基于Seq2Seq框架和领域知识图谱的新闻简报生成
2019-03-26蔡东风
符 悦,白 宇,蔡东风
(沈阳航空航天大学 人机智能研究中心,沈阳 110136)
伴随着大数据时代的到来,新闻文本呈现爆炸式的增长,在给人们带来海量数据便利的同时,也带来了信息过载的困扰。如何从大量的新闻文本中提取出重要的内容,已经成为一个亟待解决的问题,新闻简报可以帮助人们在短时间内了解大量新闻内容,有效解决信息过载的问题。对于新闻简报生成,形式化定义[1]如式(1)所示。
NS=φ(Q)
(1)
其中Q表示某个领域下的多篇文档集合,集合Q经过φ方法的变换,得到新闻简报集合NS。多文档摘要(Multi-document summarization)技术[2]的出现为简报生成问题提供了一个高效的解决方案。它利用计算机将同一主题下的多篇文档描述的主要内容通过信息压缩技术提炼为一个文本的自然语言处理技术[3],目的是通过对原文本进行压缩、提炼,为用户提供简明扼要的文字描述。
尽管当前众多的新闻网站已经纷纷推出每日的新闻简报,以供用户参考阅读,但是截止目前,绝大多数的新闻简报内容来自文中的一句话或标题。这种情况容易使句子出现较多冗余的信息,如何能根据新闻自动生成新闻简报,成为近年来NLP领域的研究热点之一,同时也具有相当大的挑战,其主要表现在以下两个方面。
第一,每篇新闻报道往往都是围绕一个主题展开叙述新闻内容,在叙述的过程中,往往会出现很多的噪声。因此,如何从新闻文本中生成“好”的新闻主题句将是需要解决的关键问题之一。
第二,现有的基于多文档文摘技术的新闻简报自动生成研究多数仅限于考虑句子与句子之间的两两关系来对句子打分,进而通过句子排序罗列形成简报,这忽略了文本中句子与句子之间在主题层面的逻辑关系[4],使得新闻简报缺乏可读性,用户阅读体验欠佳。
本文提出了一种基于神经网络Seq2Seq框架和领域知识图谱结合的方法来生成新闻简报,该方法主要用来解决以上出现的两个问题,使用Seq2Seq的框架来自动生成新闻主题句,使主题句更加简练易懂。同时考虑到新闻简报主题的相关性和简报之间的连贯性,引入领域知识图谱,利用图谱的逻辑结构,对主题句进行合理的组织,生成新闻简报。然后对于主题句生成结果采用Rouge的评价方法,在新闻简报生成结果中,则采用自动评价方法和人工评价的方法来评价新闻简报的质量。
1 相关研究
本研究涉及的任务与多自动文摘密切相关,多自动文摘是自然语言处理中一个传统的研究领域,其应用对象主要集中于新闻和社交媒体[5]。目前多文档文摘技术主要分为两种,一种是抽取式摘要的生成,另外一种是生成式摘要的生成[6]。
