基于人工蜂群算法的分布式入侵攻击检测系统
2019-04-01谭继安关继夫
谭继安 关继夫
1(东莞职业技术学院 广东 东莞 523808)2(广东医科大学教育技术与信息中心 广东 东莞 524023)
0 引 言
随着互联网与移动互联网的蓬勃发展,网络金融、网络购物等已经成为人们工作与日常生活中必不可少的一部分,因此网络安全是当前社会与国家安全的重中之重[1]。网络入侵检测系统 IDS(Intrusion Detection Systems)[2-3]作为一种有效的安全防御机制,能够快速地检测出网络攻击,已经成为了网络安全领域的研究热点。目前的IDS系统主要可分为如下几种类型[4]:基于统计分析的系统、基于规则的系统、基于人工神经网络的系统、基于数据挖掘的系统、基于条件概率的系统、基于模式检测的系统、基于免疫系统的系统。智能计算具有高适应性、高容错性以及高计算效率的优点[5],所以人工神经网络、模糊系统、演化算法、人工免疫系统、粒计算等算法在入侵检测系统中获得了深入的研究与广泛的应用。
在诸多的智能计算中,人工神经网络(ANNArtificial Neural Network)在IDS系统中的应用最为广泛[6-8],此类方案一般先对网络数据集进行标准化处理,随之通过降维处理以确定主分量的特征数,最后将处理完成后的数据集输入到神经网络中进行检测。基于神经网络的入侵检测系统比传统机器学习技术具有更高的准确率,但是神经网络的训练时间较长,并且训练的特征集存在较多的冗余与噪声[7-8]。冗余特征与不相关特征会导致IDS的计算时间增加并且影响检测准确率,因此许多研究人员融合其他的智能计算方法对特征集进行优化[9-10],从而提高IDS的性能,例如:机器学习、贝叶斯算法、自然启发式算法、种群智能算法以及免疫系统。
根据国内外研究人员的成果,IDS中数据集特征的优化已经成为决定IDS性能的关键因素[11]。本文提出了一种高效率、高准确率的IDS,其中引入了人工蜂群算法ABC(Artificial Bee Colony)[12]删除冗余与噪声的特征。采用模糊C-means分类技术FCM(Fuzzy C-Means)划分训练数据集,采用基于相关性的特征选择CFS(Correlation-based Feature Selection)删除非相关的特征。实验结果表明,该系统实现了较高的检测性能,并且实现了较高的计算效率。
1 系统设计
ABC的寻优过程具有较高的随机性,其中新食物源的适应度是否优于当前食物源的概率相等,所以ABC无法保证始终获得最优的食物源。此外,ABC的探测能力受选择机制的影响较大,并且搜索速度较慢。本文对ABC进行了改进,提高IDS的检测准确率与计算效率。IDS的结构为:(1) 划分训练数据集;(2) 特征选择;(3) 规则生成;(4) 训练混合分类器;(5) 基于ABC生成分类规则集。
1.1 基于FCM划分训练数据集
