标签约束的半监督栈式自编码器分类算法
2019-03-13王晨妮张雨轩
李 炜,宋 威,2,3,王晨妮,张雨轩
1(江南大学 物联网工程学院,江苏 无锡 214122) 2(江南大学 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122) 3(物联网技术应用教育部工程研究中心,江苏 无锡 214122)
1 引 言
自2006年以来,以自编码器(Auto-Encoder,AE)[1]为代表的深层特征表示学习[2]在机器学习领域取得了突破性的进展,这些进展主要应用深度学习进行模型初始化[3].当前针对不同的应用场景,一些AE正则化方法被学者们提出:稀疏自编码器(Sparse Auto-Encoder,SAE)[4,5]是Bengio于2007年提出,要求隐含层神经元的激活度满足一定的稀疏性;降噪自编码器(Denoising Auto-Encoder,DAE)[6,7]是由Vincent等于2008年提出的,是对输入向量加入干扰,训练编码器重构出原始输入,使网络具有更好的鲁棒性;压缩自编码器(Contractive Autoencoder,CAE)[8,9]是Bengio等人在2011年提出,用于获取鲁棒性的中间层特征.虽然无监督预训练[10]可以获得数据更有效地语义表达而使优化过程更加有效.然而,上述的AE的演变算法只是基于特征数据表示,而没有考虑过预训练阶段的标签信息,因此所得的特征鉴别性能较差,不能达到理想的分类结果[11].
无监督特征学习从数据本身进行分析,通过多层预训练有效提取出不同抽象级别的特征来表示数据,但由于标签信息的广泛缺乏,导致提取的特征不能描述特定类别,因此很难应用于分类.监督学习就可以很好地解决这个问题,它通过计算实际输出标签与期望输出标签的误差,反馈调整网络参数,从而减小标签误差,标签信息的使用能提取出适用分类的特征,但学习到的特征不能很好地表示原始的数据,泛化能力弱,很容易产生过拟合问题.
为了提取出鉴别性高同时表示性能好的数据特征,综合无监督学习和监督学习方法的优势,本文中提出了一种标签约束的半监督栈式自编码器(a label regularization semi-supervised stacked autoencoder,LSSAE),结合监督学习中反映标签的鉴别性特征和无监督学习表示性特征来捕捉数据特点,再进一步将这些特征用于分类.事实上,本文标签约束利用监督学习提高分类的准确率,标签约束项无需事先假设数据分布,避免了假设分布不准确的问题,同时它不仅可以预测类别,还可以得出各类近似几率.因此本文提出的LSSAE不但可以有效地从大量数据中提取潜在兼有鉴别性的本质特征,还有助于提高分类的准确度.
为了验证我们提出方法的有效性,我们在USPS数据库*http://www. datatang. com/data/11927 [EB/OL].等5个公开数据集*http://archive.ics.uci.edu/ml/datasets.html上做大量的实验.我们将本文提出的LSSAE方法与AE,SAE、MPN[12]和DBN[13]等算法做比较,实验结果表明LSSAE具有更好的分类准确性.
2 相关工作
2.1 栈式自编码器

在AE中需要调整的参数是θ={W,b,W′,b′},其中b和b′是编码和解码的偏置,W和W′是编码和解码的权重,W′是W的转置.通常采用梯度下降法[16]获得最优值作为参数θ.与有着较大的人工数据特征提取工作量的传统的BP神经网络[17]相比,AE可以提高特征提取的工作效率,减少原始输入数据的维数,还可以很好地学习到给定数据集的压缩和分布式特征表示.
AE是栈式自编码器的基本组成模块,将训练完成的AE层叠起来,构成具有逐层的特征提取能力[18]的栈式自编码器,在网络顶层添加分类器,通过标签误差,自顶向下利用反向传播(back propagation,BP)算法[19]微调整个网络,使栈式自编码器能很好的进行分类或预测任务.
2.2 Softmax分类器
将栈式自编码器用于分类领域,则需要在网络最后一层加入分类器.为使网络应用领域更为广泛,本文使用Softmax分类器来进行分类.
对于训练集合{(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m))},标签y取k个不同值,表示k个类别.设p(y=j|x)表示输入x的前提下,样本被判定为类别j的概率.因此对于一个k类分类器,分类结果为一个k维向量,分类结果为
(1)

