一种基于字向量和LSTM的句子相似度计算方法
2019-03-21何颖刚王宇
何颖刚,王宇
(集美大学诚毅学院, 福建 厦门 361000)
句子相似度度量是自然语言处理技术的基础,可应用于文本摘要、搜索引擎、论文查重、舆情分析、新闻去重、问答系统等业务领域。特别是在文本相似度计算方面,可以有效提高门户网站新闻去重效果。目前,中文句子相似度计算方法总体上可以分为基于统计学方法、基于汉语语义框架分析方法、基于向量空间模型方法和混合方法4类。
基于统计学方法是通过共现词、统计词频等来计算相似度。赵臻等[1]提出通过对句子语义较为重要的名词、动词、关键词等元素的词性、词位置以及词在句子中出现的频度统计量,设计权重计算公式,综合语义相似度和词序相似度,进行语句相似度计算。冯凯等[2]利用2个句子的所有最长公共子串来计算句子的相似度,在含有大量专有名词的问题集上提高了句子相似度准确率。传统相似度计算方法的缺点是受字词差异、错别字、语法错误、语序的影响较大,基于汉语语义框架分析方法是通过引入知网等专业语义资源,利用语义关系和语法成分来进行相似度计算。闫红等[3]在知网的词汇语义基础上,加入词语义原间反义、对义关系、单义原的否定等额外的特征来计算词语的相似度。朱新华等[4]在知网与同义词词林的词语语义相似度计算方法上重新设计权重计算策略,并考虑词语分布统计进行词语语义相似度计算。黄贤英、张金鹏等[5]基于HowNet语义词典进行改进,提出从词项词性角度构建词性向量,并利用词性向量计算短文本相似度。基于语义的句子相似度算法能够较好的处理多义词、同义词等情况,但准确率受语义资源的质量和规模影响。基于向量空间模型方法是利用深度学习等方法建立文本特征向量,通过特征向量进行相似度计算。李晓等[6]基于Word2Vec模型训练语料库获得词向量,然后根据句法分析,分别计算主语、谓语、宾语3部分向量相似度,并赋予不同的权重系数,从而设计句子相似度算法;郭胜国等[7]提出基于词向量计算Jaccard相似度与基于词向量依存句法相结合的相似度计算方法。混合方法是将多种相似度计算方法叠加起来的方法。周永梅等[8]通过综合VSM算法、语义相似度算法、结构相似度算法并进行改进,加入词性标注、权值和知网词语语义后设计语句相似度算法。继友翟[9]提出结合词语相似度、词权重和句型相似度来计算句子语义相似度。宋冬云等[10]通过改进向量空间模型,获得关键词加权文本相似度,然后结合文本主干语义相似度,分别加权计算得到文本最终相似度。混合方法能够综合考虑语法、语义和文本结构,使得文本相似度计算更加准确。
