机器学习算法在医疗领域中的应用
2019-03-21蔡宏伟郭佑民侯梦薇
兰 欣,卫 荣*,蔡宏伟,郭佑民,侯梦薇,邢 磊,那 天,陆 亮
(1.西安交通大学第一附属医院网络信息部,西安 710061;2.西安交通大学第一附属医院影像科,西安 710061)
0 引言
随着计算机技术、信息技术和互联网技术的迅速发展,社会各个领域积累了海量的数据。如何在这些海量数据里挖掘出有用的信息是目前各行各业所面临的问题。机器学习作为解决数据挖掘问题的主要方法之一,在许多领域得到广泛应用,尤其是在医疗领域[1]。本文现对机器学习的定义、分类、经典算法等相关概念及其在医疗领域中的应用作一综述。
1 机器学习的定义及分类
1.1 定义
机器学习是一种能自动构建出模型用来处理一些复杂关系的技术,它使用计算机模拟人类学习行为,通过学习现有知识,获取新经验与新知识,不断改善性能并实现自身完善[2]。
1.2 分类
机器学习一般根据处理的数据是否需要人为标记分为监督学习、半监督学习和无监督学习3类。
监督学习是用具有分类标签的数据作为学习目标,其针对每个要学习的样本都由学习输入和学习目标组成。机器学习算法通过已经打标签的数据进行模型训练,并将训练好的模型用来预测新数据的结果。因此,监督学习的最终目标是训练机器学习的泛化能力。
无监督学习是用于处理不具有分类标签的数据,不需要提前进行训练,而是希望通过机器学习算法寻求数据间的内在模式和规律,从而发现样本数据潜在的结构特征。因此,无监督学习的最终目标是在学习过程中根据相似性原理对数据进行区分。
在实际应用中,只有少量的带有标记的数据。因为有时对数据进行标记的代价会很高,如基因序列比对、蛋白质功能预测等需要使用特殊设备或经过昂贵且用时非常长的实验过程进行人工标记,所以衍生出半监督学习。半监督学习是使用大量的无标签的数据和一小部分有标签数据训练模型,在已标记的类别样本提供的监督信息的“引导”下,学习全部样本或只学习未标记类别样本[3]。
2 机器学习的经典算法
2.1 决策树
决策树是一种类似树形结构的预测模型,其中树的每个分支是一个分类问题,树的叶节点表示对应分类的数据分割。决策树利用信息增益发现数据库中最大信息量的字段作为决策树的一个节点,按照字段取值的不同建立树的分支。对于每个分支再重复建立树的下层节点和分支过程,最终建立完成决策树[4-5]。图1为某实例决策树模型示意图。由于决策树是一种典型的分类算法,因此在疾病的预测、辅助诊断中应用广泛,如用于管理决策协议、创建代谢紊乱的分类模式、获取耳神经病的相关知识、糖尿病的数据挖掘以及区分痴呆严重程度等[6]。
2.2 贝叶斯网络
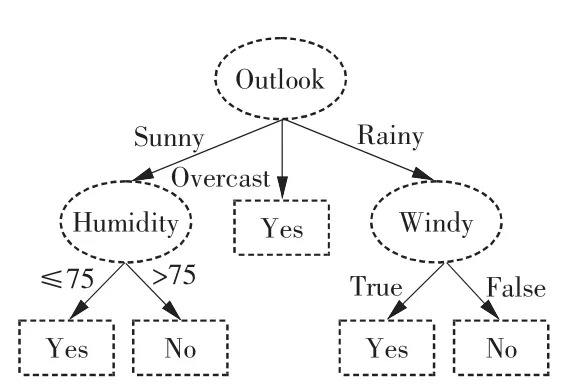
图1 某实例决策树模型示意图
贝叶斯网络是一种基于概率推理的图形化网络。贝叶斯网络实质是有向无环图,其中节点主要代表随机向量。节点与节点之间的关系,代表向量与向量之间的联系。向量之间关系的强度,需采用条件概率标识[7]。贝叶斯网络在很多方面均有应用,包括自然语言理解、故障诊断、计算机视觉、机器人等。在医学领域中的应用主要集中在医疗诊断、治疗规划等方面。
