低采样率浮动车的路况计算精度优化
2019-03-13孙卫真邱皓月
孙卫真,邱皓月,向 勇,张 禹
1(首都师范大学 信息工程学院 计算机科学与技术系,北京 100048) 2(清华大学 计算机科学与技术系 网络所,北京 100084) 3(北京理工大学 计算机学院,北京 100081)
1 引 言
近些年来随着城市化进程的推进与智能交通系统(Intelligent Transportation Systems,ITS)的快速发展,对于路况精度的要求越来越高,城市的车辆导航、交通管理[1]等都需要路况计算来提供支持.目前国内外路况计算的数据来源主要是固定探测器[2,3]和浮动车[4].浮动车相比于固定探测器,具有造价低、覆盖范围广的优势,能够提供精确的车辆定位和行驶信息[5],因此逐渐成为探测城市路况的重要数据来源.但由于数据采集能耗及传输成本原因,目前的车辆数据采样间隔通常大于30秒,采样率普遍较低[6],轨迹点的稀疏性导致同一辆车连续两个轨迹点通常不在同一条道路上.与此同时城市路网越来越复杂,路口、立交桥的日益增多导致车辆在路口处的转向时间消耗难以忽略.现有研究[7]表明车辆在路口消耗的时间占全部行驶时间的25%以上,这对交通数据分析也带来了极大的挑战.
目前针对低采样率导致轨迹点间路由增多的问题,解决方法主要是利用轨迹点的间平均速度[8]、历史道路速度[9]等对道路速度进行加权分配,但是没有考虑路口的转向时间消耗.而针对路网的复杂性,一些学者通过划定统一的路口范围[10,11],将车辆行驶时间划分为道路行驶时间和路口转向时间,但这种方法只考虑到了普通路口,在路况计算中对立交桥这种大型复杂路口的处理鲜有研究.Zhang[12]没有划定路口范围,而是引入了虚拟的路口转向时间,使用基于历史路况的行程时间分配算法进行路况探测,该方法有效的解决了低采样率下普通路口的转向时间计算问题.但当车辆处于立交桥内部时,不仅道路匹配存在较大的不确定性,而且立交桥内部的一条道路被划分成了多段道路和多个路口,路况的计算精度也会受到一定影响.因此在基于低采样率数据的路况计算中,为了提高路况计算精度,既需要对立交桥进行有效处理,也需要充分利用路口前后的车辆信息.
本文的工作概括如下:
1)将立交桥视为一个路口,利用北京市OpenStreetMap的数据,对立交桥进行了自动化定位,并划定了其路口范围.
2)充分利用路口前后的车辆信息来精确推导相关道路和路口路况,并与行程时间分配算法进行了有效结合.
3)利用2.7万辆以上的北京市出租车轨迹数据进行了计算,结果表明路况计算优化算法比行程时间分配算法整体提高了4.32%的路况精度.
2 相关工作
本文工作重心是提高低采样率下的路况计算精度,因此道路速度、路口范围划分以及转向时间的计算都与本文的工作相关.
路况计算需要使用道路的平均速度,一些学者利用车辆的瞬时速度信息[13]进行计算,比较典型的是以瞬时车速[14]和以车辆速度曲线中平滑路段的速度作为道路速度参考值[15],然而车辆的瞬时速度并不一定是稳定和可靠的,尤其是在路口拥堵或受交通灯影响时会减速或等待一段时间,并且在真实场景中,浮动车数据采样率较低,瞬时速度信息并不能代表道路速度.因此为了提高低采样率数据下的路况计算精度,Fabritiis等人[8,16]使用轨迹点的平均速度作为路由上的道路速度参考值.Liu[9]使用历史道路速度通过加权的方式计算浮动车在路由中每一条道路上的时间消耗,但他们的缺点在于没有考虑车辆在路口的转向时间消耗.
