高速铁路车站间客流变化一致性研究
2019-03-20王洪业吕晓艳刘彦麟
王 煜,王洪业,吕晓艳,刘彦麟
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
高速铁路车站客流变化直接影响列车开行对数和票额分配,如果2个高速铁路车站客流的变化有较高的“一致性”,而且客流量又较大,就可以考虑客流高峰期在这2个车站间对开临时旅客列车。对于票额分配而言,在除始发、终到旅客所占用的票额,剩余的票额需要在列车径路上的各车站间进行合理预分,以保证票额分配与客流需求尽可能相匹配。因此,各车站客流变化的一致性就可以作为对于票额分配的一个参考依据,即如果一个车站客流增长,需要增加票额,那么与其客流变化一致性较高的其他车站也应增加一定的票额,而客流变化一致性较低的车站可以适当减少票额,以平衡整体票额数量。对于某一趟列车在设置票额分组时,可以尝试将客流变化一致性较高且发送量较大的车站作为票额分组的节点车站,在此基础上统筹考虑整趟列车的票额分配。在目前对高速铁路客流规律的相关研究中,已经有很多学者采用了一些方法模型,如BP人工神经网络[1]、时间序列分析[2]、重力模型[3]、基于PAM算法聚类分析[4]、主成分分析[5]、模糊聚类[6],而关于不同车站间的旅客发送量变化相互关系则较少涉及。因此,通过聚焦于不同车站间旅客发送量变化一致性规律,根据不同车站旅客发送量变化方向和幅度对样本车站进行层次聚类,从而为列车开行和票额分配提供一个决策依据。
1 高速铁路车站客流变化一致性方法分析
1.1 方法选择
通过聚类方法分析各高速铁路车站客流变化一致性规律,高速铁路车站客流变化一致性越高意味着彼此在某种“距离”上越相近,通过选取恰当的“距离”计算公式,将客流变化一致性高的车站聚合为一类。主要步骤为:①确定计算高速铁路车站间“距离”的公式;②通过选取合适的阈值控制最终的聚类个数;③通过共表相关系数确定距离度量公式中的惩罚系数,得到最终的“距离”度量公式;④选取有代表性的高速铁路车站作为样本进行聚类,分析聚类结果,得出结论。
1.2 距离度量
为充分“度量”车站间旅客发送量变化的一致性,选用改进的曼哈顿距离分析法。相比欧式距离、马氏距离等常用距离,曼哈顿距离代表2个样本间差值的绝对值,可以较准确地描述2个车站间日旅客发送量增长率的“差异”。设车站x(x1,x2,…,xn)与车站y(y1,y2,…,yn)均为N维向量,x1,x2,…,xn,y1,y2,…,yn为该车站的日旅客发送量增长率。则车站x与车站y的曼哈顿距离表示为

即以车站间每日增长率差值的绝对值作为衡量2个车站“距离”的远近。2个车站增长率差别越大,则“距离”越远。但当2个车站发送量呈相反方向变化时(日增长率符号相反),则有理由相信这是2个车站客流变化“不一致”的明确体现,需要适当加大“距离”以作为惩罚。因而引入改进后的曼哈顿距离。
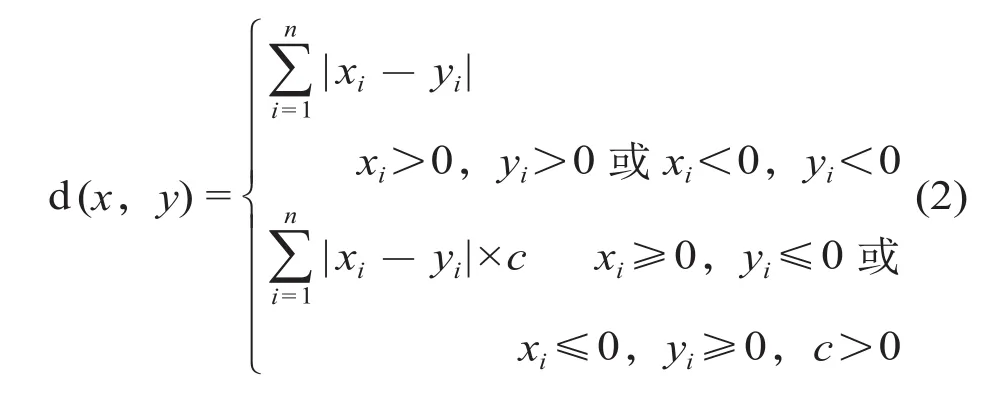
式中:c为惩罚系数,c> 1,当2个车站旅客发送量变化方向相反时,意味着“不一致”程度加大,因而作为“惩罚”,要适当加大其“距离”;c的具体取值由下文共表相关系数取最优时确定。
1.3 聚类个数与阈值
层次聚类是将各高速铁路车站看作单独的一类,将距离最近的2个高速铁路车站合并为一类,计算新类与其他类的距离,再将距离最近的类别合并,不断循环,直到所有高速铁路车站最终归为一类。层析聚类一般输出结果为树状聚类图,可以直观地反映出各类别的距离大小,即各车站在客流变化一致性上的远近,但想要较为明确地将聚类树状图划分为几个聚类簇则主要靠主观判断,缺少一个明确的规则。因此,引入偏度(不一致系数)的概念,来解决上述的问题。
