基于交互机制卷积双流融合神经网络的视频浓缩
2019-04-15赵春飞张丽红
赵春飞, 张丽红
(山西大学 物理电子工程学院, 山西 太原 030006)
随着海量监控视频数据的产生, 使得能对视频数据进行有效浏览和分析的视频浓缩技术成为一个研究热点. Tonomuray 等人最早提出关键帧思想, 他们将每一小段视频的第一帧当做关键帧[1]. Pentland等人提出将视频序列按时间间隔等分, 从预定帧中选取关键帧[2]; Girgensohn等人充分考虑时间特征, 每隔相同时间提取关键帧, 基本可以描述整个视频内容[3]; Zhang等人提出根据帧间差分变化选取关键帧[4]; Negahdaripour等人通过进一步的研究提出光流表示图像动态空间变化以及光照辐射程度[5]; Yong Liu[6]等在物体检测时采用图结构并同时建模物体细节特征、 场景上下文以及物体之间关系, 从而实现物体检测; 胡岚清等[7]采用无监督域自适应双工生成对抗性网络进行物体检测. S.Bell等提出内-外网络: 利用跳过池和递归神经网络在上下文中检测对象[8].
上述方法都是人工定义的关键帧, 会丢失帧间的关联性, 而且目标之间的相互遮挡和背景复杂程度的不同, 使得视频浓缩很难实现高压缩率. 因此利用卷积神经网络[9]强大的特征提取能力和表示能力, 将交互机制融合到卷积神经网络可提高帧间的关联性, 以有效提高浓缩比.
1 基于交互机制的卷积双流融合神经网络模型
1.1 交互机制
图 1 中, ROI(Region of Interest)是感兴趣区域, scene是背景, edge是运动目标间的关系, 该交互机制相当于一个打分. 在背景指导下, 运动目标之间通过关系程度相互交互, 即运动目标接收背景的指导信息, 每个运动目标接收其他运动目标传递来的信息, 关系不同, 接收程度不同.
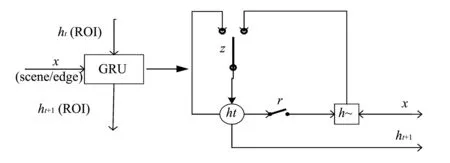
图 1 交互机制结构Fig.1 Interaction mechanism structure
所以, 交互机制也是消息传递, 采用门控循环单元GRU(Gated Recurrent Unit)实现. 例如, 当前运动物体需要接收背景信息, 那么将当前物体的状态作为隐状态, 背景信息作为输入, 输出即为接收信息更新后的物体状态; 同理当运动目标需要接收其他运动目标的信息, 同样将当前运动目标状态作为隐状态, 其他运动目标传递来的信息作为输入, 输出即为更新后的运动目标状态. GRU的门结构可以使得隐状态丢弃与输入无关的部分, 也可以选择与输入相关的部分来更新隐状态. 具体的GRU门结构工作原理为:
复位开关r通过式(1)计算
r=σ(Wr[x,ht]),
(1)
式中:x是输入;ht是运动目标前一时刻的隐状态;Wr是权重矩阵;σ是S型函数. 同理, 更新开关z通过式(2)计算
z=σ(Wz[x,ht]),
(2)
式中:Wz为权重矩阵.
更新后的状态ht+1用式(3)计算
(3)
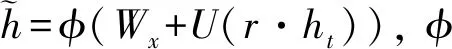
因此, GRU是一种有效的存储单元, 可以记住长期信息, 且GRU的初始状态为空或随机向量. 本文选择GRU的初始状态为随机向量.
1.2 卷积双流融合神经网络
卷积双流融合神经网络是将具有特定卷积层的两个网络融合在一起, 使得在相同像素位置的通道被放在相对应的位置. 这样, 如果一个物体在某个空间位置移动, 那么时间网络就可以识别这个物体, 空间网络就能识别物体位置, 从而得到物体的运动轨迹.
卷积双流融合神经网络的融合过程为:
1) 将特征图Xa,Xb在特征通道d的相同空间位置i,j通过式(4)进行堆叠
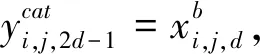
(4)
式中:y∈RH×W×2D.
