基于预训练机制的自修正复杂语义分析方法
2019-04-01李青钟将李立力李琪
李青,钟将,李立力,李琪
(1.重庆大学计算机学院,重庆 400044;2.重庆大学土木工程学院,重庆 400044;3.绍兴文理学院计算机科学与工程系,浙江 绍兴 312000)
1 引言
随着现代知识服务业的发展,海量跨领域知识信息封装存储于关系数据库中,面向内容资源的知识信息存在严重过载现象。如何创新现代服务科学,攻克关键核心技术,重塑现代知识服务业技术体系和价值链,提高内容资源在现代知识服务业增加值中的贡献度,创新发展现代知识服务新生态已成为研究热点与难点。针对内容资源的智能化、知识化、精细化和重组化的碎片性管理需求,建立新技术范式下的复杂语义分析方法成为重要的研究目标。
复杂语义分析的任务是将人类自然语言转换为对应的结构化查询语言(SQL,structured query language),即Text-to-SQL。如何高效地表达隐层知识、技术、经验与信息,则是复杂语义分析领域的研究热点与难点。同时,复杂语义分析是自然语言处理中重要的子任务之一,可为智能问答[1-3]、机器翻译[4]和复杂事件处理[5-6]等重要应用提供理论基础。因此,本文重点关注如何将自然语言映射到结构化查询语言SQL语句。
一直以来,复杂语义分析模型因缺乏高标准的标注数据集而难以训练发展。2018年,来自耶鲁大学的Yu等[7]成功构造了第一个具有复杂跨领域文本到SQL的标记数据集——Spider。2019年,Yu等[8]创新性地构造具有连贯查询的另一大型复杂跨领域文本到SQL的标记数据集——SParC。Spider数据集中语义解析任务的示例如图1所示。在此之前,几乎所有传统数据集(WikiSQL[9]、ATIS[10-11]、GeoQuery[12])都仅关注简单的SQL查询,进而导致训练模型仅满足匹配语义解析结果的需求,无法真正理解自然语言的含义[12]。
鉴于以上分析,本文提出自然语言查询的形式化语义表示模型——PT-Sem2SQL(pretraining semantic parsing to SQL)。为证明在面向真实内容资源中模型是有效的,采用Spider数据集和SParC数据集进行测试。本文模型构建思路是在以BERT[13]为主干的MT-DNN[14-15]预训练技术基础上,结合KL(Kullback-Leibler)差异技术[16]设计预训练模块。同时,为了捕获顺序信息满足复杂的SQL查询,提出带有多个子句和附加句内上下文信息的增强模块。最后,采用自修正学习优化的思想生成优化模型的执行过程,解决解码过程中的错误输出。