划分训练数据集能够有效地降低记录的数量与复杂度。模糊C-Means算法的分类效果较好并且易于实现,同时文献[13]证明基于距离的分类技术对于噪声具有鲁棒性,因此采用模糊C-Means算法降低IDS的计算复杂度。该算法的目标是最小化以下的目标函数:
(1)

(2)
(3)
迭代程序的结束条件如下式定义:
(4)
1.2 基于相关性的特征选择
CFS的速度快于基于封装的特征选择方案,适合处理大规模的网络安全问题。本方法使用基于相关性的特征选择方法,提取的特征集中包含类内相关性高、类外相关性低的特征。
CFS的目标是提取最优的特征子集,CFS一般需要融入其他的搜索技术,包括:前向选择处理、后向消除处理、双向搜索处理等。CFS的公式定义为:
(5)
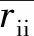

表1 CFS特征选择模型对UNS2-NB15与 NSL-KDD数据集选择的特征
1.3 基于CART生成规则
NSL-KDD的训练集中包含67 343个正常记录与58 630个异常记录,将输入数据分为标定数据与数值数据,采用量化的特征生成规则。从数据集的41个特征中选出Flag、Src_bytes、Dst_bytes、Logged_in、Srv_serror_rate、Diff_srv_rate特征将流量分离,生成精简的规则集。Flag为一个类别特征,包含了11个属性,因此需要在预处理步骤将该特征转化为数值。例如:Flag为RSTOS0,那么该网络行为被识别为异常行为。Srv_serror_rate、DF、Src_bytes与Dst_bytes的不同取值也会对异常或者正常行为的判断产生影响。因此,需要通过一个有效的规则生成机制来支持不同的特征组合。CART[15]基于二值递归分类与信息理论而实现,能够处理多类型数据集,该技术采用一个统计检验技术识别重要的特征,从而识别网络流量的异常行为。
基于类别数据生成的规则可以区分正常行为与异常行为,然后,根据数值识别攻击的类型。将正常行为划分为Ki个区间,从而减少计算时间。Ki的最小值与最大值分别表示为Kimin与Kimax,因此Kvalue所有的可能值计算为下式:
Kvalue={N/2, (N-1)/2, (N-2)/2,…, 4/2}
(6)
式中:N表示数据集的一次观察,并且K>1,N≥4。式(6)的子区间提高了正常、异常划分的准确率,并且降低了漏检率。将[Kimin,Kimax]区间的记录划分为正常记录,否则划分为异常记录。
1.4 混合ABC-AFC分类器算法
1.4.1 人工蜂群算法(ABC)
人工蜂群算法是一种基于种群的优化程序,该算法共有三种蜂群类型,分别为雇佣蜂、观察蜂、侦察蜂,雇佣蜂在食物源附近搜索食物源,选择合适的食物源,并且与观察蜂分享食物的信息。如果雇佣蜂放弃它们的食物源,那么这些雇佣蜂变为侦察蜂去搜索新食物源,每个食物源的位置即为优化问题的一个可行解。ABC算法的前半部分蜂群为雇佣蜂,后半部分为观察蜂,解的数量等于雇佣蜂或者观察蜂的数量。该算法的流程如下所示:
初始化阶段:生成一个随机分布的初始化种群。食物源的初始化方式如下所示,其中xi={xi1,xi2,…,xiD}为第i个解,D为解的维度。