2) 将1)得到的数据与滤波器f进行卷积
yconv=ycat*f+b,
(5)
式中:f∈R1×1×2D×D,b∈RD. 输出通道的数量是D, 而过滤器的尺寸是1×1×2D. 此时, 过滤器f用于将维度减少到原来的一半, 并且能够在相同的空间(像素)位置上对两个特征图Xa,Xb进行加权组合. 当在网络中作为可训练的过滤器内核时,f能够学习两个特征映射的对应关系, 从而最小化联合损失函数.
图 2 为两个卷积融合的示意图.
图 2(a) 为在第4个卷积层后融合,
图 2(b) 是在第5个卷积层和fc8后融合. 注入融合层可以对双流网络中的参数和层数产生重大影响, 特别是如果只保留被融合的网络, 而其他网络塔被截断, 如图2(a)所示. 两个网络也可以在两层融合, 如图2(b)所示. 这样就实现了从每个网络(在卷积5)中对通道进行像素级注册的最初目标, 但不会导致参数数量的减少(例如, 如果只在conv5层进行融合, 参数则会减少一半).
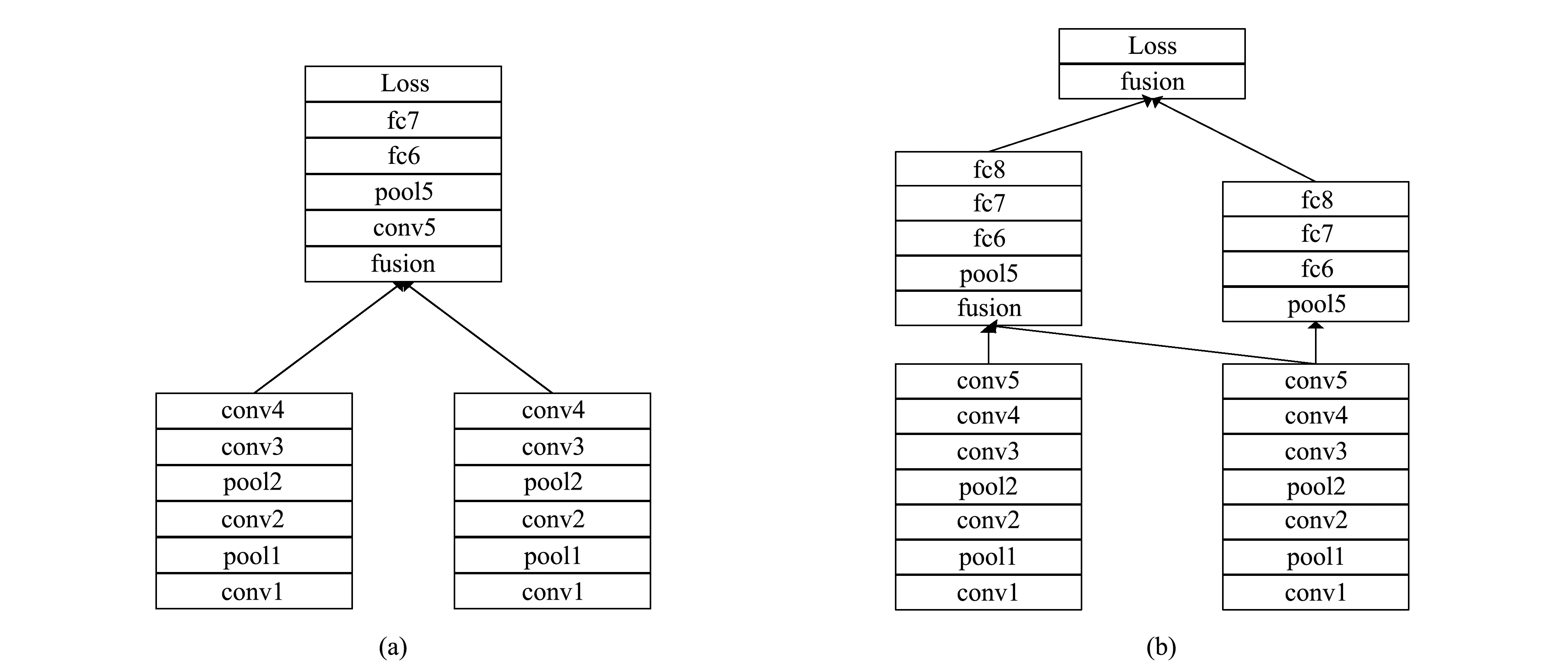
图 2 卷积融合示意图Fig.2 Convolution fusion diagram
表 1 比较了两个网络中不同层融合参数的数量. 使用VGG-M模型, 在不同的卷积层之后进行融合, 对参数的数量产生了大致相同的影响, 因为大多数这些参数都存储在全连接层中.