综上所述,本文的主要贡献如下。
首先,本文设计结合KL差异技术增加[Zero]列的MT-DNN预训练模块,构建结合多任务学习与标记数据的PT-Sem2SQL模型。这部分模块的建立可有效解决文本到SQL任务的零列[WHERE]子句的预测挑战,满足复杂跨领域文本到SQL的数据集查询任务要求。
其次,本文提出增加额外的增强模块来捕获句内上下文语义信息。通过增强模块,子任务可采用细粒度语义分析方式进行刻画,同时底层子任务的构建可为上层任务表示提供基础。通过实验验证,句内上下文语义信息对于结构化数据的语言任务同样起到至关重要的作用。
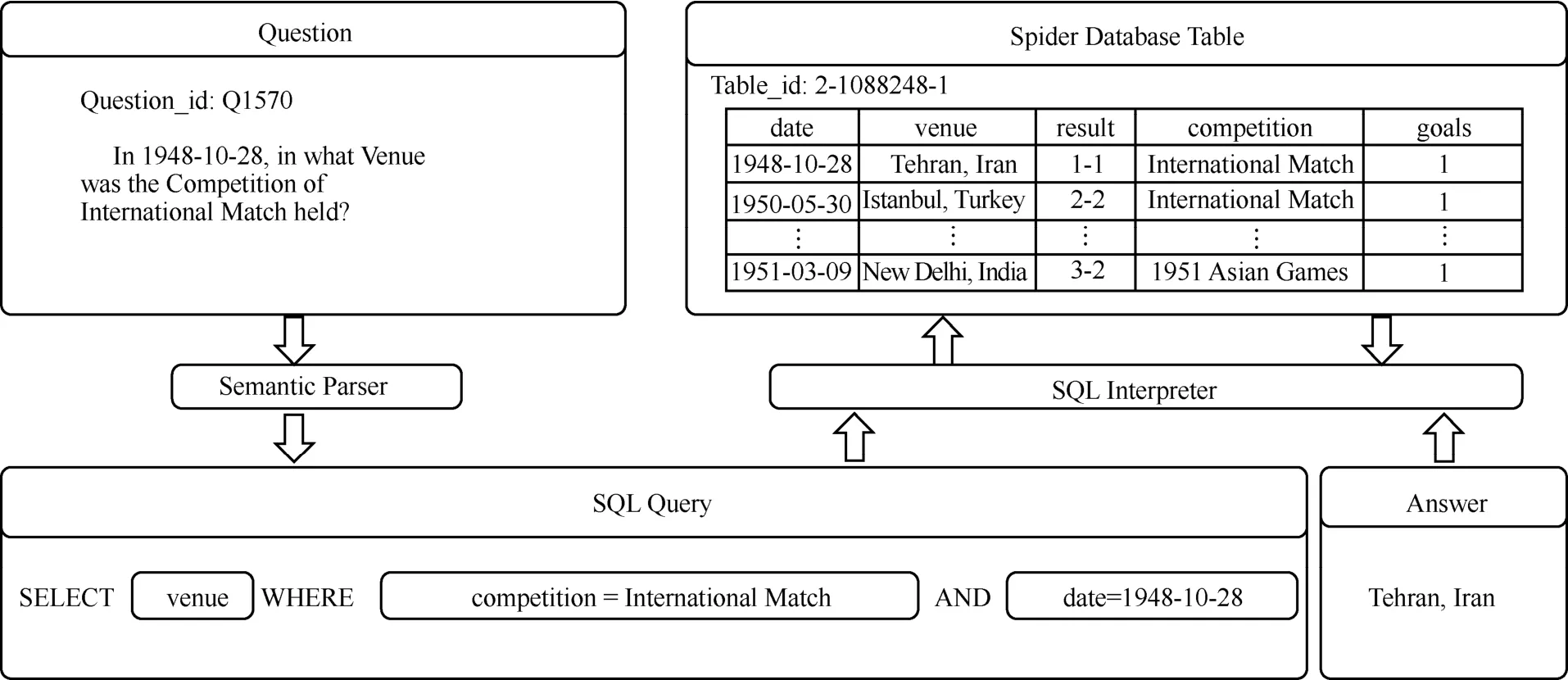
图1 Spider数据集中语义解析任务的示例
最后,针对解码过程中的错误输出问题,PT-Sem2SQL模型构建自修正方法优化生成模型的执行过程。将通过模型产生伪Text-to-SQL查询与真实的Text-to-SQL查询视为一对修正任务,采用自修正的思想优化真伪数据间差距,进而达到自修正优化的目的。
2 相关工作
针对Text-to-SQL语义解析问题的研究已经持续几十年。同时,相关领域专家已经提出各种对应的语义解析器模型[17-22]。
早期研究重点是将Text-to-SQL任务映射为序列生成的建模问题,主要构建具有自注意机制的神经网络序列到序列模型[23-24]。虽然此类方法仅取得初步效果,但无法确保生成语法的有效输出。其中,以TypeSQL为代表,它是2018年由Yu等[25]提出的依存语法分析模型,可以满足基础查询语言需求独立生成目标SQL查询的SELECT和WHERE子句。同年,Dong等[26]提出Coarse2Fine模型,通过优先输出一组草图,采用插槽填充的方法优化子句解码的结果。另一种Pointer-SQL模型则展现出新思路,提出sequence-to-action的方法,该方法使用基于注意机制的复制方法和基于值构造丢失函数的方法[27]。通过构造具有注释功能的seq2seq模型,试图确保模型在解码过程中各个阶段语法的正确性。
