基于改进Yolov3的目标检测的研究
2019-03-11晏世武罗金良严庆
晏世武 罗金良 严庆
摘要:目标检测在视频监控、无人驾驶系统、机械自动化等领域起着重要作用。在如今大数据的背景下,为进一步提高Yolov3在不同数据集下的性能,本文以KITTI数据集为基础,利用重新調整anchor数值和增加尺度融合的方法改进Yolov3,并通过增加数据的方法平衡类别,进一步提高Yolov3性能。实验结果表明,改进的Yolov3较原始的框架,其mAP提高了近5.31%,从侧面说明改进的Yolov3具有较高的实用价值。
关键词:目标检测;深度学习;尺度融合;平衡类别;mAP
0 引言
目标检测能够对图像或视频中的物体进行准确分类和定位,在监控、无人驾驶、机械自动化等领域中起着至关重要的作用。早前的目标检测是通过人工提取特征的方法,使用DPM模型,并在图像上进行窗口滑动的方法进行目标的定位。这种方法十分耗时且精度不高。随着信息时代的快速发展,如今的数据量成几何式地增长,再使用人工提取特征的方式是十分不明智的。自2012年Alexnet在ILSVRC(Large Visual Recognition Challenge)比赛中大放光彩以来,学者们不断地使用卷积神经网络(Convolution Neural Network,CNN)设计新的目标检测框架,并出现了Faster RCNN、SSD、Yolov3等高性能的目标检测框架,并且在实践中展现出强大性能。
在如今较为主流目标检测框架中,Yolov3在检测速度和精度的平衡性方面表现较好,人们不断在各种领域使用Yolov3实现目标检测功能。然而原始的Yolov3架构并不能在各种数据集下均表现出色。对于小目标物体会出现定位不准确的和漏检的情况。本文针对Yolov3的问题,设计以下改进方法:
(1)针对目标定位不准确的问题,对于不同的数据集,重新调整anchor的数值:
(2)针对小目标难检和漏检的情况,增加一个尺度融合:
(3)通过增加较少类别的物体数的方式平衡类别来优化Yolov3.
1Yolov3及其改进方式
1.1 Yolov3框架
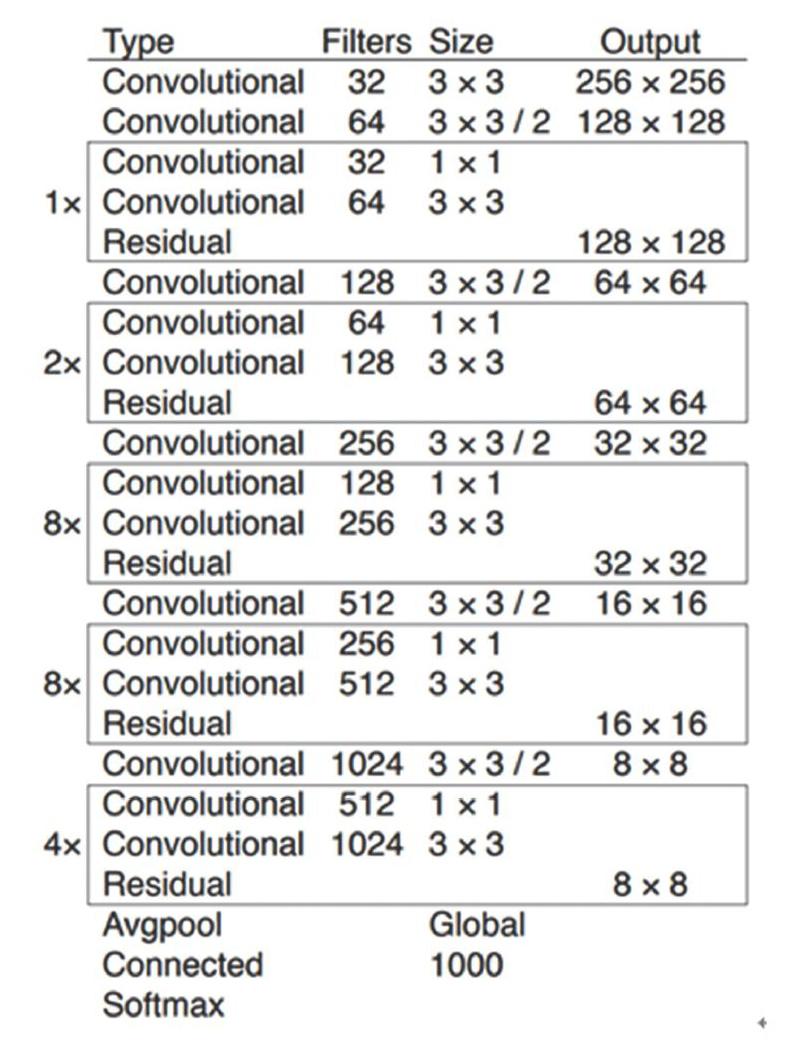
Yolov3是目标检测算法之一,是基于回归的方式进行特征提取,通过端到端的过程训练网络。最终在多尺度融合的特征层中回归出目标的类别与位置。端到端的训练方式使得分类与定位过程为一体。其两者共同的损失函数参与反向传播计算,在节约特征提取时间的同时又提升了精度,满足了目标检测的实时陸需求。Yolov3目标检测框架如图1所示。
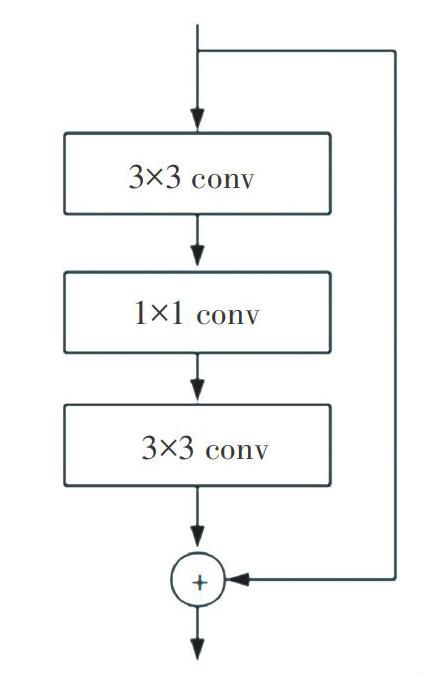
图1中提取曾为Darknet-53的网络结构。该结构以256x256图片作为输入,大量使用1×1和3×3的卷积层进行堆砌,并使用残差网络(如图2所示)将浅层信息传递到深层,可在增加网络深度的同时不引起梯度爆炸等问题,图1中最左边的数字即代表所重复的残差网络模块的个数:Yolov3结构在检测方面采用的是多尺度检测策略,使用32x32、16x16、8x8三个不同尺寸的特征图进行检测输出。原图进行尺寸映射到检测特征层的每个点上,且每个点有3个预测框。因此在三个特征层检测上共有4032个预测框。该预测数极大满足了检测多类物体的需要。最终使用logistic回归,对每个预测框进行目标性评分,根据目标性评分来选择满足需求的目标框,并对这些目标框进行预测。
1.2 anchors的设置
在Yolov3目标检测框架中anchor十分重要,它是由当前数据集通过kmeans聚类算法统计出来的,合适的anchor值能够降低网络架构的损失值,加快收敛。在原始的Yolov3网络层中,用于检测物体的特征层为32x32、16x16、8x8大小的特征提取层,这些特征层可以映射到原始图像,即原始图像被切分为对应特征层的网格大小(grid cell)。