抽取式摘要的一种思路是将原文的句子进行切分、打分、排序,最后选择排序靠前的句子作为最终的摘要结果。基于图模型的研究方法有pageRank[7]和textrank[8],该方法主要是把文本集中的所有句子当成一个节点构建一个拓扑结构图,然后对图中的节点进行迭代得到相应的打分值,最后排序压缩得到最后的摘要。基于无监督的方法,其中较为典型的是David M.Blei 等人提出的LDA模型[9],应用在多文档文摘中,通过分析原文中的词来发现蕴藏在其中的信息。基于聚类的摘要生成方法是首先对文章中的句子聚类,将相似的句子聚到同一类中,每一类代表不同的子主题,然后再将某一类中的句子排序,最后生成摘要[10]。基于有监督的生成方法主要是将摘要生成问题转变成序列标注和句子分类等问题来进行求解,比如支持向量机[11]、数学回归等。这些有监督的方法融入很多先验知识,会比传统的无监督的方法好一些,但是可移植性相对较差。基于统计的方法,则是利用词频、句子长度、句子位置等相关的特征来抽取重要的句子。巴尔宾等人开发的TextTeaser[12]就是一个典型的基于统计方法的抽取式多文档文摘。
生成式摘要是指通过理解文章的内容大意,将那些视为重要的信息进行抽取,同时抽象释义出源文档的内容。这种方法更接近摘要的本质,更类似于人工提炼的摘要结果[13]。生成式神经网络模型采用Seq2Seq框架,基本结构主要由编码器和解码器组成,由Google Brain团队[14]和Yoshua Bengio团队[15]提出,输入是一个序列,输出也是一个序列,最早应用于机器翻译领域,后来应用于自然语言处理、声音、图片,乃至视频数据等领域。例如:使用卷积神经网络来生成摘要,条件是卷积注意力机制,用来确保每一步生成的词聚焦核心词上,模型依赖大规模的语料来学习特征实现端到端的训练[16],然而这些使用神经网络的方法在单文档摘要生成过程中取得了不错的效果。但是,由于缺乏大规模的多文档摘要语料,这些方法很难适用到多文档摘要中[17],而且相对来说,目前技术难度较大,效果欠佳。
引入知识图谱的新闻简报的生成方法是对传统多文档摘要的延伸。自从2012年谷歌提出知识图谱的概念[18],利用知识图谱来描述现实世界中存在的实体或者概念及其关系。它构成一张巨大的语义网络图,节点表示实体或者概念,边则由属性或者关系构成。依赖于知识图谱强大的语义处理能力和开放的组织能力,能够有效地将互联网中结构松散的数据组织起来。李阳等[19]提出一种用于计算知识图谱中实体相似度通用的方法,能处理实体各种类型的属性值,从而提高本文分类的准确率。Karidi D P等[20]利用现有的知识图谱构建主题图,通过主题图计算用户兴趣爱好的相似度,进而为用户推送更多信息。
基于前人的研究成果,本文利用Seq2Seq框架生成新闻主题句,然后依据知识图谱的逻辑结构建立主题句与知识图谱之间的映射关系。然后根据知识图谱将信息进行合理的组织,最终形成新闻简报。
2 新闻简报模型
