基于人工神经网络的字母识别
2019-04-02陈戈珩程青青
陈戈珩, 程青青
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
21世纪以来,世界进入信息化时代。计算机技术的快速发展,使人们的工作生活变得越来越方便、越来越智能化。它让人类从很多枯燥乏味的工作中解放出来,在人工智能领域中字符识别(Optical Character Recognise, OCR)技术成为其中一个非常重要的应用[1]。
在这个信息爆炸的时代,人们的日常学习、工作和生活中几乎每时每刻都充斥着与字符相关的各种信息,字符信息是人类从外界获取信息最重要的方式之一,这些字符信息一般可以分为两类:手写体和印刷体。而我们所说的OCR技术一般指的是对印刷体字符的识别技术,原因在于手写体因人而异,一般没有统一的字符模板可供计算机参考,因此,计算机对这类字符的识别通常比较困难,不仅识别率比较低,而且对手写体字符的识别速度相对印刷体字符来说也比较慢。因此,接下来所提到的字符识别技术都是针对印刷体字符的。印刷体字符通常具有一定的规则性,而且不论对于哪一种字体来说,其对应的印刷体字符都有相应的字符模板可供参考,这也是印刷体字符的识别率远高于手写体字符的重要原因之一。
人类对印刷体字符的识别技术早在上个世纪初就开始了。1929年,德国科学家Tausheck提出了光学文字识别的概念,这是最早的一种OCR技术。之后的几十年,世界各国也相继开始OCR技术的研究,但是由于硬件技术等条件的限制,直到上个世纪六七十年代,才相继有少数学术成果以及基于OCR技术实现的产品出现[2]。1966年,IBM公司的Casey和Nagy两人联合发表了第一篇基于汉字识别的文章,填补了人类发展历史上这一页的空白。与此同时,日本在OCR技术上的研究也取得了一定的进展,研制出了一款基于印刷文字识别的邮政编码识别系统。我国在OCR技术方面的研究晚于这些国家,20世纪70年代才开始对数字和符号的识别进行研究,而且由于条件的限制,研究进度相对较慢,直到90年代,我国对字符识别技术的研究才开始步入正轨,相应的技术和产品才逐渐得到应用和普及。
1 BP神经网络
1.1 基本原理
BP(Back Propagation)神经网络是人工神经网络的一种,是由Rumelhart和McClelland的团队1986年提出的,也是目前应用最广泛的人工神经网络之一[3]。总的来说,BP神经网络属于前馈多层神经网络的一种,它在函数逼近与预测分析、模式识别、分类以及数据压缩等方面具有非常广泛的应用[4]。基本工作原理是依靠误差的反向传播进行网络训练,以期望网络的实际输出值与期望输出值之间的误差均方差达到最小。