(2)
上式中:1{·}为指示函数,即1{值为真的表达式}=1,1{值为假的表达式}=0.本文使用小批量随机梯度下降算法来最小化代价函数.
3 标签约束的半监督栈式自编码器
本文提出了一种标签约束的半监督栈式自编码器算法(LSSAE),算法中无标签样本的无监督学习可提高半监督栈式自编码器学习的泛化能力,有标签样本的监督学习可提升半监督栈式自编码器模型的分类准确度.
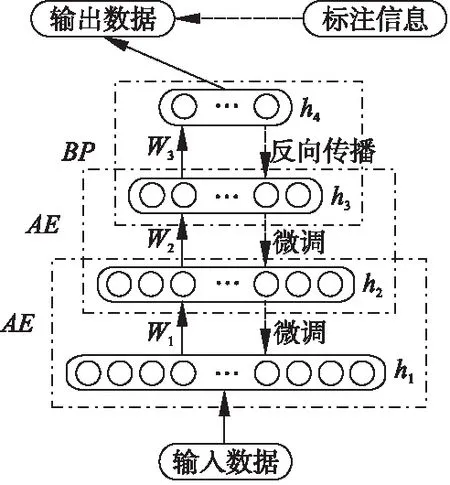
图1 栈式自编码器训练模型Fig.1 Stacked autoencoder training model
在栈式自编码器预训练过程中加入标签误差项,以减少训练数据的实际输出标签和期望输出标签之间的误差为目标,从而弥补无监督学习分类准确度较低的缺陷.然后将所学到的特征表达输入分类器中,分类结果验证了所提出的半监督栈式自编码器的有效性.图1显示的是LSSAE用于分类的框架.LSSAE的代价函数由JAE,Jwd,Jlabel三部分组成.其中,JAE是通过无监督学习计算的输入与输出数据的重构误差项,网络最小化JAE使得输入数据尽可能地接近输出数据,从而更准确地重构出输出数据.Jwd是为了减小权重的幅度计算的权重二范数正则项,用于防止过度拟合.而Jlabel是通过监督学习计算的实际标签与期望标签的标签误差项,通过使误差项最小化调整网络参数,因此,JAE和Jwd通过无监督学习获得,Jlabel通过有监督学习获得.本文提出的半监督自编码器LSSAE结合了非监督和监督学习的优点,并利用各自对应的约束来调整权值和偏置,提取出数据的特征表达,并结合Softmax分类器,通过构建具有高准确率与高泛化能力的半监督深层学习网络,进一步实现分类应用.

图2 LSSAE训练框架Fig.2 LSSAE training model
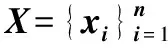
(3)
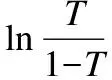
(4)
那么LSSAE的目标函数如下
JLSRAE=αJAE+βJwd+γJlabel
(5)

(6)
用梯度下降法来优化目标函数,更新W和b公式如下:
(7)
(8)
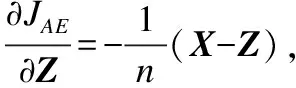
(9)
(10)