在本文中,我们使用神经网络端到端的框架Seq2Seq来得到新闻的主题句,同时引入知识图谱建立新闻主题句与知识图谱之间的映射关系,将简报生成问题转化为对知识图谱中各个节点下的新闻主题句的组织问题。除此之外,引入时序维度,以某段时间为单位来生成新闻简报,TNS(Timeline news Summaries)根据时间排序的主题句列表组成,其中,新闻简报都由某段时间内描述新闻的主题句集合构成。本文的整体模型框架如图1所示。

图1 模型框架
2.1 主题句生成模型
在文档建模和主题句生成的框架中,我们将x=x1,…xTx作为输入文档,并且把主题句y=y1,…yTx作为输出结果,主题句的生成过程是在给定主题句的情况下,找到最大化的条件概率argmaxyp(y|x),最后输出y*。
首先,在GRU的设置中,从左向右读入文本字符,一个GRU单元通过式(2)学习得到在i时刻的隐藏状态hi。
hi=GRU(hi-1,e(xi))
(2)
其中,hi∈Rn,它将i时刻的所有文本进行编码,hi通过hi-1和e(xi) 计算得到,其中e(xi)∈Rm是当前的字xi的m维向量,GRU内部计算方法如式(3)~(6)所示。
(3)
(4)
ri=sigmoid(Wre(xi)+Urhi-1)
(5)
ui=sigmoid(Wue(xi)+Uuhi-1)
(6)
其中Wr,Wu,W∈Rn*m,Ur,Uu,U∈Rn*n是权重矩阵,n是隐藏单元个数,Θ 表示矩阵相乘。
我们使用BiGRU,正序和逆序组合构造一个双层模型,每一层都是一个单向传递的结构,正序和逆序组合的GRU模型如图2所示。
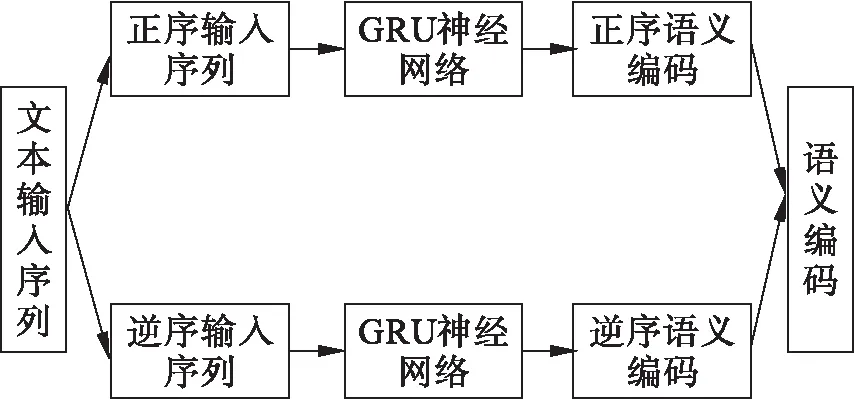
图2 正序和逆序组合的GRU模型
通过将正序输入序列和逆序输入序列输入到正逆序组合的GRU模型中,分别得到正序语义编码和逆序语义编码,其中语义编码中包含输出的注意力概率分布信息,然后将正序和逆序的编码组合在一起,作为最后的语义编码c,每次的隐藏状态都依赖于前一次的语义编码的隐藏状态,通过循环迭代直到遇到结束的标识符时最后一次编码完成。
当在生成主题句时,解码器根据在编码器中获得的语义编码c,以及前一次输出序列y1,…yt-1来预测当前的yt。条件概率的计算公式如式(7)和(8)所示。

(7)
(8)
在公式(7)中,y*是通过这个模型所找到的最佳主题句的结果。把这个条件概率进一步重写得到式(8),计算输出时间t时刻的所有合理的输出词的概率,其中t时刻的语义编码ci是输入序列和隐状态h1,h2…hT的加权求和,公式如式(9)所示。
(9)
其中αi,j是注意力权重参数,并不是一个固定的权重,它是由另一个神经网络计算得到的,如式(11)所示。
(10)
eij=a(si-1,hj)
(11)
神经网络a将上一个输出序列的隐状态si-1和输入序列的隐状态hj作为输入,计算出xj,yi的对齐值eij,对齐越好的词权重越大,对生成当前的输出词的影响也会越大,然后再归一化得到权重αi,j,Seq2Seq模型如图3所示。