BP神经网络的核心部分是BP算法,BP算法的核心思想是以网络误差平方为目标函数、采用梯度下降法来计算目标函数的最小值[5]。算法的执行过程包含两个部分,信号的正向传播以及误差的反向传播。信息首先沿正向传播,当网络输出值与期望输出值的误差不满足要求时,转入误差的反向传播阶段,并修改各个神经元权值,通过这样的反复迭代过程,最终可以得到期望的网络输出值。
1.2 网络模型
BP神经网络模型如图1所示。
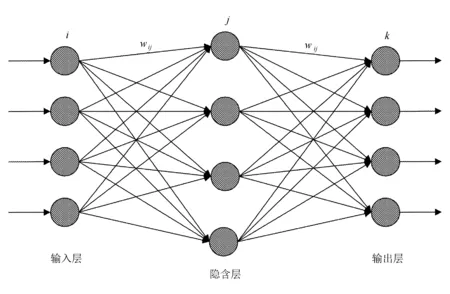
图1 BP神经网络模型
前面已经提到,BP神经网络是一种具有多层结构的前馈神经网络,一个完整的BP神经网络由输入层、隐含层和输出层组成,其中隐含层可以具有多层[5]。
1.3 附加动量法
附加动量法相比反向传播法在进行权值修正时,考虑的因素更多,在反向传播法的基础上引入误差在曲面上的变化趋势的影响,这样做的好处就是网络在进行每一次权值修正时,都要加上相比于前一次的权值变化量的值,新的权值变化量的产生方式依据反向传播方法的原理[6]。
不仅如此,附加动量法忽略了网络上一些无关紧要的微小变化特性,这样做不仅能够使网络的训练速度加快,而且可以防止网络陷入局部极小值。
下面是带有附加动量因子修正公式:
Δwij(k+1)=(1-mc)ηδiPj+mcΔwij(k)
Δbi(k+1)=(1-mc)ηδi+mcΔbi(k)
式中:mc----动量因子,取值0或1;
k----训练次数。