尽管上述以自然语言为基础的语义解析器模型成功地解决了简单语义到形式化SQL查询语句的问题,但因简单语义的单一性缺陷问题导致难以扩展,无法生成复杂的SQL查询语句。同时,此类仅在传统的WikiSQL数据集[9]上训练的模型难以捕获各种自然语言变体。2018年,耶鲁大学的Yu等成功开发Spider数据集[7],囊括困难层面的SQL查询(同时包含2个以上的[SELECT]、[WHERE]和[GROUP BY]子句)。2019年,Yu等为弥补Spider数据集中未关注上下文语境信息的不足,进一步地开发出大型上下文相关跨领域SParC数据集。它包含138个领域、具有复杂上下文依存关系、囊括复杂语义多样性的Text-to-SQL数据集。本文将Spider数据集与SParC数据集进行对比,如表1所示。
由此可见,解决复杂跨领域的数据集上Text-to-SQL语义解析问题,需要模型训练生成复杂的文本到SQL查询。同时,此类任务也更类似于自然场景下的查询。2019年提出的预处理技术,极大地增强了以词表示为主的外部语料库(如Glove模型[28])。受到此类预处理技术的发展启发,Hwang等[29]针对文本到SQL查询建立新型预训练的BERT模型。此外,一些工作也同样证明预训练外部语料库的模型在文本到SQL任务中具有显著改进的价值[13-14,30]。最优预训练技术MT-DNN[14]则更显著地体现了这一优势,成功用多任务学习将2类语料库(标注和未标注的语料库)进行深度融合。由此可知,未标注语料库的训练可有效增强模型的通用性。
3 PT-Sem2SQL模型
3.1 模型概述
本文将模型的总体结构划分为4个描述模块深入解构PT-Sem2SQL模型,即编码模块、增强模块、输出模块和自修正模块。PT-Sem2SQL模型的整体结构与基础模块如图2所示。
3.2 编码模块
为了使PT-Sem2SQL模型更适合于复杂跨领域查询任务,模型重新设计MT-DNN预处理模块,增加[Zero]和[CON-TI]增强句内语义信息。编码模块主要为以下3个部分,如图3所示。
1)句内语义信息部分([CON-TI])
本文设计[CON-TI]来捕获句内上下文语义信息的位置。同时,每个构造的Token包括3个部分:Token embedding(ET)、Type embedding(EY)和Position embedding(EP)。

表1 Spider与SParC数据集对比
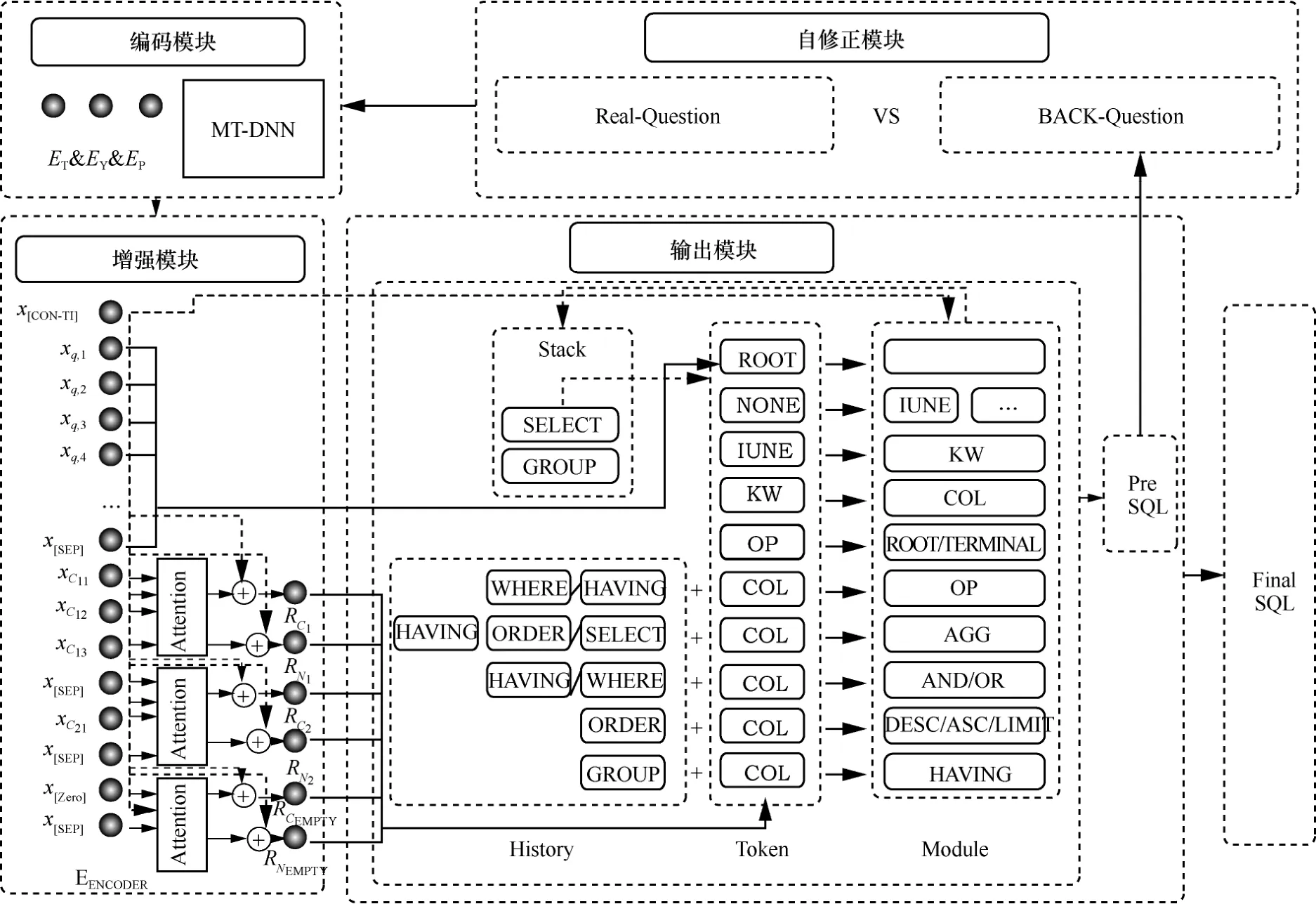
图2 PT-Sem2SQL模型的整体结构与基础模块
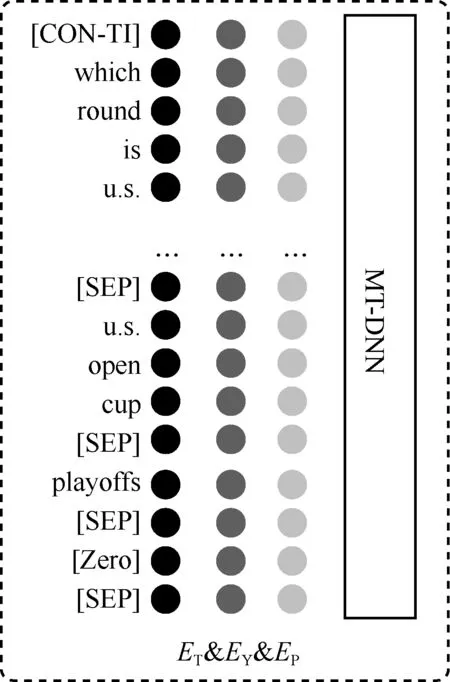
图3 PT-Sem2SQL模型的编码模块
2)零列部分([Zero])