图3 主题句生成模型
2.2 主题句与知识图谱的映射模型
该方法是将知识图谱与每篇文本中主题关键词的映射问题转化为图排序问题,每篇文本中的主题关键词意味着重点、中心思想等等。在本文中,利用主题词集T对知识图谱节点进行打分,得到每个图谱节点的得分值,然后按分数排名。将分数最高的图谱节点输出,作为主题词集的类别,也就是文本映射到图谱上的结果。对主题词集与图谱的节点间构建图模型的步骤如下。
步骤1:基于textrank算法,得到文档中的关键词以及关键词的权重,构成主题词集T=[(s1,w1),(s2,w2),…,(sn,wn)]。
步骤2:构建主题词集与图谱节点之间的有向图G=(T,V,M),其中,T是主题词集,集合V是知识图谱中节点集合,M是边的集合。对于一个给定的图谱的顶点Vi,计算该顶点所得到的“打分值”,如式(12)所示。
(12)
式中,等式左边是表示图谱节点Vi的得分ws,wj表示在主题词集{T}中每个主题词对应的权重,mij表示图谱节点vj与主题词ti之间边的权重。
该算法应用在主题与知识图谱映射问题上,核心思想在于“打分”,将图中的主题词集{T}中的词与图谱中节点集合{V}计算相似度,相似度的计算公式为
(13)
该相似度是主题词集{T}和图谱中节点的一条边,也就是主题词集{T}对图谱节点的打分值,在主题词集中,图谱{V}中某个节点得分越高,说明该文章的主题与这个节点越相关,然后将主题词集映射到得分值最高的图谱的节点上。这里给出主题词集{T}与图谱节点集合{V}的映射图模型,如图4所示。

图4 知识图谱与主题句的映射模型
2.3 新闻简报生成
本文基于知识图谱之间强大的语义处理能力和开放的组织能力,将原本松散的新闻数据组织起来。通过将主题词和知识图谱之间的映射,得到每篇新闻与图谱之间的关系,将简报生成的问题转化为组织知识图谱中各个节点下的新闻主题句的问题。图5为图谱与新闻主题之间的映射关系图。

图5 新闻简报生成模型
从图中可以看出,该知识图谱由V={V0,r1,r2,a1,a2,a3,a4}构成,在知识图谱V中,v0是根节点,也是整个图谱的核心,离根节点越近的主题事件和图谱的关系越紧密,图的右侧为图谱中每个实例对应的主题句,如何组织右侧的句子,采用的策略如下。
(1)若某个图谱节点下包含事件最多,说明该节点下的事件是某段时间内相对重要的事情,则优先考虑输出该节点下的事件,而该节点下事件输出顺序依赖于主题句映射在该节点上的对应的打分值,分数越高该主题句与该节点越相关。按照打分值从高到低依次将该节点下的主题句输出。
(2)若图谱的节点下包含的事件同样多,则依据深度优先遍历算法遍历该图谱,依次输出各个图谱节点下的主题事件。