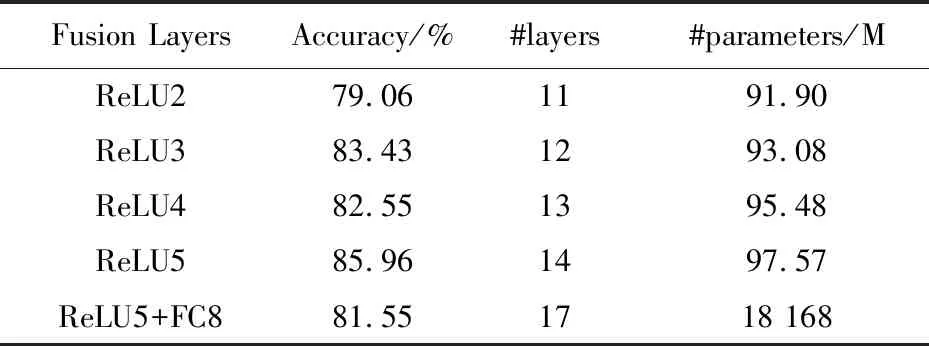
表 1 不同层融合后网络参数Tab.1 Network parameters of after different layers merged
在表 1 中比较了来自不同层的融合. 使用卷积融合, 融合层由与先前层的激活相加的单位矩阵初始化构成. 表1中, ReLU2, ReLU3, ReLU4, ReLU5表示融合发生的层数且采用ReLU激活函数; Accuracy表示在融合后的视频浓缩效果; #layers代表CNN的层数; #parameters表示网络中参数数量. 通过比较, 本文选取图 2(a) 作为融合结构.
1.3 基于交互机制卷积双流融合神经网络设计
基于交互机制的卷积双流融合神经网络如图 3 所示.
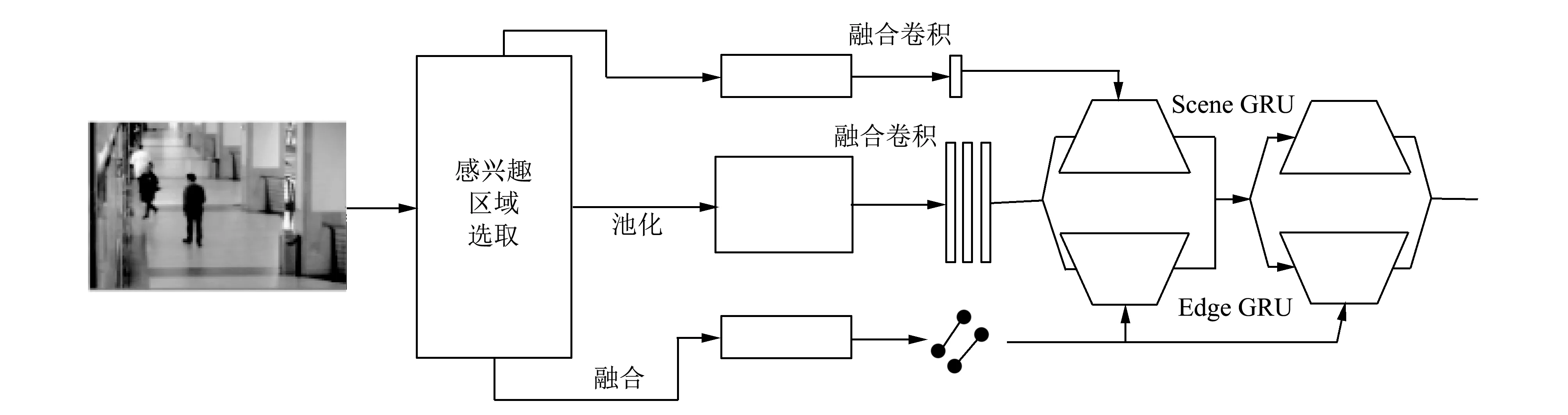
图 3 基于交互机制的卷积双流融合神经网络Fig.3 Convolutional fusion neural network based on interaction mechanism
在该网络中, 将输入的视频帧序列进行感兴趣区域ROI选取, 然后通过卷积融合神经网络提取运动目标和背景特征, 并将特征输入到交互机制结构中进行关联性运算.