本文扩展原有用于编码自然语言查询的预训练模型,添加表头列表。同时采用[SEP]将查询子句与表头列表分离,在每个列表模式中增加[Zero]部分。同时,本文也对KW-COL的交叉熵损失函数进行优化,重新定义KL值,使其KL值介于D(Q|PKW-COL)之中,即
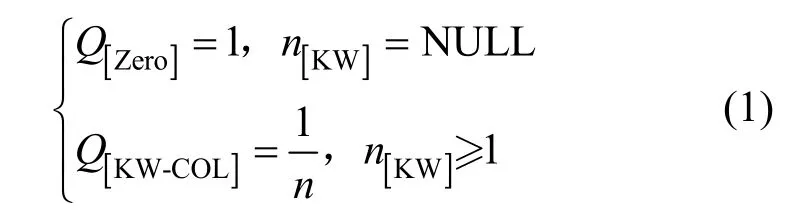
3)MT-DNN初始化部分
将编码器与MT-DNN预训练技术共同使用,使其编码器具有多个自然语言查询任务的功能。最终为模型对齐的有效查询提供支持。
3.3 增强模块
利用PT-Sem2SQL模型的编码模块输出用于编码的向量,即
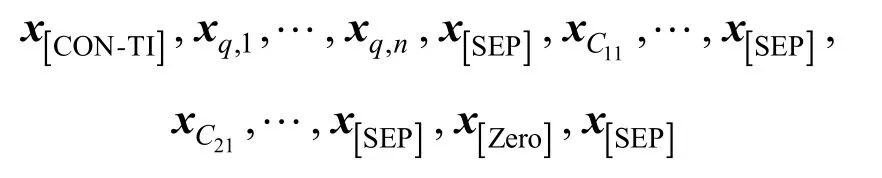
其中,x[CON-TI]代表捕获的句内上下文语义信息;每个查询句输入为xq,1,…,xq,n(n是查询字的数量);是第i列第j个Token的输出;表示增强模块的输出。所有向量都属于ℝd,d是MT-DNN编码器的隐藏维度(在大型MT-DNN模型中d=1 024)。
由于在编码模块中各部分捕获上下文影响力不够强,本文建立增强模块以加强句内的上下文影响。增强模块使用x[CON-TI]来更新架构内各个部分,同时与输出模块不同模块相互对齐连接。用softmax分类器将对齐模型分类,如式(2)所示。

其中,αij为匹配全局上下文的列的第j个标记的输出;。总结每列结果,采用式(3)计算增强模块。
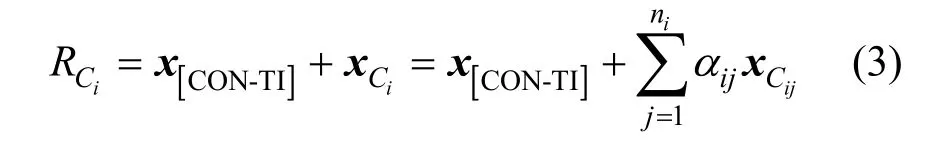
本文采用与式(2)和式(3)相类似的方式,统计增强模块预测关键字数。为了防止出现嵌套模块,本文添加终端模块的预测,具体将在第3.4节中详述。
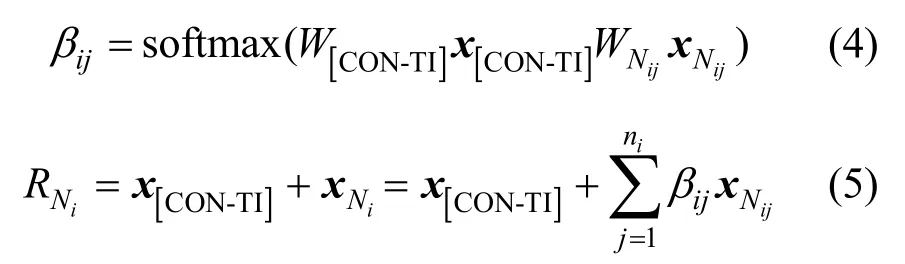
3.4 输出模块
本文引入Yu等[31]在Text-to-SQL任务的分解方式,将其分解为9个子模块。各模块都预测最终SQL查询语句的一部分。但是,与Yu等所提SyntaxSQLNet模型不同的是,本文的PT-Sem2SQL模型定义编码模块和增强模块,各个模块的计算方式也相应产生变化。同时,也注意到使用一个堆栈来运行本文的解码过程,直到其置空。
1)$ IUEN子模块
其关键字选自{INTERSECT,UNION,EXCEPT,NONE}中及概率计算式,为
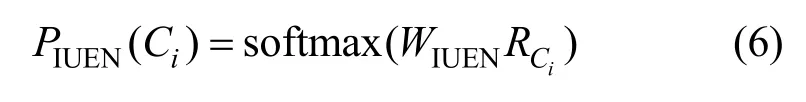
2)$ KW子模块
为结合复杂跨领域查询的特性,PT-Sem2SQL模型需要先预测SQL查询语句中的关键字数,并在3种可能的关键词中进行选择{WHERE,GROUP BY,ORDER BY}。

