基于分布式框架的并行PSO算法
2019-04-09桑渊博曾建潮孙超利
桑渊博, 曾建潮,2, 谭 瑛, 孙超利
(1. 太原科技大学, 计算机科学与技术学院, 山西 太原 030024;2. 中北大学 计算机与控制工程学院, 山西 太原 030051)
0 引 言
微粒群算法是Kennedy和Eberhart于 1995年提出的模拟鸟群或鱼群觅食的群智能优化算法, 由于其结构简单、 所需考虑的参数较少、 对优化问题无连续或可微、 可导等要求, 从而在各个领域得到了广泛的应用, 如函数优化[1]、 工程界的系统优化[2]、 神经网络训练[3]、 深度学习等. 然而, 随着优化问题规模的扩大, 微粒群算法由于易早熟收敛的缺陷导致其在高维问题[4]中的优化性能受到了限制. 在深度学习神经网络方面优化算法通常通过基于梯度的学习算法(即反向传播)进行训练. 如Such F P等[5]研究了非梯度的进化算法在深度学习上工作, 基于种群的优化算法演化神经网络的权重, 并成功地演化了四百多万个自由参数的网络. 虽然这些方法能够提高算法对于高维优化问题的求解能力, 但同时其适应值评价的次数相对来说也大大增加, 从而导致算法的运行速度较慢. 随着硬件的发展, 分布式计算[6]和GPU并行计算逐渐受到人们的关注. 分布式计算是利用集群计算对同一问题或者不同问题进行求解, 和使用单机计算形成对比, 可以在一定程度上解决计算耗时的问题[7]. 另一方面随着GPU技术的快速发展, 使得其和CPU可以进行协同工作来组成新的计算模式——异构计算. 如Luca Mussi, Fabio Daolio[8]研究了在GPU CUDA系统结构下评估了并行微粒群算法和传统串行微粒群算法的性能差别, 蔡勇等[10]研究了微粒群算法在对问题求解一致的前提下GPU的加速情况. 为此, 分布式计算以及并行计算和群体优化算法相结合, 可以大大提高算法的求解能力和求解效率. 本文着重研究如何将微粒群算法在主从式分布计算模型下, 利用GPU集群并行完成个体的位置更新以及适应值的计算, 从而验证该结构下搜索算法对于大规模优化问题[11]的运行效率.
1 相关概念
1.1 微粒群算法
在微粒群优化算法(Particle Swarm Optimization, PSO)中, 种群P由D维空间下n个粒子(或称为个体)组成,n称为种群规模. 每个粒子i都有自己的位置xi={xi1,xi2,…,xiD}和速度vi={vi1,vi2,…,viD}, 并且记录到目前为止其搜索到的个体历史最优位置pbest, 记为Pi. 整个种群到目前为止搜索的最优位置称为全局历史最优位置gbest, 记为Pg. 在每一代, 粒子根据式(1)和(2)更新其速度和位置.
Vid(t+1)=w*Vid(t)+C1*r1*(Pid(t)-
Xid(t))+C2*r2*(Pgd(t)-Xid(t)),
(1)
Xid(t+1)=Xid(t)+Vid(t),
(2)
式中:t表示迭代次数;w称为惯性权重, 其大小代表了当前粒子在搜索空间的搜索能力和探索能力;C1,C2统称为学习因子,C1为认知系数;C2为社会系数;r1,r2是两个在[0,1]上均匀分布的随机数.
1.2 基于Spark的分布式计算框架
分布式计算框架可以由分布式模型、 集群环境、 物理平台等基本条件组成. 近几年在集群计算平台发展上, 尤为突出的有Hadoop和Spark. 而Spark是建立在抽象的RDD (Resilient Distributed Datasets)之上, RDD分布模型中包含了MapReduce、 迭代计算、 关系查询和流处理四种主要功能组件. RDD模型具备像MapReduce等数据流模型的容错特性, 并且允许开发人员在大型集群上执行基于内存的计算. 现有的数据流系统对两种应用的处理并不高效: 一是迭代式算法, 这在图应用和机器学习领域很常见; 二是交互式数据挖掘工具. 这两种情况下, 将数据保存在内存中能够极大地提高性能. 为了有效地实现容错, RDD提供了一种高度受限的共享内存, 即RDD是只读的, 并且只能通过其他RDD上的批量操作来创建, 以上这些特点使得Spark在进行算法迭代运算时在计算速度上要优于Hadoop等其他计算平台.
1.3 GPU并行计算模型
随着异构计算的提出, GPU技术在各个科学领域都得到了应用, 它是以GPU部分做计算, CPU部分进行逻辑判断, 两者配合完成所有的计算任务. 在GPU计算架构上CUDA作为并行计算框架, 采用了单指令流多数据流的方式进行执行, 由于GPU强大的计算能力它可以开启成千上万个线程. 在 GPU中内核函数(kernel)执行并行计算部分, 是一个程序中并行执行的基础函数. GPU执行计算模式是依次执行内存数据复制到显存、 kernel函数运行、 显存数据复制回内存3个基本步骤. 所以它对于计算密集型的任务可以很大程度上分担CPU的计算任务, 从而CPU有更多时间去做其他的计算或逻辑判断任务, 最终提高了整体任务的计算效率.
通过分析微粒群算法的并行性可以得出以下几个方向的并行:
1) 粒子速度和位置的更新是可并行的;
2) 粒子适应度值的计算是可并行的;
3) 粒子个体最优位置的更新是可并行的.
所以微粒群算法完全可以采取分布式计算再加上GPU级别的并行去缩短算法的运行时间. 具体的设计如下:
如图 1 所示, 每个子种群(如S0)中粒子速度、 位置和个体最优解更新上通过GPU线程一一对应图1中的每一粒子上的每一维上的信息去进行并行更新, 计算每个粒子适应值时则是GPU线程和粒子个体一一对应, 在更新整体种群全局最优解时则是计算节点间并行.