xi=li+rand(0,1)×(ui-li)
(7)
式中:ui与li分别为目标函数解i的最大边界与最小边界,xi表示一个D维向量。
雇佣蜂阶段:每个雇佣蜂采集一个食物源的蜂蜜。该阶段的雇佣蜂可根据实际的观察情况与旧食物源的记忆库修改其位置。食物源的更新方法如下式所示:
vmi=xmi+φmi(xmi-xki)
(8)
式中:i∈{1,2,…,D},k为{1,2,…,BN}内的一个随机值,m为解的维度,BN为种群数量,φmi为[-1,1]区间的一个随机数,vmi为新食物源的位置。每个候选食物源的适应度函数如下式所示:
(9)
式中:fi表示第i个解的目标值。将新食物源与旧食物源的适应度进行比较,采用贪婪策略选择最优的食物源。
观察蜂阶段:观察蜂通过摇摆舞获取高质量的食物源信息,摇摆舞中包含了食物源的方向与蜂蜜量等信息。食物源的质量计算为下式:
(10)
式中:fiti表示食物源i的适应度,SN为食物源的数量。
侦察:如果雇佣蜂放弃其食物源则变为侦察蜂。雇佣蜂忽略低质量的食物源,通过式(7)寻找新的食物源。
1.4.2 人工鱼群算法(AFS)
AFS是一种仿真鱼群协同行为的人工智能算法[16]。该算法的优点有:收敛速度快、灵活性高、鲁棒性强、搜索可行解的速度快。AFS算法共包括两个部分的变量与函数。算法中X=(x1,x2,…,xn)表示人工鱼群的当前状态,对应于问题的解,Y=f(x)表示食物源鱼群的集中程度,其中Y为目标函数。步长(Step)表示人工鱼每次移动的距离,可见距离(Visual)表示人工鱼的可见距离。Xv表示人工鱼可见的区域,try_number表示觅食行为的最大迭代次数,δ(0<δ<1)表示拥挤因子。图1所示是人工鱼群算法各个要素之间的关系。
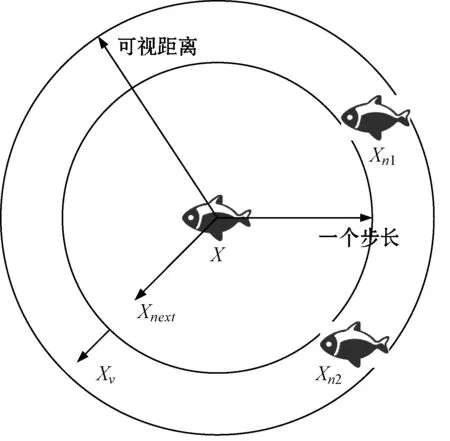
图1 人工鱼群算法各个要素之间的关系
AFS算法仿真了鱼群的觅食行为、聚群行为与追尾行为。
觅食行为:假设Xi为人工鱼群的当前状态,Xj为可见距离内随机选择的一个新状态,Xj的计算方法为:
Xj=xi+Visual·Rand()
(11)
可见距离Visual表示Xi的可见范围,Rand()函数表示取[0,1]区间的一个随机数。
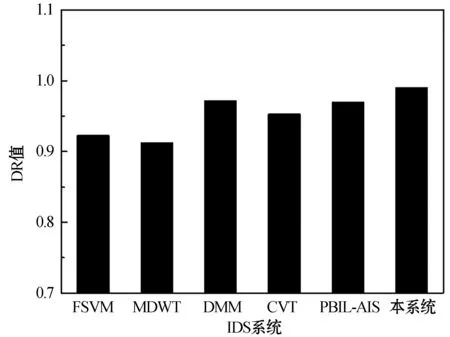
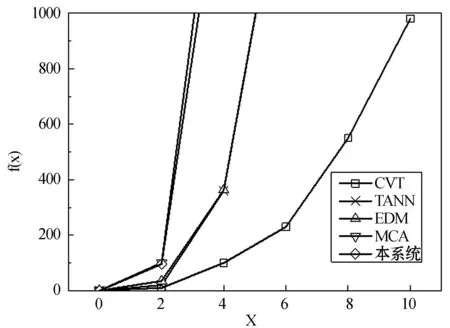
如果新的位置优于当前位置,即Yi (12) 如果在移动try_number次步长之后仍然未能满足条件,那么人工鱼在可见距离内随机移动一个步长,具体方法为: (13) 式中:Rand()表示[0,1]区间的一个随机值。 聚群行为:假设Xi是一个人工鱼的当前状态,Xc是当前可见范围的中心,nf是当前可见范围内的人工鱼数量。