3)$ OP子模块
子模块关键字选自{=,>,<,>=,<=,!=,LIKE,NOT IN,IN,BETWEEN}。$ OP子模块同样需要先预测关键字数,其概率计算式为

4)$ AGG子模块
子模块关键字选自{MAX,MIN,SUM,COUNT,AVG,NONE}。同样,它取决于聚合器的数量,计算式为
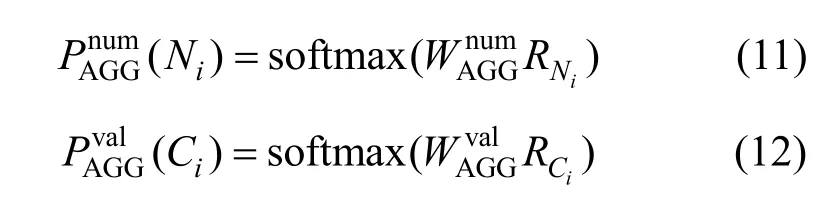
5)$ COL子模块
采用$ COL子模块来预测表中各列,其概率计算式为
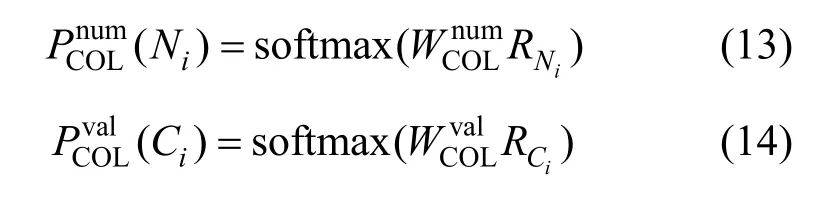
6)$ ROOT/TERMINAL子模块
为了结合复杂跨领域查询的特性,本文添加预测跨度以方便预测是否有新的子模块。这种方法能有效预测跨度的开始和结束位置。同时,模型需要首先调用$ OP子模块,然后确定它何时是$ ROOT子模块。
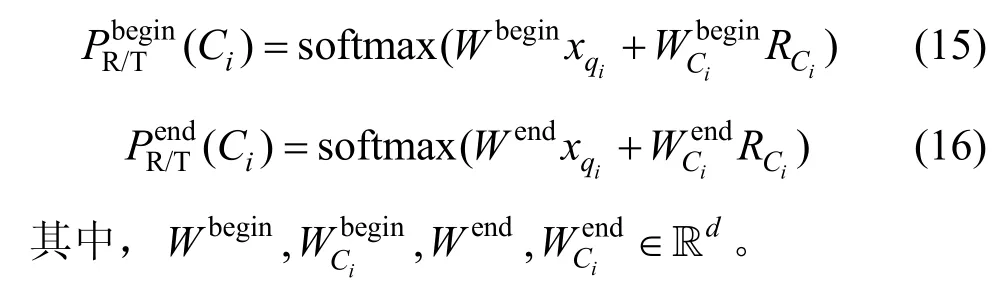
7)$ AND/OR子模块
子模块关键字选自{AND,OR}中,其概率计算式为
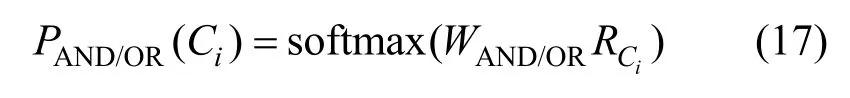
8)$ DESC/ASC/LIMIT子模块
同样,模块选自母模块ORDER BY下的{DESC,ASC,DESC LIMIT,ASC LIMIT}中,概率计算式为

9)$ HAVING子模块
模块选自母模块GROUP BY下的{HAVING},概率计算式为
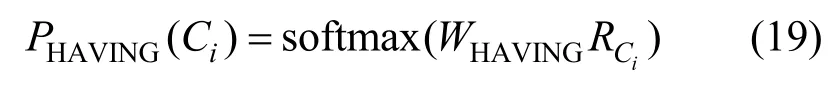
3.5 自修正模块
将输出模块生成的SQL查询语句反向生成伪查询问题(back-question),传入自修正模块。通过伪查询与真实的查询问题(real-question)间进行二元极大博弈,以达到模型自修正的目的。自修正模块解析如图4所示。
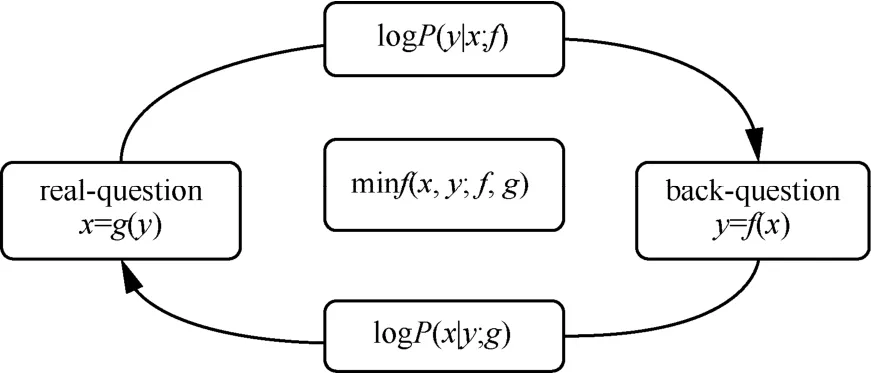
图4 PT-Sem2SQL模型的自修正模块
修正函数定义为
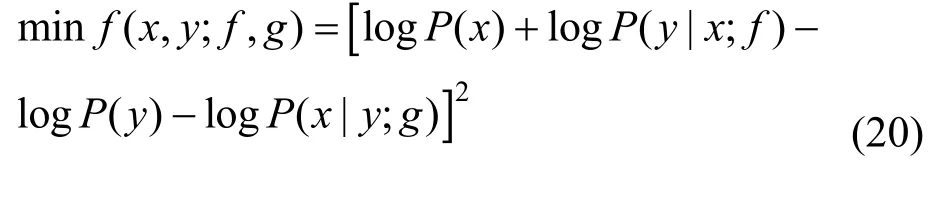
4 实验
4.1 实验环境和数据集
