基于CRTP模型的极端消极评论的内容价值研究
2019-04-12佘玉萍
佘玉萍,车 艳
(莆田学院 信息工程学院,福建 莆田 351100)
随着电子商务网站的发展,大量针对商品或者服务的用户评论也随着商品的销售而不断更新。在线用户评论成了用户体验的直接表现,也为后续用户参与提供了参考。用户评论一般有积极评论(也称为好评)和消极评论(也称为差评)两种,对用户体验有着积极和消极的影响。积极评论是商家和消费者都比较喜欢与关注的一类评价,而消极评论却是商家想删除的一类评价,但是反过来,如果能分析消极评论里提及的缺陷并进行改进,恰恰可以帮助商家提高产品及服务质量,对各商家自身改进具有现实及经济意义。
1 相关研究
对产品评级最高或最低分数是一种极端评级行为,存在评论者故意褒扬或诋毁产品的可能性。具体模型设置中,在五星评级体系中对产品评定为一星和五星,是一种极端评级行为[1]。研究表明情感极性通过评级体现,如五星评分制的系统中积极情感对应的产品评级为四星和五星。MUKHERJEE[1]等人发现,85%的虚假评论者发布的评论中80%的评论为积极评论,所以本文以商家的角度,从可信度更高的极端消极评论入手进行分析。站在商家的角度,消极的评论更真实,更有助于改进产品,即便是同行竞争者的虚假恶意评价,也可以起到防范作用。在这一背景下,用户评论,尤其是极端消极评论的效用分析成了电子商务的热点研究,同时也成为中文文本挖掘的研究热点。
相关研究中,评论内容质量问题通常被理解为评论内容对于有目的的信息使用的影响程度。随着大数据时代的到来,在线评论日益增多,海量的数据及其真假难辨的质量使评论的效用研究具有更好的现实意义[2]。目前对于评论效用评价的研究主要有以下方法:一类是以计量分析为主的评论效用评价研究,主要采用回归模型解释影响评论效用的重要因素。LU和MUDAMBI[3,4]等人把评论的质量看成是质量影响因素的线性组合,文献[2,5,6]则把评论的质量转化成多元线性回归的模型,提取了所有可获得的与评论内容相关的数据特征。尤其是从评论人特征以及面向评论内容的情感特征来探究评论对消费者和商家的效用价值。这类研究侧重主客观分析,缺少对评论内容进行进一步的语义分析。另一类是把评论效用评价分析转化为分类任务,利用机器学习的方法来构建分类预测模型。KIM[7]等利用支持向量机(SVM)分别从结构、词法、句法、语义、元数据5个文本特征对评论有用性进行研究。ZHANG ZHU[8]等人同样采用了SVM预测评论质量,发现了专有名词、情态动词等语言特征在预测时的贡献最显著。虽然SVM在文本分析上优于诸多其他分类算法,但结论不易被较好理解。
本文主要对评论文本内容进行深层次分析,因此围绕本文的研究目标,研究评论内容的内容价值。GHOSE[2]等人的研究面向英文评论内容,本文是基于中文评论内容,在研究评论效用评级CRTP模型的同时,主要从极端消极评论的获取,中文评论文本的词条化及词条间的联系进行了探索,最后通过实验进行了验证分析。
2 研究流程及模型
2.1 研究流程