如果Yc﹥Yi,Yc/nf﹥δYi,则表示当前可见范围内中心的食物浓度高于当前的状态,并且该食物源的鱼群并不拥挤,然后人工鱼根据下式向中心移动一个步长;否则,重复觅食的行为,觅食行为定义为下式: (14) 追尾行为:假设Xi为一个人工鱼的当前状态,Xmax为当前可见范围内具有最大食物浓度的人工鱼,nf为当前可见范围内的人工鱼数量。如果Yj>Yi,并且Ymax/nf>δYi,则说明Xmax的食物浓度高于当前状态,并且该食物并不稠密,然后人工鱼根据下式向Xmax移动一个步长;否则,重复觅食的行为,觅食行为定义为下式: (15) 行为选择:聚群行为与追尾行为有助于人工鱼识别出最优解。因此,人工鱼需要通过一定策略选择合适的行为。 1.4.3 改进的ABC方法 人工蜂群算法与人工鱼群算法均为智能种群优化算法。ABC算法中pxki与φmi是两个随机值,因此ABC具有一定的随机性,但是新食物源的适应度高于或者低于之前食物源的概率相等,所以ABC无法保证始终获得最优的食物源。此外,ABC的探测能力受选择机制的影响较大,并且搜索速度较低。人工鱼群算法根据鱼群拥塞度决定人工鱼的移动方向,并且防止早熟收敛,拥塞度评估机制保证人工鱼无法游向稠密的食物源,但是,人工鱼群算法的局部探测能力较弱。在网络的注入攻击检测问题中,食物与注入攻击对应,食物的密度与攻击量对应,蜂蜜表示攻击对网络agent的行为。算法1所示是混合算法的伪代码。 算法1改进的ABC算法 1. 创建ABC的初始化种群。2. 启动人工蜂搜索最优食物源。3. 基于AFS算法开始人工蜂搜索程序。4. FOREACH (当前位置的每个人工鱼Xi) {5. n=0;//人工鱼搜索新的食物源;6. WHILE (n < try_number) {7. 人工鱼选择Xj作为新位置;8. IF (新位置优于旧位置) {9. 人工鱼移动一个步长;10. GOTO 第18行;11. }ELSE{12. n=n+1;13. }14. }15. IF (人工鱼无法找到最优位置) {16. 随机选择可见距离内的一个位置;17. }18. 人工蜂与观察蜂分享食物源信息。//摇摆舞19. 观察蜂选择较优的空间。20. } 算法的第1阶段,通过式(7)随机地生成初始化食物种群,然后,释放雇佣蜂搜索高质量的食物源,每个人工蜂运行AFS算法搜索食物源。假设Xi为人工鱼的当前位置,在人工鱼的可见区域内随机选择一个位置。如果新位置Xj优于当前位置,即Yi 图2所示是本IDS系统的基本框架。具体步骤如下: 图2 本文分布式IDS系统的基本框架 步骤1预处理训练数据集。 步骤2使用FCM生成不同的训练子集。 步骤3为每个训练子集创建一个初始化种群。 步骤4采用CFS特征选择算法处理每个种群,删除种群的噪声特征与冗余特征。 步骤5为步骤2生成的每个子集产生规则集,这些规则集融合组成最终的规则集。 步骤6运行改进的ABC算法。 步骤7通过规则集训练改进的ABC算法。 步骤8计算FP、FN、TP、TN参数。 步骤9使用FP、FN、TP、TN计算检测精度。 步骤10测试加载的数据集。 步骤11比较计算的结果。 