附加动量法就是利用动量因子将最新的权值修正情况传递下去。从上式可以看出,动量因子取值不同,权值的变化情况是截然不同的。当mc=0时,权值依据梯度法的规则变化;当mc=1时,自动忽略梯度法产生的权值变化,并将最新的权值变化设定为当前的权值变化。
另外,附加动量法规定了两种特殊情况,一是修正后的权值导致误差产生较大的变化,二是误差变化率超过当前设定的最大误差变化率,最大误差变化率应当大于等于1,通常取1.04。这两种情况看似在说明同一个问题,其实不然,因为误差的产生不仅仅是因为权值的改变,第一种情况说明的仅仅是因为权值改变导致的误差,属于局部误差的范围,而第二种情况介绍的是全局误差。当这两种情况发生时,应当舍弃当前计算得出的权值变化[7]。这就要求在进行程序设计时注意选用正确的动量因子的值,具体值及判断公式如下:
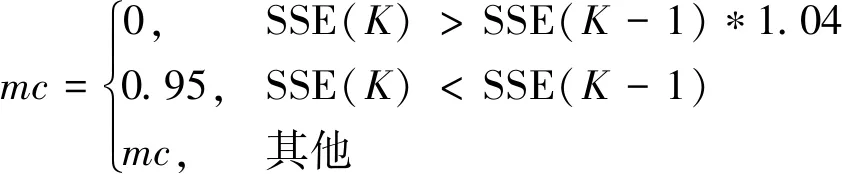
式中:SSE(K)----第K次的误差变化率。
1.4 自适应学习速率
考虑到一个固定的学习效率可能不能完全适应训练前后期的要求,文中采用可变的学习效率。首先,检查修正后的权值是否能够真正有效降低误差,如果能,说明当前选取的学习效率较低,此时适当提高学习效率;如果不能有效降低误差,说明当前学习效率可能过高,适当降低学习效率,直到网络的学习过程趋于稳定为止。这样做的好处是,可以保证网络时刻都是以当前可以接受的最大效率进行学习,可以大大缩短网络训练的时间。
具体的自适应学习效率公式及条件如下:

式中:η(k)----第k次的学习效率。
2 神经网络设计
用神经网络对字母进行识别之前需要对字母进行归一化处理,用一个7行5列的矩阵来对字母进行数字化的处理,其中有数据的地方用1表示,反之则用0表示。字母A、B、C的数字化过程如图2所示。
也可以用1*35的向量来表示数字化处理过后的字母。则可以表示为:
LetterA=[00100010100101010001111111000110001]
LetterB=[11110100011000111110100011000111110]
LetterC=[01110100011000010000100001000101110]
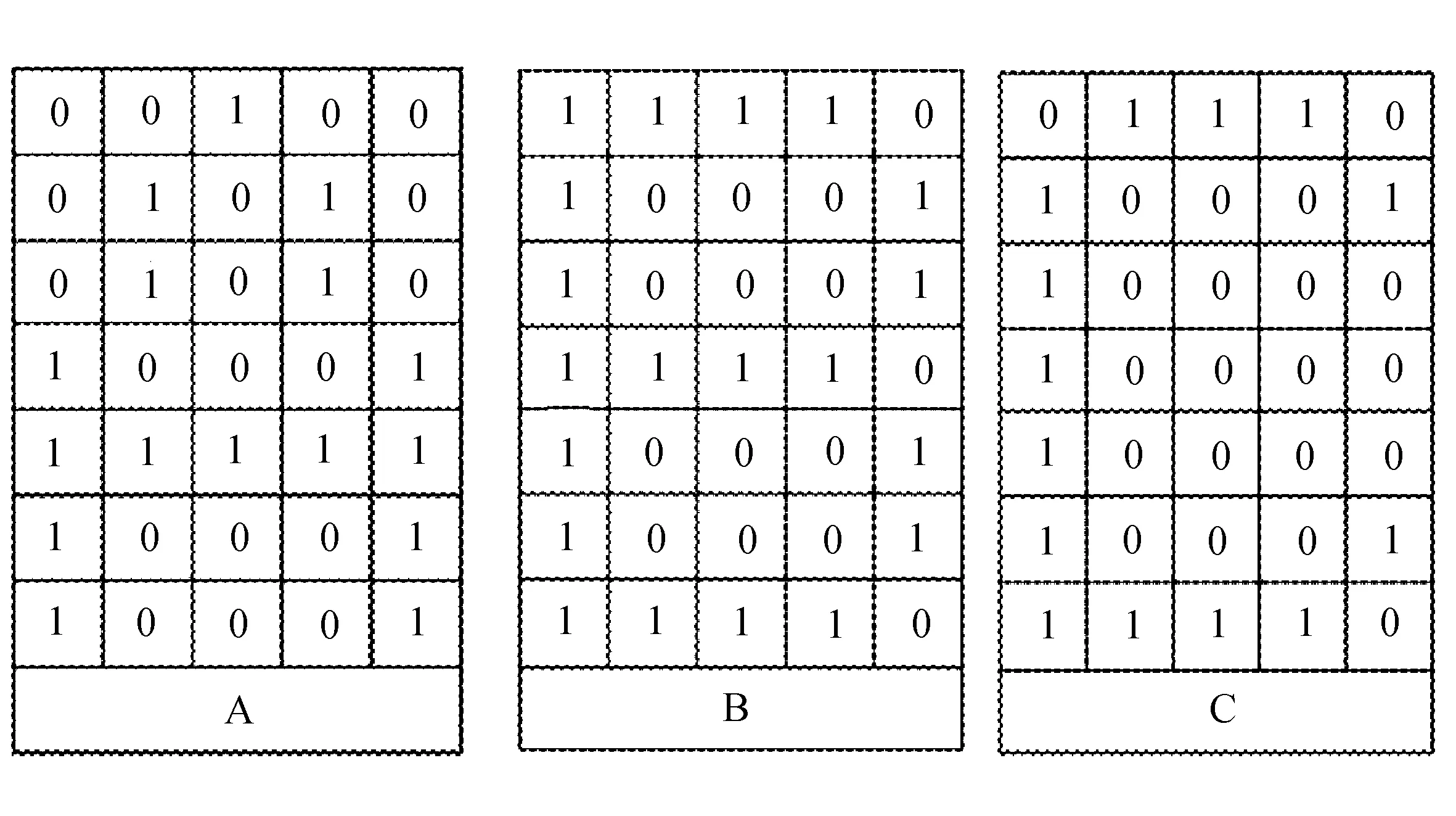
图2 数字化字母
由此可以得到26个标准字母的神经网络输入样本,将输入样本定义为alphabet向量矩,其中alphabet=[letterA,letterB,…,letterZ]。由于每个字母都由35个元素组成一个向量,故alphabet是一个35*26的矩阵,故将网络输出矩阵定义为26*26的单位阵,记为:target=eye(26)。在实验时,将理想标准信号和加入噪声的标准输入信号这两类数据分别作为数据的输入信号。
在对BP网络设计时,隐层节点个数的选择是BP网络的重要环节,它也是网络实现预测成败的关键。在实际的预测实验中,隐层节点个数过多会导致网络学习过度,学习时间剧增。隐层节点数过少,则不能达到所需要的实验预测要求。由此可见,隐层节点对于神经网络的学习和计算特性起着非常大的作用[8]。