本文以京东平台上洪恩教育官方旗舰店采集的点读产品(TTP581)的用户评论为研究数据,停用词采用的是文献[9]中的中文停用词表(共1893个)。极端消极评论的文本分析的流程是收集评论数据集,筛选出极端消极评论数据(即评论星级为1星),考虑消费者可能一次购买点读产品以及附属产品,但评论语却是多条重复的,考虑本文研究的是评论内容的效用性,所以删除同一个消费者账号下的重复评论,之后根据停用词表把评论进行过滤,接下去的任务也是研究的重点,如何进行有效的中文评论文本处理(简称CRTP模型,Chinese Review Text Processing)。极端消极评论文本分析的处理流程如图1所示。
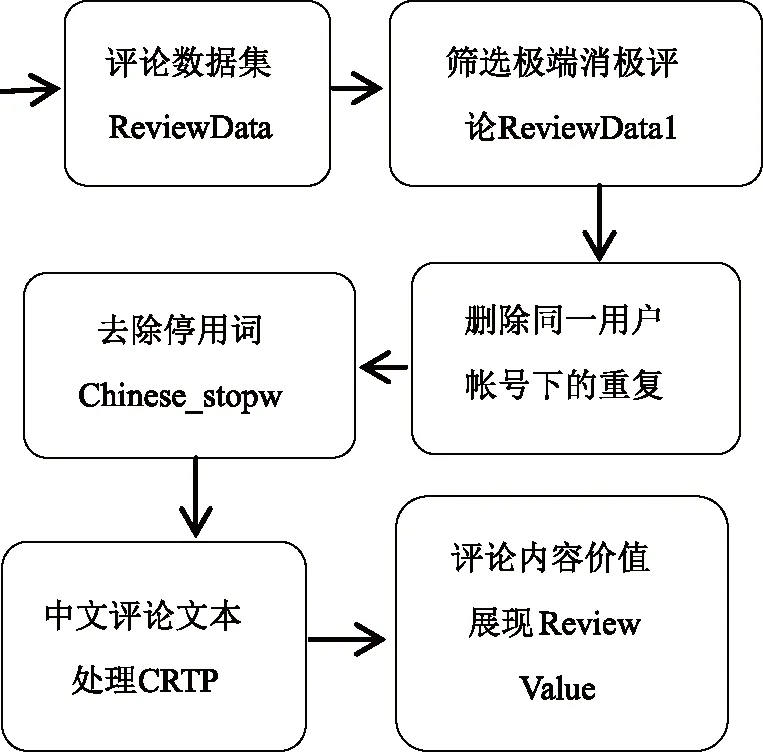
图1 极端消极文本分析的处理流程图Fig. 1 Process diagram of extreme negative text analysis
2.2 CRTP模型
本文提出了分析评论内容效用的模型,CRTP模型。评论内容效用分析要从中文文本挖掘入手,对评论语进行预处理,评论语词条化,最为关键的是如何挖掘评论内容的价值,本文主要研究词条间的联系,根据联系的紧密程度来观察词条的关系,进行预测评论的文本内容的效用。CRTP模型的目的就是有效进行评论语的词条化以及研究词条间的紧密联系。假设R={r1,r,…ri,…,rn}为极端消极评论集,T={t1,t2,…,tj,…tm}为评论词条集合。在构建CRTP模型前需要先构建一个评论词条矩阵(如表1所示),其中wij为tj在ri中出现的次数,如果第i个词条在第j个评论里多次重复出现,本文只做一次计数,这样可以杜绝同一个评论语里恶意多次复制同一个句子或者短语的现象。

表1 极端消极评论的评论词条矩阵
CRTP模型算法描述如下:
算法开始:
对于ri∈R,R={r1,r,…ri,…,rn},其中ri为第i条评论;
tj∈T,T={t1,t2,…,tj,…tm};其中tj为第j个词条;
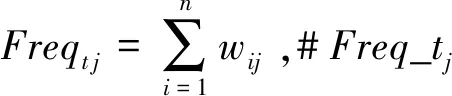
While (k
{
Term_freq_reli,j,p=min{Freqtp},p=1:k
#Term_freq_reli,j,p则为与ti同时出现在R中的p个tj次数。
如果Term_freq_reli,j,p>N,
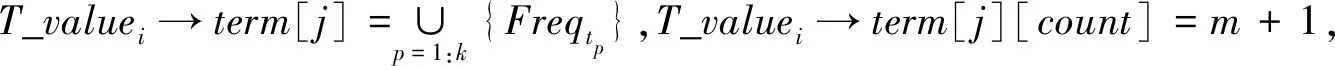
#T_valuei[term]为评论中与第i个词条有紧密关系的词条集合。
#Tvaluei[term][count]为与第i个词条有紧密
关系的词条出现的次数。
#Corelationi[j]为第i个词条与第j个词条的关联度
}
算法结束。
3 实验与结果分析
3.1 实验数据分析
本文的数据集是通过八爪鱼采集器采集到京东平台上的点读商品(TTP581)的5485条评论中筛选出的极端消极评论(1星)数据进行分析。测试数据集如表2所示。

表2 测试数据集(TTP581)的极端消极评论数据
对实验数据进行深度的文本分析,获取评论文本的词条关联关系,本文设计两组实验对用户极端消极评论文本进行CRTP模型运行,可以得到TTP581点读笔的极端消极评论次数超过20次以上且不是停用词的词条联系,如图2所示的中评论文本呈现可知,“难以沟通”、“京东客服”、“服务太差”、“外包装”、“气味太重”等这些评论语出现次数偏多,站在商家的角度,可以从这些评论词条的联系上着手对商品及其相关服务做相应改进。
