基于深度强化学习的蜂窝网资源分配算法
2019-03-13廖晓闽严少虎石嘉谭震宇赵钟灵李赞
廖晓闽,严少虎,石嘉,谭震宇,赵钟灵,李赞
(1. 西安电子科技大学综合业务网理论及关键技术国家重点实验室,陕西 西安 710071;2. 国防科技大学信息通信学院,陕西 西安 710106;3. 中国电子科技集团公司第二十九研究所,四川 成都 610036)
1 引言
随着无线网络中通信设备数量的急剧增加和业务需求的多样化,有限的频谱资源与人们日益增长的无线频谱需求之间的矛盾日渐突出和加剧。当前无线通信领域面临着智能化、宽带化、多元化、综合化等诸多技术挑战,无线网络环境变得日益复杂多样和动态多变,此外,绿色网络和智慧网络等新概念的提出,使频谱资源管理的优化目标日趋多样化,因此,如何优化频谱利用,最大限度地实现频谱资源的高效管理是当前急需解决的重点问题。
传统蜂窝网资源分配方法主要有博弈理论、拍卖机制、图论着色理论、遗传算法等。Huang等[1]将博弈理论应用于小区间蜂窝网的频谱分配,假设基站预先获得且共享信道状态信息(CSI,channel state information),将2个通信设备放置于相邻小区的重叠区域,采用静态重复的古诺博弈模型来求解纳什均衡解,获得最优的频谱效率,仿真模拟3种典型场景,通过求解一系列优化方程式来获得最优分配策略。Wang等[2]提出了一种安全的频谱拍卖机制,该机制综合考虑频谱属性和拍卖特性,采用自适应竞价、信息加密和拍卖协议等方式,在提高频谱利用率的同时,极大地提升频谱拍卖机制的安全性。Yang等[3]采用图论着色理论对全双工设备到设备(D2D,device-to-device)蜂窝网进行频谱和功率分配,构造干扰感知图,提出了一种基于图论着色理论的资源共享方案,该方案以网络吞吐量为优化目标,算法收敛速度快,时间复杂度低。Takshi等[4]基于遗传算法实现 D2D蜂窝网中的频谱和功率分配,通过同时搜索不同区间,获得全局最优的频谱效率和干扰性能,而且蜂窝网用户的信干噪比保持最低,对 D2D用户数量没有限制,并且采用信道预测方法来减少CSI信息的过载,算法具有较强的搜索性能。然而,随着未来无线网络向高密集、大数据、动态化、多目标优化等方向发展,传统的蜂窝网资源分配方法不再适用,例如,传统方法主要进行静态优化,很难适应动态变化的环境;当多目标优化问题为NP-hard问题时,求解困难;没有发挥出大数据优势,无法充分挖掘隐藏在数据中的信息等。
当前,以机器学习、深度学习为代表的新一代人工智能技术已广泛应用于医疗、教育、交通、安防、智能家居等领域,从最初的算法驱动逐渐向数据、算法和算力的复合驱动转变,有效地解决了各类问题,取得了显著成效。目前,机器学习在无线资源分配的研究还处于早期探索阶段。