四大名著文本中的无标度规律
2019-03-26孙龙龙顾长贵吴果林
孙龙龙,顾长贵,冯 靖,吴果林
(1.上海理工大学 管理学院,上海 200093;2.上海工程技术大学 高等职业技术学院,上海 200437;3.桂林航天工业学院 理学院,桂林 541004)
近年来,国内外许多学者都对文本语言内的无标度规律进行了详细的研究,并且取得了很多重要的成果。但前人大多数的研究对象都是英文文本,并且大多都是在单词层面,忽略了文本语言在其他层次上的无标度规律。本文的研究主要针对中文文本在句子、段落层次的无标度规律进行展开。
1 文字的无标度规律
人类语言学是非常复杂的社会系统[1],是人类文化在社会以及生物层面长时间演化的结晶[2]。在过去的一百年里,统计理论的日益完善,使得人类语言学的研究得到了长足的发展。其中,Zipf[3]提出了著名的Zipf’s定律。它的主要思想是将单词按照其出现频率进行排序,频率最高的单词标记为等级1(rank 1),频率第二高的单词标记为等级2(rank 2)……依次排列,在双对数坐标系里单词频率与等级标号呈现负相关规律。由Zipf’s定律,文献[4]中将Holy Bible翻译成多种语言,研究了每一种语言的Zipf指数。文献[5]对日文文本中平假名文字频率分布进行研究,指出日文中平假名的出现频率服从weibull分布的论点。文献[6]中指出了中文汉字出现频率服从幂律分布的特点。
对于语言内部存在的无标度规律(幂律分布)现象,许多学者也作了深入的研究。Altmann等[7]解释了无标度规律在单词层次和单词字母层次之间的演化。Deng等[8]对中国近现代小说从汉字使用频率角度加以研究,发现汉字的使用具有无标度规律现象。Montemurro等[9]和Bhan等[10]使用去趋势波动分析法(detrended flutuation analysis,DFA)对英文文本和韩文文本加以分析,发现英语和韩语内部存在的无标度规律。在文献[11-12]中,Ausloos和Gillet将英文文本转化为世界语文本,同样也得到了在英文文本和世界语文本中都存在无标度规律的性质。以上研究大多使用去趋势波动分析法分析非汉语语言文本的无标度规律。此外,去趋势波动分析法还可以有效探测非平稳性时间序列上的无标度规律,在DNA核苷酸序列、脉搏信号序列、金融时间序列、天气预测方面都有极为广泛的应用[13-20]。
