几种相关系数辨析及其在R语言中的实现
2019-04-12金林,李研
金 林,李 研
(中南财经政法大学 统计与数学学院,湖北 武汉 430073)
一、引言
事物之间往往都存在着一定的联系。事物之间的联系包括确定性的函数关系和非确定性的统计相关关系。确定性的函数关系,指现象之间存在着严格的依存关系,且这种关系可以通过一个数学表达式表达出来。而统计相关关系,即不确定性关系,指现象之间不存在严格的依存关系,且这种关系没有唯一的数学表达式,一个变量的取值不能由另一个变量唯一确定。在实际中,不确定性的相关关系普遍存在。比如,子女身高与父母身高的关系,两者存在一定的相关关系,但没有一个确定的函数式可以把这种关系表达出来。19世纪末,Galton正是在研究父母身高与子女身高之间的关系时首次提出了相关的概念[1]。
Galton在其论文中将相关关系定义为“一个变量变化时,另一个变量或多或少也相应地变化”。相关关系指的是变量间存在某种关系,带有不确定性,不能用函数关系精确表达,当一个或几个相互联系的变量取一定数值时,与之相对应的另一变量的值虽然不确定,但它仍按某种规律在一定范围内变化。按程度对相关关系进行分类,可以分为完全相关、不完全相关和不相关。完全相关,指一个变量的变化由另一个变量的变化唯一确定,即函数关系。不完全相关,指相关关系在不相关和完全相关之间。不相关,指变量之间变化相互独立,没有关系。有的变量之间相关关系较强,而有的变量之间相关关系较弱。我们如何对相关关系的强弱进行测度呢?这正是相关分析所要解决的问题。相关分析侧重于发现随机变量间的种种相关特性,通过各种相关系数对相关关系的强弱进行量化。相关分析的种类很多,在各领域都有很广泛的应用,但是各种相关系数的适用条件以及它们之间的区别与联系在实际应用时带来很多的混淆。
本文对各种常见的相关系数进行辨析,给出它们在软件中的实现方法,并通过实际数据的例子来说明各种相关系数的应用。本文接下来的内容结构如下:第二部分就目前比较常见的相关性度量方法进行总结并辨析他们的适用条件和特点,第三部分给出各种相关系数在R软件中的实现方法,第四部分根据相关系数的适用条件选取2016年中国31个省市的数据进行了常见相关系数的计算,最后对各种相关系数的基本情况进行总结。
二、常用相关性度量
根据相关所涉及变量的多少或按影响因素的多少,相关性度量包括:变量与变量、变量与向量、向量与向量和多向量间的相关。两变量间的相关性度量主要有Pearson简单相关系数、Spearman和Kendall等级相关系数、Cramer’s V系数、偏相关系数及广义相关测度;变量与向量间的相关性度量主要是复相关系数;两向量间的相关性度量主要有典型相关系数和广义相关系数;多向量间的相关性度量主要由阿达玛不等式引出。
(一)两变量间的相关性度量
1.Pearson简单相关系数
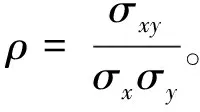
(1)