例如,文献[5]提出采用深度学习方法对 LTE中未授权频谱进行预分配,利用长短期记忆(LSTM,long short-term memory)神经网络来学习历史经验信息,并利用学习训练好的LSTM网络对未来某一窗口的频谱状态进行预测;文献[6]采用深度神经网络(DNN,deep neural network)对认知无线电中次用户使用的频谱资源和传输功率进行分配,最大化次用户频谱效率的同时,尽可能地减少对主用户造成的干扰;文献[7]将卫星系统中的动态信道分配问题建模成马尔可夫决策过程,采用深度卷积神经网络提取有用特征,对信道进行动态分配,有效地减少阻塞率,提高了频谱效率。目前,机器学习方法可以充分利用大数据的优势,模拟人类的学习行为,挖掘数据隐藏信息,以获取新的知识,然后对已有的知识结构进行重组,不断地改善自身的性能。此外,机器学习还可以实现动态实时交互,具有很强的泛化能力,在无线资源分配应用中凸显优势。
本文考虑优化蜂窝网的传输速率和系统能耗,基于深度强化学习提出了一种全新的蜂窝网资源分配算法,该算法分为两部分,即前向传输过程和反向训练过程。在前向传输过程中,考虑优化蜂窝网传输速率,采用增广拉格朗日乘子法,构建频率分配、功率分配和拉格朗日乘子的迭代更新数据流,在此基础上,构造DNN。在反向训练过程中,将能量效率作为奖惩值,构建误差函数来反向训练DNN的权值。前向传输过程和反向训练过程反复迭代,直到满足收敛条件时,输出最优资源分配方案。本文所提算法可以通过调整误差函数中的折扣因子来自主设置频谱分配策略的偏重程度,收敛速度快,在传输速率和系统能耗的优化方面明显优于其他算法,能够有效地解决多目标优化问题。
2 系统模型
考虑蜂窝网的下行链路,假设蜂窝移动通信系统中有M个微基站和N个授权移动用户,用户随机分布在小区内,所有基站和用户都为单天线系统。在每个小区内采用正交频分复用(OFDM,orthogonal frequency division multiplexing),每个频率只分配给一个用户使用,其他小区可以重复使用频率,即采用完全频率重用方案,因此从实际出发,综合考虑蜂窝网中所有基站对移动用户造成的干扰情况。系统采用集中式控制,信道增益、噪声功率等精确信道状态信息未知,每个授权移动用户仅将位置信息、干扰和传输速率通过导频信号传输给中心控制节点,由中心控制节点制定频谱分配方案。为了建设绿色网络,系统在最大化传输速率的过程中,还需要考虑能耗问题,具体的系统模型如图1所示。
假设m={1,2,…,M}表示微基站的集合,n={1,2,…,N}表示移动用户的集合,k={1,2,…,K}表示可用频率的集合。基站m中的移动用户n使用频率k通信时,干扰信号为
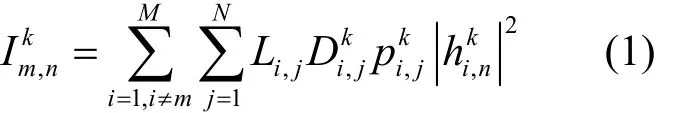
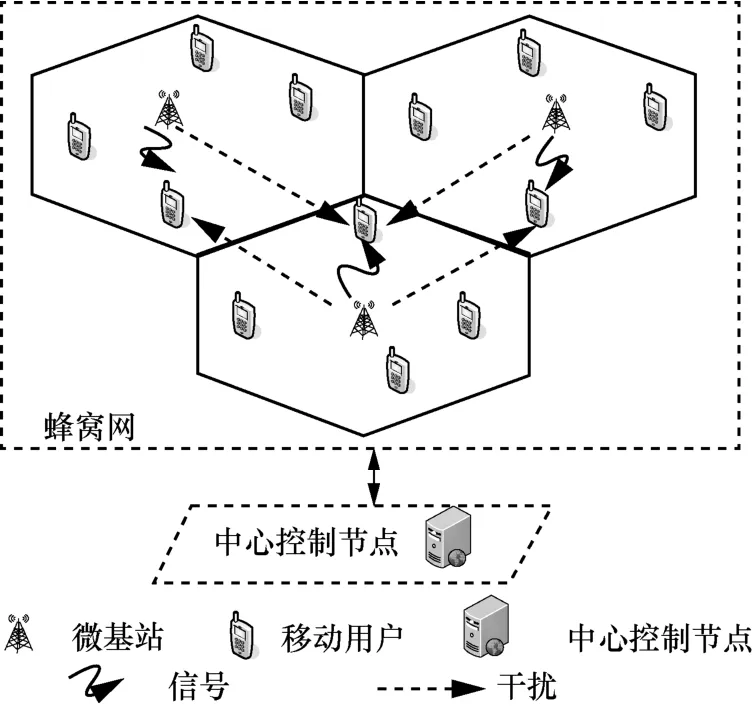
图1 系统模型
其中,Li,j表示移动用户j与基站i的接入关系,若移动用户j接入基站i,则Li,j=1 ,反之表示基站i内频率k的分配情况,若基站i把频率k分给移动用户j,则=1,反之=0;表 示基站i使用频率k与用户j通信时的功率;表示基站i使用频率k与用户n通信时的信道增益。
系统总体的传输速率可以表示为