因此,主题句输出的最终顺序为{s6,s2,s1,s4,s3,s5}。
除此之外,从新闻简报呈现的形式中可以观察到,新闻简报主要包括时间、主题、发生事件等方面的内容。根据这些条件,我们基于知识图谱来构建新闻简报的模板,模板由时间、主题、新闻内容三部分构成,使生成的简报更连贯,更具有结构化。例如:从图5的映射关系中可以看出,图谱的根节点为“人才培养”。因此,该图谱下的主题句主要围绕“人才培养”来进行阐述,最后得到的新闻简报如表1所示。

表1 新闻简报
3 实验与评估
3.1 数据集
本文在训练主题句模型的过程中选择公开的中文语料库(LCSTS),这个数据集是由Hu.等人[21]构建,包含超过两百万篇语料,该数据来自中国有名的社会媒体网站新浪微博。这些数据被分成了三部分,第一部分包含2 400 591篇语料,第二部分包含10 666篇语料,第三部分包括1 106篇语料。其中,第一部分作为训练集,第二部分作为开发集,第三部分作为测试集。这些语料中文本长度为100~150个字,主题句长度为20~30个字。在测试的过程中,除了选择公开的测试集,还在军民融合官网中爬取了1667篇新闻作为测试语料。为保持测试语料长度的一致性,选择该新闻的前两句作为文本,标题作为主题句答案进行测试。
同时,在新闻简报生成过程中选用军民融合领域知识图谱,该图谱是根据军民融合领域语料中包含的内容人工梳理构建完成,主要涉及交通运输、信息、科技协同、人才培养、安全领域、社会保障、国防科工等方面。部分图谱如图6所示。
3.2 实验设置
在主题句的生成过程中,通过不断调整参数优化模型发现设置批量为256时效果最佳,同时采用字模型,词典设置为4000,嵌入的维度为500,隐藏层的节点数为500,光束搜索大小为5,使用自适应学习率( Adadelta)来学习模型参数。
在新闻简报生成的过程中,用到的语料是军民融合领域的1667篇新闻,先通过textrank工具抽取出每篇新闻中的20个关键词,然后将知识图谱的节点和文章中的关键词通过Word2vec训练出词汇相似度矩阵模型,依据主题句与知识图谱之间的映射模型,使主题句映射到知识图谱的节点上,进而得到每篇新闻主题句与图谱之间的关系,于是,将简报生成的问题转化为把知识图谱中各个节点下的新闻主题句组织的问题。依据新闻语料中的时间数据作为时序维度,以“天”为单位生成每日的新闻简报。

图6 军民融合领域部分知识图谱
3.3 实验评估
在实验评估中,我们选择自动评价方法和人工评价方法。自动评价方法中,我们的评估指标选择ROUGE[22]得分,这种评估方法在摘要评估中很受欢迎,通过计算重叠词汇单位(包括unigram,bigram,trigram和最长公共子序列(LCS))来比较自动生成的摘要和参考摘要。该种方法同样可以用于主题句生成的结果评估中,采用ROUGE-1(unigram),ROUGE-2(bi-gram)和ROUGE-L(LCS)来评估本文的实验结果。