随着深度学习和大数据技术的广泛运用,在大规模语料库上训练Word2Vec模型,获得更好的词向量来表征语义信息,使得对自然语言的理解更加准确成为可能。李伟康等[11]利用深度学习方法将字向量和词向量结合起来应用在自动问答系统任务上,并取得不错的效果。笔者在已有研究基础上,提出融合字向量和LSTM(长短期记忆)网络的句子相似度计算方法。
1 模型原理
1.1 字向量与词向量

图1 LSTM单元
2003年,Bengio等[12]提出利用神经概率语言模型训练词的分布式表示,即词向量。词向量表示了语言的深层语义,用稠密的向量解决了传统one-hot表示带来的维度灾难和词汇鸿沟问题[13]。2013年Mikolov等[14]改进了神经网络语言模型,提出包含CBOW(Continuous Bag-of-Words)和Skip-gram(Continuous Skip-gram)2种计算框架的语言模型Word2Vec,可实现在海量数据集上进行高效词向量训练。CBOW原理是利用词W前后n个词预测当前词;而Skim-gram则是利用词W预测前后n个词。词向量可以获得文本中的语义信息、语句结构信息、句法信息等等丰富的内容。在无监督学习下通过训练词向量可以获得“queen-king+ man=women”这类词语语义相关性。字作为中文文本最小组成单位,字包含了丰富的语义信息,特别是成语这样的超短文本,基于字向量进行分析能够获得更好的语义信息。因此,使用字向量来进行中文自然语言处理具有重要的实践意义。笔者采用Skip-gram模型进行中文字向量训练,获得字向量表示,并通过字向量进行句子相似度分析。
1.2 长短期记忆网络LSTM
1997年,Hochreiter 和 Schmidhuber改进了RNN (Recurrent Neural Network,循环神经网络)模型,使用LSTM (Long Short-Term Memory,长短期记忆网络)代替隐藏层的节点,使得RNN可以记忆、更新长距离的信息,从而可以实现对长距离信息的处理[15]。LSTM的原理是通过门(Gates)的结构来实现,如图1所示。使用门机制可以实现选择性地让信息通过。LSTM有3个门:遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate),和单元(cell)实现历史信息的更新和保留。
2 模型结构
为了实现句子相似度计算的任务,笔者提出了基于字向量和LSTM神经网络的相似度计算模型,模型结构如图2所示。模型总共包含3个主要部分:由字向量构成的文本向量化层、基于LSTM的特征信息提取层、相似度度量层。
2.1 文本向量化层
将文本信息转换为高质量的向量表示是自然语言处理工作的首要步骤。利用Word2Vec对语料库数据进行训练获得字向量表示,字向量定义如下:
vi=[vi1,vi2,vi3,…,vin]
(1)
式中:vi为第i个字向量;n为字向量的维度,在训练字向量时进行设置。
进一步地,将语句中的文本逐字映射到向量空间,获得句子向量化表示:
Sk=[v1,v2,v3,…,vt]
(2)
式中:Sk为句子k;vt为句子中第t个位置字的字向量,对应LSTM网络第t时刻的输入向量。
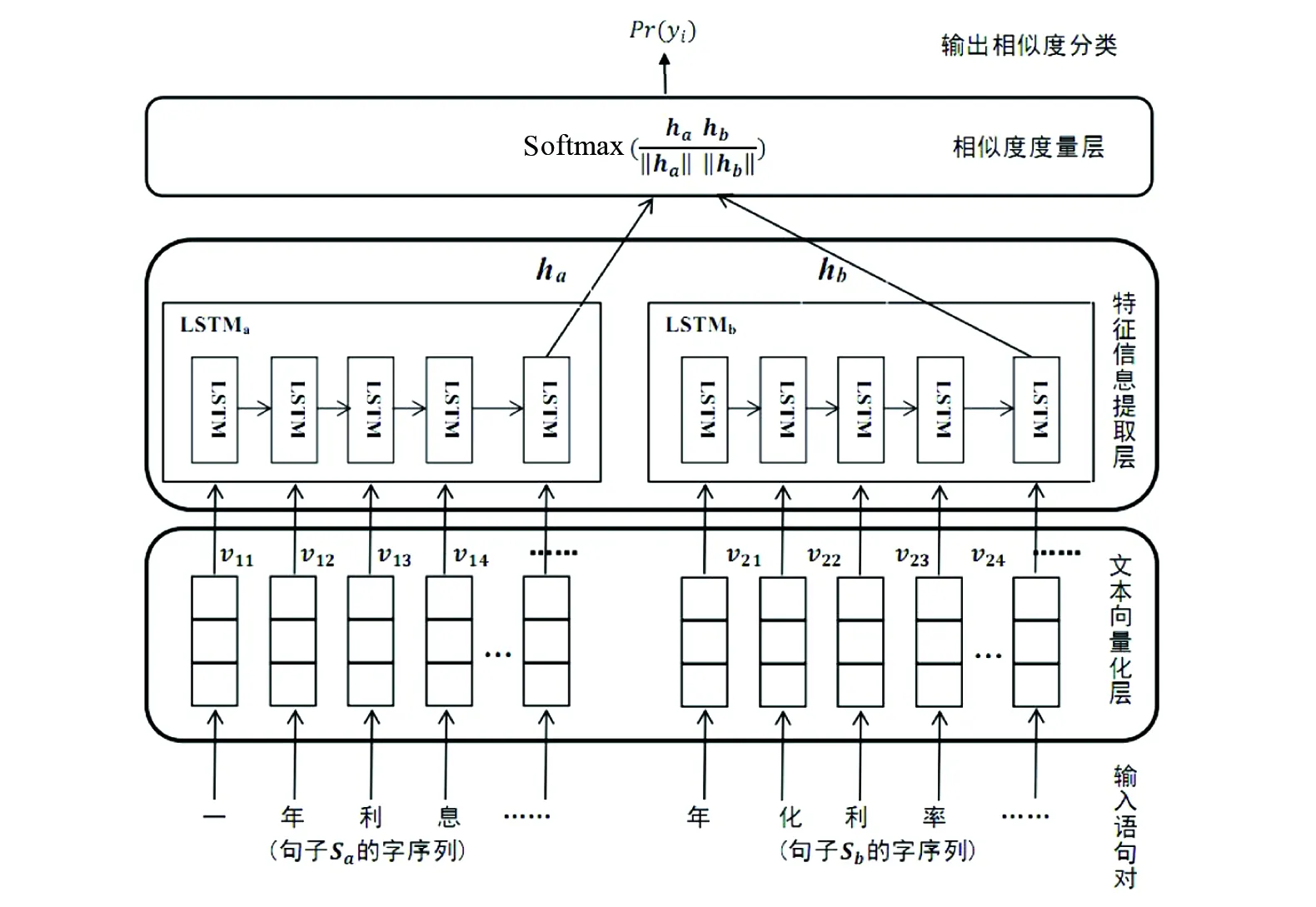
图2 基于字向量和LSTM的模型结构图
2.2 LSTM语句特征信息提取层
将向量化后的2个语句的句向量分别输入LSTM网络,获得对应的特征向量。LSTM网络的计算过程和输出结果表述如下:
it=σg(Wivt+Uiht-1+bi)
(3)
ft=σg(Wfvt+Ufht-1+bf)
(4)
(5)
(6)
ot=σg(Wovt+Uoht-1+bo)
(7)
ht=ot∘tanh(ct)
(8)
式中:it表示输入门;ft表示遗忘门;ct表示记忆单元状态;ot表示输出门;ht表示隐藏层状态;σg表示sigmoid函数; ∘表示元素乘法;vt为t时刻输入向量;Wi,Wf,Wc,Wo为不同门的权值矩阵;Ui,Uf,Uc,Uo为各门的偏置值。
2.3 相似度度量层
LSTM层的输出结果取最后一个LSTM单元的输出值作为特征向量,然后在相似度度量层计算2个句子特征向量的余弦相似度,求得结果后送入Softmax分类器,获得相似度判断结果。具体计算公式如下:
(9)
式中:yi表示相似度类别;ha是句子的a特征向量表示;hb是句子的b特征向量表示。
3 相似度计算方法与说明
首先,通过Word2Vec对语料库数据进行训练获得字向量表示。对句子Sa和Sb分别进行预处理,并获得句子的字序列后,利用Word2Vec训练得到的字向量,将字序列转换为字向量矩阵[v1,v2,v3,…,vt]。然后,将句子Sa和Sb的字向量矩阵以序列方式分别输入LSTM到网络中进行训练,获得句子的特征向量表示ha和hb。最后,将句子Sa和Sb的LSTM输出ha和hb代入相似度计算公式(9),求得相似度值。
dropout方法是目前能有效预防神经网络过拟合的方法之一,其原理是在训练迭代过程中,以设定的概率P随机删除神经元,用余下的神经元组成网络来训练数据。为了防止模型过拟合,在图2所示模型中采用dropout方法随机选择部分神经网络节点失活,从而提高模型的泛化能力,dropout(丢弃率)超参值取20%、30%、40%和50%,分别进行试验对比选取最优值。
4 算法试验与实施
4.1 试验数据