在网络中的交互机结构中, 左边scene GRU接收场景信息, 将ROI特征作为隐状态, 场景特征作为信息输入. 右边edge GRU接收其他物体的信息, 通过关系程度计算每个物体传递的信息, 再pooling所有物体传递来的整合信息, 将整合后的信息传递到当前ROI. 两种GRU的输出融合为最终的状态表达, 作为物体状态. 当物体状态更新后, 物体之间的关系发生变化, 更多次的信息交互迭代可以更鲁棒地表示物体状态.
2 实验验证分析
2.1 实验准备及平台
在Windows Server 2008, 2.2 GHz, 14核, 31 GB ROM的服务器上搭建网络运行环境, 所使用的软件有Python, MATLAB.
所使用的实验数据如表 2 所示.

表 2 实验所用数据集Tab.2 Experimental data set
2.2 算法流程
基于交互机制的卷积双流融合神经网络的视频浓缩整体算法流程图如图 4 所示.
1) 读取输入视频文件;
2) 视频分解: 分割输入的视频数据文件, 读取视频数据信息, 获得对应的视频帧序列;
3) 特征提取: 用基于交互机制的卷积双流融合神经网络对步骤2) 的视频帧序列进行特征提取;
4) 相似性度量: 融合图像的多种特征来进行视频帧之间的相似性度量, 计算出视频的帧序列间相似矩阵;
5) 关键帧提取: 将步骤4) 得到的相似矩阵进行场景聚类, 然后计算视频帧到该聚类中心的距离, 将距离聚类中心最近的视频帧作为场景的关键帧;
6) 视频浓缩: 将提取出来的关键帧按照视频流中的先后顺序排列, 设置想要的帧率, 合成缩略视频;
7) 视频输出: 将缩略视频保存为avi 视频文件, 然后输出浓缩视频.
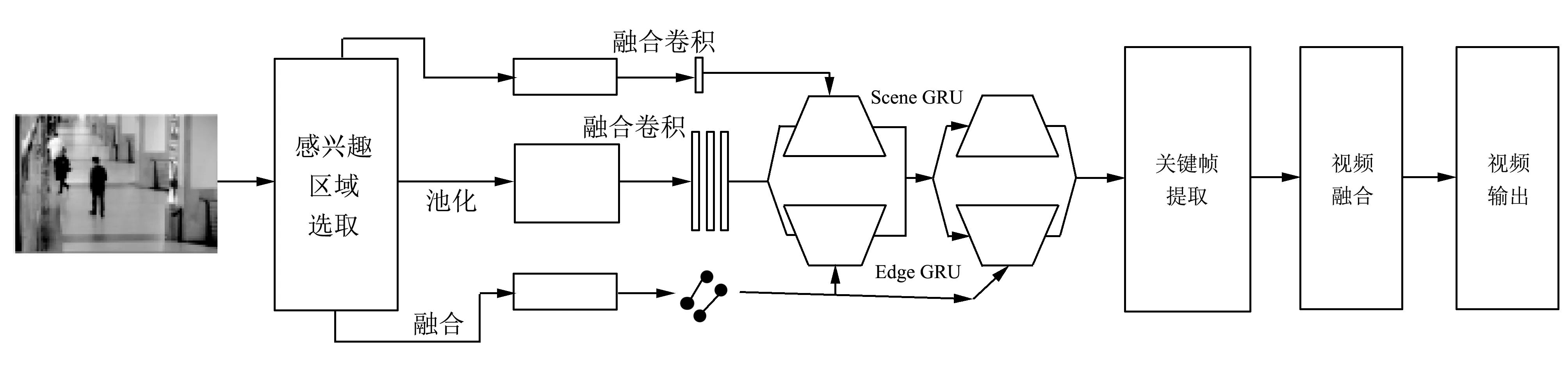
图 4 算法框图Fig.4 Algorithm block diagram
2.3 实验比较
2.3.1 视频浓缩评价指标
本文采用保真率[10]和压缩率[11]两个比较客观的指标来评价视频浓缩质量的好坏.
输入视频文件S包含有N个视频帧, 其帧序列表示为式(6); 浓缩视频F包含K个提取出来的视频关键帧, 其帧序列表示为式(7),
S={Si|i=1,2,…,N},
(6)
F={Fj|j=1,2,…,K}.
