网络化测试系统中并行数据处理架构的实现*
2019-03-12刘兆庆于洪彬梁洋洋梁军
刘兆庆,于洪彬,梁洋洋,梁军
(哈尔滨工业大学 电气工程及其自动化学院,黑龙江 哈尔滨 150001)
0 引言
网络化测试系统在武器装备测试、核爆炸试验、航空航天测试等领域有着广泛的应用[1]。实时性是网络化测试系统面临的主要问题之一[2]。除了采用高性能测试仪器和高速通信网络外,测试数据的处理是影响系统实时性的关键。
目前,网络化测试系统中大多采用集中式数据处理方式。在该方式下,数据全部存储在主控计算机,由数据库管理系统进行统一管理,主控计算机承担所有测试数据的计算、综合和处理任务。集中式数据处理方式对计算机的性能要求较高,骨干网络带宽压力大,测试数据在数据库中的查询时间变长,数据处理时效性差[3]。随着测试系统规模的增大,这些问题越来越凸显出来。
在不投入更多硬件资源的情况下,为了提升网络化测试系统的实时性,必须充分挖掘系统内的计算资源并设计相应的数据处理模式。由于嵌入式技术在仪器领域的应用不断模糊着计算机与仪器的界限,智能仪器大多有独立的CPU、内存、硬盘、网络接口等一系列资源,具有一定的数据处理能力。而且随着并行处理或分布式处理技术支持的日渐成熟,将仪器资源共享出来,联合多个仪器资源,在主控计算机的管理调度下,协同地进行部分或全部数据处理任务,使数据处理任务以一种空间并行的方式在仪器节点本地运行,存在着降低时延,提高系统实时性的可能。这种方式有利于实时性的根本原因在于以下2点:
(1) 利用并行方式的可扩展性引入更多计算资源加入进数据处理任务;
(2) 数据传输以局部传输为主,避免了集中式处理僵硬的数据传输模式。
在利用仪器资源进行数据处理应以不牺牲测试任务的执行性能为前提,这要求在仪器上引入隔离技术。本文设计了一种基于仪器资源的并行数据处理计算架构。在该架构下,在主控计算机根据数据处理任务的资源需求,为任务分配满足资源需求的物理节点;在仪器节点上,使用隔离技术,将任务进程限制在特定的资源上。构建并行数据处理平台,利用并行FFT(faster Fourier transformation)应用验证数据处理架构的可行性,分析了该模式的计算性能和在这种计算模式下进一步提升数据处理效率进而提高系统实时性的关键因素,为后续研究指出了研究方向。
1 并行计算模式和平台构建分析
文献[4]指出了在一个分布式系统上构建计算平台的要解决的一般问题:
(1) 管理系统中多种硬件资源;
(2) 定义用户可以发现、请求和使用资源;
(3) 实现在资源上并行计算的执行。