图 1 PSO算法与GPU线程并行对应关系Fig.1 PSO and GPU thread parallel correspondence
2 基于分布式框架的并行PSO算法
作为群智智能优化算法的微粒群算法, 其种群中粒子和粒子之间的位置和速度更新以及他们的目标函数评价独立, 故此可利用GPU并行计算实现以提高算法的运行效率. 而种群中个体之间的交互主要是通过全局最优位置的共享, 故此可利用分布式主从式计算模型, 在主节点进行粒子之间的交互, 而在从节点对粒子本身进行更新, 从而在保证原微粒群算法寻优结果的基础上提高优化速度. 算法的总体流程图如图 2 所示. 在微粒群算法中, 粒子的社会学习主要是通过种群的群体历史最优位置共享而实现, 而如何实现并行环境下位置的共享其实就是如何处理多进程间的协同工作. 常见的进程通信技术主要有: 管道、 信号量、 消息队列、 共享内存等方式, 其中以共享内存的通信效率最高. 为此, 在本文中采用类似于共享内存的数据库方式来解决数据共享的问题, 在每个节点并发访问全局最优位置时通过数据库加锁机制来解决并发操作引起的数据不一致性. 从图 2 中可以看到不同于传统的微粒群算法, 每个粒子速度和位置的不同维度更新分别在不同的GPU线程上并行实现, 以及每个粒子的适应值计算和其个体历史最优位置的更新也都在不同的GPU线程上并行实现. 而种群的全局最优位置则在共享内存通过加锁机制在主节点上进行实现. 算法1给出了本文方法的伪代码.

算法 1 PPSO-DF算法伪代码Algorithm 1 The pseudocode of PPSO-DF algorithm
在算法 1 中,t表示进化迭代数,P(t)表示第t代种群粒子位置信息, arrayRDD[n]表示种群经过RDD化后被并行化到n个计算节点, 其中n表示计算节点个数, 且每个计算节点中的粒子个数相同. parallel意思是并行执行所包含下的代码段, barrier表示线程间的同步, 保证了数据处理的一致性.

图 2 基于分布式框架的并行PSO算法 Fig.2 Parallel PSO algorithm based on distributed framework
3 仿真实验
3.1 实验参数设置
由于目前没有对优化算法集成计算的相应软件, 所以为了验证本文算法的有效性, 就在5个高维测试函数上进行了测试, 并和无GPU集群并行计算的PSO(称为CPU-PSO)进行了比较. 为公平起见, 在CPU-PSO中, 采用了同步进化的方式. 实验在3台具有相同配置服务器组成的Spark集群计算平台上实现, 其中2台各有2块Tesla K20m型号的GPU, 第3台作为主控节点不参与计算任务, 只负责任务调度和收集计算结果. 每台机器其他配置如下: 操作系统为Centos6.8, Intel(R) Xeon(R) CPU, 主频1.80 GHz, Hadoop和Spark对应版本分别为Hadoop2.6.5和Spark1.6.1. 表 1 给出了测试函数的维度以及相应的粒子数设计, 其中D表示函数维度,N表示总种群大小. 算法中止条件为运行迭代次数达到 4 000次. 微粒群算法中, 惯性权重w设为0.729 8, 社会学习因子C1=C2=1.496 2,Vmax在每一维度的值设置为对应维度变化范围的0.15倍. 每个算法在每个问题上独立运行10次.