路口和立交桥是城市路网的重要组成部分,现有的工作大多是针对普通路口来划定路口范围,如[10,17]分别以距离路口中心100米和160米作为路口范围.其缺点在于城市道路长度不一,将路口范围设为统一值是不合适的.Yue[6]根据历史的路口车辆等待长度和道路级别来设置路口范围,但该道路模型假设两轨迹点间只能跨越一个路口,局限性较大.Zhang[12]引入了虚拟的路口转向时间,以<道路A,道路B,路口转向时间>三元组的形式来描述路口转向时间开销,解决了连续两个轨迹点跨越多个路口的情况.
目前学者们在路况计算中只考虑到了普通路口,但对于立交桥这种大型复杂的路口鲜有研究.而立交桥道路结构复杂,内部纵横交错,和普通路口存在较大差别,需要单独区分.在路况计算中针对立交桥的研究需要涉及定位及路口范围划分问题,关于立交桥的定位研究,现有大多数的尝试是基于几何统计学相关的知识进行提取,如基于改进霍夫变换的城市立交桥检测方法[18]和基于拓扑关系与道路分类的立交桥识别方法[19],但其缺点是需要依赖遥感系统和图形库.Ma[20]通过聚类算法对城市部分地区的复杂交叉口进行了定位,但并没有应用于城市整体,且将立交桥的路口范围划分为圆形,包括了很多非立交区域的道路,对于形状不规则的立交桥并不适用.因此在路况计算前,会将立交桥简化抽象为一个路口,忽略其内部细节,对立交桥进行自动化定位,并确定其路口范围.
在考虑路口转向时间的路况计算方面,现在已有不少研究,如基于路口下游路段浮动车数据[21]和基于模糊C均值聚类的方法[22]来估计路段行程时间.Yue[6]将道路划分为平滑路段与路口路段,能够将一部分道路路况分离到路口.而Zhang[12]对于连续轨迹点之间的路由,先根据历史路况得出道路和路口行驶时间的估计值并使用每个道路和路口上的时间开销在该估计值中所占的比例作为权重,对真实的行驶时间进行了加权分配.但以上文献都没有对立交桥进行区分处理.
本文的最终目的是提高低采样率车辆下的路况计算精度,因此普通路口和立交桥都会作为路口参与计算.我们将充分利用同一辆车通过路口前后的轨迹点信息来精确推导相关道路和路口路况,借鉴行程时间分配算法[12],根据路口前后轨迹点数目设置不同的影响因子来对道路行驶速度和路口转向时间进行计算和更新.
3 路况计算系统框架
图1是路况计算系统框架,在路况计算前会对地图数据进行预处理,包括将双向道路拆分成两条单向道路和对立交桥的定位与路口范围划分,并存入到地图数据库中.该系统以低采样率浮动车数据和地图数据作为输入,经过道路匹配、路况计算后将路况更新到路况数据库中.本文按车辆的真实发送时间差模拟了轨迹数据的发送并进行处理.当车辆轨迹数据到达时,首先经过数据清洗去除错误和重复的轨迹点,然后将车辆匹配到道路上.本文使用的道路匹配基于OHMM(Online Hidden Markov Model)地图匹配[23]算法它基于变长滑动窗口的马尔科夫匹配模型,考虑匹配点的上下文环境,计算每一个轨迹点所在的道路,并给出车辆从前一个轨迹点到当前轨迹点的路由信息.
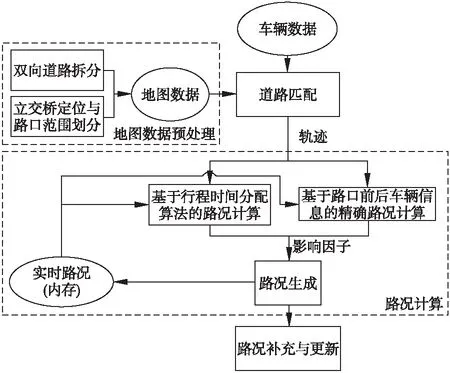
图1 路况计算系统框架Fig.1 Framework of traffic situation calculation system
在路况计算阶段,本文借鉴Zhang[12]的工作,提出了一种改进的路况计算优化方法.它基于路口前后轨迹点位置及数量精确计算了道路行驶速度和路口转向时间,通过设置影响因子,与行程时间分配算法相结合来提高路况精度.生成的实时路况又会作为历史数据参与到下一批次的路况计算中,具体细节将在第5节进行说明.在路况汇总与更新阶段,以5分钟为一个时间片,将计算出的路况(道路速度和转向时间信息)存储到路况数据库中.在此系统中本文的工作重点是立交桥定位、路口范围划分与提高路况计算精度.