采用文献[8]提出的能量效率来衡量系统能耗,即将每焦耳的能量最多能携带多少比特(单位为bit/J)作为衡量标准,则系统总体的能量效率可以表示为
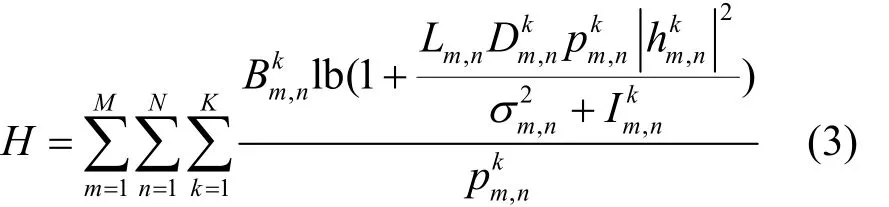
根据系统优化目标,在基站子载波发射功率之和满足最大发射功率约束的条件下,要解决的多目标优化问题描述如式(4)~式(6)所示。

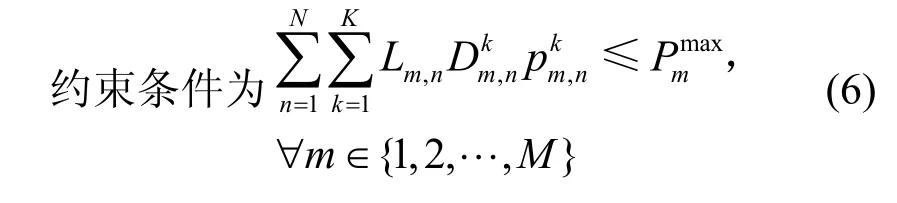
3 基于深度强化学习的资源分配算法
本文除了考虑传输速率外,还综合考虑能耗,于是资源分配问题变成了NP-hard问题,难以求得最优解。目前研究热点是将该问题转化为求解其次优解,但是求解复杂度高,影响系统运行效率[9],本文采用深度强化学习方法来求解该问题。
3.1 算法框架
深度强化学习将深度学习的感知能力和强化学习的决策能力相结合,不断以试错的方式与环境进行交互,通过最大化累积奖赏的方式来获得最优策略[10]。本文采用深度Q网络(DQN,deep Q-network)来具体求解资源分配问题,核心思想是将值网络作为评判模块,基于值网络来遍历当前观测状态下的各种动作,与环境进行实时交互,将状态、动作和奖惩值存储在记忆单元中,采用Q-learning算法来反复训练值网络,最后选择能获得最大价值的动作作为输出。基于深度强化学习的资源分配算法的基本框架如图2所示。

图2 基于深度强化学习的资源分配算法的基本框架
在图2中,st为算法进行到第t(t=1,2,...,T)步时所对应的观测,at为观测st下所执行的动作,rt为观测st下执行动作at后,所获取的奖赏/惩罚,值网络采用DNN来描述,即将DNN作为动作状态值函数
算法采用Q-learning学习机制[11],主要根据如式(7)所示的迭代式来实现动作状态值函数的优化学习。
其中,αk是学习速率,γ∈(0,1)为折扣因子,s'为执行动作at后获得的观测值,a′为动作集合∧中使得第k次迭代下的动作状态值函数在观测值s'下可执行的动作。从式(7)可以看出,要实现动作状态值函数的逼近,即

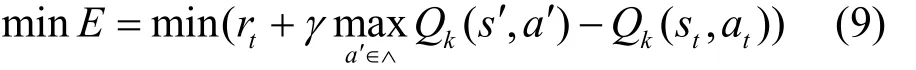
因此,本文将式(9)作为误差函数,通过求解误差梯度,即采用梯度下降法来更新DNN中的参数,求得动作状态值函数的最优解。
3.2 算法流程
对于系统模型中给出的多目标优化问题,基于深度强化学习的资源分配算法主要分成 2个过程来求解,分别是前向传输过程和反向训练过程。在前向传输过程中,本文以传输速率最大化为优化目标,利用式(4)和式(6)构造 DNN;在反向训练过程中,将能量效率作为奖惩值,利用式(9)来反向训练DNN。
3.2.1 前向传输过程
构造DNN是前向传输过程的核心,主要分成以下7个步骤。
1)考虑到每个微基站在所有信道上的发射功率之和不能超过其最大发射功率,依据式(4)和式(6),系统传输速率最优化问题表示为