Pearson相关系数通常用来衡量两个连续变量之间的相关关系。其取值在[-1,1]之间,其绝对值|r|表示两变量间相关关系程度的强弱,越接近1,表明两变量间相关程度越高,它们之间的关系越密切。r>0表示正相关,r<0表示负相关,r=0表示不相关,|r|=1表示完全相关。r是样本统计量,其取值会受到抽样波动性的影响,因此一般可通过对r进行统计检验判断两个变量之间线性关系是否显著[3]。此外,需要注意的是,Pearson相关系数只是衡量两变量间线性相关程度的大小,r=0只表示两变量间无线性相关关系,但不能确定是否存在其他非线性相关关系。
2.Spearman等级相关系数
Spearman相关系数又称秩相关系数,是利用两变量的秩次大小作线性相关分析,对原始变量的分布不作要求,属于非参数统计方法,适用范围相对来说比较广。在Pearson提出简单相关系数之后,Spearman指出对于“大”“中”“小”这样的定序变量间的相关性,Pearson相关系数不再适用,进而提出了适用于定序数据的等级相关系数方法[4]。其基本定义为:2个定序随机变量X和Y的秩之间的Pearson相关系数。若变量X、Y的样本数据分别为x1,x2,…,xn;y1,y2,…,yn,则X、Y之间的Spearman等级相关系数可以表示为:
(2)
式中,ri和si分别表示xi和yi的秩,当变量里出现相等值的时候,该值对应的秩为这几个值对应的秩的平均值[5]。然而,实际应用中,为计算简便,可以通过被观测两个变量间的等级差值简化计算rs,计算公式为:
(3)
式中,rs表示等级相关系数;D为每对观测值的等级差;n为样本容量。rs的取值范围为[-1,1],当一个变量随另一个变量单调递增的时候,rs=1;反之,当一个变量随另一个变量单调递减的时候,rs=-1,具体可以参考樊嵘等的论述[5]。
Spearman相关系数对数据条件的要求没有Pearson相关系数要求严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量大小如何,都可以用Spearman相关系数进行研究。
3.Kendall等级相关系数
1938年,Kendall提出了计算等级相关系数的新方法[6]。Kendall相关系数的计算也是以变量X和Y的等级数据进行,根据配对等级顺序排列的位置是否颠倒或换位,得出等级换位的次数,进而进行计算。其计算公式为:
(4)
其中n为样本容量,Σi为换位总次数。
在测量等级相关方面,与Spearman相关系数相比,Kendall相关系数有更大的优势,Kendall相关系数的置信区间更容易解释,可靠性也更高[7]。两种相关系数在样本量小的时候,均不服从正态分布;当样本量较大的时候,均渐近服从正态分布。这里需要注意的是,Kendall相关系数只是说明两组数据相关性高低,并不反映线性相关程度的大小。
4.Cramer′sV系数
