融合多层卷积特征的双视点手势识别技术研究
2019-03-13杨刘涛
张 哲,孙 瑾,杨刘涛
(南京航空航天大学 民航学院,南京 211106)
1 引 言
随着智能设备日益渗入到我们的生活,人们在享受这些设备带来方便的同时,如何促进人与机器进行更好的“交流”成为智能设备发展的目标之一.众多的人机交互方式中,由于操作的灵巧性,手势是使用最广、用途最多的交互方式,其中基于视觉的手部交互技术因为对用户限制较少,更容易提供一种自然、和谐、智能的交互方式而成为交互技术的热门研究领域,在远程医疗、指导机器人在空间、深海进行复杂作业等领域也具有潜在的巨大商业价值.
基于视觉的人手交互通过视频采集卡、摄像头等视频采集设备获取运动人手图像,根据图像信息推断出手势的三维方位指向,完成交互操作.因此,准确实现手部交互的过程,首先要对手势包含的信息进行分析,手势识别就成为了关键的步骤.同其他图像分类方法类似,手势识别方法包括特征提取和特征分类两大步骤.传统特征往往依据先验知识,由人工设计提取图像特征,如LBP[1](Local Binary Pattern)、HoG[2](Histogram of Oriented Gradient)和SIFT[3](Scale-invariant feature transform)等.单一特征包含的图像信息有限,而且一个成熟的特征形成需要很长时间的验证与改进.
最近几年随着深度学习的挖掘与应用,基于深度学习框架的分类方法极大提高了图像识别的准确性.自从2012年Alex Krizhevsky[4]利用深度学习方法取得ImageNet大赛的冠军之后,卷积神经网络(Convolutional Neural Network,CNN )成为了图像识别领域的研究热门.训练好的卷积网络模型每一层能自动提取大量的图像特征,将最终提取特征输入到Softmax层利用交叉熵得到属于各个类别的概率.
牛津大学视觉几何组提出的VGGNet[5]结构通过小尺寸卷积和增加网络深度的方法有效提升模型效果.研究表明[6,7],网络层次越深,提取的视觉特征可分辨性越好,更有利于图像分类.但加深网络会使网络复杂化,从而增加网络的训练时间和出现“过拟合”的倾向,为此,GoogLeNet[8]网络提出了Inception基本单元,使用不同尺度的卷积核来增强单层卷积的宽度.同时为了减少网络参数,每个Inception单元进行特征提取前会进行一次降维,既能大大提升卷积提取特征的能力,又不会使计算量提升很多.但是通过实验发现,利用GoogLeNet网络对存在“同形异构”问题(图1)的单视点手势识别效果不佳.分析其原因,主要由于单视点下容易出现手势自遮挡问题,使得对于姿态较为相近的手势识别误差较大.同时最后的全连接层提取的特征,在网络传递过程中也丢失了部分浅层网络提取的特征信息.
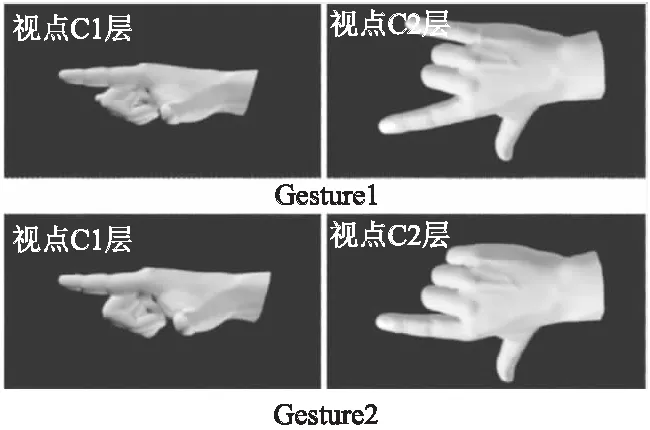
图1 自遮挡导致的“同形异构”手势Fig.1 Indistinguishable gestures caused by self-occlusion
针对以上分析可知,GoogLeNet具有卷积层深度和宽度更大、网络参数更少的优点.因此本文以GoogLeNet网络为基础,进一步提出了一种融合多层卷积特征的双视点手势识别方法.首先对双视点框架下手势图像采集和手势分类结果进行融合,降低单一视点下手势自遮挡的影响,提高手势识别的准确性;同时在每个视点下,学习网络融合多层卷积特征以补充深层网络在特征提取时降维造成的信息丢失,增强特征的鲁棒性;最后利用支持向量机代替Softmax逻辑回归层提高分类效果.
2 GoogLeNet神经网络
卷积神经网络是一种深度前馈人工神经网络,与普通神经网络相比,卷积神经网络包含了一个由卷积层和池化层构成的特征抽取器.其中每一层卷积层包含大量作为神经元权值的卷积核,根据局部感受野和权值共享原则对全局图像进行卷积操作提取特征;池化层也称为子采样层,可以看做是一种特殊的卷积过程,池化层能有效减小特征的分辨率,和卷积层一起大大简化模型复杂度和网络参数数量.
本文的网络框架是基于GoogLeNet网络.网络框架在一般的卷积神经网络基础上,除了提高网络深度以增强网络提取特征的泛化性以外,为了减少网络参数,防止出现过拟合,提出了一种Inception模型单元,如图2所示.
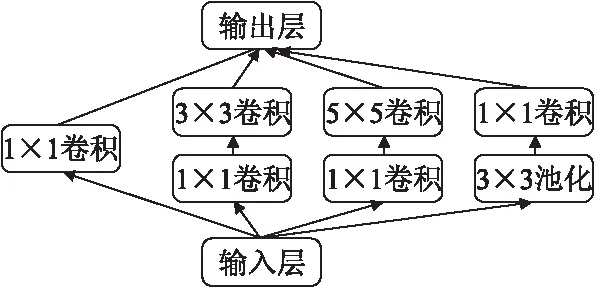
图2 Inception单元组成Fig.2 Structure of ′Inception′
Inception单元分别采用1×1、3×3、5×5三种尺寸的卷积层以及一个3×3的最大值池化层对输入层的神经元进行卷积操作提取更为丰富的特征,提高了卷积网络的宽度.为减少5×5的卷积核产生的巨大计算量,受NIN[9](Network in network)的启发,在对输入层神经元进行3×3、5×5卷积操作前先采用1×1的卷积核进行降维操作,在保证特征提取性能的同时成倍数的降低网络参数,节约了大量的运行时间.与此同时,GoogLeNet网络整体网络深度达到22层,网络越深越容易带来梯度消失问题,不利于模型优化.所以在整个网络不同深度的Inception单元处加上了三个损失函数层(如图3所示)来保证向前传导时梯度不会消失.
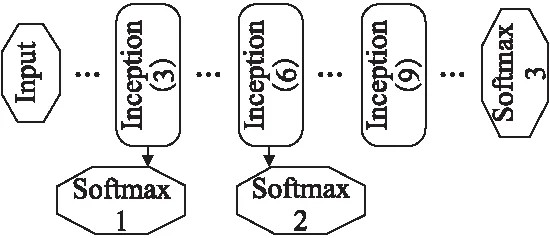
图3 GoogLeNet网络损失函数层Fig.3 Loss function layer on GoogLeNet
在识别过程中,最后提取到的图像卷积特征通过全连接层得到分类向量X=[x1,x2,…,xm],m为类别总数,再输入Softmax分类层得到样本属于类别i的概率值:
(1)
所以分类结果为:
(2)
训练时损失函数为:
Loss=-logPl
(3)
其中l为训练样本的类别标签.
3 融合多卷积特征的手势识别
本文使用GoogLeNet网络作为整个手势识别框架结构的核心,参考文献[11]的双分辨率网络结构,提出双视点下的卷积神经网络结构.3.1节介绍了双视点手势识别方法及多手势预测结果的投票机制,以及利用SVM分类器替代网络原有Softmax分类函数的设计方案;3.2节分析介绍了不同深度网络层的特征冗余问题以及多层卷积特征融合的问题.
3.1 双视点网络框架
前文提到,GoogLeNet网络拥有很好的分类识别性能,但是对于单视点手势图像来说性能却远未达到预期.究其原因,手部自由度高,单视点下会出现如图1的手势自遮挡问题,导致“同形异构”手势在单视点下的特征差异较小,可分辨性不高,容易出现手势误判.为了减小手势自遮挡的影响,本文借鉴文献[13]提出的正交双视点布局,如图4所示,分别从两个正交视点C1、C2采集目标手势s的输入图像I(s|C1)、I(s|C2).预处理后同时将双视点图像分别输入到单独训练的GoogLeNet网络模型中进行特征提取,得到三层不同深度的卷积特征f1、f2、f3.根据多卷积特征融合方法(3.2中介绍)对三个特征进行特征降维和融合,得到最终双视点下融合特征FC1、FC2.