目前,尚未查找到基于嵌入式仪器进行并行计算平台的构建方案。本文将根据网络化测试系统简洁、高效、实时的应用需求,结合现有并行技术、集群技术及隔离技术的技术支持,设计适宜在网络化测试系统的平台构建方案。文献[5]提出了一种基于MPI(message passing interface)的云计算模型,该模型替换了Hadoop中的MapReduce编程模型,实现了在MPI计算平台上的云计算。文献[6]提出了利用MPI构建云计算的非虚拟化平台,利用MPI对异构环境的支持,直接在异构环境上构建MPI集群,避免了虚拟化的性能损耗,并进一步在对MapReduce的替换、多级容错机制等方面进行了研究。文献[7]实现了在Docker容器上部署MPI集群用于高性能计算。MPI是一个高性能的消息传递模型,在注重时效性的并行计算中有着广泛应用。但以上都是以云计算为应用环境展开的,在网络化测试应用环境中存在着不适宜。
对于硬件设备的处理主要由2种处理方式——非虚拟化技术和虚拟化技术。非虚拟化技术应用以网格计算为代表,直接对物理资源进行管理,按照批处理方式对资源进行调度。虚拟化技术以云计算为代表,对底层硬件使用虚拟化技术构成虚拟资源,在虚拟资源上以数据为驱动进行调度。
网络化测试系统中的计算平台构建应强调高效实时。智能仪器相对于PC来说资源有限,虚拟化技术的性能开销较大,影响节点计算性能和通信性能。非虚拟化技术会保留原有硬件性能,通信性能更好,有利于系统的实时性要求。网络化测试系统中的并行数据处理不宜构建虚拟化的计算平台。因此,资源的管理调度应以具体物理硬件为基础,作业资源需求通过资源参数或属性描述直接定位到具体物理节点。这可以通过本地的资源管理器实现[8]。
事实上,虚拟化技术在构建统一资源类型的同时也实现了资源的隔离与控制。虚拟机由于Hypervisor的存在,在获得良好隔离性的同时产生了很大的系统开销。LXC(Linux containers)和Docker是轻量级虚拟化技术,在云计算中具有广泛应用,是满足云计算环境需求的技术架构,但对于网络化测试系统存在冗余封装。LXC基于Linux内核Cgroups和Namespace构建,Cgroups进行资源管理,Namespace用于安全隔离[9-10]。本文直接调用Linux的Cgroups内核支持,实现对计算任务的资源控制。
综上所述,本文将采用本地资源管理器实现系统资源的管理分配,采用Cgroups实现仪器节点资源的隔离与控制,采用MPI消息传递模型构建计算平台。
2 适用于网络化测试系统的计算资源模型
在分析了网络化测试系统体系结构的基础上,本文提出了一种双层资源模型,用来解决网络化测试系统中的资源问题。