4 立交桥的定位与路口范围划分
立交桥作为城市主干道的重要连接点,在路况计算中需要考虑其对路况精度造成的影响.但其形态种类繁多,内部纵横交错,分别对其建模将十分低效,因此本文将整个立交桥区域视作一个路口,在地图中对其进行自动化定位并确定路口范围.然后将这些属于立交桥路口范围内的道路与该立交桥进行关联,存储到地图数据库中,用于路况计算优化.
4.1 利用聚类算法对立交桥进行定位
OpenStreetMap的道路数据包括了道路级别信息,本文直接利用高等级道路(高速公路连接路和主干道连接路)这种自发地理信息的数据,基于道路连接点的密度对立交桥进行定位.考虑到以下几个原因,本文决定选用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法进行聚类:
1)北京市立交桥的数量、形状及位置分布在OpenStreetMap中是没有标注的,而DBSCAN算法不需要事先知道要形成的簇的数量,能够自动确定聚类的个数,并且可以构成任意形状的区域.
2)并不是所有的道路连接点都属于某个立交桥区域,在OpenStreetMap中有大量道路连接点属于噪声点,而DBSCAN根据密度可以很好地识别出这些噪声点.
4.1.1 DBSCAN简介及算法改进
DBSCAN算法是一种典型的基于密度的聚类算法,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇.其基本原理是通过检查数据集中每个点的给定半径Eps邻域来搜索簇,如果点p的Eps邻域包含的点多于最小包含点数MinPts,则创建一个以p为核心对象的簇;然后迭代地聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并;当没有新的点添加到任何簇时,该过程结束.
在路况计算应用中,为了对立交桥进行定位,对DBSCAN算法做了以下改进:
1)为了提高聚类质量,对直接聚类和合并聚类的半径设置了不同的参数.聚类半径为所有点到核心点的空间距离阈值.如果半径设置很大,则相邻的密度较大的簇将有很大概率被合并为同一个簇,它们之间的差异将被忽略;如果半径设置过小,则一个相对比较稀疏的簇可能被划分为多个相似的簇.因此为了减少距离阈值造成的差异,对直接聚类半径(eps1)和合并聚类半径(eps2)分别进行设置.
2)北京市的市中心区域与周边区域的立交桥密度差异很大,而DBSCAN算法不适合反映密度变化较大的数据集,因此采取的办法是将北京地图分为两部分:市中心区域和周边区域.以不同的密度来对这两类区域分别进行聚类.如图6,市中心区域在粗线边框内部,定义纬度区间为39.843到39.925,经度区间为116.250到116.465.周边区域则在其外部(粗线边框与细线边框之间),这样划分能够很好地将市中心区域和周边区域的不同密度的立交桥分开,同时又能避免对立交桥本身的切割.
4.1.2 去除线形噪声区域
并不是所有的满足密度条件的簇都能构成立交桥,图2所示的是六里桥与丽泽桥之间的西三环南路部分路段.在半径范围内的道路连接点满足了密度条件,但立交桥作为疏导交通的关键区域,是与多条方向各异的主干道相连接的,纵横交错,而不会是这种线形区域.