约束条件为

2)采用增广拉格朗日乘子法将约束优化问题转化为无约束优化问题,构造的增广拉格朗日函数表示为
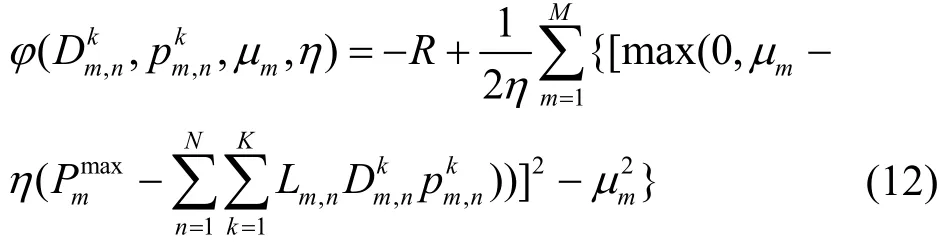
其中,μ={μm,∀m∈{ 1,2,… ,M}}为拉格朗日乘子,η为惩罚因子,从而把求解约束优化问题转化为求解无约束优化问题,即
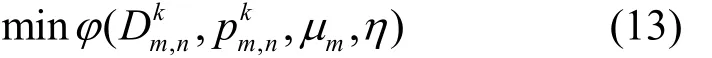
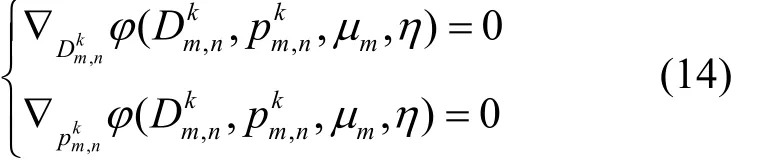


此外,拉格朗日乘子迭代方程式为
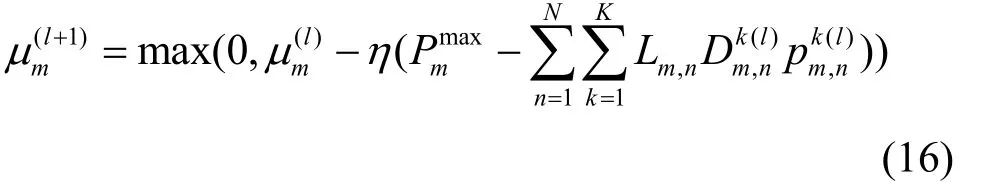
4)将移动用户与基站的接入关系Lm,n和移动用户干扰信息作为输入,各基站内频率分配、功率分配和拉格朗日乘子μ根据式(15)m和式(16),依次迭代,形成如下数据流。
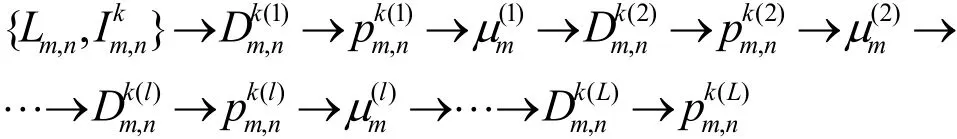
5)根据迭代更新数据流来构造DNN,如图3所示。DNN包括输入层、频率分配层、功率分配层、乘子层和输出层,深度取决于频率分配、功率分配和拉格朗日乘子μ的迭代更新次数。DNN中m频率分配层和功率分配层的权值参数为信道增益和噪声;非线性转换函数分别为频率分配、 功率分配和拉格朗日乘子μ的迭代更新方程式。m
6)初始化 DNN 的权值参数,即将信道增益初始化为瑞利分布,将噪声初始化为高斯 白噪声。
7)在时刻t,将观测到的蜂窝网用户接入信息和干扰信息作为DNN的输入,设定阈值θ 、D和最大迭代更新次数Q1,经过DNN的前向传输后,当或迭代更新次数达到最大迭代更新次数Q1时,在输出层输出一组数值,每一个数值对应一种频谱分配方案和功率分配方案,从输出的数值中寻找出最大数值,并将最大数值所对应的频率分配方案和功率分配方案作为时刻t的资源分配策略。
3.2.2 反向训练过程
构造误差函数来训练DNN是反向训练过程的核心,主要分成以下5个步骤。
1)在执行频率分配方案和功率分配方案后,观测系统能量效率,将能量效率作为奖惩值,即