双层资源模型如图1所示。在系统的层面上,主控计算机管理系统中所有仪器节点及其附带的资源属性。服务中心是系统的核心,作为全局的用户的唯一接口,可以对系统进行查询、配置,提交计算任务、进行任务状态监测。调度中心根据计算任务提出的资源属性需求,按照可插拔式的调度策略配置,以物理仪器节点作为基本单位,从系统中选出可以满足计算需求的节点集合,给出任务运行的节点建议。
在仪器节点上,将计算所需的资源(CPU、内存等)以一定的形式联合起来,构成资源容器,计算进程仅可使用容器内的全部资源,从而避免了不同进程间的资源抢占。

图1 双层资源模型Fig.1 Two-level resource model
2.1 顶层资源管理
本文采用TORQUE资源管理器实现位于顶层的面向用户的作业管理和系统资源管理分配[11]。TORQUE是基于PBS(portable batch system)工程的高级开源产品,包含了目前最好的社区版和专业版。它具有良好的可扩展性、稳定性和功能性,因此在全世界的政府、科研、商业领域有着广泛应用[12]。由于TORQUE可以免费被使用、修改、发布,为后续进一步研究开发提供可能,本文采用TORQUE社区版作为资源管理器。
通过在网络化测试系统中布置TORQUE,可以达到以下目的:①以节点为基本资源单位,将节点具有的资源和特性进行定义或统计。②根据资源或特性需求,为作业找到合适节点运行。③使作业按照创建、提交、执行、结束的工作流运行,通过命令对作业进行监控或控制。
PBS有4个主要部件:命令、作业服务器、作业执行器以及作业调度器。网络化测试系统是多机系统,其中主控计算机性能较强且更为稳定,所以主控计算机中布置服务进程(Server)和执行进程(MOM),负责上述用户服务器的基本功能和部分计算任务。此外,调度进程(Scheduler)运行在主控计算机上,一方面从服务器获取集群系统上的作业信息,另一方面获取本分区节点资源信息。主控计算机作为面向用户的接口,需要布置客户命令。
在仪器节点上布置执行进程,接受来自Server的加载、查询等命令,并负责作业状况的监测以及向Server报告作业结果信息。
PBS组件在网络化测试系统中结构如图2所示。

图2 PBS组件在网络化测试系统中结构Fig.2 Structure of PBS components in net-centric ATS
2.2 仪器资源隔离
Cgroups(control groups)是Linux内核的一个功能,用来限制、统计和分离一个进程组的资源(CPU、内存、磁盘输入输出等),从而实现Linux操作系统环境下的物理分割。在Cgroups中,任务就是系统中的一个进程,控制族群是按照某种标准划分的进程,资源控制都是以控制族群为单位实现的。一个加入控制族群的进程可以使用到为控制族群分配的资源,同时受到以控制族群为单位的限制。一个子系统就是一个资源控制器,Cgroups为每种可以控制的资源定义了一个子系统,比如cpu子系统就是控制CPU时间分配的一个控制器。子系统必须附加到一个层级上才能起作用,层级就是一棵控制族群树,通过在Cgroups文件系统中创建、移除、重命名等操作构建的。