图2 线形区域Fig.2 Linear area
为了排除满足密度条件的条带状噪声区域,需要对聚类起来的簇判断形状.具体做法是利用线性回归对簇中所有道路连接点拟合出一条直线,如果这些点中最远的点到直线的距离小于一定距离,则取消此聚类.每一个簇中的点集被记作:{(lati,loni),i=1,2,…,n},其中lati代表坐标点的纬度值,loni代表经度值.在本文中线性回归公式为
slope*lat-lon+intercept=0
(1)
其中slope代表拟合直线的斜率,intercept代表截距.线性回归通常是根据各点与回归直线的接近程度来判断相关关系的强弱,当各点很接近回归直线时,两变量的相关关系越强,反映在地图上则越接近为条带状区域.由于每个簇中点的数量不同,位置分布也不同,无法给所有簇定义一个统一的相近点数量来判断是否是条带状区域.本文的解决办法是计算簇中各点与回归直线的距离d,若所有点到直线的距离都小于距离上限,则该簇为条带状区域,取消该簇的聚类.其中簇中某一个坐标点(lati,loni)到回归直线的距离d的计算公式为
(2)
经过以上的聚类处理后,便可以有效确定立交桥的位置了.
4.2 立交桥路口范围划分
4.2.1 计算凸包
事实上,立交桥并非圆形,而是不规则的多边形区域,因此需要进一步计算立交桥的路口范围,为此本文将利用Jarvis步进法[25]来计算每一个簇中的坐标点所组成的凸包.算法思路如下:
1)建立坐标轴,X轴代表经度轴,Y轴代表纬度轴.
2)纬度最大的前提下,尽量使经度最小的点,记为A点.
3)以A点为起始点,X轴正方向射线顺时针扫描,找到旋转角最小时扫描到的点,记为B点.
4)以B为起始点,AB方向射线顺时针扫描,找到旋转角最小时扫描到的点,记为C点.
5)以此类推,直到找到起始点A.
4.2.2 路口范围修正
只由聚类后的道路连接点组成的立交桥路口仍然存在范围过小或过大的问题,需要进行修正.
1)修正范围过小的立交桥:道路连接点是道路的起点和终点,它们的连线并不一定能完整地覆盖整条道路,尤其是弯曲的道路.如图3(a)显示的公主坟区域,只有道路连接点的凸包算法并不能完整地覆盖立交桥.OpenStreetMap数据库中对于道路的划分粒度已经很细,但通过对道路表中的the_geom字段进行分析,发现道路标识除了起点和终点以外,还包括道路中的折线点.示例字段如下:(′LINESTRING(116.4645492 39.9530732,116.4645886 39.952977,116.4650889 39.9512556)′,).字段中除了起始点位置的坐标,其余坐标均为折线点.如图3(b),加入折线点之后计算凸包,便可以解决道路连接点覆盖范围不全的问题.

(a) (b)
2)修正范围过大的立交桥:有的道路连接点构成的路口范围明显过大,为了将立交桥限制在一定范围内,首先去掉了连接低等级道路的点.然后计算了每个簇的质心,并设置区域半径限制为600米,删除了距离质心超过600米的点.
5 路口计算精度优化
在路况计算中,本文利用同一辆车通过路口前后的轨迹点信息来精确推导相关道路和路口的路况,通过与行程时间分配算法[12]相结合来进行路况计算精度的优化.行程时间分片算法将道路路口视作虚拟路口,根据历史的道路行驶时间或转向时间在历史总时间中所占的比重,对真实的行驶时间进行加权分配,得出当前道路行程时间和道路转向时间.该算法可以处理两轨迹点间跨越多条道路的情况,将一部分道路路况分离到路口.
5.1 立交桥路况计算模型
行程时间分配算法对普通路口具有较大适用性.但由于立交桥的道路结构复杂,车辆不仅在立交桥内的道路匹配存在较大的不确定性,而且道路划分粒度细,将立交桥内一条道路划分成多段道路并设置多个路口是不合适的,会影响路况计算的精度.为了正确探测立交桥的路口路况,本文将立交桥抽象为一个路口,单独计算立交桥各个方向的转向时间.本文将立交桥转向时间定义为车辆从进入立交桥前到驶离立交桥后的时间差.