当两变量为名义变量时,上述相关系数都不再适用。Harald Cramer于1946年提出Cramer′sV系数,用于度量两个名义变量之间的相关性[8]。在由分类变量构建的列联表中,给定同时具有属性A、B的n个样本,nij(i=1,2,…,r;j=1,2,…,k)表示(Ai,Bj)被观测的次数,卡方统计量可以表示为:
(5)
其中ni.表示具有Ai属性的个体中所有具有Bj属性的观测频数,n.j表示具有Bj属性的个体中所有具有Ai属性的观测频数。根据卡方统计量可以定义Cramer′sV系数为:
(6)
Cramer′sV系数的提出是基于Pearson卡方统计量,其取值范围在[0,1]之间,其主要应用于大于2×2的列联表,在两个变量完全相关的情况下取值为1,在两个变量完全独立的情况下取值为0。
5.偏相关系数
在实际中,一个变量往往受到多种因素的影响,因而有必要研究多变量模型。在一元线性模型中,随机变量Y与X之间的相关系数即为Pearson相关系数,它反映的是Y与X之间线性相关关系的程度。在多变量构成的系统中,当研究一个变量对另一个变量的影响或相关程度时,把其他变量的影响视为固定的,即暂不考虑其他变量的影响,单独研究两个变量之间的相互关系的密切程度,所得数值结果即为偏相关系数。偏相关系数的具体计算过程如下:
给定X、μ、Σ,分别表示随机向量、均值向量和方差协方差阵,将其作如下剖分:
(7)
则给定X2时,xi和xj的偏相关系数定义为:
(8)
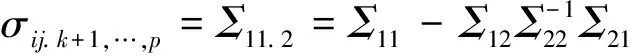
偏相关分析的主要作用在于,在所有的自变量中,判断哪些自变量对因变量的影响较大,从而选择比较重要的自变量,至于那些对因变量影响较小的自变量就可以舍去,不予考虑。
6.广义相关测度
Pearson简单相关系数、Spearman和Kendall等级相关系数、Cramer′s V系数等都具有对称性,也即两个变量之间的地位是平等的,改变变量顺序不影响相关系数的大小。但在实际中,有些变量之间的相互影响并不是对称的。Zheng于2012年引入广义相关测度(Generalized Measures of Correlation)的概念对两个变量之间的非对称性相关关系进行测量[9]。假设两变量分别为X和Y,则广义相关测度具体定义为:
(9)
所以得到X和Y之间一对广义相关度量如下:
{GMC(Y|X),GMC)X|Y)}=
(10)
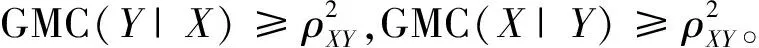
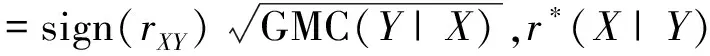
(11)
其中,sign(rXY)表示Pearson样本相关系数(rXY)的正负性,也即广义相关测度的平方根赋予了Pearson样本相关系数的符号。广义相关测度的样本估计量一般使用非参数方法得到,估计的具体过程和估计量的最终形式可以参见Zheng等(2012)的文章[9]。
(二)变量与向量间的相关性度量:复相关系数