实验中,根据Kolmogorov定理和单隐层的设计经验公式确定隐层节点数范围介于8~17之间。
通过实验的验证和误差值的分析,将最终值确定为14。此时,BP网络的输出显示以及网络训练速度和精度因素都是最好的。实验仿真如图3~图5所示。
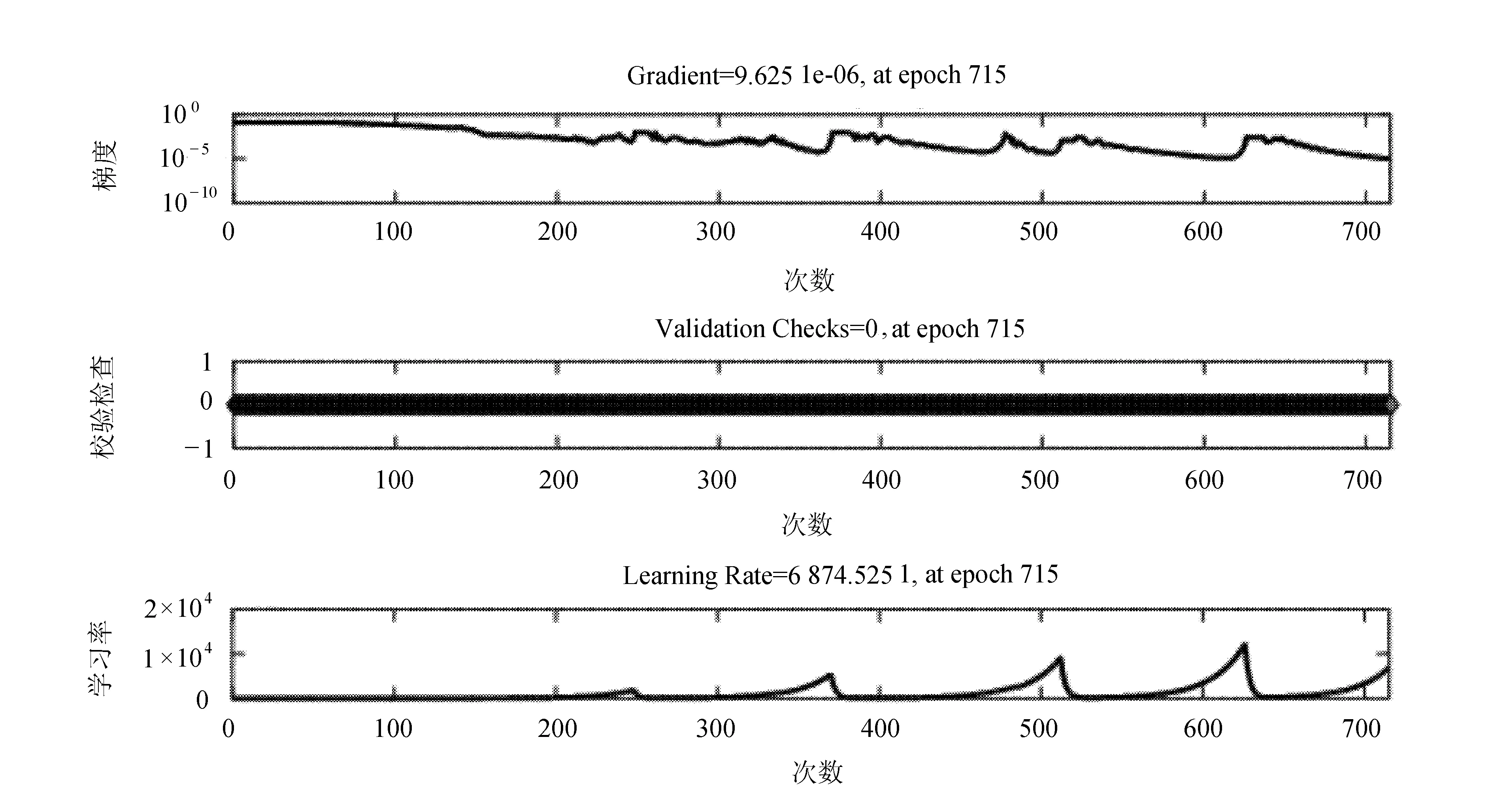
图3 理想标准信号训练状态图
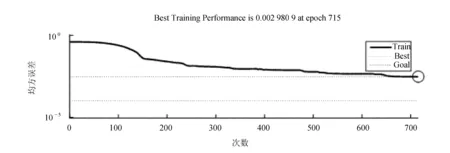
图4 理想标准信号训练误差性能曲线
3 仿真实验
文中选择MATLAB开发环境,基于MATLAB对于图像、神经网络等提供的工具箱函数建立了BP神经网络,并对获取的样本进行识别。

图5 训练回归曲线
实验过程中,为了使产生的网络具有一定的容错能力,需要采用BP网络对不同的信号进行训练,再使用trainlm函数达到快速训练的目的,在这个过程中,网络的学习速率和冲量参数的设定均为自适应改变。先将理想信号输入,直到平方和误差足够小再停止训练。文献[9]在实验时,将训练结束的条件规定为:最大次数1 000,误差平方和为0.000 01。通过MATLAB训练后得到实验结果:TRAINLM,Epoch 368/1000,SEE 3.68e-05/1e-05,Gradient 9.972e-06 TRAINLM,Performance goal met。由此可见,经过368次训练后误差达到要求。实验仿真如图6~图8所示。

