变化的时候,ROC 曲线能够保持不变,能够准确反应模型优劣,如图3所示。AUC的值就是ROC曲线下面的面积,越大模型越准确。
服务方式
本项目面向大学生群体和企业机构分别采用两种不同服务模式。
数据服务
学生端:平台主要对学生提供信用评分查询、征信报告分析、信用管理服务、信用成长建议。学生可通过移动客户端充分了解自己的信用信息,根据信用建议调整自己的行为,增强信用意识。

图3 由逻辑回归算法结果得到的ROC曲线
企业端:向企业机构提供数据服务。信用报告形式,金融机构可直接根据本平台的分析结果对学生进行评级划分;数据接口形式,企业机构可利用数据接口获得相关信用数据辅助业务开展。
应用服务
以合作共赢的前提下,依托高校学生征信模型,融合企业方具体场景业务需要,协助企业构建生产环境的信用服务模型。
改进提升
模型迭代
根据已有数据结合提取的特征属性,使用专家评分法卡、机器学习、逻辑回归、深度学习方法进行初步的模型设计,通过调整模型参数和模型融合得到效果相对较好的模型。
更多的数据
引入更多的学生数据进行测试,检验模型的有效性,从而进一步地调整优化模型。
利用更多合作机构的数据,如信用卡数据、房屋租赁、工作等多方面的数据,进一步完善和迭代模型,使准确性更高。
进入大数据、人工智能时代后,高校沉淀的海量数据究竟应该如何发挥作用,能发挥哪些作用,这些疑问需要网络信息部门不断探索求证。不同角度看待高校信息部门做征信研究(金融类服务)是否恰当,一定会得到不同结论。参考阿里蚂蚁金服提出Techfin,对比金融机构Fintech的例子,网络信息中心作为高校IT技术的领先者和数据的集成管理者,未来的在角色定位应该是TechX,利用新兴技术(Tech)赋能其他部门(X),进一步发挥信息技术在教育教学、教育管理中的支撑引领作用,促进信息技术与业务的深度融合,为学校的学科建设、教学科研服务。