有时候,我们需要考虑一个变量x1与其他多个变量x2,…,xp之间的相关性,这种相关性可以达到多高的程度,能不能用一个数值将其表示出来。这时可以构造一个关于x2,…,xp的线性组合,通过计算该线性组合与x1之间的简单相关系数作为变量x1与x2,…,xp之间的相关性度量。
给定X、μ、Σ,分别表示随机向量、均值向量和方差协方差阵,将其作(7)式的剖分,取k=1,则x1和X2的线性函数lTX2间的最大相关系数即为x1和X2间的复相关系数,记作ρ1.2,…p,它度量了一个变量x1与一组变量x2,…,xp间的相关程度。其计算公式为:
(12)
一个简单的求解复相关系数的方法是,用xi和x1,…,xi-1,xi+1,…,xp做辅助回归,可决系数R2的算术平方根即为复相关系数。需要注意的是,简单相关系数的取值范围在[-1,1]之间,而复相关系数的取值范围是[0,1]。这是因为,在两个变量的情况下,回归系数有正负之分,所以在研究相关时,也有正相关和负相关之分;而在多个变量时,偏回归系数有两个或两个以上,其符号有正有负,不能按正负来区别,所以复相关系数只能取正值。
对于复相关系数的应用,一般不会单独进行复相关系数的研究,往往与回归分析结合在一起,对回归分析的结果进行解释时,复相关系数起到一定的解释作用,复相关系数越大,说明解释变量与因变量有较强的相关性。
(三)两向量间的相关性度量
相关的概念不仅可以应用于变量与变量或变量与向量之间,而且还可以应用于两个或多个随机向量之间。
1.典型相关系数
典型相关分析由Hotelling在1936年首次提出,是利用综合变量对之间的相关关系来反映两组指标之间的整体相关性的多元统计分析方法[10]。其基本原理是:为了从总体上把握两组指标之间的相关关系,分别在两组变量中提取有代表性的两个综合变量U1和V1(分别为两个变量组中各变量的线性组合),利用这两个综合变量之间的相关关系来反映两组指标之间的整体相关性。
定义随机向量X=(X1,X2,…,Xp)′,Y=(Y1,Y2,…,Yq)′,它们的协方差矩阵为:
(13)
为研究两组变量之间的关系,考虑其线性组合:
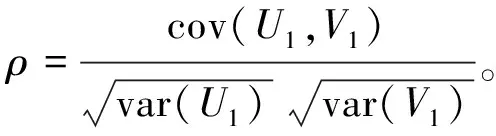
(14)
在实际问题分析中,当面临两组多变量数据,并希望研究两组变量之间的关系时,就要用到典型相关分析。典型相关分析有助于综合地描述两组变量之间典型的相关关系,其条件是,两组变量是连续型变量,且服从多元正态分布。
2.广义相关系数
广义相关性是两组随机向量之间的相关性,是简单相关、复相关、典型相关性的推广。张尧庭于1978年提出了广义相关系数的概念,并证明了其合理性[11]。
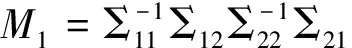
1)全部非零特征根的算术平均数:
2)全部非零特征根的几何平均数:
3)全部非零特征根的调和平均数:
4)全部非零特征根的最大值:
5)全部非零特征根的最小值:
广义相关系数满足相关系数的基本性质,具有对称性,其取值范围为[0,1]。广义相关系数可以应用于多元线性模型的假设检验问题导出相关统计量,多元逐步回归导出递推公式,还可以应用于多元聚类分析中得到新的聚类方法。广义相关系数与其他相关系数之间有一定的联系。当随机向量X、Y退化为随机变量x、y时,此时M1为一维矩阵,x、y间简单相关系数的平方即为广义相关系数(此时上面5种广义相关系数都相同);当随机向量X退化为随机变量x时,此时M1也为一维矩阵,x与Y间复相关系数的平方即为广义相关系数;线性相关阵特征值λ即为X、Y间的典型相关系数的平方。
(四)多向量间的相关性度量
在测度多向量间的相关性之前,我们首先需要了解阿达玛不等式。
设X~Np(μ,Σ),对X、Σ作如下剖分:
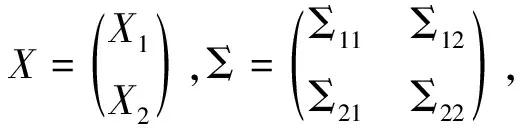
(15)
已知k个向量X1,X2,…,Xk,分别为p1,p2,…,pk维,则cov(Xi,Xj)=Σij有pi×pj个:
那么可以定义
(16)
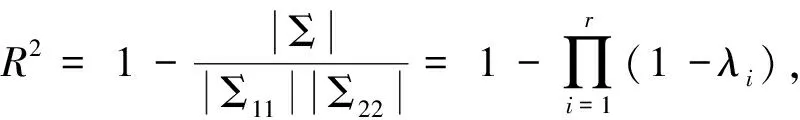
三、相关系数的R软件实现
下面我们对上面介绍的各种相关系数在统计软件R中的实现进行说明。在R软件中,对于不同相关系数的计算有相应的函数,运用cor ()函数可直接算得两变量间的简单相关系数,assocstats()函数可以进行Cramer’s V系数的计算,pcor()函数可以进行偏相关系数的计算,gmcmtx0()可以进行广义相关测度系数的计算,cancor()函数可以进行典型相关系数的计算,对于复相关系数、广义相关系数及多向量间的相关系数则可以根据公式自定义函数编程实现。具体的函数定义及相关计算方法如表1所示。

表1 R中各相关系数函数的用法
自定义函数的代码和解释如下所示:

###R中复相关系数的计算:fcor<-f+unction(x,Y){ x<-scale(x) y<-scale(Y) sigma11<-cov(x,x);sigma12<-cov(x,y);sigma21<-cov(y,x); sigma22<-cov(y,y)r<-(sigma12%∗%solve(sigma22)%∗%sigma21/sigma11)^(1/2) return(r)}
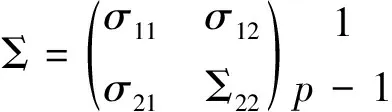

###R中广义相关系数的计算:gcor<-function(X,Y){x<-scale(X);y<-scale(Y) sigma11<-cov(x,x);sigma22<-cov(y,y) sigma12<-cov(x,y);sigma21<-cov(y,x) m1<-solve(sigma11)%∗%sigma12%∗%solve(sigma22)%∗%sigma21 r<-qr(m1)$rank; lambda<-eigen(m1)$values r1<-(1/r)∗sum(lambda);r2<-prod(lambda)∧(1/r) r3<-1/((1/r)∗sum(1/lambda)) r4<-max(lambda); r5<-min(lambda) return(list(r1,r2,r3,r4,r5))}