(7)
1) 保真率
保真率用来表征浓缩视频是否完整有效准确地表达了原始视频的结构和信息. 本文利用浓缩视频中的关键帧和输入视频中的视频序列之间的距离来计算保真率的大小.
关键帧序列Fi与原始输入视频文件S中任意一个视频帧Si之间的距离定义为式(8),
d(Si,Fj)=min{d(Si,Fj)|j=1,2,…,K}.
(8)
则浓缩视频和输入视频文件的距离用式(9)表示
d(S,F)=max{d(Si,F)|i=1,2,…,N}.
(9)
由此, 保真率的定义式为式(10),
FDLT=max{d(Si,Fj)|i=1,2,…,N,
j=1,2,…,K}.
(10)
2) 压缩率
压缩率用来表征视频浓缩结果的冗余度, 压缩率越大, 浓缩效果越好. 压缩率用式(11)定义,
RoC(S,F)=1-K/F.
(11)
2.3.2 实验结果
将本文所采用的方法和基于抽样的视频浓缩方法、 基于镜头分割的视频浓缩方法以及基于F-RNN的视频浓缩方法进行比较, 其结果如表 3, 表 4 所示.
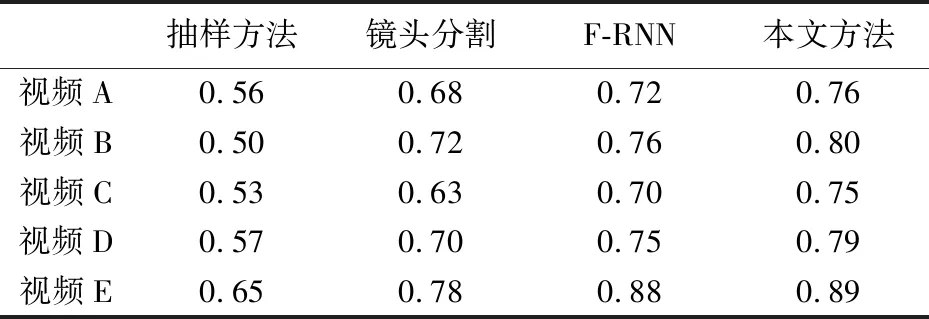
表 3 保真率比较结果Tab.3 Fidelity rate comparison result
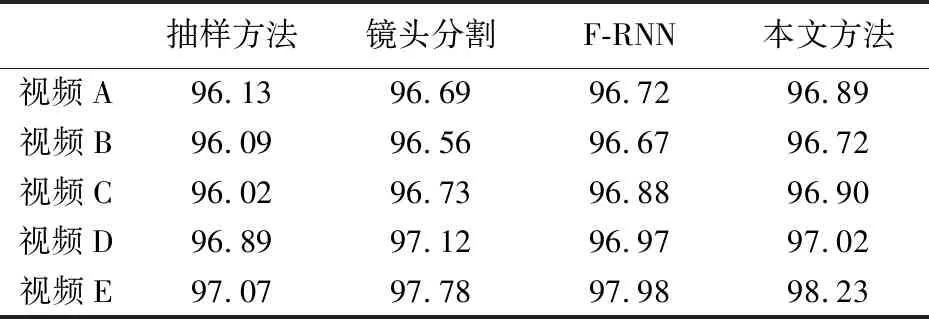
表 4 压缩率比较结果Tab.4 Compression ratio comparison result
从表 3 中可以看出, 对于背景简单的E类视频, 本文所用的方法和基于F-RNN的视频浓缩方法的保真度要优于传统的视频浓缩方法, 且保真度相近; 但是对于场景数量多而且复杂的视频, 本文所用方法的保真度明显优于其他3种方法. 从表 4 中可以看出, 视频中存在运动的目标或者是摄像机运动时, 本文所用的方法压缩率明显高于镜头分割的方法. 因为本文方法直接利用图像特征的差异对整个视频帧序列进行场景聚类, 避免了场景误检测的问题.
3 结束语
针对如何实现高压缩率的视频浓缩问题, 本文提出采用交互机制的卷积双流融合神经网络提取运动目标的特征并将其与背景特征结合起来进行聚类, 从而实现高压缩率的视频浓缩. 克服了传统方法中信息冗余度高、 特征关联性差等问题. 实验结果表明: 在保持原有信息的基础上, 本文提出的方法能有效提升浓缩视频的保真率和压缩率.