目前对于语言文本无标度规律的研究大多基于单词的层面,而没有从语句和段落的更高层次对文本加以研究[19]。对语言文本而言,语句和段落是其重要的组成单元[20]。一方面,语句为单词的使用提供了具体的语境,另一方面,语句的逻辑排列形成语句群、段落乃至整个文本,从而清楚地表达作者思想。此外,上述文献的研究对象大都是英文文本,而很少有研究者对中文小说文本进行研究。然而,中文小说文本与西方文学作品有很大差别,即中国的汉字是由绘画引申而来[21],其后汉字经过几千年的演化使得中国人的思想表达方式与西方有很大不同。概括而言,汉字语言是世界上最为成熟的语言之一,而对于汉字在语句和段落层次上的无标度规律的研究,却很少有学者涉及。本文从语句层次以及段落层次使用去趋势波动分析法对中国古代小说文本四大名著加以研究。
2 四大名著文本数据
2.1 数据来源
本文所用到的数据均来自4大名著小说文本。四大名著是中国文学史中的经典作品,它们分别是《红楼梦》(A Dream of Red Mansions)简记为ADRM,《三国演义》(The Romence of Three Kingdoms)简记为TRTK,《水浒传》(All Men are Brothers)简记为AMAB,《西游记》(The Pilgrimage to the West)简记为TPTW。表1给出了四大名著相关文本数据。
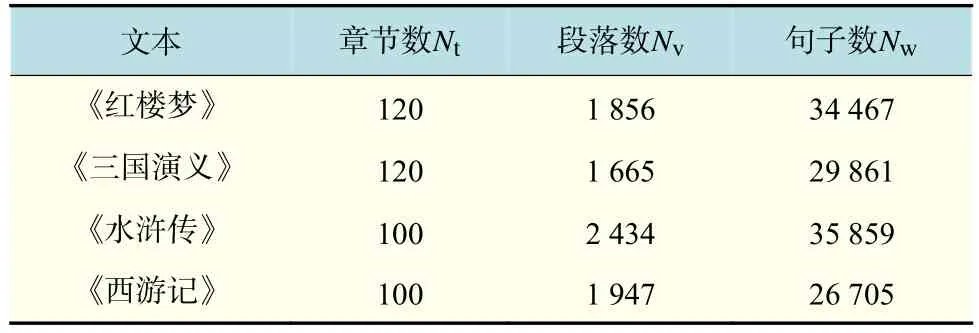
表1 四大名著相关文本数据Tab.1 Related data of Four Great Classical Novels
2.2 时间序列的提取
本文分别从以上4本小说文本中提取每段字数时间序列、每段句子数时间序列和每句字数时间序列。忽略所有标点符号,仅计算每段汉字的个数Mt,来构建每段字数时间序列;以句号(‘.’)、问号(‘?’)、感叹号(‘!’)、省略号(‘……’)为一句话结束的标志并忽略其他标点符号,来统计每句话汉字数Mv和每段的句子数Mw,并构建相应的时间序列。图1(a)为摘自《红楼梦》中的一段文字,其中标记在红框内的标点符号为每句话结束的标志。图1(b)为与上述文本相对应的每句字数时间序列 ξi={27,20,13,21,11,15,···},其中Num(n)表示句子数目,Mv(n)表示每句话的汉字数目。