2.3 人工神经网路
人工神经网络是模拟人脑神经元结构进行信息处理的一种数学模型,建立在麦卡洛克-皮茨模型(McCulloch-Pitts model,简称“MP 模型”)和 Hebb学习规则基础上。神经网络中的每个神经元接收大量的输入信号,执行输入的加权和,通过非线性激活函数产生激活响应并对随后连接的神经元传递输出信号[8]。图2为某实例人工神经网络模型示意图。人工神经网络包含前馈式网络、反馈式网络和自组织网络三大类。人工神经网络具有很强的自组织性、鲁棒性和容错性,在疾病的预后评估、早期预防中得到广泛的应用[9]。
2.4 支持向量机
支持向量机的基本思想是在高维空间中寻找一个最优超平面作为二分类问题的分割,这个超平面要保证最小的分类错误率[10]。支持向量机具有强大的数学背景、分析高维复杂数据集的能力和准确的性能。在医疗领域应用中,其可对骨龄估计、跌倒监测、医疗咨询框架以及依据人脑图像进行痴呆症、抑郁症分类的模式识别[11]。

图2 某实例人工神经网络模型示意图
2.5 深度学习
深度学习作为机器学习领域的一个新的研究方向,不需要人工参与设计就能将原始数据通过自动学习过程从一些简单的非线性模型变换为更高层次的抽象表达,再组合多层变换,学习提取出非常复杂的函数特征。这是深度学习与传统的机器学习最主要的区别[12]。图3为某实例具有2个隐层的深度学习模型示意图。在医疗领域中,常用的深度学习算法包括卷积神经网络、深层信念网络、深度神经网络与递归神经网络,主要可以用来进行疾病诊断、药物研发、医学影像的分析等[13]。
3 机器学习在医疗领域中的应用
机器学习在医疗数据中的研究与应用越来越广泛,已取得不少成果,主要集中在疾病的预测、疾病的辅助诊断、疾病的预后评估、新药研发、健康管理、医学图像识别等方面。
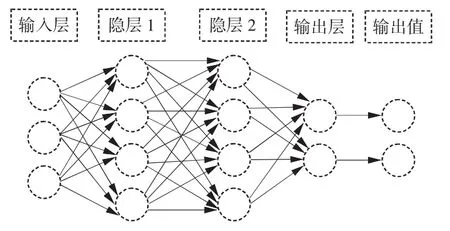
图3 某实例具有2个隐层的深度学习模型示意图
3.1 疾病预测
现代医疗方法都是期望通过早期干预来预防疾病,因为早发现、早治疗是降低大多数疾病治疗成本甚至逆转诊断结果的关键。传统意义上,医生根据人口统计学、现有医疗条件、生活常规等基本信息评估疾病发展的可能性,但是准确率并不高。随着大数据和机器学习技术的发展,疾病的预测变得越来越准确。Hongyoon和Kyong采用那些具有轻度认知障碍、易发展为阿尔茨海默病的患者的脑图像数据作为数据样本,运用卷积神经网络训练模型,预测患者3 a内患上阿尔茨海默病的趋势,其准确度高达84%[14]。诺丁汉大学流行病学家Weng博士团队[15]发现一套评估心血管病风险的机器学习算法,这套评估算法是来自英国家庭的378 256例患者的常规临床数据,该数据应用到基于4种不同机器学习算法:随机森林、逻辑回归、梯度提升和神经网络。