基于改进贝叶斯算法的垃圾短信过滤研究*
2019-04-11金小梅毛本清
金小梅,毛本清
(衢州学院,浙江 衢州 324000)
现实生活中,我们手机用户经常会接到诸如中奖、返税等诈骗短信,严重影响了我们的正常生活,有的已经对部分用户造成不小的经济损失。手机垃圾短信现象不仅在我国大量存在,在欧美等发达国家也广泛存在,已成为世界性的问题。因此如何从已有的手机短信中挖掘出垃圾短信的特点,从而对短信进行分类,成为相关领域专家的研究重点。
现有手机垃圾短信拦截技术主要分为以下两类:①手机号码的黑白名单技术[1]。对未备案的短时间内发送大量短信的号码添到黑名单列表,实现垃圾短信的拦截。②文本内容过滤技术。邻近分类算法(k-Nearest Neighbor,简称KNN算法)、决策树与朴素贝叶斯算法是其中的代表,主要包括三个方面,分别是基于文本内容过滤、基于规则过滤与基于关键字过滤。
朴素贝叶斯算法是文本文档分类算法中较为有效的算法,其特点是速度快、效率高、耗费少、应用广泛,由于稳定性较好、实现简单,且易于开发维护,因此能够满足手机短信过滤要求。
1 朴素贝叶斯算法
朴素贝叶斯算法思想核心是求解向量X=(x1,x2,…,xm),归属C=(C1,C2,…,Ck)的概率值p(Ci∣X),最大的概率值所对应的Cj即为X 所属类别。过程如下[2]:
设A 代表训练数据集A1,A2,…,Am;k 个类:C1,C2,…,Ck;用m 维特征向量来表示数据样本x 各属性值,即X=(x1,x2,…,xm),其中xi∈Ai(1≤i≤m)。
计算数据集各类中各属性的条件概率,即p(xi∣C1),p(xi∣C2),…,p(xi∣Ck),(1≤i≤m)。
根据条件概率和朴素贝叶斯算法的假定,计算未知样本在各类中的后验概率:
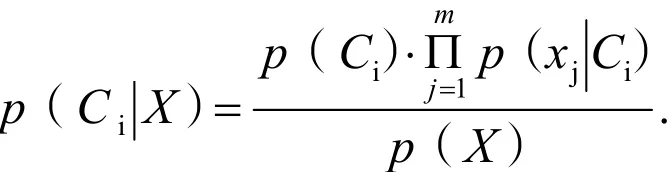
后验概率的最大值所对应的类即为该未知样本的分类:

由以上步骤可知,朴素贝叶斯分类模型的实现,主要分为4 个部分:①假定X=(x1,x2,…,xm)为一个待处理的分类文本,xi为X 的第i 个特征属性向量;②类集合C(C1,C2,…,Ck)为预先类集合;③计算p(C1∣X),p(C2∣X),…,p(Ck∣X);④如果存在p(Cj∣X)=max{p(C1∣X),p(C2∣X),…,p(Ck∣X},则X∈Cj.
因此,我们可以根据训练集来计算某已知文本类的先验概率,再计算其后验概率,对后续新的文本类进行分析预测,在已知的分类概率的条件下,由此可得待处理文本属于某一类概率值,最后取其中的最大值,将待处理文本归类到最大值的那类中。需要说明的是,类别之间是相互独立的,模型具有收敛性。朴素贝叶斯算法阈值分类流程如图1 所示。