如图4所示,多边形区域代表立交桥,第4节中已经划定了路口范围,并存储了属于立交桥的道路,需要注意的是立交桥的范围实际上是不规则区域,而不是圆形区域.它连接了多个方向的道路,因此有多个不同的转向时间.以图4中从右向左行驶的车辆为例,真实行驶时间为TR1+TR1,R2+TR2,其中TRi代表车辆在道路Ri上的行驶时间,TR1,R2代表车辆经过立交桥的转向时间.这样的道路模型可以忽略立交桥内部复杂的道路细节,只需计算立交桥外的道路速度,即可获得转向时间,并且还可以避免当车辆处于立交桥内部时引起的道路匹配错误,进一步提高精度.以图4为例,对于每一条车辆轨迹,记录该车辆进入立交桥前的连续两个轨迹点和驶离立交桥后连续两个轨迹点.当探测出车辆驶离立交桥后的第二个轨迹点时,开始计算立交桥的路况,需要注意的是,轨迹采样率低,连续两个轨迹点很少在同一条道路上,因此按以下两种条件的道路速度来计算车辆在立交桥的转向时间.
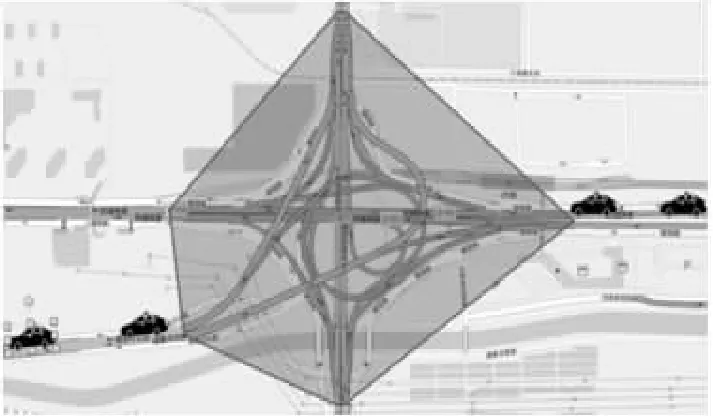
图4 立交桥路况计算模型Fig.4 Calculation model of overpass traffic situation
1)如果立交桥外的一端有连续两个轨迹点,其所在的道路路由之间没有红绿灯,且不在其他立交桥内,则将两个轨迹点之间经过的道路连接成一条道路,并将两轨迹点间道路间转向时间置为0,并可由立交桥外轨迹点的位置及时间戳计算两个轨迹点间的道路速度,两个轨迹点之间经过的道路被记作R1,…,Rn,轨迹点在所在道路的道路覆盖率为fi,其长度记作LR1*fi+LR2+…+LRn*fi,时间间隔记作T,则两轨迹点间所有道路速度VRi的计算公式为
(3)
2)如果不满足1,则立交桥外的道路速度使用行程时间分配算法计算出的道路速度.
5.2 路口处的路况计算优化
将复杂的立交桥抽象为一个路口后,便可以充分利用轨迹点经过路口前后的信息来对路况计算进行优化了.需要注意的是,为了减少车辆异常缓慢行驶或停靠的影响,行程时间分配算法引入了速度平滑影响因子α,使用历史速度vpre对当前探测速度进行平滑.本文为了最大限度地探测出路口路况,根据路口前后的车辆数目分了4种场景进行计算,如图5所示,本文对不同场景下推导出的道路速度v,通过设置不同的影响因子α,按(4)来计算新的道路速度vnew.具体影响因子的设置见表1.
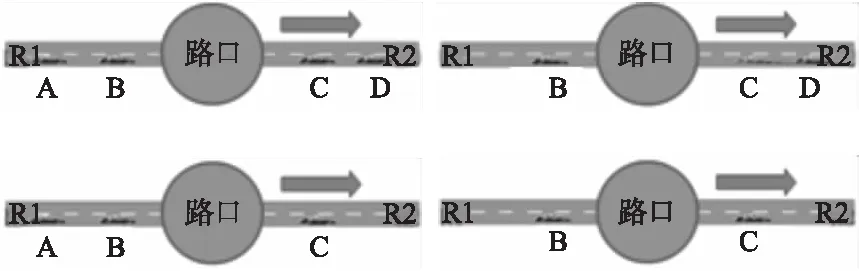
图5 4种场景下的路况计算Fig.5 Calculation of road conditions under four scenarios
α=0.9-|seqcur-seqpre|*0.1
vnew=vpre*α+(1-α)*v
(4)
1)同一辆车在路口前后的道路上各有两个轨迹点,这时路口附近的的道路速度由前后道路上连续两个轨迹点的位置及时间戳计算得出,此时以此路况为准,其可信度为100%,因此历史路况影响因子为0.这种情况下的转向时间的计算相当精确,第6节对此场景下的立交桥路口路况进行了验证.