图1 文本向时间序列的转化Fig.1 Translation from text to time series
3 无标度规律分析方法
去趋势波动分析法是1994年由Peng等[13]基于DNA机理提出的标度计算方法。该方法适用于分析非平稳性时间序列的长程相关性,其优点是它可以有效滤去序列中的各阶趋势成分,并能检测含有噪声且叠加有多项式趋势信号的长程相关[13-20]。假设一时间序列为其中N为序列长度。
首先对该序列进行相空间重构,可得到一系列时间序列片段Yn:

式中,s为去趋势波动分析法中盒子的大小。
其次,对每个时间序列片段用q阶多项式
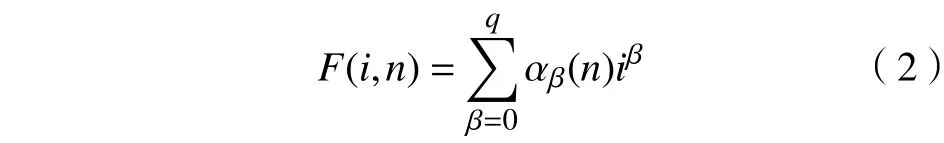
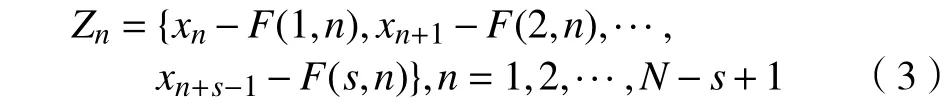
如果原时间序列存在长期相关性,则有
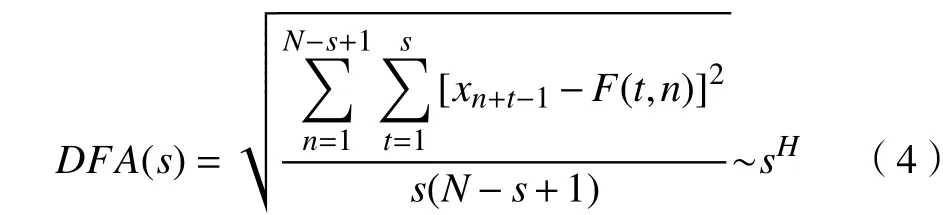
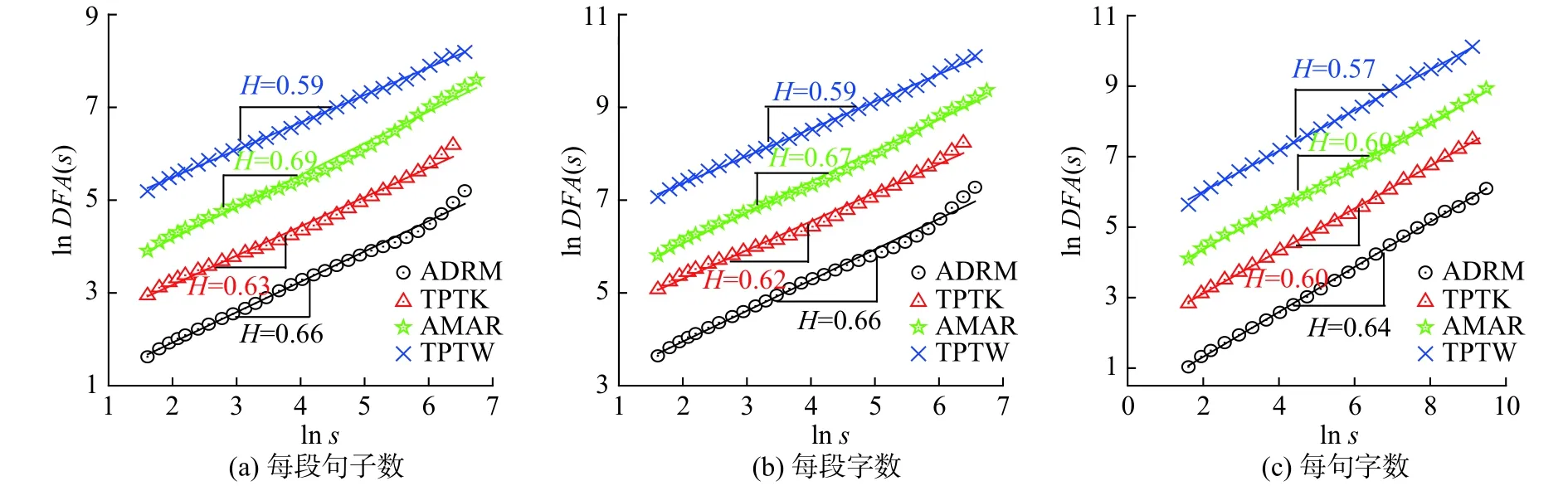
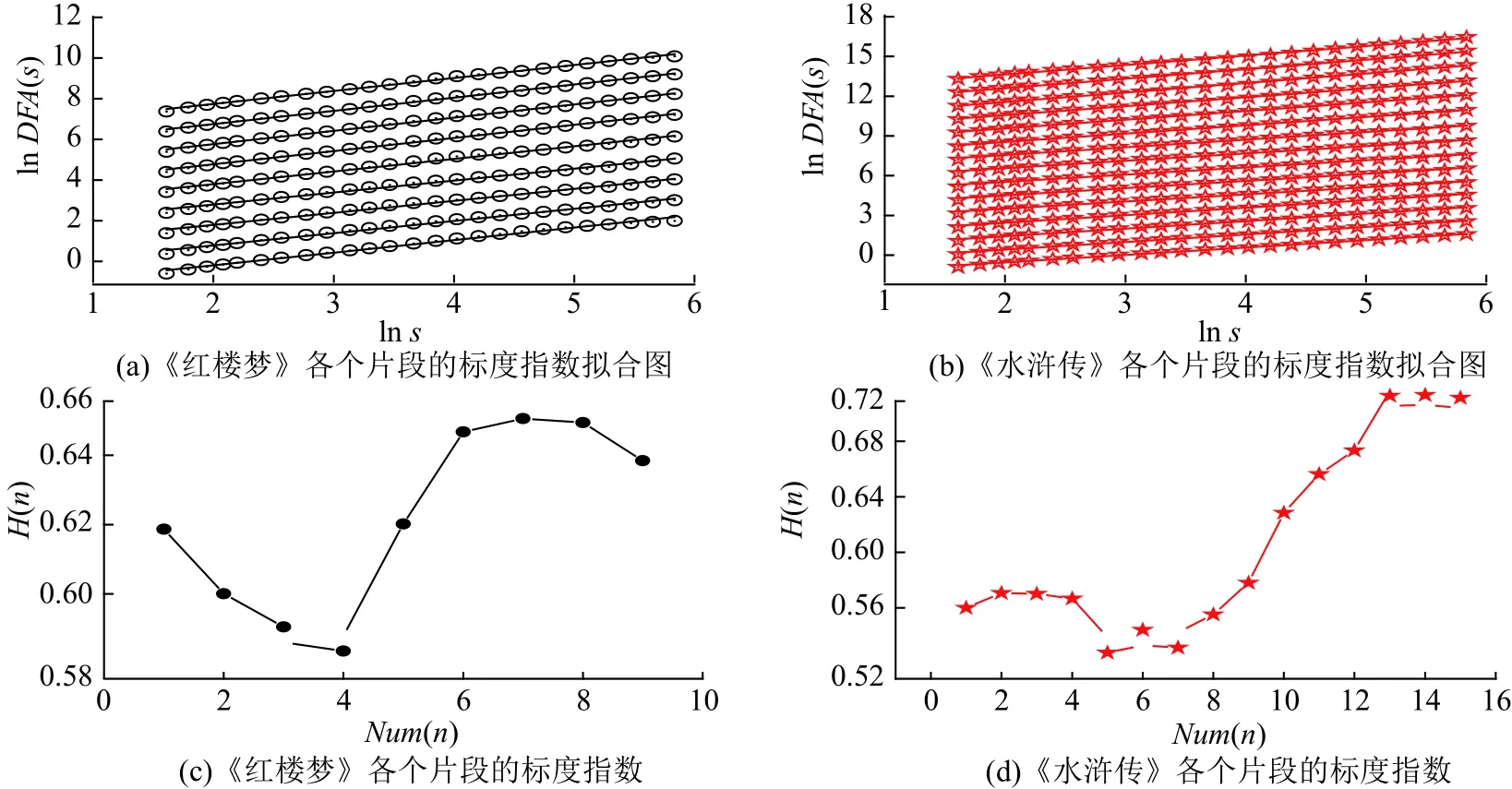
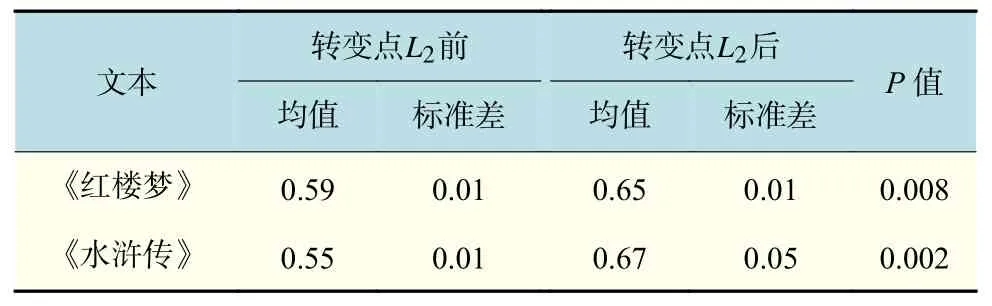
式中,H为标度指数(scaling exponent)。若H=0.5,则表明时间序列可用随机游走过程来描述;若0.5 计算过程中,多项式拟合函数中的阶数q取2,即用最小二乘法拟合序列片段趋势。用q值取2的多项式对序列片段进行拟合,使得每个标度范围内的数据点数目几乎相同,提高了结果的准确性[19]。 对四大名著每段句子数时间序列、每段字数时间序列、每句字数时间序列运用去趋势波动分析法分析,结果如图2所示。其中:lns为对盒子大小取对数值;lnDFA(s)为对涨落的大小取对数值。 每段句子数时间序列和每段字数时间序列的标度指数H几乎相同,且接近于0.60。每句字数时间序列的标度指数H则偏小,但其标度指数H值也接近于0.60。这说明中国四大名著小说无论在段落层次还是语句层次上均具有长程相关性,且标度指数H与Holy Bible[22]在单词长度层次得到的标度指数H几乎相同。