###R中多向量间相关系数的计算:mulcor<-function(mylist){ data<-as.data.frame(mylist) standard<-scale(data);sigma<-cov(standard) for(i in 1:length(mylist)){ r2<-1-det(sigma)/prod(det(cov(mylist[[i]]))) return(r2) }}
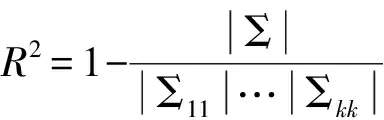
四、实例分析
在给出了常见的相关性度量及其在R软件中的实现后,为了进一步对其进行说明,下面运用2016年中国31个省市的宏观经济数据,选取经济发展、能源消耗和环境污染三个方面下的不同指标,根据相关系数的适用条件,选择合适的指标对以上相关系数分别进行计算并做出相应分析。
地区生产总值代表了一个地区的经济发展水平,考虑到居民生活水平也从另一侧面反映一个地区的经济发展,且相对来说第二产业产值与能源消耗和环境污染的关系更大,因此选取地区生产总值、居民人均可支配收入及第二产业产值占地区生产总值的比重作为反映经济发展状况的指标。根据主要的能源消耗,选取煤炭消耗量、油品消耗量、天然气消耗量及电力消耗作为衡量能源消耗的指标;同时选取废水排放量、废气排放量、工业固体废物排放量及污染治理完成投资衡量环境污染。具体指标结构如表2所示。
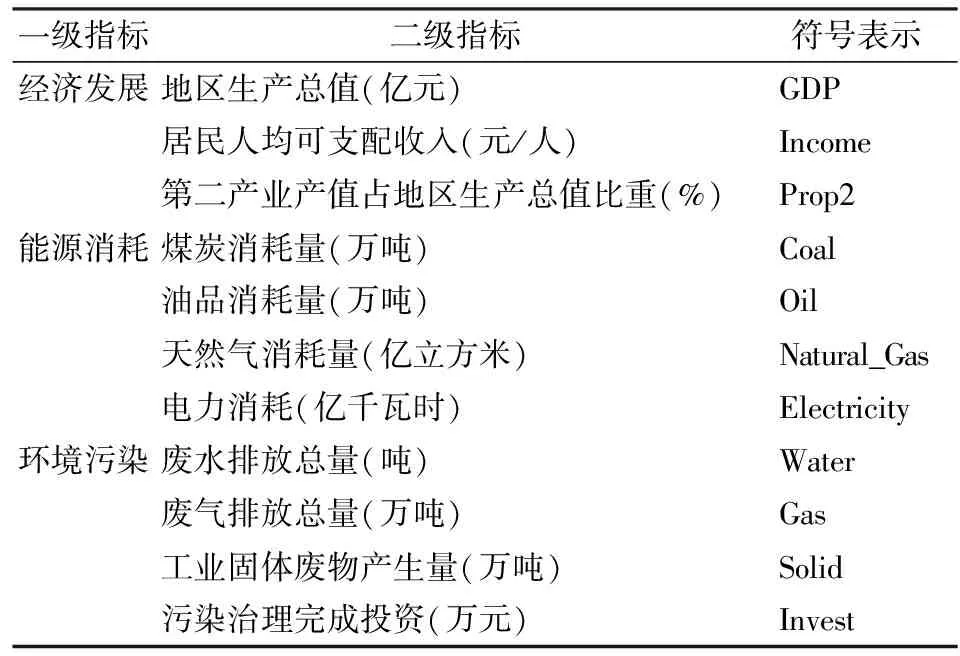
表2 经济-能源-环境指标体系
各指标数据来源于《中国统计年鉴2017》《中国能源统计年鉴2017》及《中国环境统计年鉴2017》。在数据获取中,西藏在能源消费总量、废水、废气排放量这些指标上存在缺失数据,因此本次研究范围限定在除去西藏以外的其他30个省市。我们可以认为这30个省市的这些指标数据都是相互独立的,进而可以进行一系列相关系数的计算,且所有相关系数的计算均在R 软件中进行,检验的显著性水平均取0.05。在计算之前,首先对原始数据进行标准化处理以消除量纲的影响。
(一)简单相关系数和偏相关系数的计算
在所构建的指标体系中,选取经济发展中最具代表性的GDP和环境污染中的各变量计算相关系数。在实际应用中,根据散点图的分布更能清晰地看出变量之间相关关系的强弱和具体关系。我们可以把变量间简单相关系数矩阵和散点图矩阵放在一个图形中,结果如图1所示。
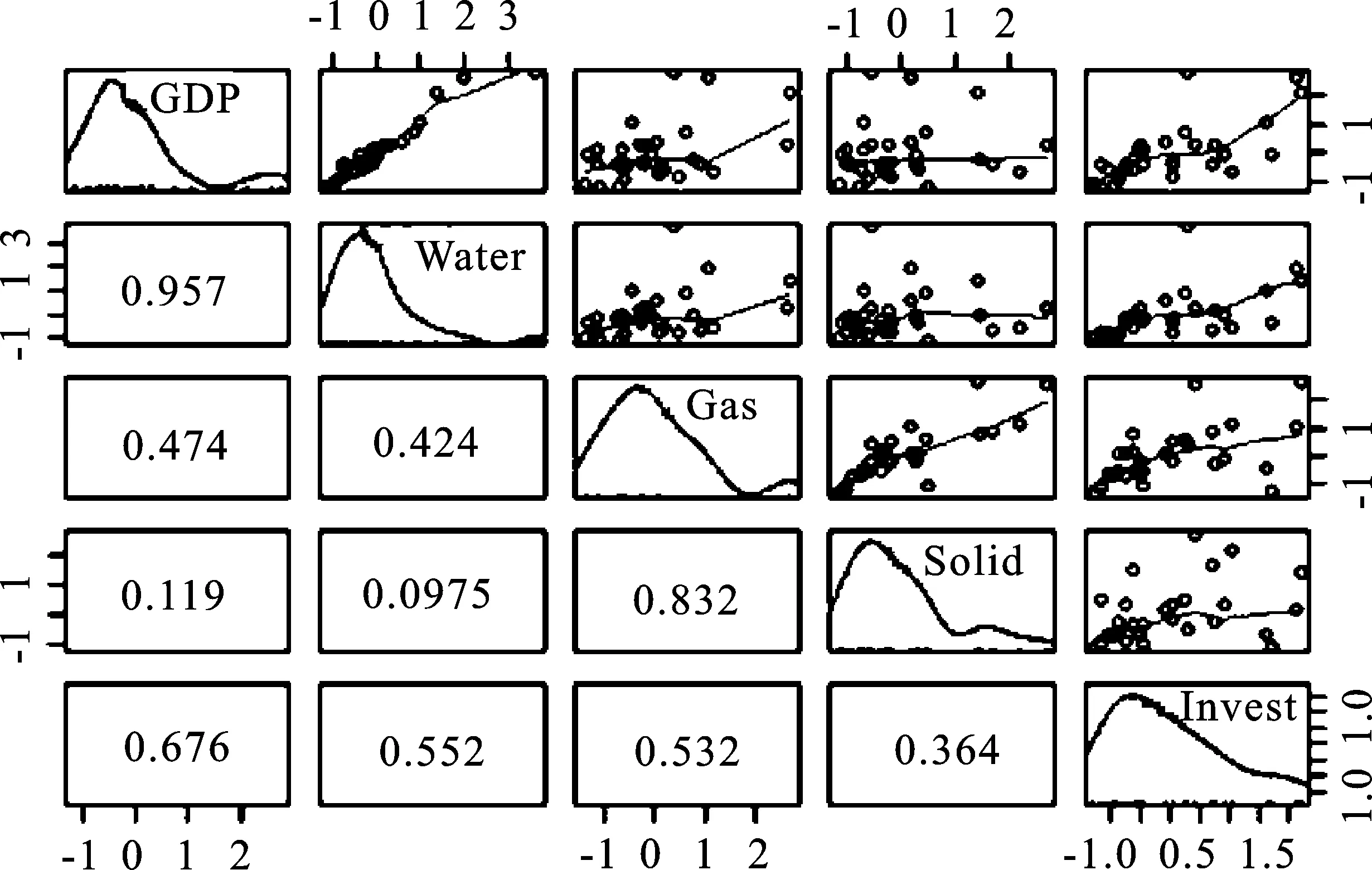
图1 GDP与环境污染变量间的矩阵散点图