如果真实框(ground truth)中某个物体的中心坐标落在gridcell里,就由该grid cell预测该物体,并且每个Cddcell预测3个边界框,其边界框的大小由anchor值决定,然后对预测的边界框与真实框的交互比(IOU)来选出超过IOU值的边界框去进行检测,为进一步减少不必要的检测次数,使用设置目标置信度的方法,当预测框的置信度小于该设定值就不再去检测该框。
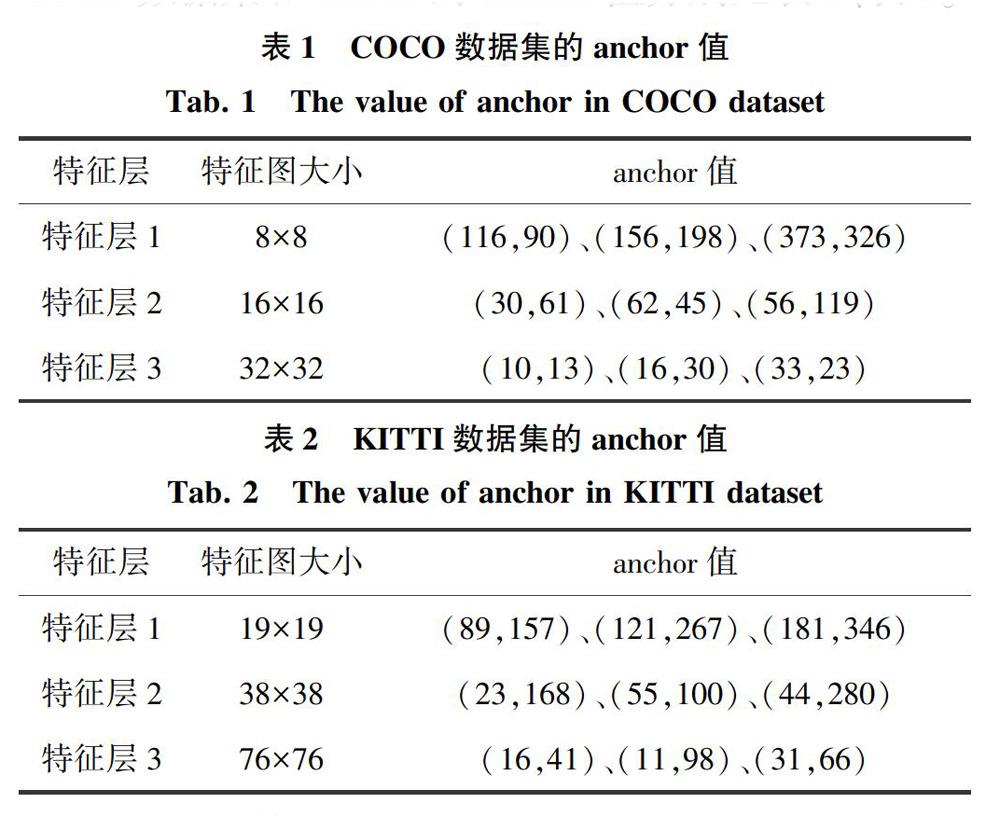
本文训练使用的KITTI数据集,而原始Yolov3中的anchor值是使用COCO数据集得到的。因此,为提升本文物体的定位精度,重新使用kmeans算法去统计是十分必要的,且由于KITTI数据集的图片较大。本文将Yolov3的初始图片大小设为608×608,其对应特征层的大小也相应的会改变。COCO数据集和KITHI的anchor值分别见表1、表2.
1.3 多尺度检测
Yolov3目标检测框架中使用了多尺度检测,即上文所提到的19x19、38×38、76×76三个特征层同时检测图像或视频中的物体,且根据anchor中的值预先画出预测边界框。这种方式对中大型物体具有很好的检测效果,但是对于小物体存在难检或漏检的情况。本文针对KITTI数据集,增加一个特征尺度以提升检测精度。三尺度与四尺度检测模型如图3、4所示,由于增加了一个特征尺度,则anchor值也需要重新调整,见表3.
1.4 平衡数据类别
本文训练的数据集为KITTI。它是由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。标注了九个类别的物体,分别为Car、Van、Truck、Pedestrian、Person sitting、CyClist、Tram、Misc、DontCare。由于车辆的数据集较多而其它的数据较小,有结合CNN需要大量数据集的特点。本文对KITTI数据集中类别进行合并,合并策略如下:
(1)Car、Van、Truck、Tram合为一类,记为Vehicle;