这也进一步表明在中文小说文本中,其语言内部无论是段落层次还是语句层次均存在固有的无标度规律。 为了更加细致地研究上述时间序列,对以上时间序列设置滑动窗口S,把时间序列划分成相应的时序片段,分别对每一个时序片段采用去趋势波动分析法分析。每段句子数时间序列和每段字数时间序列的序列长为 103,且滑动窗口长度S=1 000,每句字数时间序列的序列长为1 04,且滑动窗口S取10 000。在每段字数时间序列结果中,《红楼梦》和《水浒传》两本小说前后部分存在着标度指数的明显变化,结果如图3所示。图3 中(e),(f),(g),(h)分别为《红楼梦》、《三国演义》、《水浒传》、《西游记》在各个时序片段上的拟合图。其中:Num(n)表示滑动窗口的数目;H(n)表示对应滑动窗口的标度指数。 图2 四大名著在各个层次的标度律Fig.2 Scaling behaviors of Four Great Classical Novels across all levels 从图3可以看出,《红楼梦》和《水浒传》的标度指数变化相对明显,其变化区间分别为[0.55,0.65]和[0.52,0.71],且《红楼梦》和《水浒传》存在标度指数转变点。《红楼梦》的标度指数转变点在第72章节,且转变点前或后标度指数相对稳定。《水浒传》的标度指数转变点L1在第67章节,其转变点之前的标度指数呈递减趋势,转变点之后的标度指数呈递增趋势。《三国演义》和《西游记》的标度指数则无明显变化,其浮动区间分别为[0.57,0.60]和[0.56,0.59]。分别对《红楼梦》和《水浒传》转变点前后的标度指数做双样本t检验(two-samplettest),检验结果如表 2 所示。 图3 使用去趋势波动分析法分析每段字数时序片段的结果Fig.3 DFA results of the time series’ segments for the number of characters in a paragraph 对于《红楼梦》和《水浒传》,其标度指数转变点前后差异显著(P<0.001)。事实上,对于《红楼梦》一书作者的争议一直存在,当下大众比较认可的一种说法是《红楼梦》由曹雪芹和高鹗两人前后历经十几年时间创作完成,其中曹雪芹创作了前80章节,后40章节由高鹗在曹雪芹的思想影响下续写完成[23]。