(4)
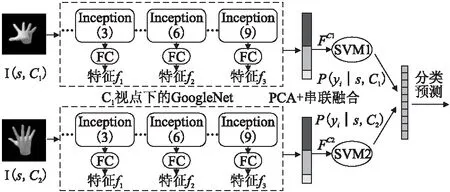
图4 融合多卷积特征的双视点手势识别网络结构Fig. 4 Dual-views gesture recognition framework based on the fusion of multi-convolution features
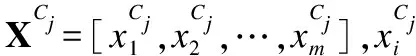
(5)
其中yi表示第i个类别标签,m为手势类别数量.
在得到两个视点下的预测向量XC1,XC2后结合双视点预测向量的结果,采用绝对多数投票法得到最终目标手势的分类预测向量:
R=1-(1-XC1)⊗(1-XC2)
(6)
“⊗”表示向量对应元素相乘,依据概率最大原则得到目标手势的分类结果,其中ri为R向量的第i个分量,即预测为第i类的概率:
(7)
3.2 多卷积特征的融合
深度学习网络为了加强特征提取的泛化性,往往需要层数很深的卷积网络.一般来说,深度越深,特征表达能力越强.通常会选取最后的全连接层特征,即图4中特征f3,进行分类器的训练.但是由于Inception单元在进行多尺度卷积核训练时为了降低参数量,对特征输入层进行了降维操作,导致输入图像在前向传播提取特征时丢失一部分底层特征信息.相关研究[12]证明了不同卷积层特征之间存在一定的互补性.为了提高深度学习网络提取特征的鲁棒性,本文提出了一种融合不同深度层卷积特征的方法,结合多层次特征以补充单层卷积特征可能造成的特征信息丢失.
GoogLeNet网络共有9个Inception单元.如图4所示,本文从浅至深分别选取第3、6、9个Inception单元的输出进行特征提取,得到三个不同层次的卷积特征f1、f2、f3.其中特征空间均为1×n维.为了保持融合过程中特征空间维度不变,同时忽略特征中的次要成分,本文在特征融合前先对网络提取的卷积特征进行主成分分析,并在保证特征正确表示(累计贡献率>97%)的前提下对三个卷积特征进行降维:
φ(f,α)=f*T(:,1:α·n)
(8)
其中f为原特征向量,压缩率α根据训练样本卷积特征的累计贡献率确定.T∈Rn×n为根据样本集特征得到的映射转化矩阵,降维后特征φ(·,·)空间维度为1×(α·n)进行降维串联后得到三个不同层次卷积特征的融合特征为:
F=[φ(f1,α1),φ(f2,α2),φ(f3,α3)]
(9)
4 实验及结果分析
4.1 实验数据集
本文双视点安排如图5所示,数据集利用poser建模软件构建20种常用手势,如图6所示.数据集中存在多种由于自遮挡导致的“同形异构”手势,如手势5和手势6等.