对于新闻简报生成的结果,我们采取自动评价方法和人工评价方法来评估生成的新闻简报的语言质量,并且和其他的方法对比。在采用人工评价方法时,我们随机从新闻简报中抽出100篇进行人工评价,要求十名志愿者从连贯性、非冗余性和可读性三个方面进行人工评价。评级的格式为1-5个数字分数(不一定是整数),其中较高的分数表示级别较高的等级。连贯性是指语句前后衔接是否恰当,非冗余性是指语句中不存在重复和多余的信息。可读性是指语句便于阅读,吸引读者的特性。
3.4 基础方法
LexRank[23]基于句子图形表示中的特征向量中心性的概念来计算句子重要性。在该模型中,基于句子内余弦相似度的连通矩阵被用作句子图形表示的邻接矩阵。
TextRank(Mihalcea和Tarau,2004)构建图形并将每个句子添加为顶点,两个句子的重叠被视为连接句子的关系。 然后应用基于图形的排序算法直到收敛。 句子根据其最终得分进行排序,并使用贪婪算法对每个句子施加多样性惩罚并选择摘要句子。
SumBasic[24]提出了用一个句子中所有词在文本集中出现的概率之和来表示句子重要程度的方法,然后选择最重要的句子组成摘要。
Luhn[25]提出了“词频”的方法,通过计算文章中“keywords”的出现频率来找到文章的中心句子以此来生成文本摘要。
RNN和RNN-cont是具有RNN编码器和解码器的两个序列到序列的基本模型,由Hu等人提出。区别在于RNN-cont具有注意力机制而RNN没有注意力机制。
3.5 结果与讨论
(1)主题句生成模型
在主题句模型训练的实验结果中,对比了我们的模型和以上的其他基础方法,实验结果如表2所示。

表2 在LCSTS语料上实验对比结果
从表中可以看出,BiGRU方法优于其他方法,主要由于BiGRU在预测语句中缺失的单词的时候考虑了上下文的信息,因此输入到网络中的信息也更加全面,防止了前后信息的丢失。该方法对比前四个抽取式的摘要生成方法,也有较大的提升,抽取式的摘要方法主要缺点在于抽出的是一句话或者几句话,而且这些语句中包含的信息并不全面,冗余信息也相对较多。在本文的实验中,LCTST数据集的文本长度相对较短,语言较为精炼,所以抽出的主题句并不理想。因此,我们采用BiGRU模型来生成主题句。
接下来,我们将训练好的主题句生成模型应用到军民融合领域的新闻语料中来生成主题句。实验结果如表3所示。

表3 军民融合语料上的实验结果
从表中可以看出,BiGRU模型应用在军民融合领域的新闻语料中得到的效果比在LCSTS语料上的效果更好。两种语料实验结果对比如表4所示。

表4 对比两种语料的实验结果
对比两种语料可以发现,LCSTS语料中的重要信息相对分散,而在军民融合的语料中的重要信息相对集中,多数重要信息连接在一起。因此,在通过使用神经网络模型BiGRU得到的结果也相对较好,在自动评价的结果中,得到的结果也优于在LCSTS语料中得到的结果。