为了进一步了解哪些词项在极端消极评论中出现的频率较高,还可以通过分析词项与出现的次数,如图3所示。在此基础上,商家就可以更加明确得到极端消极评论的显著问题所在,如“客服”、“点读”、“挂绳”等与产品及服务有关的词项出现的次数均较高。

图2 TTP581商品的极端消极评论出现次数超过20次以上且不是停用词的词条Fig. 2 Words of more than 20 times and not stop words of TTP581 extreme negative reviews
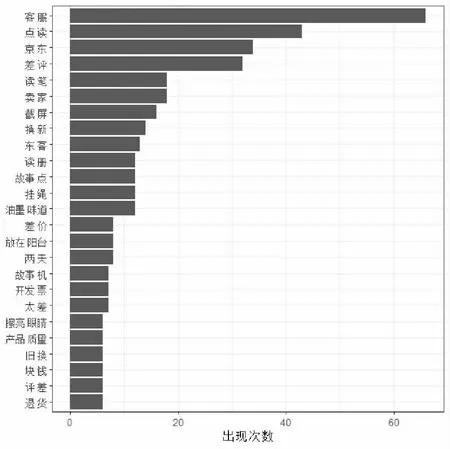
图3 TTP581商品的极端消极评论中出现次数较多的前25个关联词Fig. 3 Top 25 words of TTP581 extreme negative reviews
本模型还可以通过词项-关联度图来更为清楚观测感兴趣方面的问题所在,如本文通过实验查询了分别与“差”、“服务”、“产品”、“价格”这四个词条联系比较密切的词条,如图4所示。
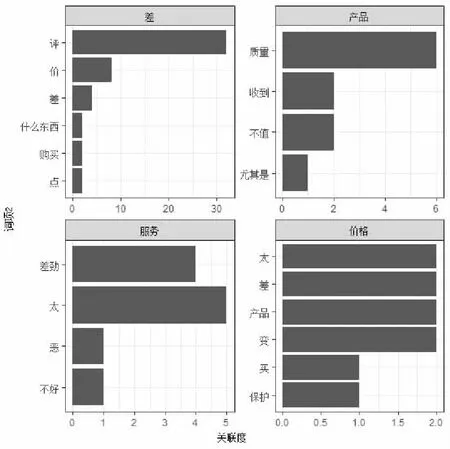
图4 TTP581商品极端消极评论中分别与“差”“服务”“产品”“价格”最相关的词条Fig.4 The most relevant words of “bad” “service” “product” “price” of TTP581 extreme negative reviews
3.2 CRTP模型验证
为了验证本文提出的CRTP模型的可靠性,通过了两个实验来验证。实验一是通过对本模型分析词项与其频数的分布图,如图5所示,由图5可知,少量的词项出现的频率极高或者较高,大部分词项的几乎不会出现,这在用户评论现象是普遍存在的。

图5 TTP581商品极端消极评论中所有词项与其频数图Fig.5 Term frequency of TTP581 extreme negative reviews
实验二是分析词项词频与排名的关系,如图6所示,从词项词频-排名曲线图以及其对应的拟合直线,可以看出拟合度还是较高的,拟合直线的斜率已经接近-1,这种分布是符合Zipf定律[10]。
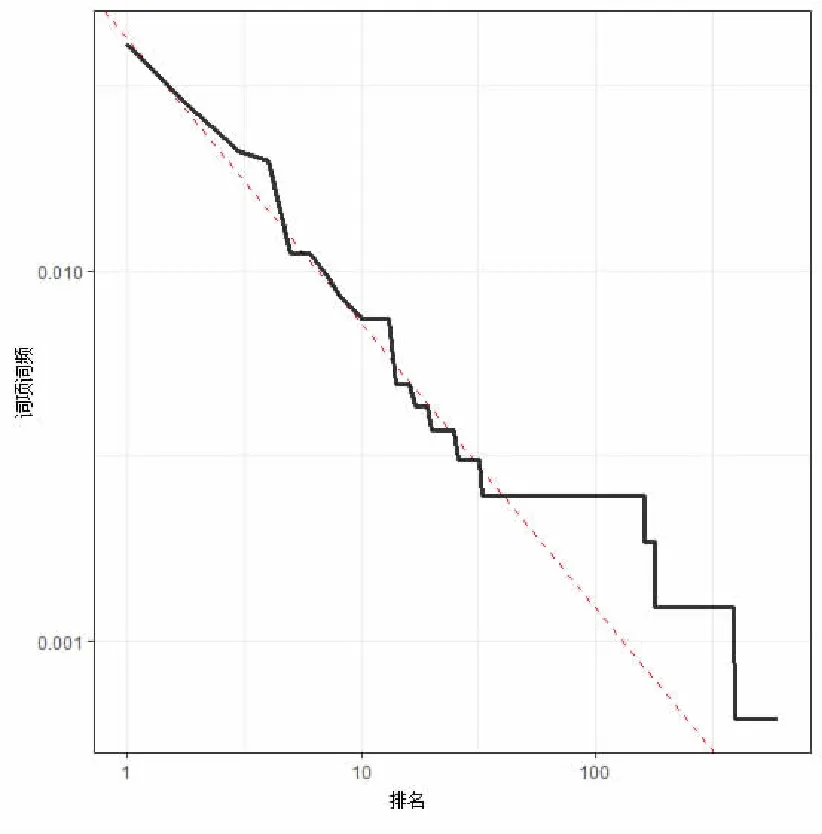
图6 TTP581商品极端消极评论中词项词频与排名的曲线图及其拟合直线图Fig.6 Curve graph of term frequency-term rank and its fit line
4 结束语
在线用户评论的分析是文本分析的一个领域,目前国内外已有很多研究[11],而中文用户评论的研究相对较少,且深入分析中文评论文本内容的几乎没有,针对极端消极评论文本内容分析从而获取改善商品的研究几乎没有。本文在面向极端消极评论的内容价值分析做了初步探索的同时,也以点读产品(TTP581)的评论数据得到了有助于改善商品的文本分析,且通过实验验证了CRTP模型的可靠性,但仍然有待于改进,如本文的极端消极评论只考虑评论星级为1星(最低)的情况,可能遗漏其他星级评论对商品的有效评论。