本文使用复杂跨领域的Spider数据集[7]进行初步验证,包括11 840个查询问题,其中有6 445个独特的复杂跨领域SQL查询和206个具有多个表的数据库。同时,这也是一个具有复杂跨域SQL查询的新型Text-to-SQL数据集。Spider数据集同时汇聚6个现有数据集中的数据,分别为Restaurants[32-33]、GeoQuery[34]、Scholar[35]、Academic[36]、Yelp和IMDB[37]。本文将Spider数据集随机划分为3个部分进行实验,即训练集(8 659个查询问题)、验证集(1 034个查询问题)、测试集(2 147个查询问题)。为进一步验证PT-Sem2SQL模型在上下文相关跨领域Text-to-SQL数据集中的效果,本文使用SParC数据集进行更进一步实验。在SParC数据集中同样采用随机划分进行实验,即训练集(3 024个查询问题)、验证集(422个查询问题)、测试集(842个查询问题)。
本文的PT-Sem2SQL模型是在Python 3.6上采用PyTorch并在MT-DNN之上构建实现的。具体来说,模型使用全局学习率为10–5的Adam优化器,其中,β1=0.9或β1=0.999。同时,根据2017年Smith等[38]提出的增加训练过程中的Batch Size,能够在训练集和测试集上取得类似学习率衰减表现的思想,设置Batch Size大小为32。PT-Sem2SQL模型采用全链接层的注意力机制,Dropout参数选自{0.1,0.2,0.3,0.4,0.5,0.6},并通过参数调整性实验训练10轮,选择在验证集上的最佳匹配模型将Dropout设置为0.2。
4.2 Spider数据集
4.2.1 Spider准确度测量
本文通过对比先前的模型来评估PT-Sem2SQL模型的执行效果。表2为模型在验证集和测试集上文本到SQL查询的准确性。为了对比展现自修正模块的影响程度,在表2中添加消融性实验结果展示行。
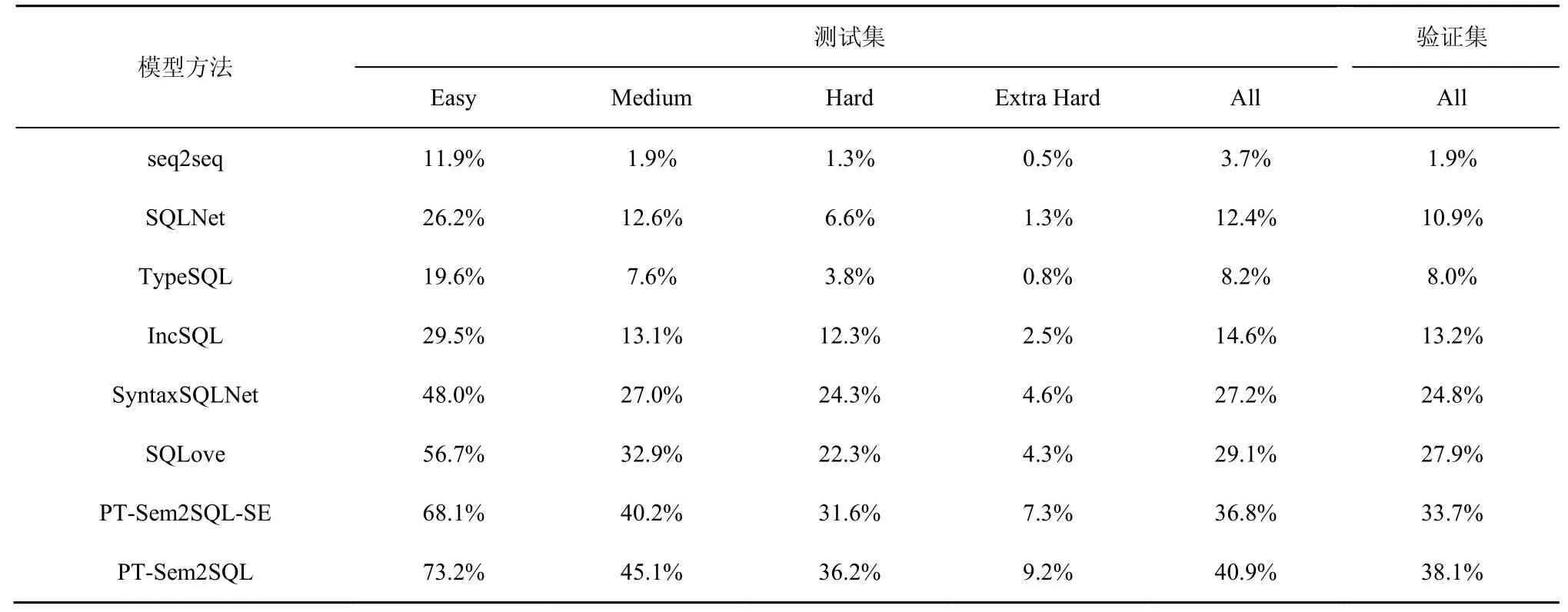
表2 Spider数据集中不同难度水平下各模型的准确度测量
由表2实验结果可知,对比其他基线Text-to-SQL模型(包括最新的SQLove模型),在Spider数据集上本文模型都表现出较好的准确性。同时在PT-Sem2SQL模型中,使用自修正技术导致执行精度在测试集中从原先的36.8%提高到40.9%,在验证集从原先的33.7%提高到38.1%。由此可见,采用自修正方法可以显著改善效果。
4.2.2 各模块准确度测量
2018年,Yu等将SQL子句分解为5个部分(如“SELECT”“WHERE”“GROUP BY”“ORDER BY”和“KEYWORDS”)来计算组件匹配F1分数[7]。本文模型也效仿该方式,检查各个组件是否完全匹配,如表3所示。