图1表示GDP与环境污染各变量两两之间的相关系数,上三角部分表示变量之间的散点图及非参数回归曲线的具体形式,下三角部分表示变量间相关系数的大小,对角线表示各个变量自身的分布情况。根据上图结果并结合相关检验可知,就GDP与环境污染各变量来看,GDP与废水排放量之间的相关性最强,相关系数达到了0.957,其次是污染治理完成投资,相关系数为0.676,最后是废气排放量,相关系数为0.474,而其与工业固体废物产生量之间不存在显著的线性相关关系。
选取GDP、能源消耗及环境污染中的各变量,计算GDP和能源消耗量及环境污染中各变量之间的偏相关系数,计算结果如表3所示。
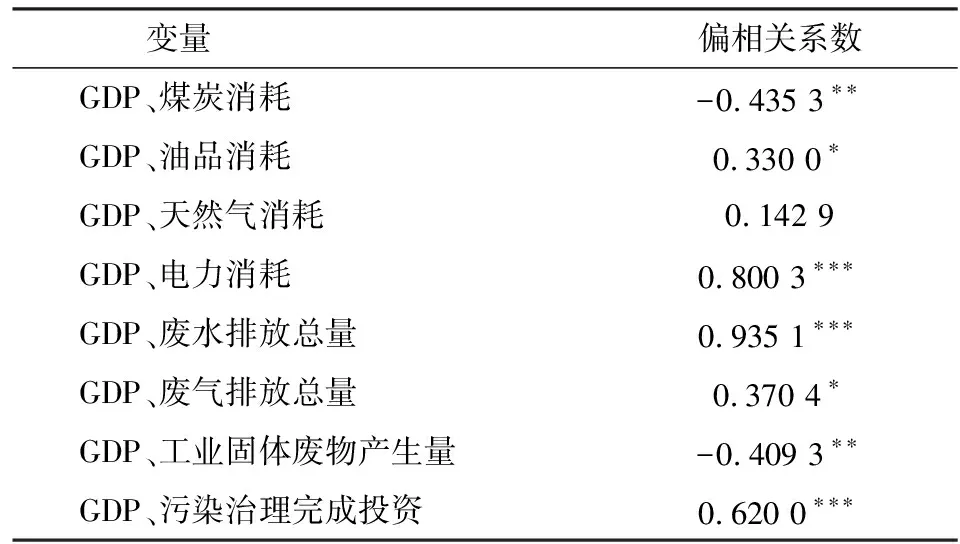
表3 两变量间偏相关系数度量结果
注:***、**、*分别表示在1%、5%及10%的显著性水平下显著。
由上表可知,除天然气消耗外,GDP与其他变量间的偏相关系数均通过显著性检验。GDP与电力消耗间的偏相关系数为0.800 3,这表明在固定煤炭消耗、油品消耗及天然气消耗的情况下,GDP与电力消耗之间存在显著的正相关关系;同理可解释GDP与其他变量的偏相关系数。值得注意的是,GDP与煤炭消耗、工业固体废物产生量之间存在负的偏相关系数,这好像与我们的实际认知存在一定的偏差,这主要是因为对于中国各省份来说,GDP较发达省份的能源供应结构更为合理,单位GDP煤炭消耗量较低,单位GDP工业固体废物产生量也相对较低。
(二)复相关系数的计算及解释
选取GDP、能源消耗及环境污染中的各指标,计算GDP和能源消耗及环境污染之间的复相关系数。计算结果为:GDP与能源消耗的复相关系数为0.953 8,GDP与环境污染之间的复相关系数为0.977 8。这说明GDP与能源消耗及环境污染之间均存在极强的正相关关系。
(三)典型相关分析
选取经济发展、能源消耗及环境污染各指标组成的向量,分别计算两向量之间的典型相关系数。计算结果为:经济发展与能源消耗之间的第一对典型相关系数为0.954 2,且通过显著性检验,该结果表明经济发展与能源消耗之间存在极强的正相关关系。进一步来看,两者之间的第一对典型变量的线性组合为:
U1eco,energy=0.188 8GDP-0.007 7Income-
0.002 2Prop2
V1eco,energy=-0.042 0Coal+0.032 0Oil+
0.008 3NaturalGas+0.179 3Electricity
其中U1eco,energy表示经济发展的各指标的线性组合,V1eco,energy表示能源消耗的各指标的线性组合。根据变量前的系数可以发现,在经济发展中,GDP起主要作用,在能源消耗中电力消耗起主要作用。说明在经济发展与能源消耗之间的关系中,GDP与电力消耗之间密切相关。
同样可得到经济发展与环境污染之间的第一对典型相关系数为0.982 8,能源消耗与环境污染之间的第一对典型相关系数为0.962 2,均通过显著性检验,结果表明经济发展与环境污染、能源消耗与环境污染之间都存在极强的正相关关系。通过典型相关分析可知,2016年中国各地区的经济发展、能源消耗和环境污染两两之间存在非常强的相关关系。
(四)多向量间的相关