而对于《水浒传》一书的作者也存在很大争议,普遍认为《水浒传》一书是由施耐庵一人完成[24-26]。但也有人指出《水浒传》是由施耐庵和罗贯中共同完成的,即“施耐庵的本,罗贯中编次”[27-29]。本文从数理统计的角度分析,发现了《红楼梦》和《水浒传》书中每段字数时间序列存在标度指数的转变,且转变点前后标度指数显著变化。为了验证上述发现,本文从每段所含信息量的角度作了以下工作加以分析。 表2 转变点 L1前后双样本t检验结果Tab.2 Results of two-sample t test for the data before and after separation points L1 令{Xi},i=1,2,···,Nv,表示每段字数时间序列;{Yi},i=1,2,···,Nv,表示每段句子数时间序列; {Zi},i=1,2,···,Nw,表示每句字数时间序列。其中,Nv表示段落数,Nw表示句子数。则有: 将每句字数时间序列 {Zi}均分成Nv段,每一段含有wv个元素,对每个片段运用香农熵(Shannon entropy)[30-32]: 由式(5),每一个片段会得到对应的H(i)的值。在此将H(i)定义为每一段所包含的信息量,对每段信息量时间序列作去趋势波动分析,其结果如图4所示。 图4给出了四大名著每段信息量时间序列的标度行为,《红楼梦》、《三国演义》、《水浒传》、《西游记》的标度指数分别为0.62,0.62,0.65,0.59。由此可得,每段信息量时间序列的标度指数和每段字数时间序列的标度指数几乎相同。 为了理解《红楼梦》和《水浒传》两本小说存在转变点的现象,对每段信息量时间序列划分时序片段,其序列长为1 03,且滑动窗口S取1 000。同样对每个时序片段运用去趋势波动分析法分析,结果如图5所示。 由图5可知,《红楼梦》和《水浒传》的信息量时间序列也存在标度指数分段现象,《红楼梦》的每段信息量时间序列标度指数的转变点L2与每段字数时间序列的标度指数转变点L1一致,均在第72章节。《水浒传》的每段信息量时间序列标度指数的转变点L2在第62章节。对《红楼梦》和《水浒传》每段信息量转变点前后进行差异性检验,表3列出了双样本t检验(two-samplettest)的检验结果。 