采用检出率DR(Detection Rate)、虚警率FAR(False Alarm Rate)与检测精度DA(Detection Accuracy)三个指标评估网络入侵检测系统的性能,DR表示异常行为被正确分类为异常的比例,FAR表示正常、异常行为被错误分类的比例,检测精度表示正常、异常行为均被正确分类的比例。DR、FAR、DA三个指标的计算方法分别如下式所示: (16) (17) (18) (19) (20) 式中:FN表示异常行为被错误分类为正常行为的百分比,TN表示正常行为被正确分类为正常行为的百分比,TP表示异常行为被正确分类为异常行为的百分比,FP表示正常行为被错误分类为异常行为的百分比。 在NetBeans IDE 8.1环境下使用JAVA语言开发本系统,采用Weka 3.8软件允许系统的CFS特征选择算法。实验环境为windows7 64位操作系统,Intel Core i7处理器,8 GB内存。 采用NSL-KDD与UNSW-NB15[17]两个数据集作为benchmark数据集。NSL-KDD数据集解决了KDD99数据集中存在的固有问题,NSL-KDD数据集由于缺少基于入侵检测网络的公共数据集,所以NSL-KDD数据集并非现有真实网络的完美代表。但NSL-KDD仍然作为有效的基准数据集,帮助研究人员比较不同的入侵检测方法。UNSW-NB15综合数据集能够很好地反映当今网络环境下的流量特征,并且包括了丰富且全面的入侵检测数据,因此该数据集能够很好地评估IDS的性能。 表2所示是IDS参数的取值情况。 表2 仿真参数与相关取值 将本方法与其他IDS进行了比较。表3所示是本系统对于NSL-KDD训练集与测试集的检测准确率平均值、最小值与最大值,该实验从NSL-KDD数据集随机选择样本进行实验。 表3 本系统对NSL-KDD训练集与测试集的检测 精度平均值、最小值与最大值 UNSW-NB15数据集能够反映真实攻击的网络环境,从该数据集选择不同规模的数据集作为实验数据集,文件数量从60 000到220 000。每个数据集中选择65%样本作为训练集,剩下的35%作为测试集,将式(6)的Kvalue值分别设为2、4、6、8、10。图3(a)与图3(b)所示分别为不同K值条件下本系统对于NSL-KDD与UNSW-NB15两个数据集的性能结果,性能指标分别包括:DR、准确率DA、FAR。从图中可看出,K值对性能指标具有直接的影响,UNSW-NB15数据集实验中K值从2增至10,DR与DA指标均明显升高,而FPR则明显下降。NSL-KDD数据集实验中K值从2增至10,DR与DA指标均明显升高,而FPR则明显下降。 (a) NSL-KDD数据集 (b) UNSW-NB15数据集图3 不同K值条件下本系统对于NSL-KDD与 UNSW-NB15两个数据集性能结果 为了评估本IDS系统对攻击行为的分析能力,统计了不同K值情况下NSL-KDD与UNSW-NB15数据集各种攻击类型的DR值,分别如图4(a)和图4(b)所示。对于UNSW-NB15数据集,正常记录与异常记录的DR值区间分别为42.6%~92.8%, 对于NSL-KDD数据集,正常记录与异常记录的DR值区间分别为93.7%与100%。 (a) NSL-KDD数据集 (b) UNSW-NB15数据集图4 不同K值情况下NSL-KDD与UNSW-NB 15数据集各种攻击类型的DR值 将本系统与其他IDS系统进行比较,分别为:FSVM[18]、MDWT[19]、DMM[20]、CVT[21]与PBIL-AIS[22]。图5(a)和图5(b)所示分别为IDS系统对于UNSW-NB15数据集的实验结果。综合两图的结果可看出,本系统的DR结果优于其他5个IDS系统,文献[22]中分析认为无法获得PBIL-AIS的虚警率值,所以将本系统与其他4个IDS系统比较,结果显示本系统的虚警率结果优于其他4个IDS系统。 (a) DR值 (b) 虚警率值图5 6个IDS系统对于UNSW-NB15数据集的实验结果 计算复杂度与时间成本是IDS的另一个关键性能指标。本文的IDS系统共有5个步骤组成。① FCM的计算复杂度为O(ns2D),式中n、s与D分别为特征数量、子集数量与维度。② CFS最坏的情况需要(n2-n)/2次前向选择与后向消除搜索操作,因此,计算CFS的成对特征选择矩阵的复杂度为O(n2),其中n表示特征数量。③ 基于CART的规则生成过程中,计算复杂度主要是一个建立决策树的程序,建立决策树的复杂度等于O(n×vlogv),其中n与v分别表示特征数量与记录数量。④ 假设l、n、D分别表示ABC算法的最大迭代次数、人工agent数量以及搜索空间的维度,ABC中计算人工蜂与人工鱼位置的复杂度为O(n×D)。ABC的复杂度为O(n×D×l)。⑤分类器的复杂度则为O(n2)。 最终,本文IDS的总计算复杂度为O(ns2D+n2+nvlogv+nlogn+n2)=O(n2)。将本方法与其他IDS的复杂度进行比较,复杂度转化为关于O的函数f(x)=O(g(x)),其中g(x)表示总计算复杂度,x表示实数,图6所示是5个IDS系统的f(x)曲线图。时间成本表示数据处理所需的时间,因此可获得每秒钟处理的记录数量。本文的IDS每秒钟可处理约28 543个记录,本系统快于CVT系统、TANN系统、EDM系统,略低于MCA系统。 图6 5个IDS系统的f(x)曲线图 本文提出了一种高效率、高准确率的IDS,其中引入了人工蜂群算法删除冗余与噪声的特征。采用模糊C-means分类技术划分训练数据集,采用基于相关性的特征选择删除非相关的特征。本系统的检出率结果与虚警率结果均优于其他的IDS系统,每秒钟可处理约28 543个记录,实现了较高的计算效率。
1.5 基于改进ABC算法的分布式IDS系统

2 实验结果与分析
2.1 性能指标
2.2 仿真环境与实验数据集

2.3 实验结果与讨论

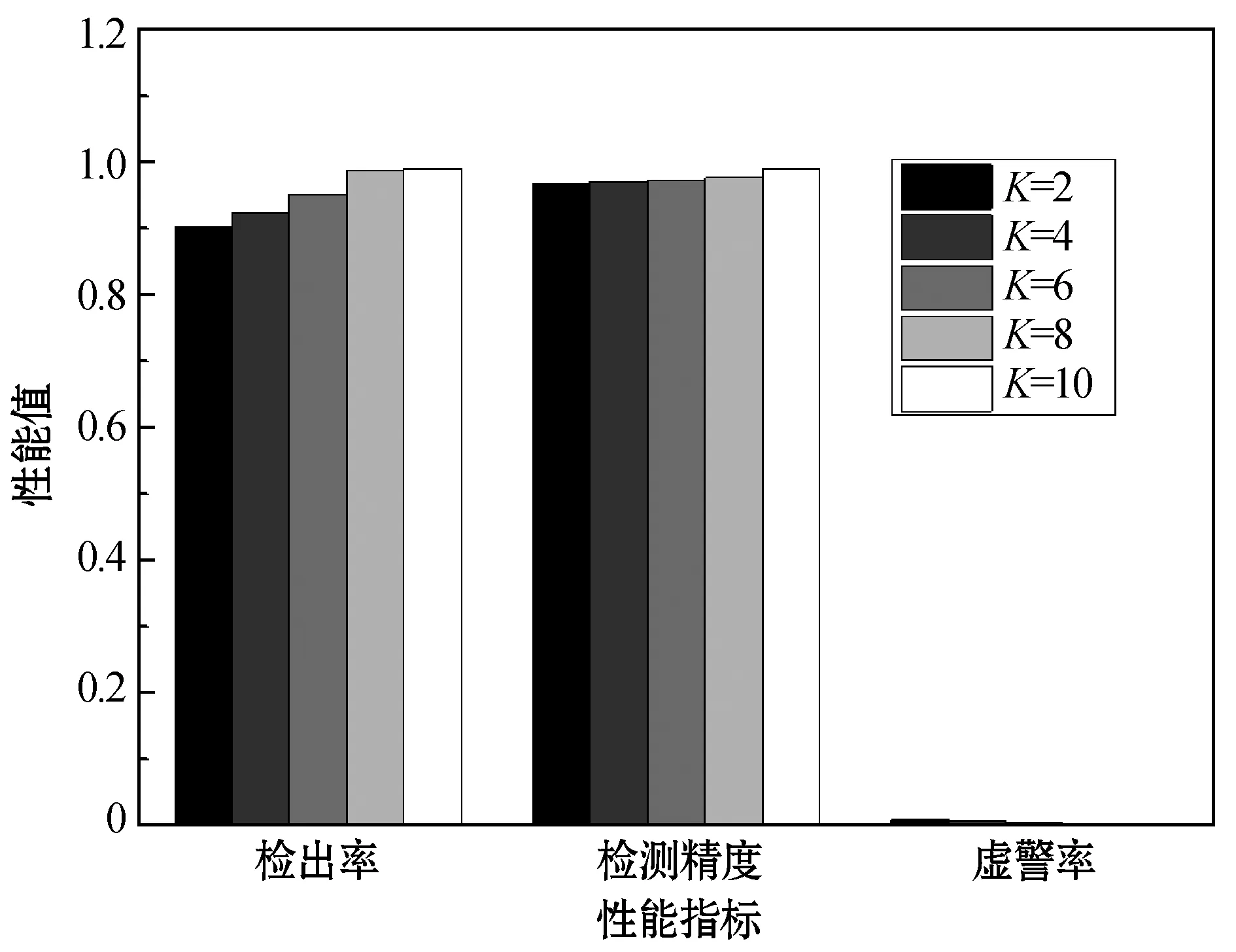
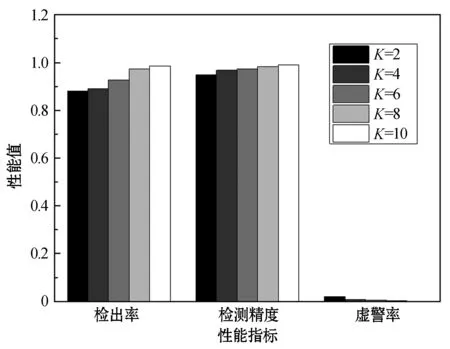


2.4 与其他算法的比较

2.5 计算复杂度分析
3 结 语