2)同一辆车在路口前的道路上有一个轨迹点,路口后的道路上有两个轨迹点,此时路口前的道路速度根据行程时间分配算法计算得出,其可信度为50%,路口后的道路速度仍旧由两个连续的GPS点计算得出,其可信度为100%,因此转向时间可信度为75%,设置历史路况影响因子为0.25.
3)同一辆车在路口前的道路上有两个轨迹点,路口后的道路上有一个轨迹点,此时路口后道路速度可信度为50%,路口前的道路速度的可信度为100%,因此转向时间可信度为75%,设置历史路况影响因子为0.25.
4)同一辆车连续两个轨迹点间只跨越单个路口并且路口前后的道路只有一个轨迹点时的情况,利用行程时间分配算法在该时间片的道路速度,计算出路口的转向时间,转向时间可信度为50%,设置历史路况影响因子置为0.5.
表1 4种场景
Table 1 Four scenarios
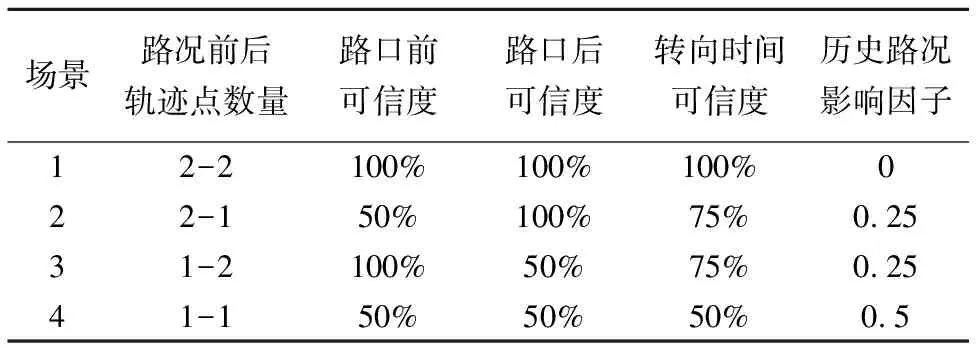
场景路况前后轨迹点数量路口前可信度路口后可信度转向时间可信度历史路况影响因子12-2100%100%100%022-150%100%75%0.2531-2100%50%75%0.2541-150%50%50%0.5
而对于同一辆车的相邻轨迹点跨越多个路口的情况,仍旧按行程时间分配算法[12]进行路况计算和更新.为了与行程时间分配算法相结合,本文还对立交桥的路口转向时间进行了处理,设置了立交桥内的道路标准速度,然后将剩余的转向时间平均分配到了立交桥内的道路之间.由于本文融合了行程时间分配算法,历史路况对当前路况会产生影响,因此当前时间片的路况也会对后续时间片的路况计算起到积极的修正作用.
6 评估与分析
这部分首先介绍了聚类算法的参数设置以及最终聚类的效果,然后通过处理北京市2.7万辆出租车的轨迹数据,验证了改进的路况计算优化方法的效果.实验使用的地图数据来源于OpenStreetMap的北京市地图.地图区域的纬度区间为39.68~40.18,经度区间为116.08~116.77,大约16400平方公里.
6.1 聚类算法的参数设置及最终聚类效果
DBSCAN算法对参数十分敏感,细微的不同都可能导致结果差别较大,而参数的选择只能靠实验与观察确定.改进后的DBSCAN算法需要设置4个参数,直接聚类半径(eps1)、合并聚类半径(eps2)、最小包含点数(minPts)、点到拟合直线的距离上限(dist).表2为市中心区域和周边区域中各参数的设置.由表2可以看出市中心区域比周边区域各项参数都要高,从而也印证了立交桥在不同区域的密度差异很大,对区域的划分是必要的.