贝叶斯算法虽然速度较快、正确率高,但存在误判的情况[3]。在朴素贝叶斯公式中,如果,待定样本X 即归为Ci类,反之为Cj类,但如果样本比例不均衡,容易造成误判,为避免误判造成的损失,我们采取自学习方式进行,选择合适阈值提高模型准确性。阈值α的具体选择依赖于其在训练数据集上的表现,当时,把待定样本归为Ci类,如果本属Ci类的样本,结果错判给Cj类的较多,则我们可以取阈值;如果本属Cj类的样本,结果错判给Ci类的较多,则取阈值,这样能显著提高模型的准确率[4]。
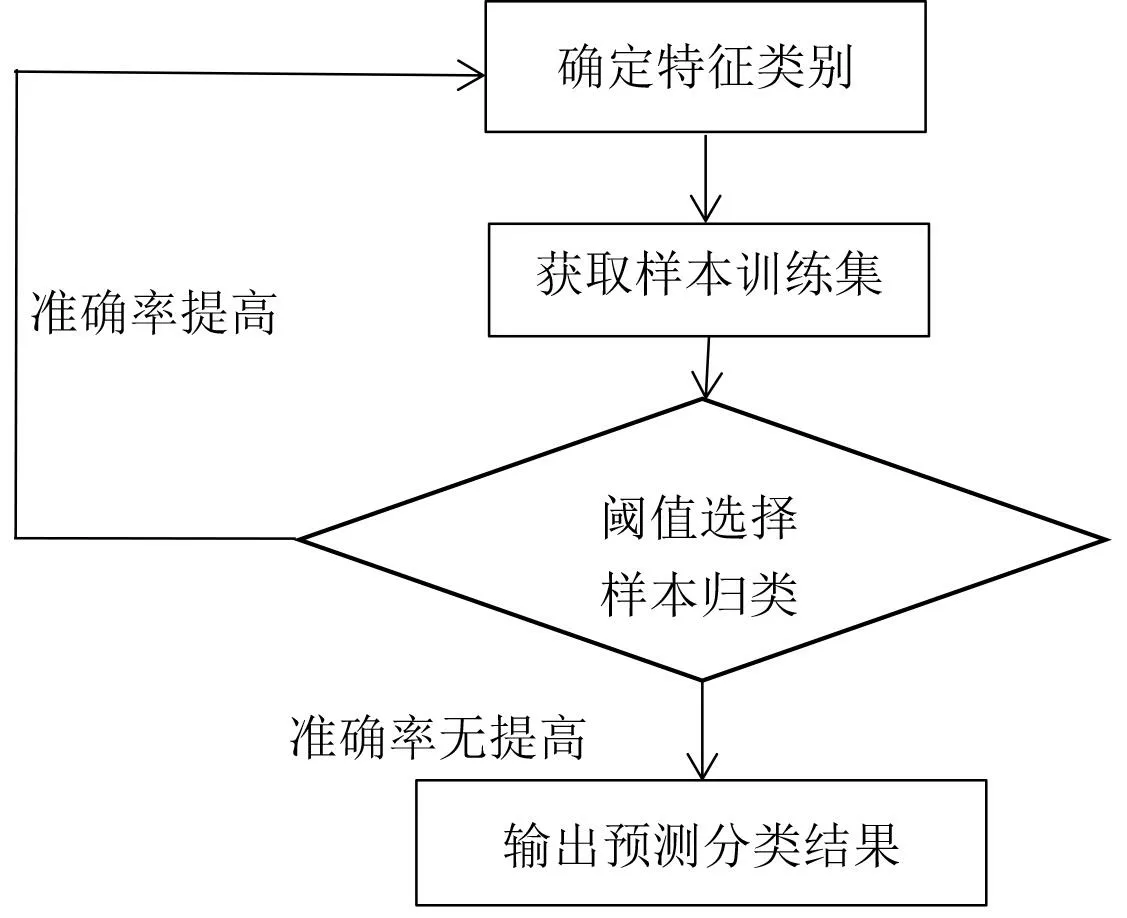
图1 朴素贝叶斯算法阈值分类流程图
2 短信短语特征项提取
垃圾短信特征项的提取,我们以基本短语为单位的分词方法。结合基本短语构成算法,并根据基本短语的定义实现由词到基本短语的转换。基本短语模式特征项提取应当遵循的以下两个规则[5]。
2.1 一般名词短语结构模型的界定
短语结构模型的界定,是一种确定不同类型短语的边界位置的过程,是以单词为构件形成短语的主要步骤。作为能代表文本主要特征的一般名词短语和动词短语,其界定规则对降低特征项空间的维度及提高准确性来说非常重要。赵军、黄昌宁等人根据词语潜在的依存关系,分析了汉语简单非嵌套式名词短语(baseNP)的结构,并给出了相关定义:①baseNP+baseNP,如“公路里程”“高校教师”等;②baseNP+名词|名动词,“公路建设”“高校发展”等;③限定性定语+baseNP,如“双核”“三好学生”等;④限定性定语+名词|名动词,如“中国信息公路”“第三世界国家”。
2.2 一般动词短语结构模型的界定
一般动词短语结构模型形式主要有:①述补结构,如压马路、走路等;②述宾结构,如修改论文、选角等;③状中结构,如立刻动手、到黄山游玩等;④连动结构,如去洗手、开动等;⑤联合结构,如边走边唱、甲和乙等;⑥其他动词短语,如“着了过”属性的动词,睡了、坐着、想了想、听说过等。短信文本短语特征项提取是先把第一个分词词语对后面的词语分别进行组合,通过过程测试检验则认为合格,如果不符则将该短信所有短语列为垃圾短信短语(词语)向量集,则取下一个分词词语重复上述过程,直到最后一个词语完成组合测试为止,垃圾短信过滤处理流程如图2 所示。
利用统计思想,基于互信息方法划分分词短语的边界。互信息是考察一个消息中两信号间的相互依赖度的度量,也是分词词语间结合的紧密程度的度量,通过短信文本相邻词性标记的互信息值大小来进行判断,其极小值的位置为短语的边界。互信息方法的计算如下式所示:

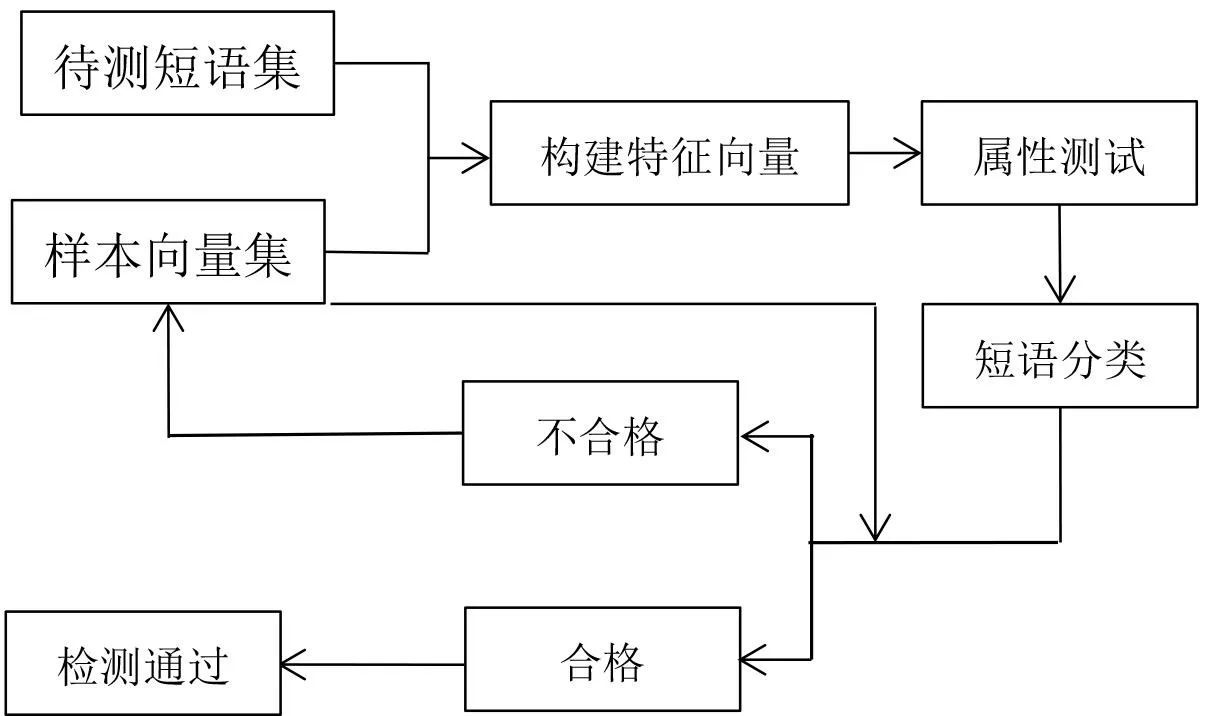
图2 垃圾短信过滤处理流程示意图
利用互信息值算法如下。