本文主要涉及到计算资源的控制,所以我们只关注系统的CPU资源和内存资源的控制,涉及到Cgroups子系统有cpuset,cpu和memory。将运行进程的进程号分别写入相应子系统下的task文件,即完成了一个硬件容器的划分并将进程限制在该容器内运行。
cpuset子系统为cgroup中的任务分配独立CPU(在多核系统)和内存节点。通过cpuset.cpus和cpuset.mems可分别选择使用的CPU节点和内存节点。
cpu子系统使用调度程序提供对CPU的cgroup任务访问。比如,通过cpu子系统下的cpu.cfs_quota_us调整至cpu.cfs_period_us数值的比例限定了单位时间内使用CPU时间。
memory子系统设定cgroup中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。通过memory.limit_in_bytes限制内存使用量。
多种仪器资源整合与限制如图3所示。
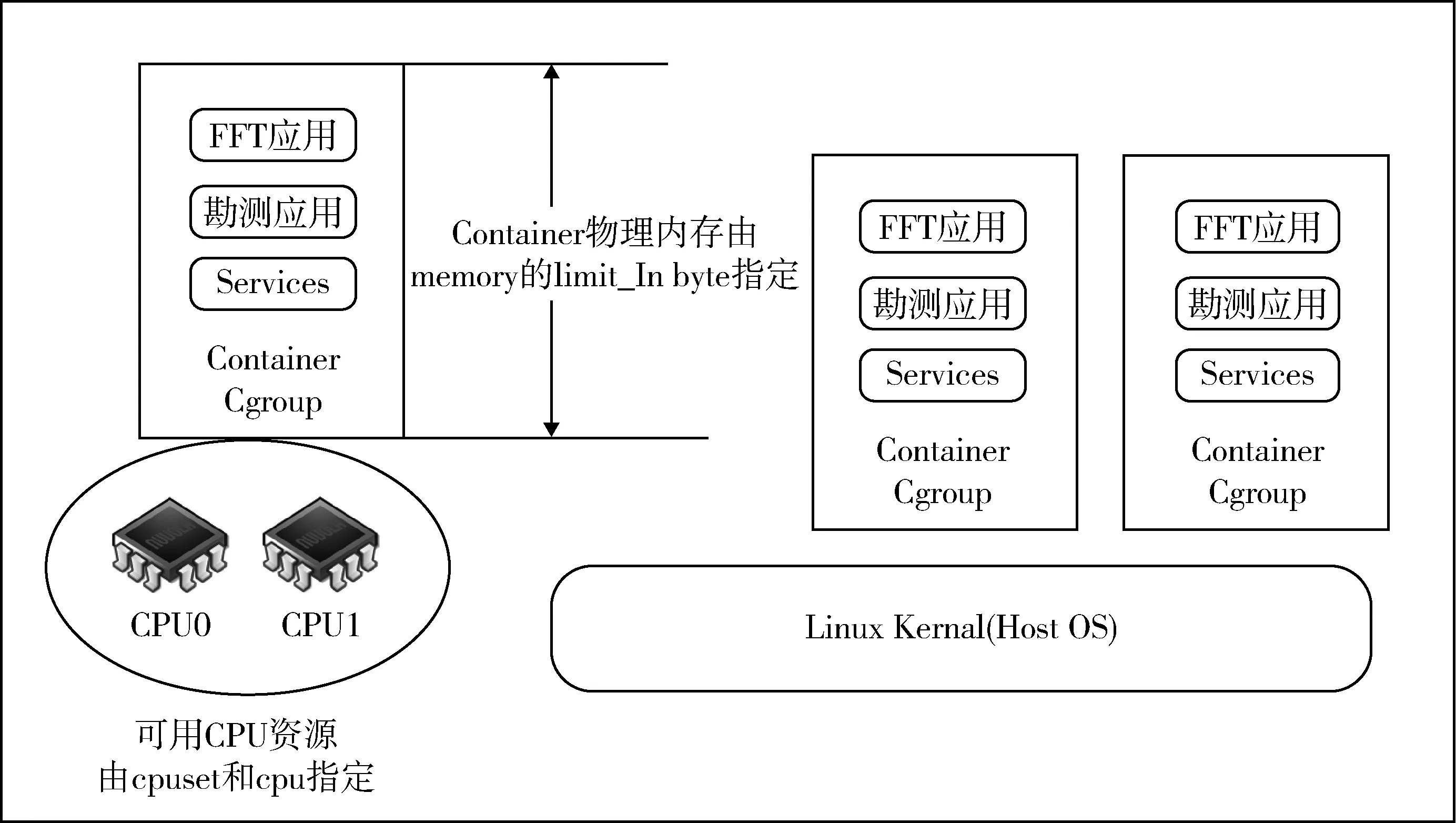
图3 多种仪器资源整合与限制Fig.3 Integration and limitation of multiple instruments’ resources
3 实验验证及结果分析
本文采用1台主控计算机和4块Digilent公司的Zedboard实验载板,通过商用交换机和网线互联,用来模拟网络化测试硬件环境。本文在该硬件平台上,构建了基于MPI消息传递模型的程序开发和运行环境[13-14]。MPI标准的功能通过MPICH和Hydra进程管理器配合实现。通信系统通过一系列网络配置,使用户无需对每个节点进行显示登录操作,屏蔽了底层IP通信,在程序开发时关心的对象是计算进程。进程管理系统在机群上派生计算进程,管理用户参数、环境变量及进程开启节点信息等,并进行进程控制[15]。在此基础上进行并行FFT的MPI程序进行实验验证。
分3种模式进行实验,分别是:①在单一节点读取全部数据,在该节点上进行串行FFT计算,计算结束后,将计算结果上传主控机,在特定文件夹下生成结果文件;②依次在2个、4个节点上展开并行FFT计算,每个节点上数据子向量分别为完整数据文件的1/2和1/4,读取数据,节点间利用本地数据或向其余节点请求各步FFT计算所需数据,完成相应部分的FFT计算,随后计算结果被主控计算机收集并综合生成最终结果文件;③将不同数据规模的完整数据文件拆分在2个节点上,节点读取数据文件被主控计算机收集,由主控计算机按串行方式完成FFT计算。