从表3的结果可以看出,本文设计的PT-Sem2SQL模型是第一个在各个模块都超过60%准确度的模型。特别地,PT-Sem2SQL模型在最具挑战性的[WHERE]子句上取得很好的准确率。这主要归功于重新设计增加[Zero]和[CON-TI]的编码模块。该模块在MT-DNN预处理的基础上重新结合Kullback-Leibler差异技术定义KL值增加[Zero],再利用[CON-TI]部分增强句内语义信息,为模型提供更多的示例,贴合满足复杂跨领域数据的查询需求。
同时,本文认真分析错误检索表中的错误输出问题。关注到主要是因为在使用模板自动生成查询时,概率性引入一些错误。例如,问题“What is the maximum percentage grown 2000—2008 in burundi?”与“year”有关,错误输出SQL查询包含不必要的“COUNT”。同时,另外一个值得注意的错误是因为人们设计的训练数据中没有考虑自然语言的模糊性表达问题。虽然针对Spider数据集此类问题不是关键性问题,但对于其他大多数任务却是共性问题。比如针对同样的自然语言查询,一些人倾向于使用自然语言“和”,而另外一些人倾向于使用自然语言“或”进行表达。
4.2.3 各训练数据量准确度测量
为观测各模型在不同训练数据量下的表现,本文选择在{20%,40%,60%,80%,100%}训练集下刻画准确度趋势,如图5所示。

图5 各模型在不同训练数据量下的准确度趋势
实验结果表明,在不同训练数据量下,PT-Sem2SQL的性能都优于其他6个基线模型。此外,随着训练数据量的增加,PT-Sem2SQL可以实现的性能改进尤为突出,准确度测量高于其他模型。其主要原因是随着训练数据资源的增加,PT-Sem2SQL可以更好地训练问题分解器并进行信息提取,进而生成更准确的查询子模块以及准确填充提取的关键词信息。这些有助于PT-Sem2SQL在Text-to-SQL语义解析过程中获得更好的逻辑形式结果,提升模型准确度。

表3 Spider测试集上各组件匹配的F1分数
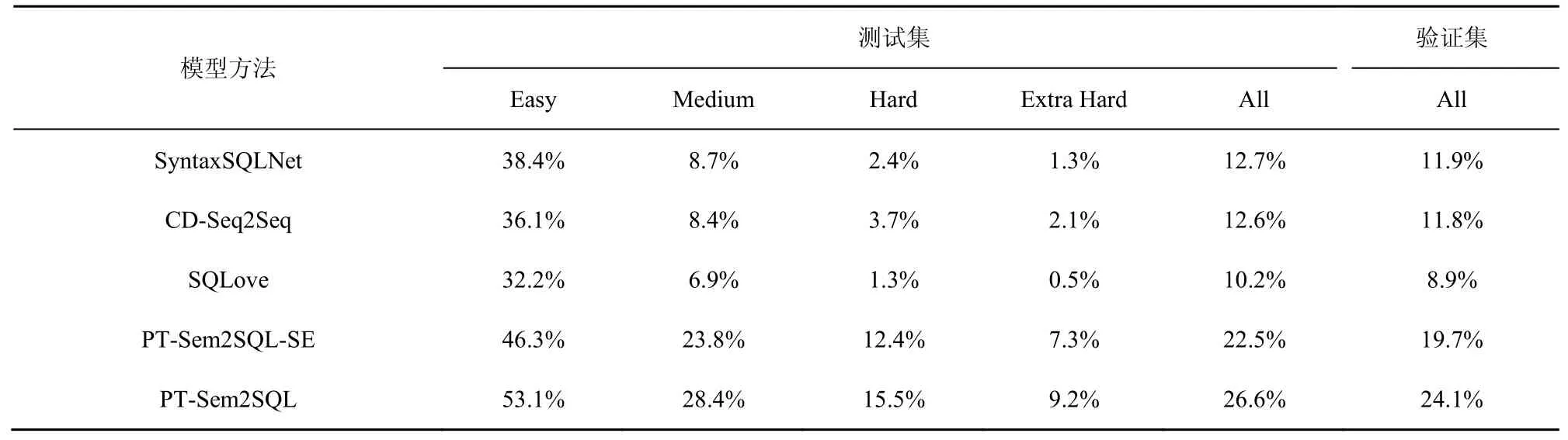
表4 SParC数据集中不同难度水平下各模型的准确度测量
4.3 SParC数据集
4.3.1 SParC准确度测量