(11)
(12)
(13)
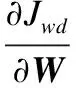
(14)
(15)
综合以上重构误差,权重衰减项和标签误差项的偏导数,我们可以得到LSSAE的目标函数JLSSAE的偏导数为
(16)
(17)
4 实验结果与分析
4.1 实验数据集
为了验证本文所提出方法的有效性,将提出的LSSAE与AE、SAE、DBN等在几个公开数据集上进行对比实验,然后应用到softmax分类器完成分类.数据集主要包括5个公开数据库,分别为USPS、PenDigits、Coil20、OptDigits、ORL.具体数据信息如表1所示.
4.2 相关配置
本论文中实验的开发环境为Matlab2014a,计算机系统配置如下:CPU 为 Intel(R)Core(TM)i3-4170;主频为 3.70 GHz;内存为 4GB;操作系统为Windows10 64位.
4.3 实验结果分析
LSSAE算法有参数α,β和γ,这三个参数用于控制目标函数中各项的相对重要性.本文对这些参数进行讨论,将这些参数以{1×10e| e =-5,-4,-3,-2,-1,0,1,2,3}的规则变化.图3讨论了LSSAE在PenDigits数据库上的参数α在{0.00001,0.0001,0.001,0.01,0.1,1,10}时,LSSAE达到最优的情况,图3中每张图表示不同γ值的变化范围.从图3不难看出,当α=0.00001,β=0.001,γ=0.1时,LSSAE达到最优分类结果,三个参数的量级差是为了调整三组惩罚项趋于同一数量级.
表1 数据集的规格
Table 1 Dataset format
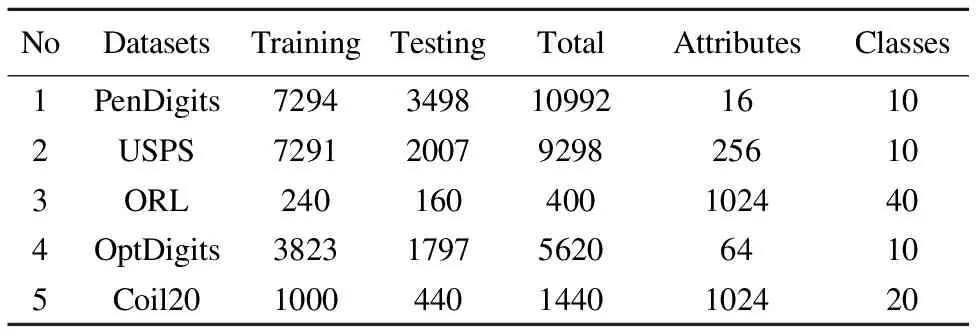
NoDatasetsTrainingTestingTotalAttributesClasses1PenDigits729434981099216102USPS729120079298256103ORL2401604001024404OptDigits38231797562064105Coil2010004401440102420

图3 不同α,β,γ下LSSAE的分类情况Fig.3 LSSAE classification under different α,β,γ
为公平比较,对比网络的结构都对应相同,参数讨论得出了使得模型分类情况最佳的参数,下一步将研究隐含层层数对性能的影响.本文首先为每个测试数据集确定最佳的模型参数,而后在固定其他参数的前提下讨论网络层数.图4显示了Pen Digits、USPS、Opt Digits数据集的分类情况.
从图4(a)可看出当隐含层为2层时,整体网络为4层,LSSAE用于分类的准确率已达到一个相对平稳的状态,准确率超过99%,同样在(b)(c)子图可以看出,LSSAE均在双隐含层下得到最优结果且明显高于其他算法,不论隐含层层数为多少,LSSAE在两数据集下的分类准确率分别始终保持在96%和97%以上.
表2中显示了各分类算法在Pen Digits,USPS,ORL,Opt Digits以及Coil20数据集上的分类情况,每个数据集上均进行20次实验取均值.其中,每组数据的前一项对应平均分类准确率,后一项对应了准确率波动方差.通过表2可以看出LSSAE算法在各数据集上的分类准确率波动均较小,少量实验结果波动大于DBN及MPN,但是LSSAE的平均分类准确率高于DBN、MPN等其他算法,因此LSSAE在分类问题上的表现优于其他算法.
表2 各数据集分类准确率(%)
Table 2 Accuracy of different datasets classification(%)

Datasets MPNAESAEDBNLSSAEPen Digits88.92±0.2192.87±0.6393.35±0.7394.55±0.7398.91±0.44USPS93.27±0.1394.38±1.0794.42±0.9194.69±0.6797.25±0.37ORL92.33±095.67±0.8296.02±1.5796.54±098.28±1.32Opt Digits95.24±0.9895.41±1.2695.90±1.1496.28±0.5898.53±1.08Coil2089.14±093.75±1.0395.07±0.6996.42±097.92±0.95
5 结束语
本文将标签正则化加入到栈式自编码器中提出一个半监督栈式自编码器(LSSAE).单独使用重构约束项没有用到目标信息而不利于分类,单独使用标签项导致学习到的特征不能很好的表征原始数据,泛化能力较差,模型容易过度拟合.因此为综合发挥无监督学习与监督学习的优势,利用逐层半监督训练对自编码参数和分类参数进行共同优化,以达到保留数据本质特征且保证模型泛化能力的同时,又可以实现较好分类效果的目的.