预测准确性通过ROC曲线下的AUC面积进行评估,结果显示,这4种机器学习算法在预测心血管疾病方面比美国心脏病学院已建立的、使用近10 a的算法做得更好,其中神经网络技术表现最佳,比已建立的算法正确预测心血管疾病患者达355人[15]。具体每种算法所对应的AUC值如图4所示。用机器学习算法对疾病的预测实质上就是用标示过的数据集进行训练,然后不断对训练的模型进行测试和优化,最后对未知的结果进行预测。机器学习用于分类的方法有很多,包含支持向量机、决策树算法、逻辑回归、集成方法等,其中支持向量机用得最多,它有着极强的稳健性且能对非线性决策边界建模,又有许多可选的核函数,同时还可以有效学习高维数据,这一点是其他算法很难做到的,因此在疾病的预测方面有着广泛的应用。
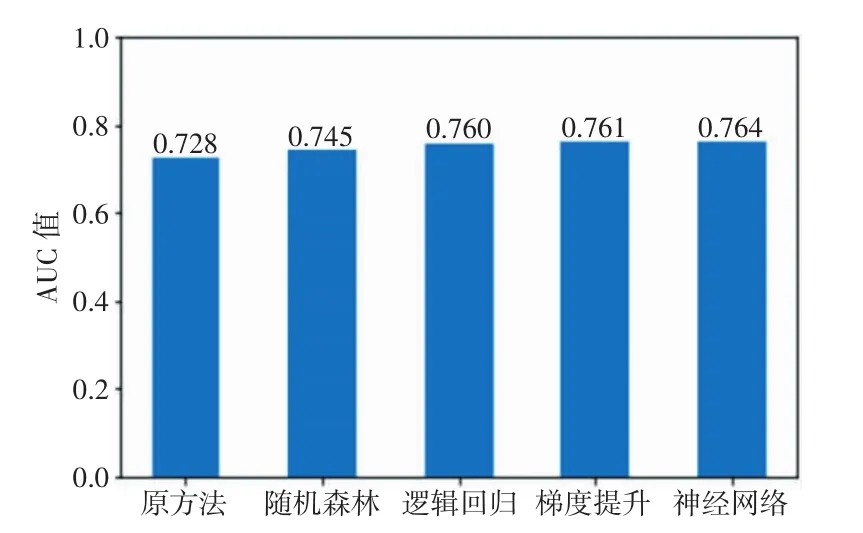
图4 不同算法下的AUC值对比图
3.2 疾病辅助诊断
对患者疾病诊断的过程会产生大量的数据,从医学图像到基因序列,从检验数据到病理数据,这些大量数据如果单靠人力采用常规方法诊断既费时又费人力,同时缺乏质量保证。因此,可以结合机器学习技术提供相应的辅助诊断。Mahesh Kumar等[16]针对228个可视波长眼部图像数据运用序列最小支持向量机优化算法预测眼前节眼部异常,结果显示:准确率为96.96%,灵敏度为97%,特异度为99%[17],比其他的算法构建的分类器性能更好,具体见表1。
Rehme等[17]对人在静息状态下的功能磁共振成像数据运用机器学习算法中的支持向量机算法识别和分类脑卒中后运动功能障碍的内表型。支持向量机算法能够正确诊断中风患者,准确率达到了87.6%[17]。疾病辅助诊断的模型建立核心是分类算法的选取,每一种分类算法各有利弊,其中K-近邻算法简单、易于实现、精度高、对异常值不敏感,同时不需要对参数进行估计,尤其是在多分类问题上的效果比其他机器算法更具优势,能够为医生在疾病诊断中提供高效、高质量的分析判断,提升诊断准确率。
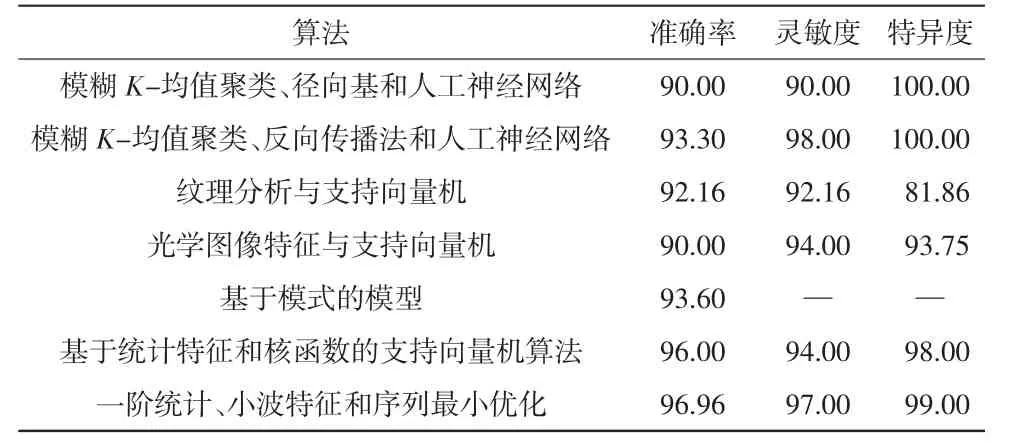
表1 基于一阶统计和小波特征的分类器比较[17]%
3.3 疾病预后评估
疾病的预后评估是对疾病发病后发展为各种不同结局的预测,在临床很有必要。同一种疾病,由于患者的年龄、体质、合并疾病、接受治疗的早晚等诸多不同因素,即使接受了同样的治疗,预后也可能有很大的差别。如果能对不同术后患者的预后作出准确预测,那么就可以对不同的患者有针对性地采用不同的治疗手段,进一步提高患者的生存率。Asadi等[18]对国家神经科学中心22 a间接受血管内治疗脑动脉畸形(brain arteriovenous malformation,BAVM)的患者进行回顾性研究并收集患者的临床表现、影像学、手术细节、并发症等信息建立数据库,然后通过人工神经网络和支持向量机对数据进行分析,预测精度在90%以上,远远高于标准的回归模型43%的预测精度。他们还使用机器学习技术来确定尼尔瘘管的存在与否是影响BAVM血管内栓塞治疗的结果最重要的因素,具体各影响因子重要性如图5所示。Hope等[19]通过高斯过程回归模型研究了MRI图像中的病灶与治疗结果之间的关系,并用该模型预测脑卒中后认知功能障碍的严重程度和随时间的恢复过程。疾病的预后受多种因素所影响,并且各因素之间并非完全独立,针对疾病预后因素的分析和疾病结局的预测,机器学习中的神经网络因其非线性处理的能力,以及其高度的并行性、良好容错性等特点表明它在疾病预后评估方面有良好的应用。