3)依据式(9),构建如式(18)所示的误差函数。
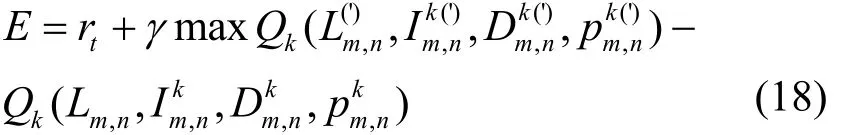
其中,折扣因子 γ ∈ [ 0,1]决定了资源分配策略偏重程度,若采用反向传播算法使用损失函数E趋于最小化,当γ→0,神经网络当前时刻输出的动作状态值函数)趋近于奖惩值rt,即资源分配策略偏重于优化系统能量效率;当γ→ 1 ,奖惩值rt和神经网络下一时刻输出的动作状态值函数占有同样的比重,此时资源分配策略综合优化系统能量效率和传输速率。
4)设定阈值θE,将损失函数值E与阈值θE进行比较。若损失函数值E≥θE,则执行5),否则,将选定的频谱分配方案和功率分配方案作为最优资源管理策略,完成蜂窝网资源分配。
5)采用反向传播算法,使损失函数值E趋于最小化,沿着损失函数梯度下降方向逐层修正信道增益和噪声,若DNN的权值参数更新次数达 到限定的最大次数Q2,则将获得的频谱分配方案和功率分配方案作为最优资源分配策略,完成蜂窝网资源分配,否则,修正好DNN的权值后,继续执行DNN的前向传输操作。
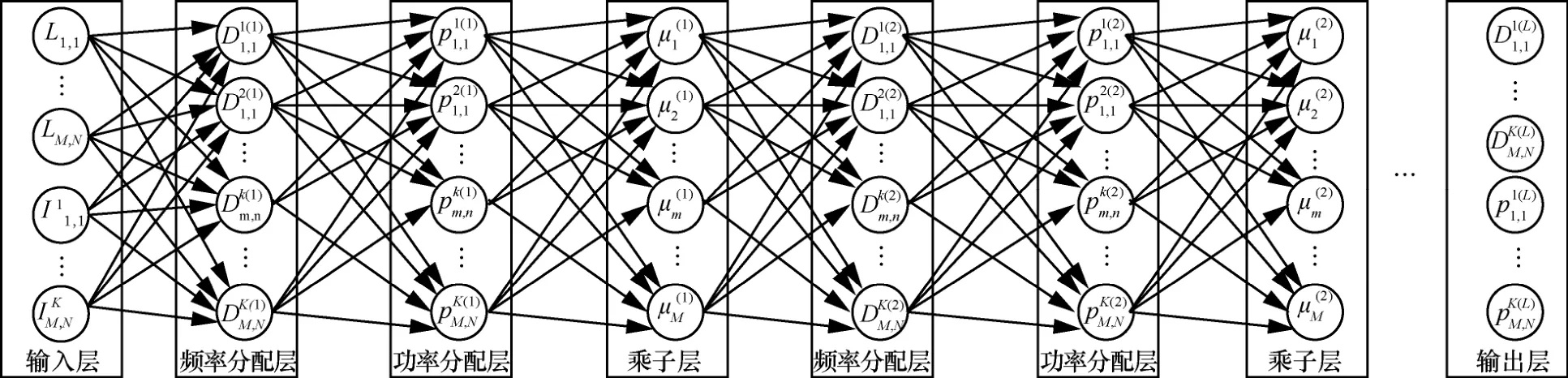
图3 DNN的基本架构

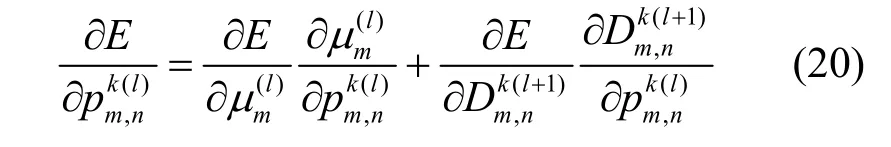
求得误差函数关于权值修正的梯度后,利用式(21)更新DNN的权值

其中,λ为学习速率。
4 仿真与分析
本文分别仿真分析了折扣因子对蜂窝网资源分配策略、基于深度强化学习的资源分配算法的收敛性和性能的影响,采用蒙特卡洛方法重复执行1 000次,然后对结果取平均值。在每一次算法执行过程中,蜂窝用户均随机分布在系统中,仿真参数如表1所示。