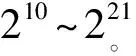
(1) 算法执行时间
图4表示FFT计算的算法执行时间随着数据规模增加的变化情况。横坐标表示采样的数据点数按2的次幂增加,纵坐标表示在不同模式下的算法执行时间,可以得到以下结论:
1) 随着数据规模按2的次幂增加,在数据规模较小时,各种模式下算法执行时间基本相同且约等于0;在数据规模较大时,随着数据规模增大,可以看到执行时间有较为明显的变化且按指数规律增长。
2) 在1节点、2节点和4节点进行计算时,当数据规模较大时,在数据规模相同的情况下,随着计算节点数目的增加,算法执行时间有着明显的减少。

图4 不同模式下FFT计算的算法执行时间Fig.4 Execution time of FFT under different modes
3) 采用主控计算机进行数据收集进行FFT计算的模式下,执行时间小于其他模式的计算。
图5截取数据规模为210~216部分详细展示数据规模较小时的算法执行情况。可以看到,当数据规模较小时,增大并行仪器节点规模不能无限缩小算法的执行时间。如表1所示,2节点并行处理时间在213之前大于单节点处理,4节点并行处理时间在214之前大于其余2种节点计算模式。这是由于并行数据处理的通信开销造成的。

图5 210~216数据规模下算法执行时间Fig.5 Execution time of data scale varying from 210 to 216
(2) 并行数据处理通信时间分析
算法执行时间主要由通信时间和计算时间两部分组成,图6表现了并行数据处理中通信时间占总执行时间比例,横坐标为数据规模,纵坐标为时间百分比。图7表示2,4节点并行数据处理中的通信时间,横坐标为数据规模。结论如下:

表1 210~216数据规模算法执行时间Table 1 Execution time of data scale varying from 210 to 216 s
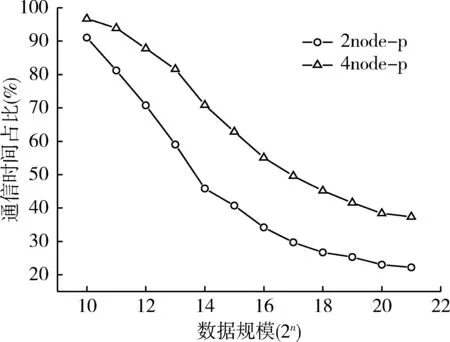
图6 通信时间占并行处理时间的比例Fig.6 Communication time percentage of parallel processing
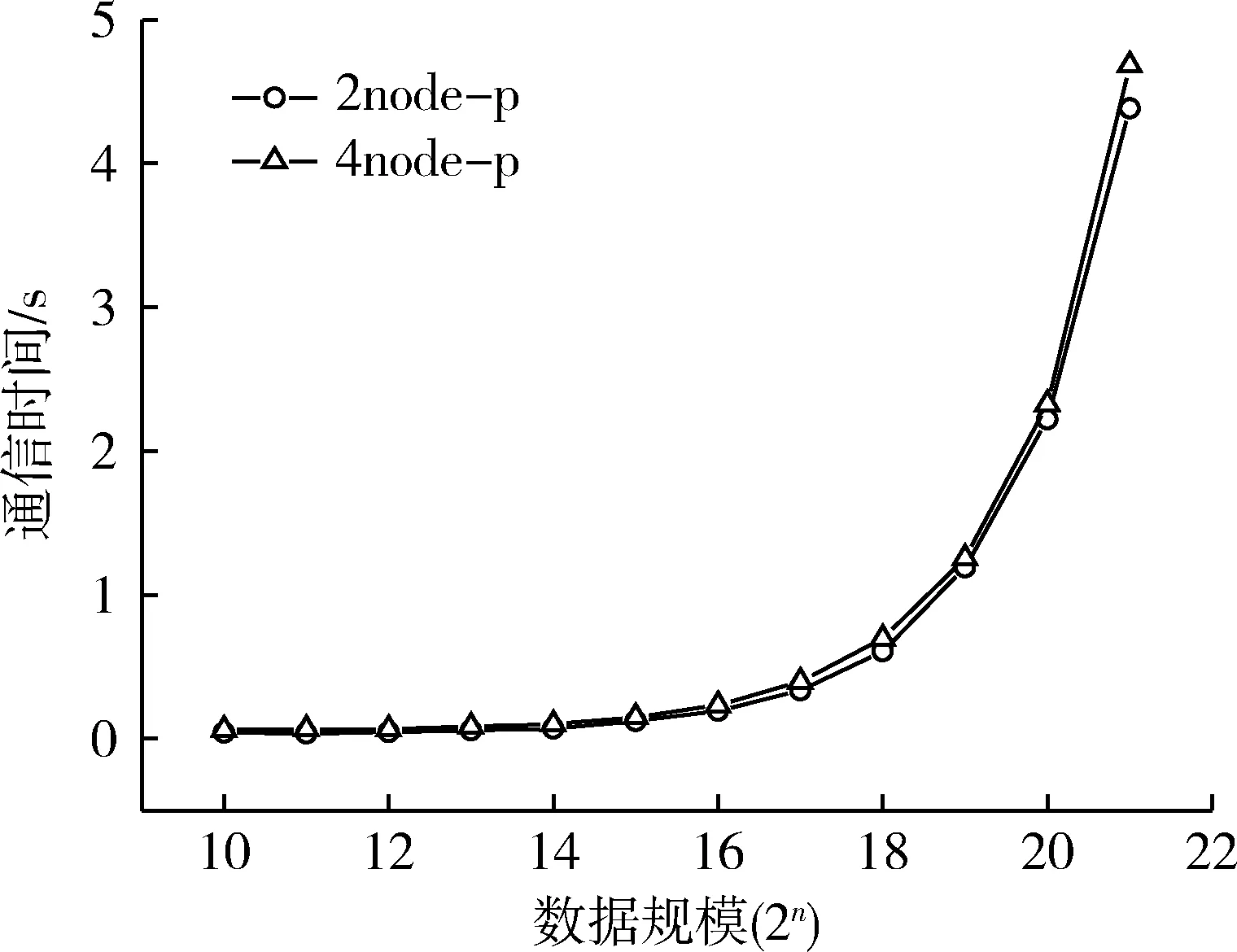