采用Chinese STS (中文语义相似度训练集, 西安科技大学,2016,https://github.com/IAdmireu/ChineseSTS)和CCKS2018 Task3(微众银行智能客服问句匹配大赛)提供的语料来进行试验。Chinese STS是由唐善成等老师收集和整理中文文本语义相似度语料库, 语料库分为2个子集,笔者选用simtrain- to05sts数据集来进行试验,该数据集一共有10000对句子对,并人工标注了相似度值,取值从0到5(5表示相似度最高,语义相似;0表示相似度最低,语义相反或不相干)。CCKS2018 Task3是微众银行提供的自动问答系统语料,该数据集共有100000对句子对,并标注了句子对相似度值,取值为0或1(0表示不相似,1表示相似)。从语料库质量上看,语料库2来源于自动问答系统,因此语料库句子存在错别字、语法不规范等问题;语料库1语句经过人工采集、清洗和甄别,语句表述较规范、数据质量较高。试验中,语料库按70∶10∶20比例分割成训练集、测试集和验证集3部分。
4.2 试验评价指标
试验采用准确率Precision、召回率Recall和F1值来衡量句子相似度计算方法的性能。准确率用于表示正确分类为指定类别的文档数量与分类到了指定类别的全部文档数量的比值。召回率是指某个类集内同属于某类别文档的数量与文档集中属于该类别文档的数量的比值。F1值是用来衡量分类模型精确度的一种指标,是准确率和召回率的调和均值。指标定义公式如下:
(10)
(11)
(12)
式中:TP为正确分类到正类的样本数;FP为误分为正类的负样本数;FN为误分类到负类的正样本数。
4.3 字向量训练
采用维基百科中文语料(zhwiki-20180120 -pages-articles,1.42G),对该语料进行繁体转简体、去除数字、特殊符号、停用词等处理后,使用Word2Vec的Skip-gram模型进行训练得到字向量。为了对比不同粒度向量在模型上的效果,额外训练了词向量,分词工具使用jieba。字向量和词向量的维度均为400维,上下文窗口大小设置为5,词频最小值为5。从字向量训练结果中选择中心字“书”和“房”来计算语义距离最近10个字,结果如表1所示。另外,为了对比不同粒度向量效果,从词向量训练结果中选择中心字“图书”和“学生”来计算语义距离最近4个词语,结果如表2所示。
从表1和表2结果可以看出,字向量对于词义的准确度的度量要好于使用词向量:从 “房”和“书”2字的相似度前10个近义字来看,它们的意义与“房”字有较高的相似度和关联度;而从“图书”和“学生”2个单词的相似度最高的4个单词来看,关联度不够密切。因此该模型采用字向量进行相似度计算,能够更好的获得计算结果。
4.4 试验结果及分析