表3 转变点 L2前后双样本t检验结果Tab.3 Results of two-sample t test for the data before and after separation pointsL2 表2和表3结果表明,《红楼梦》和《水浒传》无论在每段字数时间序列,还是在每段所含信息量时间序列上,均存在标度指数的转变现象,且转变点前后的标度指数差异性显著(P<0.008)。 前人在英文版的Holy Bible[22]中,使用去趋势波动分析研究了由单词长度构成的时间序列,发现了标度指数接近为0.6的无标度规律。本文在更高的层次即在段落层次和语句层次上使用去趋势波动分析我国的四大名著文本,即分析每一名著的每段句子数时间序列、每段字数时间序列和每句字数时间序列。研究发现,中国四大名著在各个层次上存在标度律,且每个层次上的标度指数也都接近于0.60。这说明中文小说文本在各个层次上均满足固有的无标度规律,且具有相似的长程相关性,各个层次相似的无标度规律表明中文文本从微观层次到宏观层次具有相似的长程关联性,为重构语言形成与发展的理论模型提供帮助。 此外,本文还佐证了《红楼梦》的作者为曹雪芹和高鹗两人的说法,并支持《水浒传》一书有很大可能是施耐庵与罗贯中合作完成的观点。用去趋势波动分析法对每段字数时间序列的时序片段以及每段信息量时间序列的时序片段分析,得出了《红楼梦》和《水浒传》这两本小说在段落字数以及段落信息量上存在着标度指数的前后显著差别。《红楼梦》的标度指数转变点为第72章节,即其前72章节和后48章节在段落结构和段落信息量上存在着前后变化,该转变点现象与学者们认为的《红楼梦》前80章由曹雪芹创作、后40章由高鹗完成的说法相接近。不同的标度指数表征不同作者的写作习惯以及表达方式,在一定程度上标度指数可以作为区分不同作者的依据[20]。而对于《水浒传》,其标度指数也存在转变点现象,约为第70章节,从而支持了《水浒传》一书有很大可能是两人共同编写的结论,与当下许多学者认为的《水浒传》是“施耐庵的本,罗贯中编次”的说法不谋而合[27-29]。4 无标度规律分析结果
4.1 无标度规律分析
4.2 时序片段的分析



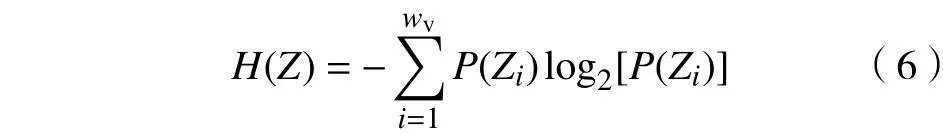

5 结 论