图5 视点安排Fig.5 Illustration of viewpoint
每一种手势根据人手在空间中的可转动范围,在三维正交轴的三个方向以一定的角度间隔连续旋转并从正交双视点方向进行采样.每种手势共有1936种姿态样本,从中选取1540组双视点图像作为训练样本集,在其余样本中再选取220组作为测试样本.

图6 poser建模工具构建的20种手势Fig.6 20 different types of gestures modeled by the software of poser
4.2 单视点与双视点对比实验
为解决自遮挡问题,提高识别准确率,本文采用双视点下的卷积神经网络结构,通过实验对比单视点和双视点下每一类手势识别的准确性,得到如图7所示的对比曲线.
可以发现双视点框架下能有效的降低单一视点存在的手势自遮挡问题的影响,明显提高“同形异构”手势的整体识别准确率.图7中手势9在视点C1下的识别精度要明显高于视点C2下的识别精度,但是在双视点结果融合后,其结果大于C2视点下的识别精度,却略小于视点C1下的识别结果(双视点和C1下准确率分别为96.3636%和97.2727%).结合手势9的测试样本和公式(6)分析可知:该手势在C1视点下不存在歧义手势,隶属手势9类别的置信概率最大,准确率高,但在C2视点下由于自遮挡造成该手势与其他手势相似,导致属于其他手势识别置信概率增大,识别错误.本文方法是结合两个视点预测向量的结果,根据公式(6)在C2视点下错误类别置信概率增大同时正确类别置信概率降低会导致双视点下的错误分类,因此出现双视点识别率小于视点C1下的识别率.识别过程选择任一视点都会出现自遮挡情况,但根据图7所示20种手势测试样本的结果分析,双视点识别网络整体识别准确率更为稳定,能有效降低手势在某一单视点下的误识别概率.