提出基于字向量和LSTM神经网络的CV-LSTM模型进行试验,网络参数配置如表3所示。试验所使用的机器配置为Intel i5-3470 3.2GHZ四核处理器,16GB RAM, Nvidia GTX1060显卡,Ubuntu16.04操作系统,神经网络模型基于tensorflow开源机器学习库进行开发。
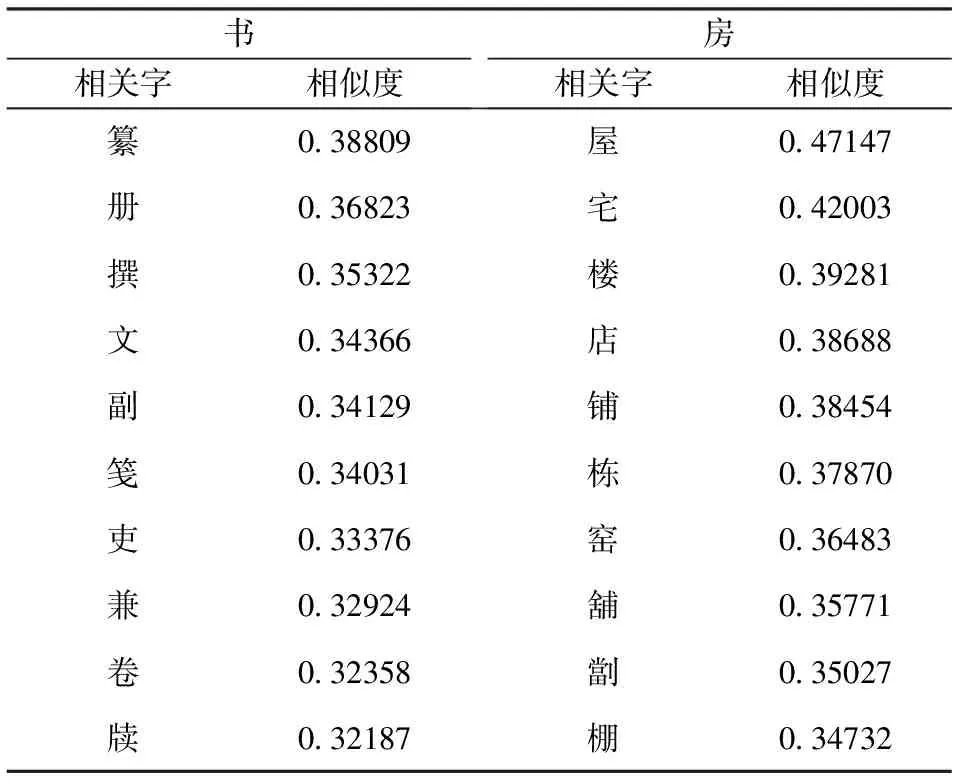
表1 字符语义距离
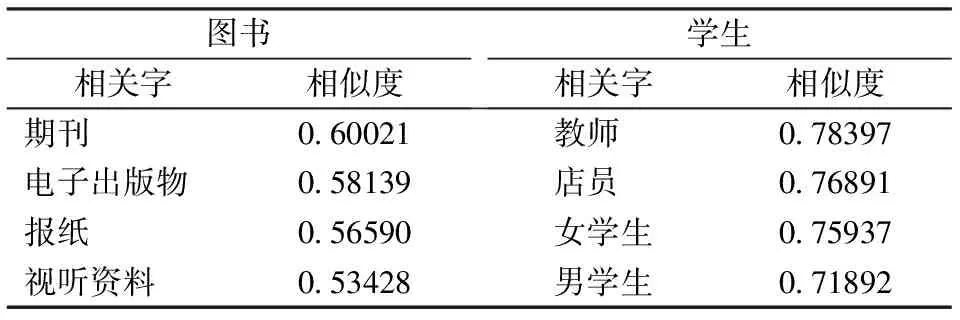
表2 词语义距离

表3 CV-LSTM算法参数设置
文本向量层主要参数为字向量维度、滑动窗口大小,笔者选择字向量维度(100、200、300、400)进行试验取优,滑动窗口大小取值为5;LSTM层主要参数有节点数、dropout值、学习率等等,选择节点数(100、200、300、400、500)、dropout(20%、30%、40%、50%)进行试验取优,其余参数如表3所示。模型目标函数选用交叉熵代价函数(cross-entropy cost function)。同时,训练过程使用Adadelta(自适应学习率调整)算法来优化目标函数。试验结果见图3~图5。
图3横坐标表示模型训练的 epoch number(全部样本训练过的次数),每个epoch训练时间约30~60min,与节点数量、维度大小呈正相关。从图3中可知,向量维度取400维对模型的准确率提升较佳。 图4体现了LSTM节点数个数对模型的影响,从数据对比可以看出不同节点数下模型准确率相差不大,考虑到训练时耗,节点数选取200。
图5反映了不同dropout值模型准确率的变化情况。从图5可以看出,随着迭代次数增加,准确率趋于稳定,当dropout取0.3时,模型性能较好。
4.5 算法验证
为了验证算法的有效性,笔者将其与2种传统的相似度计算方法莱文斯坦比(levenstein ratio)和Jaro-Winkler Distance方法进行对比;同时,根据文本向量化粒度单位不同,在相同模型下,选择了词向量和字向量进行效果比对;另外,为了比对不同神经网络模型的效果,还选择了卷积神经网络CNN方法、混合LSTM+CNN方法来进行对比。
1)Levenshtein_ratio方法。通过式(13)计算2个字符串相似度:
(13)
式中:sum为2个对比字符串的长度总和;ldist为类编辑距离。相似度阈值取0.618。
2)Jaro-Winkler Distance方法。通过式(14)计算相似度:
(14)
式中,|si|为句子si长度;m为2个句子中相同字符数量;t为字符替换总次数的0.5倍。相似度阈值取0.618。