如图6所示,本文将计算凸包的过程放在立交桥路口范围修正之后,有效地定位了立交桥并划定了路口范围.
表2 聚类算法的参数设置
Table 2 Parameter setting of clustering algorithm

区域直接聚类半径合并聚类半径最小包含点数点到拟合直线的距离上限市中心20022080.0006周边500500120.001
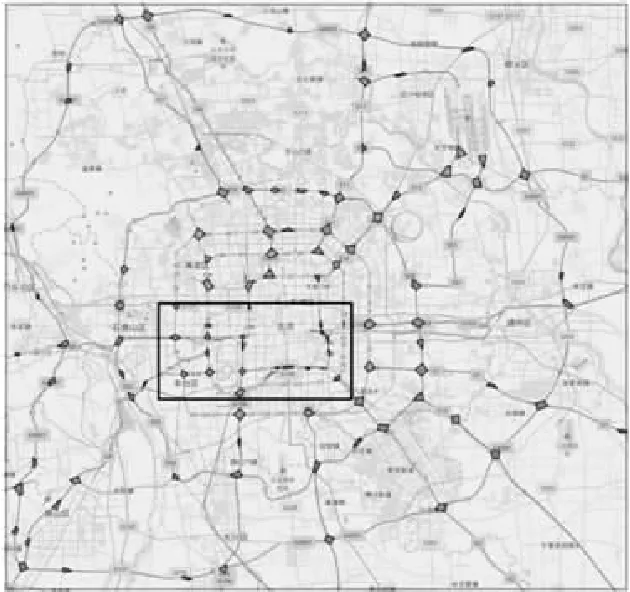
图6 立交桥及其路口范围Fig.6 Overpass and it′s intersection range
6.2 路况计算效果
6.2.1 立交桥局部路况计算效果
在立交桥路口前后各有两点的条件下,本文对一天中经过立交桥车辆进行了随机采样,用车辆进入立交桥前的最后一个轨迹点和驶离立交桥后的第一个轨迹点的时间差作为真实的行驶时间,对基于行程时间分配算法和路况优化算法进行了对比.结果如表3所示,在立交桥路口前后各有两点这种
表3 局部行驶时间对比
Table 3 Comparison of local running time
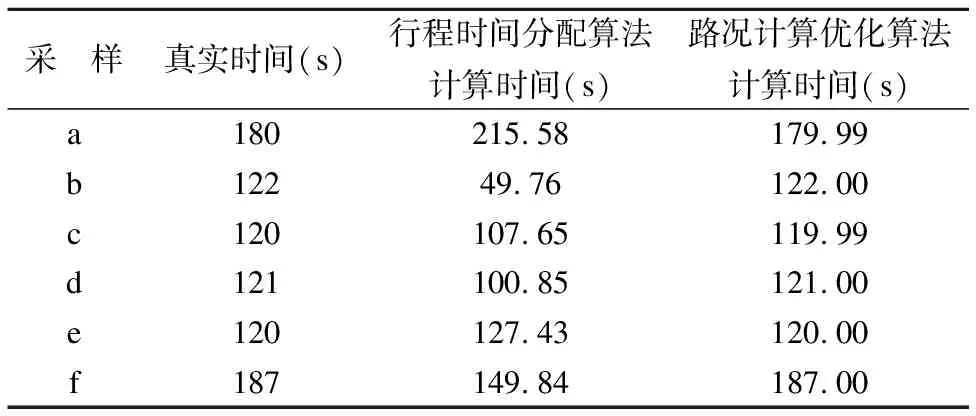
采 样真实时间(s)行程时间分配算法计算时间(s)路况计算优化算法计算时间(s)a180215.58179.99b12249.76122.00c120107.65119.99d121100.85121.00e120127.43120.00f187149.84187.00
数据量最完整的情况下,路况计算优化算法最为准确,计算效果最好.