图6 加入噪声信号的训练状态图
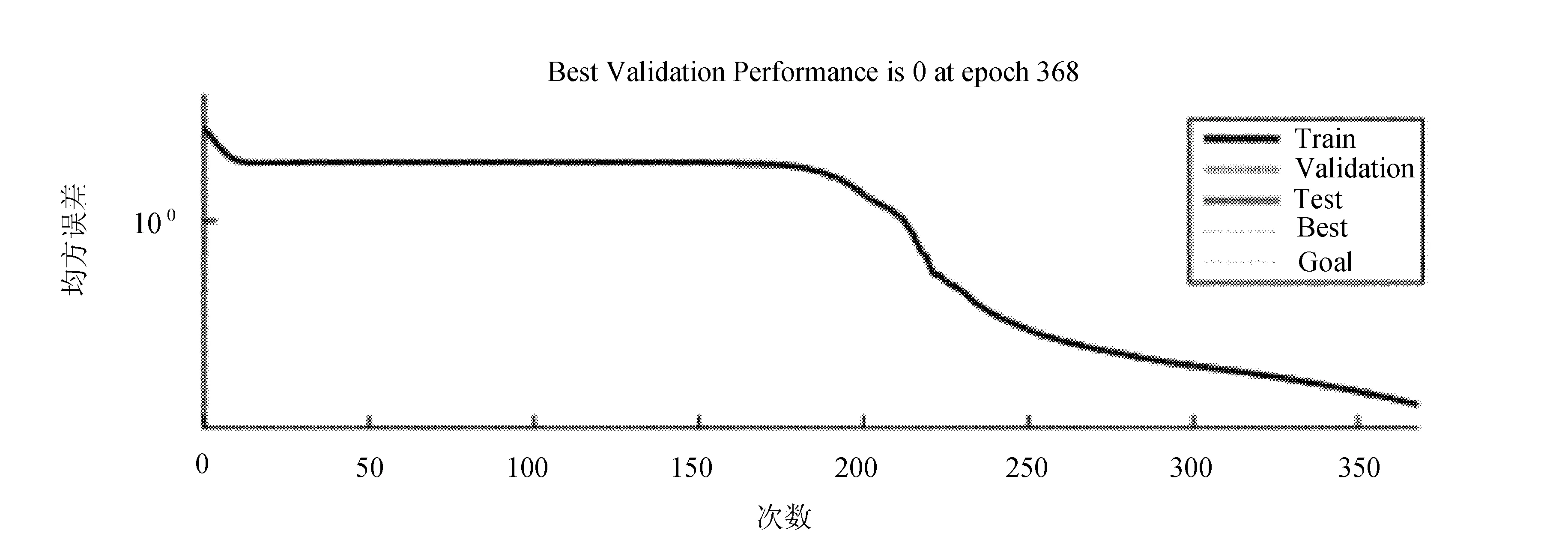
图7 加入噪声信号的训练误差性能曲线
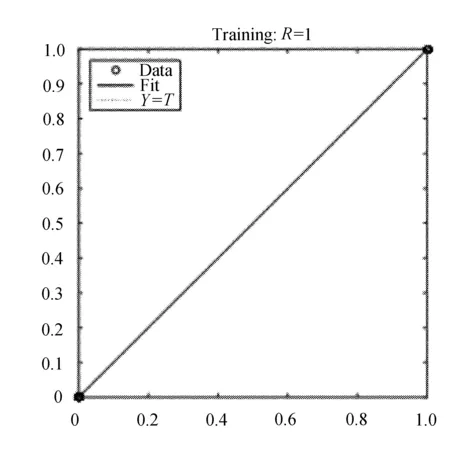
图8 训练回归曲线图
接下来进行的是含有噪声的信号实验,选用15组带有噪声的信号,将加入噪声的均值设定为0.1和0.2。这是为了保证神经网络既能够对含噪声信号识别,又能够对于理想情况下的字母进行识别。为了保证网络在识别理想输入向量的稳定性,要在输入时满足同时输入有误差向量和两倍重复的无误差信号。运行程序,查看识别错误与噪声信号的关系,实验结果如图9~图11所示。
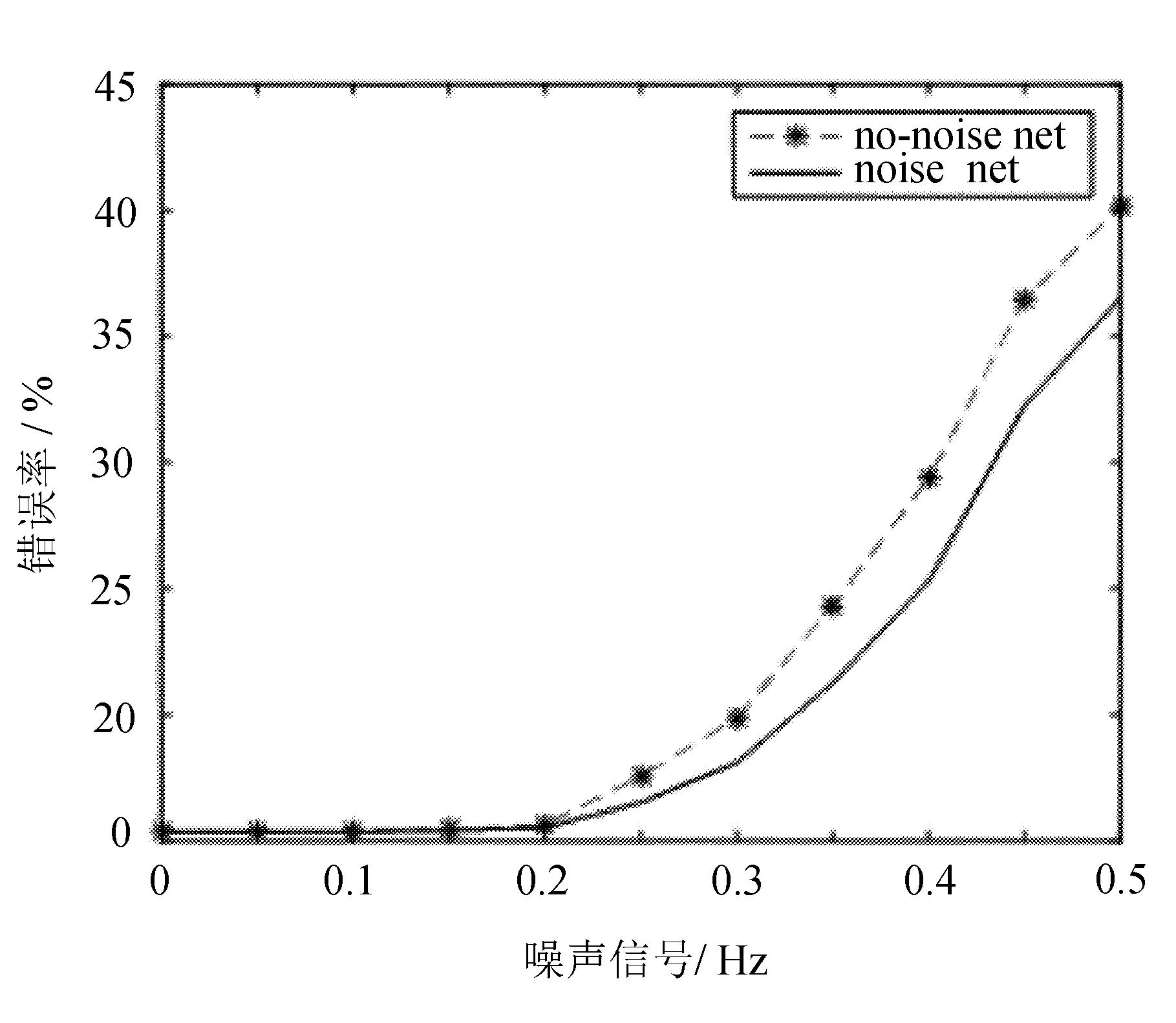
图9 第一次运行结果
通过三次结果的对比分析,可以看出每一次的运行结果都存在差异,这是因为在实验的过程中,每次运行时产生的随机数是不同的。
由实验数据可以得出,当噪声小于0.15的时候,两个网络的识别错误率基本上是相同的,而当噪声不断增加时,经过训练的网络会明显比没有经过训练的网络识别错误率要低,噪声越大,差距也会越大。

图10 第二次运行结果