输入:训练样本向量集x
输出:由词语和短语组成新的向量空间x_temp
Begin
fid=fopen(sFileName,’x’);
if(fid!={})
for each fid into x do
while x_i!=x_j
z_ij=sqrt[(x_i)^2+(x_j)^2]
case min_i=inf,nbor_i=i
case min_i=z_ij; nbor_i=j
end
while x_i!=x_temp
flag(i,x_temp)=-1
break ;end
while x_i=x_temp
flag(i,temp)=1
delet(x_i)
break ;end
for each x_i in x do
x_temp=nbor_i
flag(i,x_temp)=-1
xdelet(x_temp)
break ;end
if delet(x_i)
output x
else output x_temp
end
基于短语贝叶斯垃圾短信过滤方法的主要改进在于利用互信息计算对短信文本特征项提取算法。该算法特征项提取以短语为单位,降低样本空间规模,在此基础上训练样本集,生成分类模型,实现文本短信过滤。
3 实验与结果
为清晰表达比较结果,引入了几个参数,定义如下:


SP 反映垃圾短信过滤系统的可靠性,侧重安全性;SR反映垃圾短信过滤系统的效率,侧重有效性;F 则综合两者的指标,侧重综合性能。
我们以短信为例进行试验,其中含正常短信1 032 条,手机拦截短信375 条。以短语为单位得到特征项数为20 783,其中BaseNP 为13 542,BaseVP 有7 241 个,而以词为单位得到特征项数为173 657.这样降低样本空间规模,缩减计算量,提高系统效率。
下面测试在KNN 方法(词模式下)、改进贝叶斯算法(词模式下)及改进贝叶斯算法(短语模式下)3 种不同方式下过滤性能上的表现。SR、SP 与F 值比较结果如图3 所示。

图3 三种方式过滤性能比较结果
实验测试表明,在综合性能指标上,词模式下KNN 算法与改进贝叶斯算法没有多大差异,但短语模式下的改进贝叶斯算法要比前两者高出近2%;而在SR、SP 数据的比较上,词模式下的贝叶斯算法并没有较KNN 算法高明,甚至在SR 比较中要低1.56%,短语模式下却比两者高出许多,其中SP 达到了94.51%,可知以短语为单位进行特征提取,然后再进行分类过滤所得的结果,更优于词模式下的KNN算法与贝叶斯算法。
短语模式下改进贝叶斯算法在查全率、查准率及综合指标等方面都有一定的提高,但在特征项提取阶段还存在诸多人为因素,机器的认别程度还存在较大不足,机器对文本短语分类依然有进一步改善的可能。