6.2.2 北京市路况计算优化效果
为了计算探测出的路况精度,并且减少出租车异常行驶行为的影响,实验选取了北京市4月14日6:00~23:00行驶时间大于10分钟且处于载客状态的出租车进行测试,共有27239条轨迹.本文将匹配后的轨迹中第一个点与最后一个点的时间差值作为真实的车辆行驶时间.然后分别计算了基于行程时间分配算法的估计时间和改进的路况计算优化算法的估计时间,并将估计时间与真实时间进行比较,得出错误率(Error rate).错误率的计算方法来自于[12],计算公式为
(5)
由图7可以看出,改进的路况计算优化算法在0%~15%错误率的数量上相比于行程时间分配算法有大幅增加,而在15%~100%错误率的数量比基于行程时间分配的数量则都要少.路况优化算法比行程时间分配算法平均降低了4.32%的错误率,从16.56%降到了12.24%.其中经过立交桥的车辆的错误率由16.02%降到了10.99%,这种情况占到了69.09%,即一天中大多数车辆的行驶路径都会经过立交桥.而车辆不经过立交桥,只在普通道路行驶的错误率由17.76%降到了15.02%,因此也说明了将立交桥抽象为一个路口并进行路况计算优化的处理是必要的.
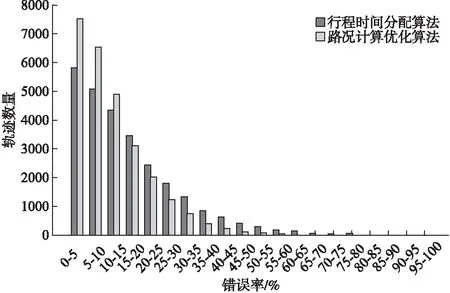
图7 错误率柱状图Fig.7 Error rate histogram
表4显示的是累积的错误率表,从表4中可以看出,路况优化算法可以将51.51%的轨迹的路况错误率限制在10%以内,且99.06%的轨迹的路况错误率不超过50%.实验结果表明优化算法有效提升了路况计算精度.本文还对错误率超过80%的车辆轨迹进行了分析,其错误率较高的原因在于车辆的异常停止和部分轨迹点的道路匹配错误.
表4 累积错误率表
Table 4 Cumulative error rate table

错误率行程时间分配算法路况计算优化算法10%40.17%51.51%20%68.82%81.19%30%84.58%93.38%40%92.87%97.68%50%96.63%99.06%
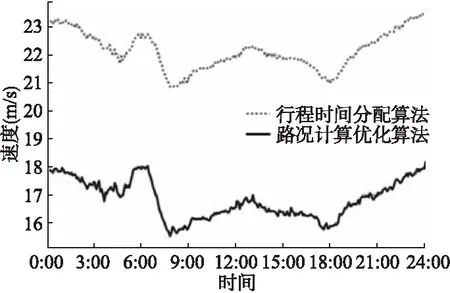
图8 所有道路的平均速度Fig.8 Average speed of all roads
图8显示了所有道路的平均速度.本文认为行程时间分配算法[12]存在系统性偏差,探测出的道路速度总体偏快,在使用改进的路况计算优化算法后,道路速度普遍降低.但道路速度曲线的变化趋势是基本一致的,在早高峰和晚高峰时道路速度都会有所下降.
7 结束语
本文针对复杂城市道路场景下,以低采样率车辆轨迹为数据来源的路况计算精度较差的问题,考虑到立交桥的影响,将立交桥抽象为一个路口,利用改进的DBSCAN算法和Jarvis步进法对其进行了自动化定位和划定其路口范围.并充分利用到了路口前后的车辆位置信息,通过精确推导相关道路和路口的路况,设计了一种改进的路况计算优化算法,相比于行程时间分配算法,有效提高了路况计算精度.
在路况计算中使用平滑因子对异常低速行驶或临时停车行为进行了抑制,但当道路上缺少足够的车辆数据时,系统就无法识别这两种异常行为,路况计算精度会受到一定影响,因此本文还有可以进一步改进的地方.另外通过与高采样率车辆计算出的路况数据相结合等也是提高路况计算精度的一个有效方法.