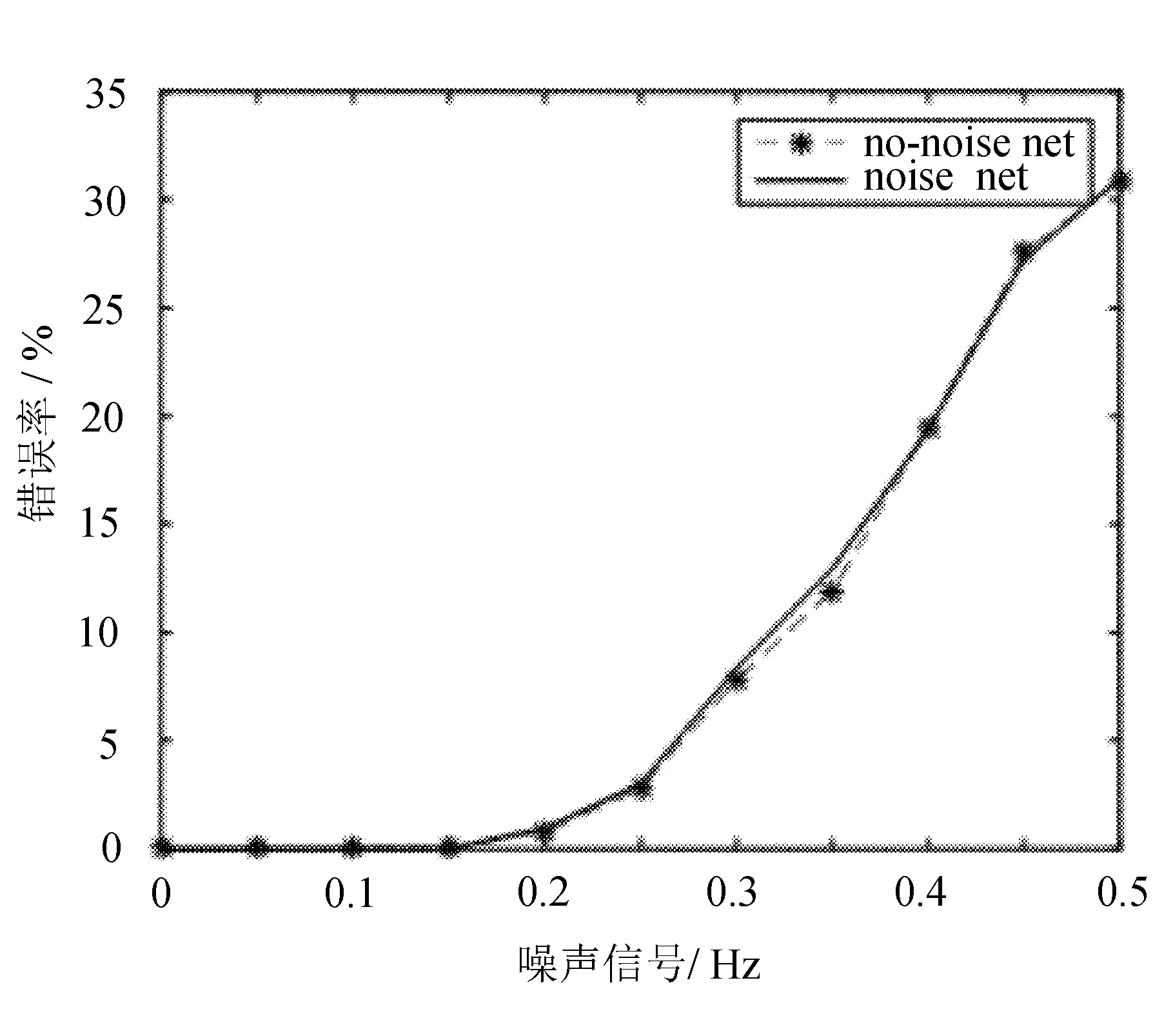
图11 第三次运行结果
编辑alphabet_recognise.m代码,运行程序,结果如图12~图15所示。
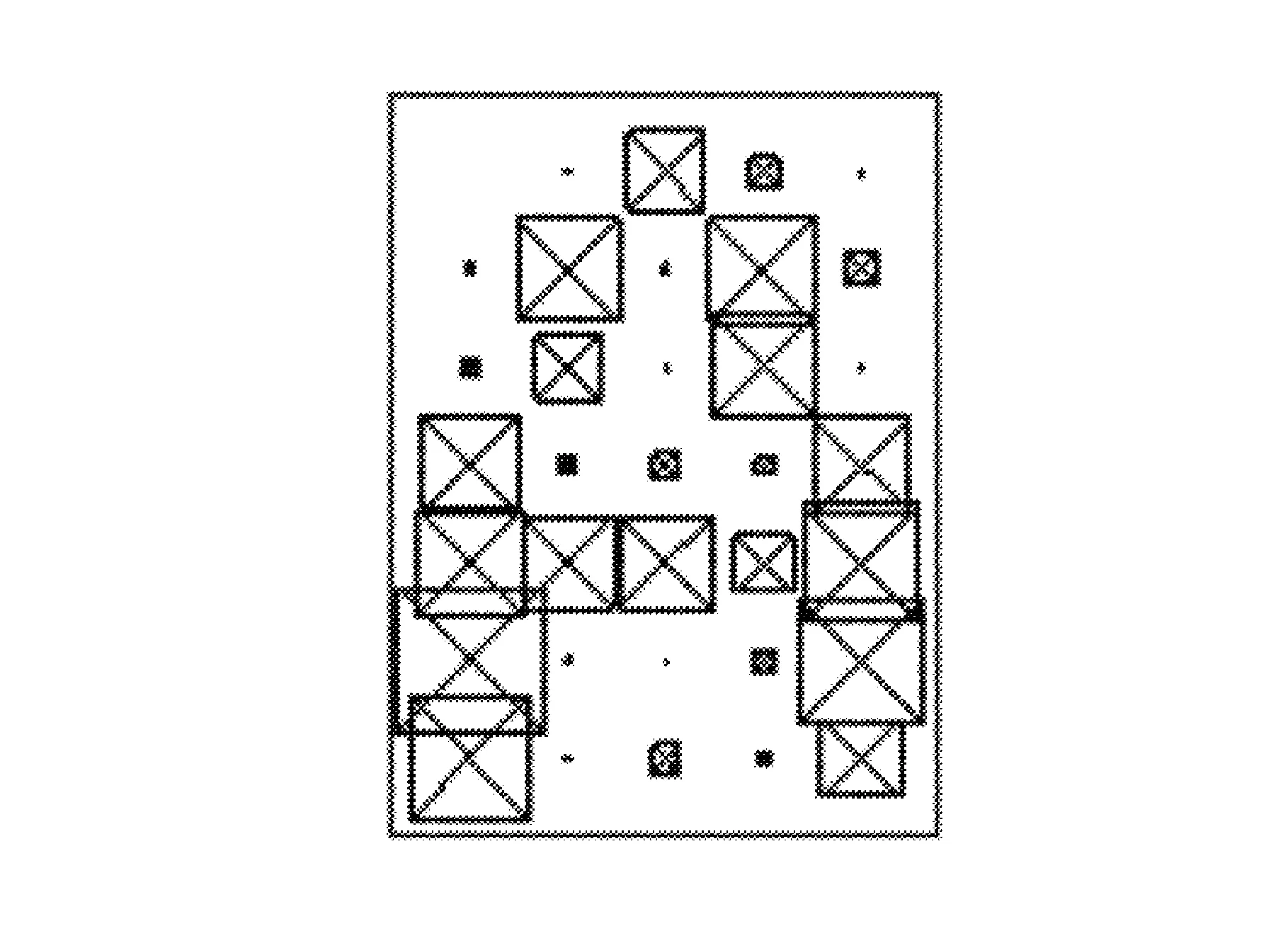
图12 含噪声的字母A显示图

图13 经过训练后的网络显示的A图
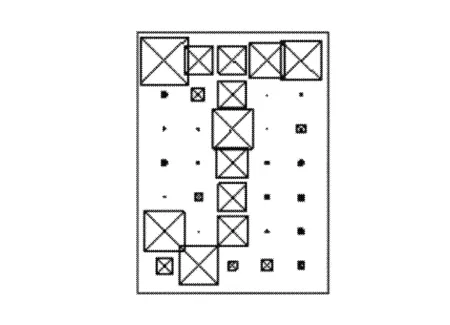
图14 含噪声的字母J显示图
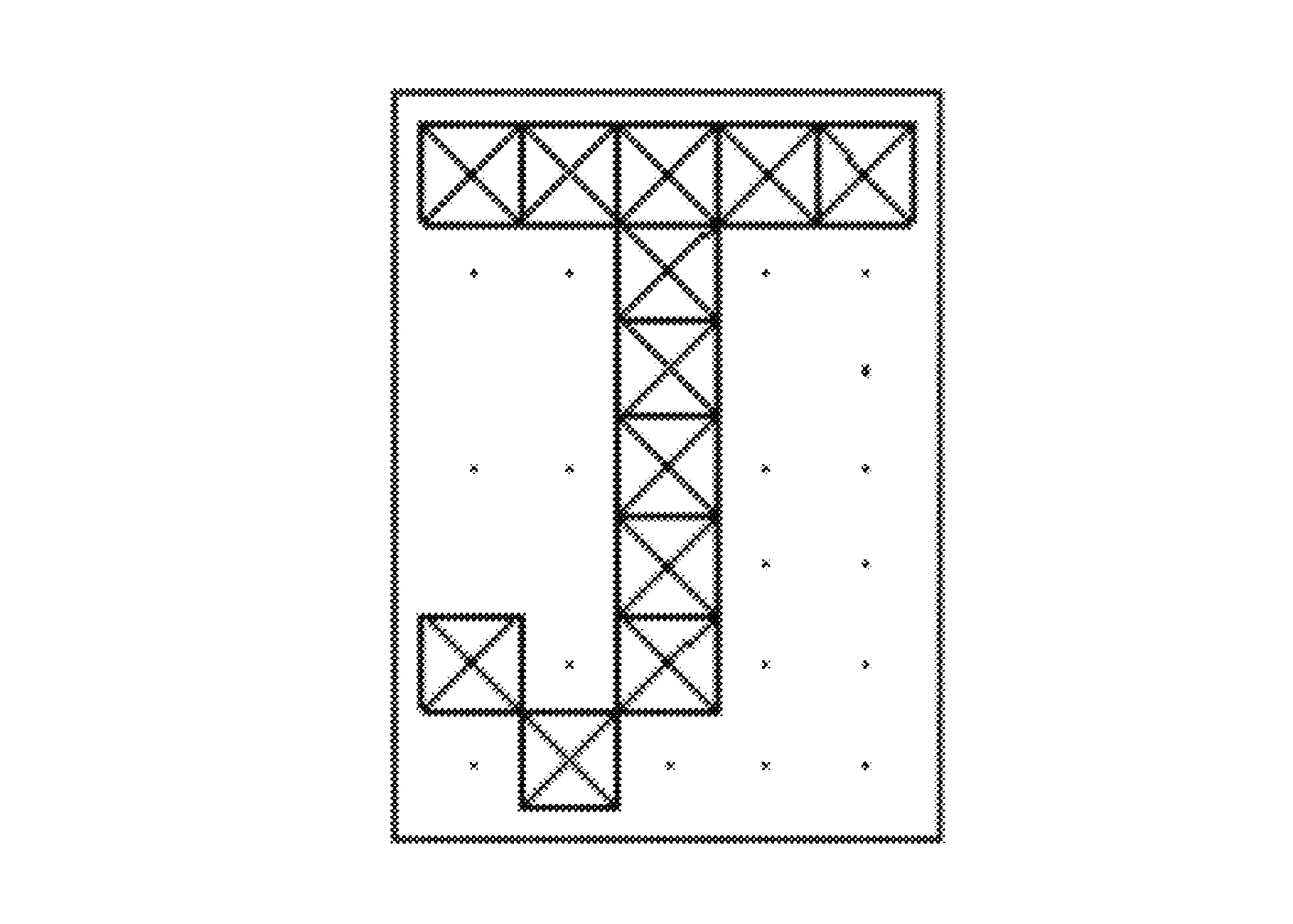
图15 经过训练后的网络显示的J图
4 结 语
利用BP网络对有噪声的字母进行识别和仿真,结果表明,此网络具有联想记忆和抗干扰功能,对于字母具有一定的辨别能力,可以作为一种对字母识别的有效方法。改进后的BP传播算法在加快训练速度的基础上还解决了在实验时网络陷入局部极小值的问题,在训练过程中可以根据当时的具体情况来自动调整学习速率,从而将学习速率和误差值达到最佳的平衡状态。在实验过程中发现,均值为0~0.15之间的噪声环境下,两个网络都能够准确的进行识别。但是当所加的噪声均值超过0.15时,待识别字符在噪声作用下不再接近于理想字符,无噪声训练网络的出错率急剧上升,此时有噪声训练网络的性能较好。为了获得更高的识别准确率,可以训练更多的样本,尽量选择一些带有噪声的字母来多次训练网络,使得识别的准确率更高。