图7 并行数据处理通信时间对比Fig.7 Comparison of communication time between nodes
1) 2种不同模式的并行数据处理的通信时间基本相同,投入更多仪器节点没有明显的减小。
2) 4节点并行的通信时间占比明显高于2节点并行的情况,因为随着投入更多仪器节点进行计算,计算时间有明显的缩减,在通信时间基本不变的情况下,4节点并行的通信占比会更大。
3) 当数据规模较小时,通信时间是主要的时间开销。2节点并行数据规模小于等于213时,4节点并行数据规模小于等于216时,通信时间都占总时间的50%以上。
(3) 加速比与效率分析
加速比(speed-up),是同一任务在单处理器系统和并行处理器系统中运行消耗时间的比率,用来衡量并行系统或程序并行化的性能和效果。
SP=T1/TP,
式中:SP为加速比;T1为单处理器下的运行时间;TP表示在有P个处理器并行系统中的运行时间。
效率(efficiency),它反映了处理器的利用率,P为并行计算机中处理器的个数[16]。
EP=SP/P.
考虑到测试的应用环境,本文的加速比与效率评价中包括了单节点至主控计算机的数据传输时间。图8,9分别表示2节点、4节点并行计算加速比和效率随着数据规模变化的关系。可以得到以下结论:

图8 并行FFT计算加速比随数据规模变化的关系Fig.8 Speedup ratio of parallel FFT algorithm with data scale

图9 并行FFT计算效率随数据规模变化的关系Fig.9 Parallel FFT algorithm efficiency with data scale
1) 加速比随数据规模增加呈上升趋势,但数据规模较大时增速变缓。从图中可以看到4节点并行在221时可达2.8左右(最理想情况为4),2节点加速比可达1.8左右(最理想情况为2)。
2) 效率随数据规模增大呈上升趋势。虽然4节点并行计算相较于2节点可以获得更大的加速比,但2节点的并行效率更高。
3) 数据规模较小时,并行计算的加速比和效率都比较低,这是因为在该情况下通信时间在全部执行时间中所占的比例大。
4) 可以看出,数据通信已是影响系统达到线性加速比的主要因素。
4 结束语
本文设计了一种网络化测试系统中的并行数据处理模式,充分利用系统内计算资源,减小网络传输延迟,进而提高系统实时性。成功实现了从顶层作业脚本编写、提交,系统给出运行仪器节点建议,并行FFT程序在建议节点上运行,并将计算进程纳入资源容器进行执行的工作流程。实验结果表明,通过引入更多仪器资源,计算时间的减少较为明显,而通信开销却基本不变,成为进一步提高实时性的关键因素。