图7 单视点结构与双视点结构效果比较Fig.7 Accuracy comparison between single view and dual-views
4.3 与现有深度学习方法对比实验
本文的双视点识别网络是基于GoogLeNet深度学习网络的改进.通过在单视点下与两种经典的深度学习网络GoogLeNet和Alexnet进行识别效果的比较,验证本文融合多层卷积特征的方法性能.本文的三层特征的压缩率根据实验结果分别取α1=1/2,α2=3/8,α3=1/8,两个视点下的实验结果分别如图8所示.
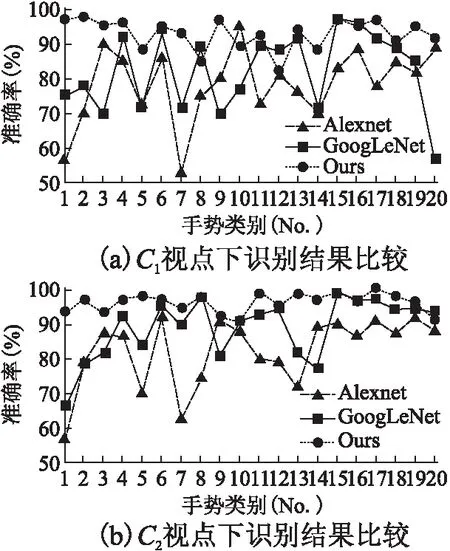
图8 不同视点下识别准确率比较Fig.8 Accuracy comparison at different viewpoint
从实验结果可知,本文提出的融合多卷积特征的识别方法在自遮挡程度不同的两个视点下的整体识别效果均优于GoogLeNet和Alexnet深度识别网络,并且对于每一类手势的识别结果波动较小,表明对于单视点下自遮挡严重的手势,手势特征的可分辨性更好.
4.4 多卷积特征融合实验
4.3节验证了本文方法较现有深度学习方法的优势,本节为充分验证融合特征鲁棒性,选取手势自遮挡现象严重,“同形异构”手势较为突出的视点下,通过实验验证不同卷积层特征对识别准确度的影响.实验结果如表1所示,随着卷积层数的加深,手势识别准确率递增.而融合后的多卷积特征,在单视点下的效果准确率要优于单一卷积层特征,说明了多卷积特征融合具有较强的鲁棒性.

表1 单层卷积特征与多层融合特征效果比较Table 1 Accuracy comparisons between single layer feature and fusion feature of multi-layers
4.5 与人工设计特征方法对比实验
本文与文献[13]提出的传统KNN方法和Pareto-Optimality方法进行比较验证双视点下不同识别方法的性能.三种方法均采用正交双视点的识别框架,其中,KNN方法采用串联结构,先在一个视点下进行手势相似度比较,筛选出一部分相似度较高的手势,再与目标手势在第二个视点下再进行比较,最终得出手势识别结果.而Pareto-Optimality方法则是双视点下同时进行特征相似度比较,将识别匹配问题转化为数据点集的优化问题得到手势识别结果.这两种方法进行比较的手势特征均采用人工设计的改进LBP特征.

图9 三种手势识别方法准确率比较Fig.9 Accuracy result of three methods on 20 gesture
与上述两种方法识别准确率对比结果如图9所示.可以看出在同样的双视点框架中,本文的方法能明显提高手势识别的准确性,证明了多卷积特征相对于传统人工设计特征具有明显的优势.

表2 单个手势识别平均用时Table 2 Average time cost of three methods on each gesture
传统KNN方法和Pareto-Optimality方法均属于在线学习的方法,随着样本库的增大,其识别的时间也随之增加.本文基于深度学习的方法属于离线学习方法,只需要提前训练好网络模型参数,在实际识别过程中将目标手势图像输入网络即可.即使有新的样本加入训练集,只需要在原先的网络参数基础上对网络参数进行微调,微调过程离线进行,不影响在线识别过程.在本文相同的实验环境(Intel i5-4590,3.30GHz)下,表2给出了目标手势在三种方法下的平均识别时间,可以看出本文方法较传统方法能有效提高时间效率.
5 研究结论
本文在深度学习网络基础上提出了一种融合多层卷积特征的双视点手势识别方法,通过将不同层的卷积特征进行降维,根据训练样本特征贡献率得到的融合特征补充了丢失的部分浅层卷积特征信息,提高了特征的鲁棒性.同时双视点网络结构能有效降低单视点下存在的手势自遮挡问题的影响,提高识别精度.基于深度学习框架的手势识别方法在运算时间上优于基于数据库查询的在线学习方法,有利于提高手部识别的时间效率.