表1 仿真参数
首先,分析折扣因子对资源分配策略的影响。将可用子载波数设为4,图4仿真了折扣因子在[0,1]内的取值情况,显示了折扣因子对蜂窝网资源分配策略的影响情况,当折扣因子取值为0时,资源分配策略偏重于奖惩值,即偏重优化能量效率,此时获得的能量效率最高,传输速率最低。随着折扣因子增大,误差函数E中,动作状态值函数占有比重越来越大,资源分配策略所获得的传输速率越来越高,能量效率越来越低。当折扣因子取值为1时,系统获得的传输速率最高,能量效率最低。因此,在仿真过程中,可以根据资源分配策略的偏重程度来合理设置折扣因子。
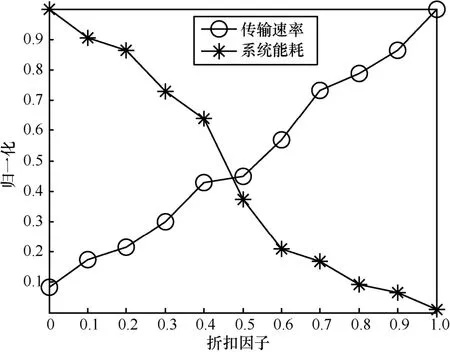
图4 折扣因子对资源分配策略的影响
其次,分析算法收敛性。将可用子载波数设为 4,算法运算速度取决于 DNN深度和反向训练DNN的次数。设定阈值 θD=θp= 0 .01,图5显示了DNN的深度。当DNN的深度为6时,差值DNN输出频率分配方案和功率分配方案。设定阈值θE=0.001,图6显示了反向训练DNN的次数。当反向训练次数达5次时,E< 0 .001,反向训练过程结束,输出最优的频率分配方案和功率分配方案。

图5 DNN的深度
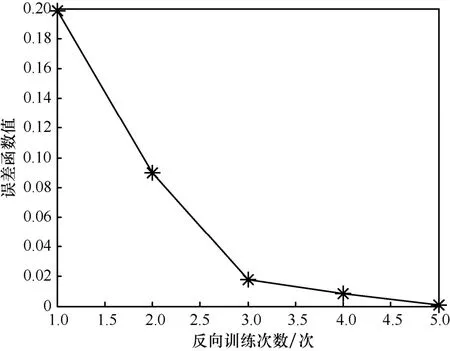
图6 DNN的反向训练次数
最后,分析算法性能。通过改变子信道数,将本文提出的算法分别从传输速率和能量效率两方面与随机分配算法、贪婪算法进行比较。图7和图8分别给出了传输速率和能量效率比较结果。可以看出,当折扣因子为1时,本文提出算法得到的资源分配策略偏重于优化传输速率,系统获得的传输速率接近于贪婪算法,但是获得的能量效率高于贪婪算法;虽然获得的能量效率低于随机分配算法,但是传输速率高于随机分配算法。当折扣因子为 0时,本文提出算法得到的资源分配策略偏重于优化能量效率,即奖惩值,虽然系统获得的传输速率相对较低,但是系统获得的能量效率高于贪婪算法和随机分配算法。

图7 传输速率

图8 能量效率
5 结束语
为了提高蜂窝网传输速率的同时,尽可能地增大能量效率,本文讨论了蜂窝网中的资源分配问题,提出了一种基于深度强化学习的蜂窝网资源分配算法,该算法包括前向传输和反向训练2个过程。在前向传输过程中,主要构建DNN,以最优化传输速率;在反向训练过程中,将能量效率作为奖惩值,采用Q-learning机制来构建误差函数,反向训练DNN中的权值参数。仿真结果显示,本文提出的算法可以通过设置折扣因子,自主选择资源分配策略的偏重程度,收敛速度快,在传输速率和系统能耗优化方面都明显优于其他算法,有效地解决了蜂窝网资源分配多目标优化问题。