偏度(不一致系数)是衡量自然簇分离的一个依据。设置好某个阈值,当一个节点和它的所有子节点的不一致系数小于所设置的阈值时,该节点及其下面的所有子节点被聚为一类,即形成一个聚类簇(聚类类别)。因此,通过计算聚类过程中的偏值(不一致系数),使所取阈值比该偏值(不一致系数)大一点即可控制最终聚类个数。具体计算过程如下。
设共有n个样本,则聚类过程矩阵Z=其中,xi,yi表示该步聚合时所聚集2类的序列号;di表示这2个序列号代表的类在聚合时的距离;mi表示这2类所包含的样本个数。
在聚类过程矩阵Z基础上计算出偏度矩阵R=其中,μi为该步聚合时距离的平均值;σi表示该步聚合时距离的标准差;ni为计算均值和标准差时选择的已聚合的类的个数;αi即为该步聚合时的偏度。

1.4 共表相关系数与惩罚系数
共表相关系数r是用来度量聚类效果“好坏”的一个指标,即聚类的结果应该使样本数据在同一个簇(类别)内差异性尽可能小(一致性尽可能高),不同簇(类别)中差异性尽可能地大。因此,共表相关系数r越接近1,则簇内一致性越高,簇间差异性越大,聚类效果越好。如公式(2)所述,惩罚系数c的取值应使共表相关系数r尽可能的大。但是,随着c的增大,共表相关系数r逐渐减小。与此同时根据经验,惩罚系数也不应该无限大,c< = 10
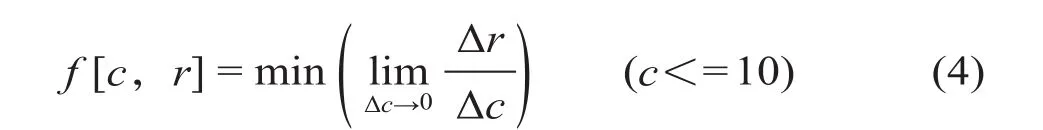
因此,综合考虑,在c< = 10范围内,使公式(4)取得最小时的c值即为惩罚系数。
2 案例分析
2.1 样本数据选择
(1)选取2017年全年旅客发送量超过1 000万人次且排名靠前的33个高速铁路车站作为样本,这些高速铁路车站基本位于直辖市、省会城市、计划单列市等大城市,城市类型和车站等级较为统一,减少这些因素对高速铁路车站发送量变化的影响。33个车站样本情况如表1所示。
(2)表1中33个高速铁路车站全年发送量都在1 000万人次以上,但不同车站日旅客发送量变化的绝对值差异仍然较大,单纯用发送量指标的变动不合适。因此,为消除量纲的影响,以各高速铁路车站日旅客发送量增长率作为进行聚类的指标,每个车站有364个数据,最后形成33×364的数据矩阵。

表1 33个车站样本情况Tab.1 33 station sample cases
2.2 计算结果
通过公式(4)确定惩罚系数c= 5.1,将选取的样本数据(33×364的数据矩阵)输入python,输出树状聚类结果。聚类结果如图1所示。
图1中,纵坐标为各高速铁路车站在公式(2)下计算出的“距离”,横坐标为所选择的33个高速铁路车站,图中序号对应的车站依次为:0—成都东站,1—贵阳北站,2—上海虹桥站,3—北京西站,4—长春站,5—重庆北站,6—长沙南站,7—西安北站,8—合肥南站,9—福州站,10—杭州东站,11—汉口站,12 —深圳北站,13—广州南站,14—济南站,15—南宁东站,16—宁波站,17—南京南站,18—南昌西站,19—沈阳北站,20—上海站,21—石家庄站,22—苏州站,23—深圳站,24—天津站,25—太原南站,26—徐州东站,27—北京南站,28—温州南站,29—武汉站,30—无锡站,31—厦门北站,32—郑州东站。将所有样本聚合为以下明确的类别。