3.4 新药研发
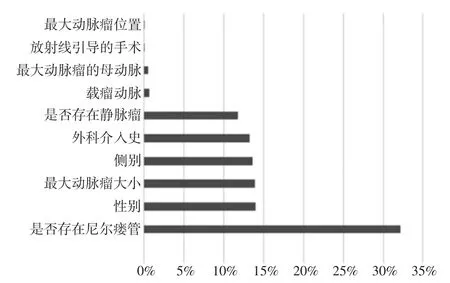
图5 影响BAVM血管内栓塞治疗结果的各因素占比[18]
新药研发是一个极其复杂过程,包括目标识别、设计和制造以及新药物的治疗、药物剂量选择、药物疗效评价和药物不良反应控制。传统方式的药物研发由于资源有限、成本高、持续时间长、命中率低具有一定局限性,机器学习技术在药物学的发展,为药物开发提供了新的思路,并逐渐受到研究者的关注。根据目前的研究,机器学习技术被广泛应用于新药的发现和新的药物靶点的确定、适当治疗和药物剂量的决定、药物疗效、药物之间相互作用的预测。哥伦比亚大学研究组利用机器学习算法研究发现,头孢曲松和兰索拉唑混合使用可导致心律紊乱。而微软公司Hanover利用机器学习预测药物有效性,为患者制订个性化治疗方案[20]。深度学习与传统的人工神经网络相比,其包含多层隐层,能自动学习特征,对数据结构的要求低,同时过滤掉诸多噪声,更加接近人脑的认知模式。因此,深度学习算法的大数据处理能力及强大的特征抽象能力使其在药物研发和药物信息领域具有广泛的应用前景。
3.5 健康管理
目前,在各个医院里都有可穿戴设备和移动医疗设备,这些设备大多只能监测血压和脉搏等简单生命指标,被动地提醒患者何时吃药,但无法主动监测和记录患者行为、环境因素并给出预防措施和建议[21]。将这些设备采集的数据与机器学习技术相结合,能够提供个性化的健康预警与建议,监控个体行为,实现健康管理的目标。加州大学旧金山分校采用半监督机器学习技术,利用33 628人周的健康传感器数据训练深度神经网络(DeepHeart)[21]。他们后来对照12 790人周的单独数据集验证了DeepHeart的准确性,成功率达85%。
3.6 医学图像识别
医学图像识别指利用数学方法和计算机对医学图像进行处理、分析的技术,一般分为输入待识别图像、输入图像预处理、图像特征提取、辨别分类、输出分类结果5个步骤。医学图像识别可以在减轻医师工作量的基础上,提高识别的准确率,降低医疗成本,节省医疗资源,目前在肺结节、脑部、心脏、眼部视网膜等领域有良好的发展前景。例如:David等[22]提出开发一套能够利用图像处理技术对糖尿病视网膜病变重要特征进行视网膜图像分析以及基于人工神经网络的图像分类器自动系统,根据疾病情况对图像进行分类,结果血管网、视神经盘和病变样渗出物被识别出,如图6~8所示。针对医学图像的特征,基于传统的机器学习算法如神经网络、支持向量机、粗糙集、模糊理论的图像识别能达到一定精度,但是各方法均有一定局限性。传统的机器学习算法需要人工选取特征,这些会受到片面或者主观方面的影响,导致特征提取方法在内容表达上不够好,识别率低。近年来,深度学习的出现让识别从人为设定变为自学习状态,特别是以卷积神经网络为代表的模型逐渐变成了医学识别领域的发展方向和强有力的工具。