(2)新闻简报生成模型
结合军民融合领域的知识图谱得到328篇新闻简报,我们先采用自动评价的方法得到如表5所示的结果。
从该表中可以看出,采用BiGRU+KG的方法得到的效果更好一些,主要是因为在使用BiGRU方法生成主题句的时候,效果优于其他的方法。因此在通过知识图谱对主题句进行组织时,效果同样优于其他的方法。

表5 对新闻简报自动评价实验结果
由于ROUGE自动评价的方法并不考虑文章句子间前后的顺序关系,因此对于本文中基于知识图谱将主题句进行组织的结果合理性问题,我们采用了人工评价的方法,对比其他方法结果如表6所示。
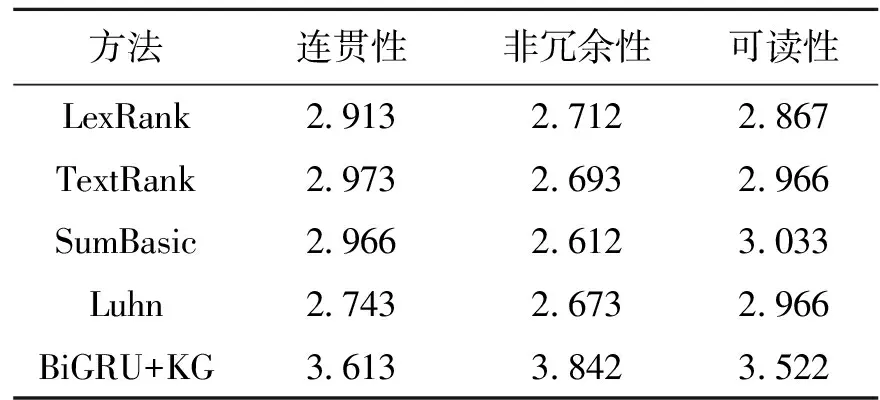
表6 对新闻简报进行人工评价结果
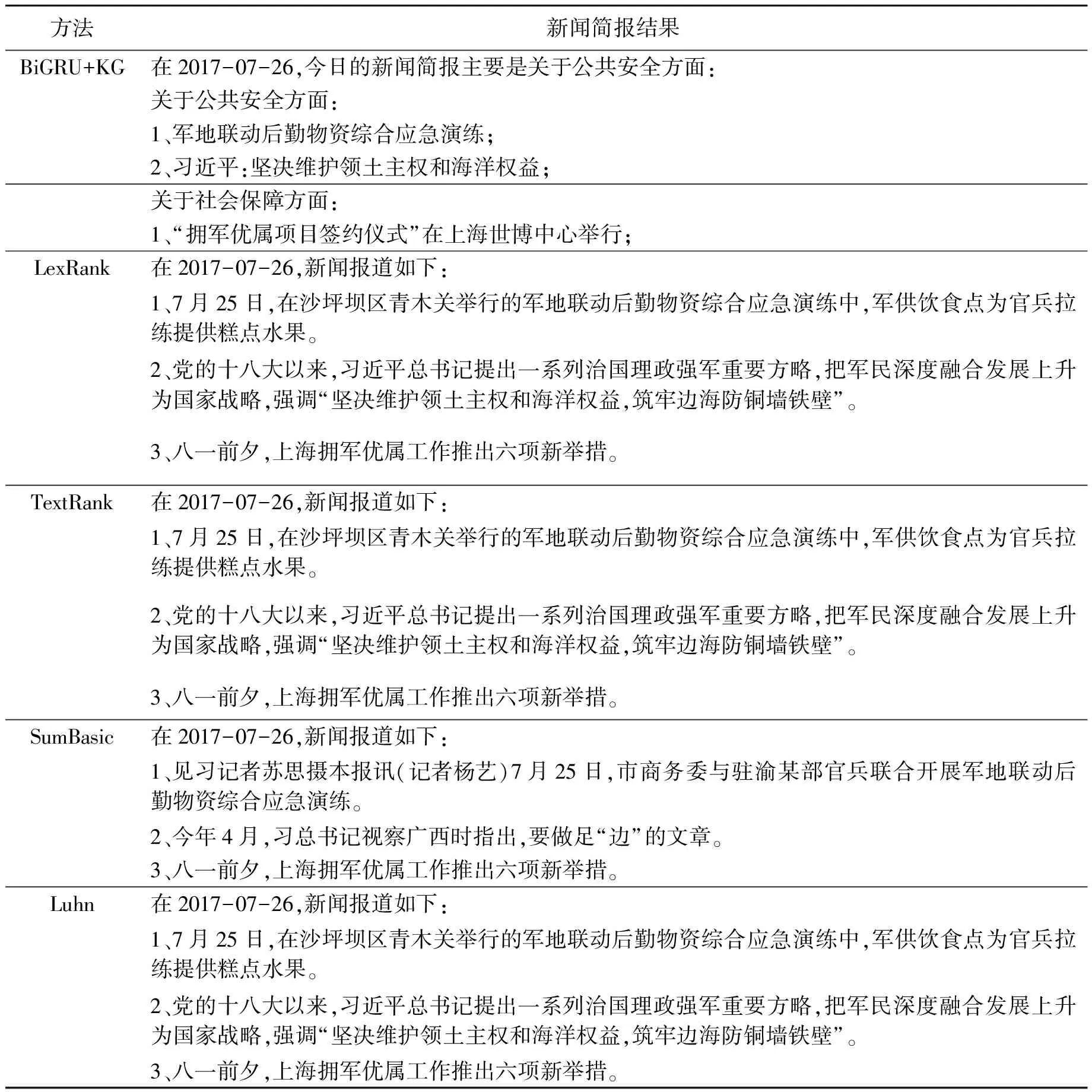
表7 新闻简报结果
从表格中可以看出,从人工评价的角度来说,BiGRU+KG的方法略优于其他传统的方法,无论是从连贯性上、非冗余性上、还是从可读性上都得到较好的评价。首先,基于知识图谱得到的新闻简报可以将这一天中发生的相关事情合并在一起进行阐述,可以帮助读者快速了解某一天中主要发生的新闻内容。如表7所示,通过使用BiGRU+KG的方法可以得到这一天的新闻简报中关于公共安全方面共报道了5篇新闻,关于社会保障方面报道了1篇,关于科技协同方面报道了1篇。因此,首先描述公共安全方面的信息,这5篇报道按照知识图谱中的逻辑结构进行输出。这也体现了知识图谱在本文中的重要作用,使新闻简报更具有连贯性和可读性。而其他方法生成的新闻简报皆是将某一天中的主题句罗列在一起所形成的,因此连贯性相对较差,而且句子中包含的多余信息使句子变得冗长而不简洁。因此,BiGRU+KG的方法有效提高了新闻简报的非冗余性、连贯性以及可读性。
4 结论
本文研究如何从多篇新闻中自动生成新闻简报,我们将该问题分解成两个任务来进行。第一个任务是通过使用神经网络Seq2Seq的框架自动生成新闻主题句,从而解决主题句生成的结果中包含大量噪声的问题。从实验结果来看,使用Seq2Seq框架在生成新闻主题句时取得了较好的结果。第二个任务是基于领域知识图谱的方法生成新闻简报,通过知识图谱使主题句之间更具有逻辑性,然后通过知识图谱将新闻主题句进行合理的组织。这种方法不仅在自动评价中取得了不错的效果,而且在人工评价中也得到3.5以上的得分。从而证明基于Seq2Seq框架和领域知识图谱的方法生成新闻简报可以提高新闻简报生成结果的可读性、连贯性以及非冗余性。
在未来的工作中,我们将尝试采用不同的神经网络模型融入到Seq2Seq的框架中,并且尝试在神经网络中加入主题词等相关知识来提高新闻主题句的生成效果。