阈值取1.144 7,得出聚类结果为:[5 5 2 2 4 4 4 5 4 4 4 4 1 1 4 5 4 4 4 4 2 4 3 1 3 5 4 2 4 4 3 6 4]。其中,第1个数字5代表样本编号为0的成都东站,第2个数字5代表编号为1的高速铁路车站贵阳北站,以此类推,33个数字代表33个高速铁路车站,相同数字代表的车站表示属于同一类别,如成都东站和贵阳北站都是5,属于同一个聚类类别。最终33个高速铁路车站可以分为6个类别:①深圳北站、广州南站、深圳站;②上海虹桥站、北京南站、北京西站、上海站;③苏州站、无锡站、天津站;④成都东站、太原南站、西安北站、南宁东站、贵阳北站;⑤厦门北站;⑥其他各站。该聚类结果与聚类树状图相一致。
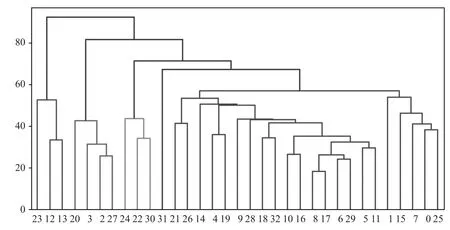
图1 聚类结果Fig.1 Clustering results
2.3 结果分析
(1)高速铁路车站间旅客发送量变化一致性与所在区域和地理距离有很大关系。同属一个地理区域或者地理距离越近的高速铁路车站旅客发送量变化一致性越高。例如,第1类中的深圳北站、广州南站、深圳站同属于珠江三角洲,地理距离较近,且直线距离不超过200 km;第2类中的北京西站、北京南站同属北京市,上海站、上海虹桥站同属上海市;第3类中的苏州站、无锡站同属于长三角地区且为相邻的地级市,直线距离不超过100 km。
(2)高速铁路车站间旅客发送量变化一致性与站间开通的高速铁路线路等级和客流有很大关系。同一线路的始发车站、终到车站的旅客发送量变化一致性往往越高,原因很可能是始发终到客流一般是该线路上占比最大的区段客流,且这一点在发送量越大的高速铁路干线越明显。例如,第1类中的上海虹桥站、北京南站,两者为京沪高速铁路的始发终到站;第4类中的太原南站、西安北站、成都东站,分别是大西高速铁路太原至西安段始发终到车站,西成高速铁路始发终到车站。
(3)经济文化交流越频繁,客流变化一致性也越高。例如,聚类距离排名“最近”的前5组的高速铁路车站,合肥南站与南京北站、长沙南站和武汉站、上海虹桥与北京南站、杭州东站与宁波站、重庆北站与汉口站在经济文化上关系度较高,联系较紧密,人员交流也较为密切。
3 研究结论
以主要高速铁路车站日旅客发送量增长率为样本,通过选择合适的距离度量公式和阈值进行聚类,最终输出聚类结果,达到预期效果。聚类结果揭示了以33个主要高速铁路车站为样本的各站间旅客发送量变化“一致性”规律,为列车开行、票额分配提供了一定决策依据。
(1)在客流高峰期,可以优先考虑在旅客发送量变化一致性较高的车站间加开临客列车,例如,同一条高速铁路线路两端节点车站间、处于同一地理区域的高等级车站间。
(2)新开列车可以根据所经过车站的发送量变化一致性来合理安排停靠站。例如,在客流高峰期的繁忙干线上应尽可能保持相邻2个停靠车站较低的发送量一致性以保证整列车不会过早超员。
(3)当某车站旅客日发送量增长较大时,与其“一致性”较高的其他车站旅客发送量有较大概率同方向波动,可以适当增加这些车站的票额,同时减少其他与该高速铁路车站变化一致性较低的车站票额。
(4)如果一趟列车经过若干发送量变化“一致性”很高的车站,而且这些车站发送量绝对值在整趟列车总发送量占比较高,则在票额分配时可以以这些车站为节点车站进行票额分组,统筹考虑整趟列车的票额分配。
(5)高速铁路车站旅客发送量变化的“一致性”与车站所在区域、地理距离、开通高速铁路线路等级与经济文化等因素有显著关系,还应进一步研究这些因素如何具体影响车站旅客客流变化。