与Spider数据集类似,本文的模型准确度测量重点对比2018—2019年Yu等所提出的基线SyntaxSQLNet[31]、CD-Seq2Seq[39]模型与2019年Hwang等所提出的基线SQLove模型[29]。Spider数据集上不同难度水平占比分别为:Easy(40%)、Medium(37%)、Hard(12%)、Extra Hard(11%)。对比实验结果如表4所示。
从表4的结果可以看出,PT-Sem2SQL的测试集准确度性能首次达到26.6%。进行自修正模块消融实验后模型在验证集和测试集上的准确性仍优于其他基线模型,可以基本解决上下文相关Text-to-SQL任务。通过消融实验可以看出,自修正模块对模型性能贡献度较高,在测试集中执行精度从原先的22.5%提高到26.6%,在验证集中执行精度从原先的19.7%提高到24.1%。
4.3.2 问题匹配度与上下文相关交互匹配度测量
2019年,Yu等将上下文感知模型的性能测试分解为2个部分(问题匹配度测量和上下文相关交互匹配度测量),以此计算上下文相关跨领域Text-to-SQL的模型匹配度[8]。本文模型也效仿该方式,检查模型是否完全匹配,具体如表5所示。
实验结果表明,PT-Sem2SQL模型性能优于其他基线模型,问题匹配度高达34.1%,而上下文相关交互匹配度达13.4%,相比最佳历史基线CD-Seq2Seq模型提升5.9%。当模型进行消融实验后,问题匹配度由34.1%降低到32.7%,上下文相关交互匹配度由13.4%降低到11.9%。主要是因为模型在自修正模块可以分析历史问题差异性,经过修正模块后可解析问题间交互差异,有效扩展上下文相关交互通路。同时,通过表5可以看出,由于SParC数据集复杂度大幅增加,各模型匹配度表现欠佳,仍有很大的改进空间。
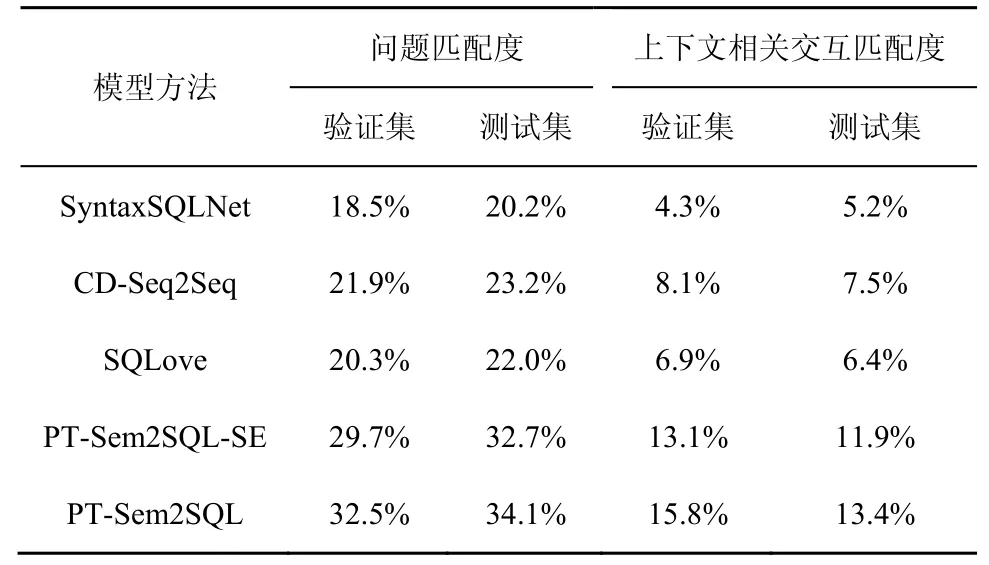
表5 问题匹配度与上下文相关交互匹配度测量
5 结束语
本文提出了PT-Sem2SQL模型,重新解构复杂语义解析问题,强化Text-to-SQL任务的上下文信息。同时,本文基于最先进的MT-DNN预训练技术重新设计模型的编码模块,成功解决在复杂语义Text-to-SQL任务数据集中的列预测问题。针对解码过程中的错误输出问题,PT-Sem2SQL模型自修正模块优化模型。通过Spider和SParC数据集的不同模型对比实验结果表明,本文的模型展示优于所有基线模型,表现出卓越性能。这些新的尝试为复杂的跨域Text-to-SQL任务提供有效技术支持,也希望下一步引入知识图谱表征方法,解决局部子句查询出错的问题。