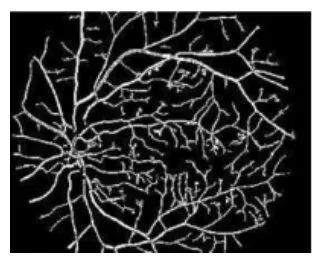
图6 识别出的血管网[22]

图7 识别出的视神经盘[22]
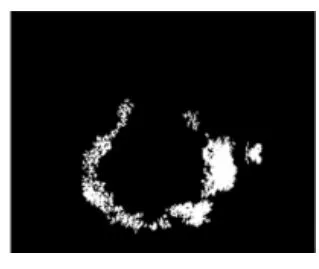
图8 识别出的病变样渗出物[22]
4 结语
现代科技日新月异,机器学习技术为医疗领域提供了新方法,通过计算机的运算能力,对大量的医疗数据在相对短的时间内进行数据分析、建模和训练,探究各种医学指标之间的关系,通过训练后的模型来预测并辅助诊断疾病,提升诊断准确率,同时也可扩展应用于医药及健康管理领域,进一步提升整体医疗行业的发展。目前在医疗领域,如疾病预测、疾病辅助诊断、疾病的预后评估、新药研发、健康管理等,大多数研究者会使用支持向量机、人工神经网络、决策树等传统的机器学习算法,这些算法其实都是对数据间的相似度进行衡量;监督学习是通过同类别样本间的相似性对模型的参数进行学习,非监督学习是通过样本间的相似性实现同类聚集、异类分散。故对于样本间相似性的研究是一个重要方向,也是未来人工智能辅助诊疗的核心技术之一。基于医疗数据的相似度计算,目前可以拓展多种实际的应用,以下为其中的两大应用发展趋势:
(1)基于病案的推理。这是一个解决实际问题的范例方法,基于过往经历过的病案及期间获得的知识来为新的医疗问题提供解决方法。此类技术已经被广泛运用于各种医疗场景中解决实际问题,利用已有的知识解决新的问题。Gottlieb等[23]提出利用患者之间在多个维度方面的相似性来预测最终的出院诊断,使用人口统计学、初始血液、心电图测量以及医学史等多方面在2个独立医院的住院患者中寻找相似性取得很高的精度。该方法在传染病、寄生虫病、内分泌、代谢疾病以及循环系统疾病在内的主要疾病类别提供了精确的预测(ROC曲线面积>0.86的交叉验证精度)[23]。
(2)药物警戒。在药理学中,为了防止在复杂疾病情况下或与其他药物混合使用时产生的有害作用,大部分的药物在其使用过程中都需要收集、检测、评估、追踪。利用电子病历数据检测药物的有害作用,目前已经有相当多的研究,其中关键的一步就是尽可能均等地匹配患者,以消除其他易混淆因素对分析结果的干扰。Vilar等[24]应用基于相似性的建模技术,使用2D和3D分子结构、不良药物事件(adverse drug events,ADE)、靶和解剖治疗化学(aratomical thernpeutic chemical,ATC)相似性度量,对先前在药物中选择的候选关联即4个ADE结果的广泛关联研究。
机器学习算法较传统的统计学算法有着无可比拟的优势和发展前景,它不需要数据的前提假设,更多依据实际数据特征建立模型,并在建模过程中自动学习改进,这一技术的日趋成熟必将为医疗领域发展带来巨大的变革。