3)WV-CNN方法。使用词向量,利用卷积神经网络进行训练和相似度计算。网络结构主要由1个词嵌入层、2个卷积层、2个池化层构成。卷积核窗口的大小为3,卷积核的个数为128,池化层采用maxpooling方法。
4)CV-CNN方法。使用字向量,利用卷积神经网络进行训练和相似度计算。网络结构和WV-CNN相同。
5)WV-LSTM方法。使用词向量,利用LSTM模型进行训练和相似度计算,网络结构和图2相同。
6)CV-LSTM方法。笔者的方法,使用字向量,利用LSTM模型进行训练和相似度计算,模型结构如图2所示。
7)WV-LSTM-CNN混合方法。使用字向量,利用卷积神经网络和LSTM网络进行训练和相似度计算。
对比结果如表4和表5所示。由表4和表5可以看出,CV-LSTM方法在计算结果上要好于其他方法,具体分析如下:
1)CV-LSTM方法的指标均高于其他方法。在CCKS2018 Task3数据集上CV-LSTM方法准确率比采用词向量的WV-LSTM方法准确率高6.63%,比传统的Levenstein-ratio方法高6.55%,在ChineseSTS数据集上CV-LSTM方法的准确率也达到了96.1%。这是由于字向量能够更多保存语义信息,同时,针对语句中用词不规范、错别字、语法错误等,通过字向量能够更好的保留句子的核心结构和语义,降低噪音干扰,提高相似度计算结果。而传统的方法对于存在语法错误、字词错误、语序错误的句子,计算准确率较低。
2)CV-LSTM训练结果优于CV-CNN训练结果,准确率大幅提高为17.33%。这是因为,句子属于短文本,包含的信息量不如长文本丰富,因此使用卷积神经网络,较难从句子结构中提取出有效的特征信息,导致相似度准确率低于CV-LSTM方法。
3)使用词向量和字向量进行相似度计算的结果表明,使用字向量的方法(CV-CNN、CV-LSTM)效果均要好于使用词向量的方法(WV-CNN、WV-LSTM),这得益于字向量能保存比词向量更丰富语义信息,从而提升相似度计算效果。
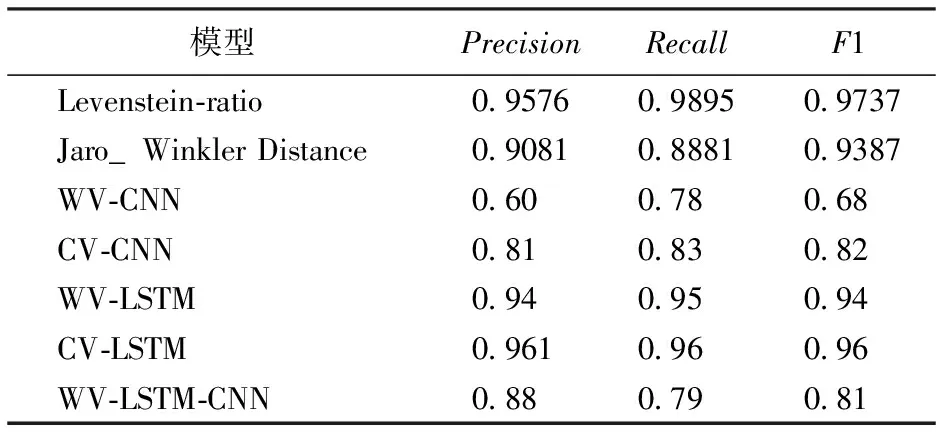
表4 ChineseSTS数据集分析结果
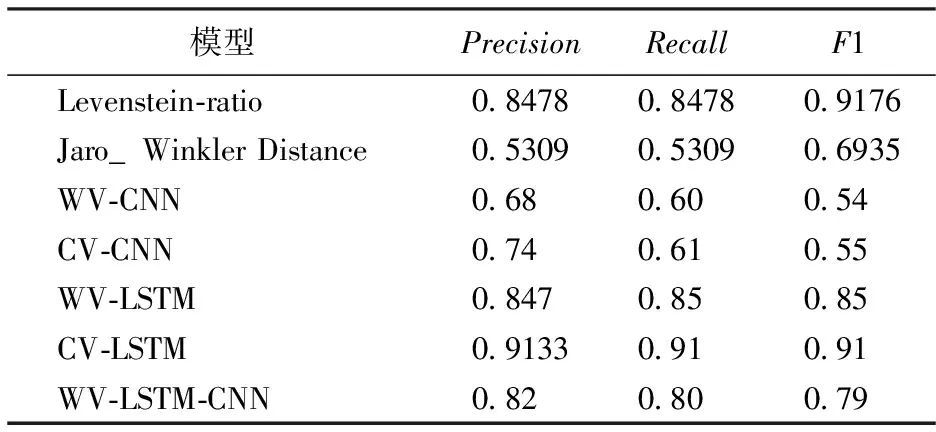
表5 CCKS2018 Task3 数据集分析结果
5 结语
笔者提出了一种新的语句相似度计算方法,采用Word2Vec训练得到字向量,将语句编码为字向量后,输入LSTM模型得到句子的语义特征,再使用相似度计算公式获得句子的相似度值。试验结果表明了该方法的可行性与有效性,可以更好地完成自动问答系统和毕业论文课题去重系统中的相似度判断任务。目前,新闻去重、舆情分析等对相似度计算有着更多的应用需求,下一步工作将开展短文本、长文本相似度算法分析和研究。