表 1 函数维度和种群大小设置Tab.1 The settings on function dimension and swarm size
3.2 实验结果及分析
表 2 给出了不同维度下两种算法在函数上所需的运行时间, 单位为秒. 由于本文方法中没有对微粒群算法本身做改进, 认为对算法的寻优结果没有太多的变化, 故此在本文中只给出相同评价次数下其运行时间, 而没有给出其运行结果. 从表 2 中可以看出, 在低维上此方法并不占优优势, 而随着维度的提高, 可以发现此方法相比于无GPU的微粒群算法其运行时间得到了大大的提高, 从而说明了基于分布式框架的并行微粒群算法能够加快对高维问题的优化效率. 图3给出了两种算法在F1和F11函数上对其不同维度上的优化运行时间走势图, 从图中也可以很清晰地看出其随着维度的提高两种方法的时间差也大大地提高. 表 3 给出了CPU-PSO和PPSO-DF各维度下的加速比. 从表中进一步看出了当粒子维度和粒子数规模小于一定量时并不能体现GPU并行计算的优越性, 这是因为在内存和显存之间存在数据的传输, 但当问题规模越来越大时内存和显存间的数据传输部分所占的比例减小, 从而更能体现GPU的处理速度优越性.
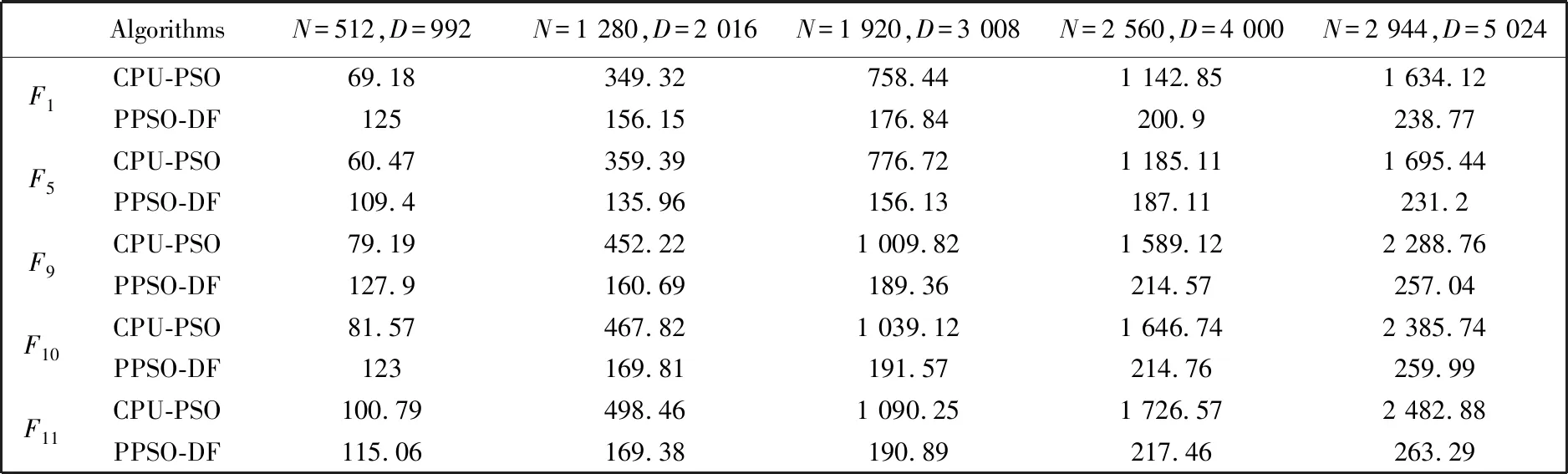
表 2 CPU-PSO和PPSO-DF算法求解不同高维问题的运行时间Tab.2 The runtime of CPU-PSO and PPSO-DF algorithms for solving different high-dimensional problems

图 3 F1, F11函数不同维度下的运行时间走势Fig.3 The trend of running time in different dimensions of F1 and F11 functions

表 3 CPU-PSO/ PPSO-FD算法加速比Tab.3 The speed-up ratio of CPU-PSO and PPSO-FD algorithms
4 结 论
鉴于微粒群算法本身具有并行的能力, 在本文中提出了分布式框架下的并行微粒群算法以提高微粒群算法求解大规模优化问题的有效性. 目前对于深度学习中图像识别、 自然语言分析等存在大量需要优化的参数, 有的都是以百万级个数, 所以可以通过分布式的方式训练其中的参数从而节省微粒群算法对大规模优化问题的求解时间.
本文方法验证了分布式框架下并行微粒群算法的计算效率得到了很大提高, 然而, 文中并未对微粒群算法本身进行改进, 因此算法仍然容易陷入局部最优. 今后, 将在本文框架下对微粒群算法进行改进, 以期在保证计算效率的前提下获得更好的优化结果.