上面的典型相关分析是两个向量两两之间进行分析。我们也可以把几个向量放在一起衡量它们之间的整体相关性。选取经济发展、能源消耗和环境污染各指标组成的向量,进行三个向量之间相关系数的计算。计算结果为:经济发展、能源消耗、环境污染三者之间的相关系数为0.999 9,表明在所研究的范围内,三者之间存在极强的正相关关系。这与典型相关分析的结论是一致的。
通过以上的各种相关分析表明,在当前时期,中国的经济发展、能源消耗和环境污染三者之间密切相关,且存在明显的正相关关系。在当前经济模式下,经济高速发展是以消耗更多的能源并造成严重环境污染为代价的,这样的经济增长难以持续。因此,当前中国必须转变经济发展方式,推进绿色发展、循环发展、低碳发展,节约资源和保护环境,实现经济社会的可持续发展。
五、总结
本文根据涉及变量的多少和变量的类型,对变量与变量、变量与向量、向量与向量、多向量之间的相关性进行了总结。大致可以归纳如下:1.变量与变量之间的相关性主要由Pearson相关系数、Spearman相关系数、Kendall相关系数、Cramer’s V系数及偏相关系数进行度量,同时还介绍了广义相关测度。当涉及两个连续型变量时,Pearson相关系数用来刻画其线性相关关系,当涉及定序数据时,Spearman和Kendall等级相关比较适合,当涉及名义变量时,用Cramer’s V系数进行计算;如果同时存在多个变量(大于等于三个),研究其中两个变量间的相关性,则用偏相关系数进行度量,偏相关系数主要出现在回归分析中,研究某个自变量在忽略其他自变量时对因变量的影响;若两个变量之间存在非对称相依性,则使用广义相关测度较为合适。2.变量与向量之间的相关性主要由复相关系数进行度量,复相关系数也主要出现在回归分析中,描述一个变量对多个变量的线性相关关系。3.向量与向量之间,也即两组多变量之间的相关性可以用典型相关系数进行度量,其主要是运用主成分分析的思想,通过降维,来研究综合变量之间的简单相关系数,达到研究两组多个变量相关关系的目的;同时还可以使用广义相关系数度量两组随机向量之间的相关性。4.多向量之间的相关性主要由阿达玛不等式引出。现将各种相关系数的具体情况总结在表4中。
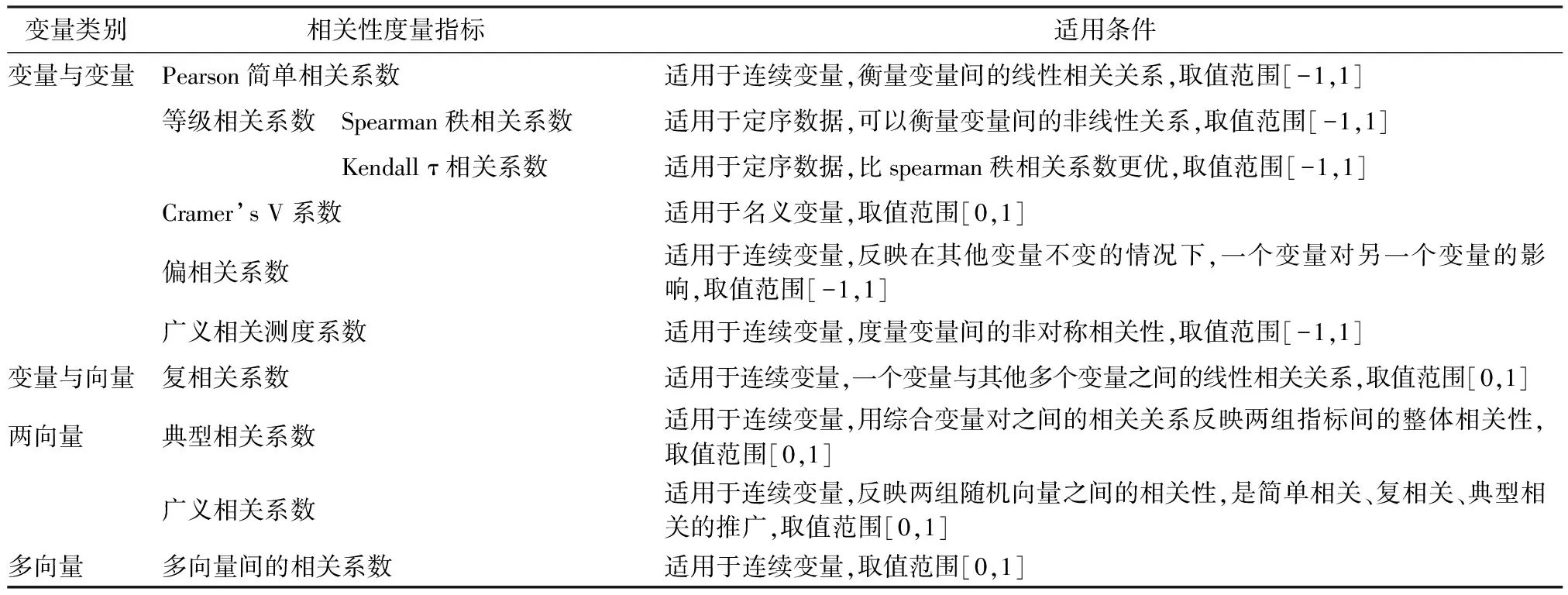
表4 各相关系数适用条件总结
最后需要指出,在使用相关系数的时候,应该注意两个方面问题:一是以上各种相关系数都是基于数据是相互独立的假设,也即只有满足变量的样本数据是独立的条件,才能使用以上相关系数度量变量之间的相关性强弱。如两个时间序列数据不满足这个条件,因此在时间序列分析中,我们就不能直接使用以上这些相关系数。二是在大部分相关分析中,变量之间的关系是对等的,改变变量的顺序不影响相关分析的结果。这与回归分析中变量区分为因变量和自变量有很大的区别。我们在解释相关系数的时候应特别注意这一点。相关系数只能表明变量之间是否存在相关关系,而不能表明变量之间是否具有因果关系。
