商业银行审计中贷款风险等级分类规则挖掘研究
2019-03-11马宇州东北农业大学隋学深审计署审计科研所
◆马宇州/ 东北农业大学 隋学深/ 审计署审计科研所
我国商业银行贷款风险等级分类通常采用五级分类法。贷款五级分类法是以借款人的偿还能力为核心,把银行贷款按风险程度或质量高低分为正常贷款、关注贷款、次级贷款、可疑贷款和损失贷款五大类。有两类属于正常贷款,后三类属于不良贷款。审计人员在对贷款风险等级分类真实性进行审计时,除了希望发现正常贷款和不良贷款之间相互错分的情况外,还希望挖掘出正常贷款和不良贷款数据各自具有的分类规则特征。本文就是运用决策树方法挖掘分类规划。决策树方法是利用信息论中的信息增益寻找示例数据库中具有最大信息量的属性字段,建立决策树的一个节点,再根据该属性字段的不同取值建立树的分支;之后在每个分支集中重复建立树的下一个节点和分支,树的质量取决于分类精度和树的大小。
一、实验数据采集、预处理与决策表构建
(一)实验数据采集
从某商业银行某一级分行某年度“借款凭证表”中随机采集了10 万条贷款记录作为实验的原始数据。由于不良贷款(次级贷款、可疑贷款和损失贷款)记录数占比较低,从10万条贷款记录中按照最大化的原则选择出5350 条属于不良贷款记录的数据标记为B 类数据。考虑到决策树算法对类平衡的要求,即要使输入决策树运算的两类数据量大体相当,所以,从10万条贷款记录中随机选择出5343条属于正常贷款(正常贷款和关注贷款)的数据标记为A 类数据。A 类数据和B 类数据共10693 个贷款记录数据作为初始实验数据。
(二)实验数据预处理
根据对商业银行“借款凭证表”中字段经济含义的理解,我们剔除那些和贷款五级分类耦合性较强的字段,为了提高运算速度,还剔除了对正常贷款和不良贷款分类不相关的字段,即那些对分类没有价值的字段。根据以上原则,我们对“借款凭证表”中的42 个字段进行了属性约简,剔除掉的字段属性有:借款凭证编号、借款合同编号、客户代码、机构编码、项目编号、借款凭证原始号码、贷款类别、专项贷款类别、借款用途、贷款账号、还款方式、分期还款周期标志、保证形式、担保合同编号、贷款四级分类、贷款五级分类、表内欠息五级分类、表外欠息五级分类、诉讼时效提示日、操作员和增量标志等共21 个;保留下来的字段属性有:贷款性质分类、贷款期限分类、基准利率、利率浮动幅度百分比、币种、借款金额、借款日期、到期日期、展期到期日、本凭证累计收回贷款、本凭证贷款余额、核销金额、担保方式、累计实收利息、利息收入、表内应收利息、表外应收利息、表内实收利息、表外实收利息、是否以资抵债和操作日期等共21个。
(三)决策表构建及其数据结构说明
1.决策表构建。用经过预处理后的含有10693个A、B类混合数据构建决策表。
2.决策表数据结构说明。决策表中包含了21个经过约简后的属性,由于算法计算过程中应用的是属性的英文名称,为了方便对实验结果的理解,我们建立了21个条件属性的英汉对照及属性经济含义表,如表1所示。
二、实证分析
(一)决策树算法对银行风险等级分类规则挖掘实验及其结果
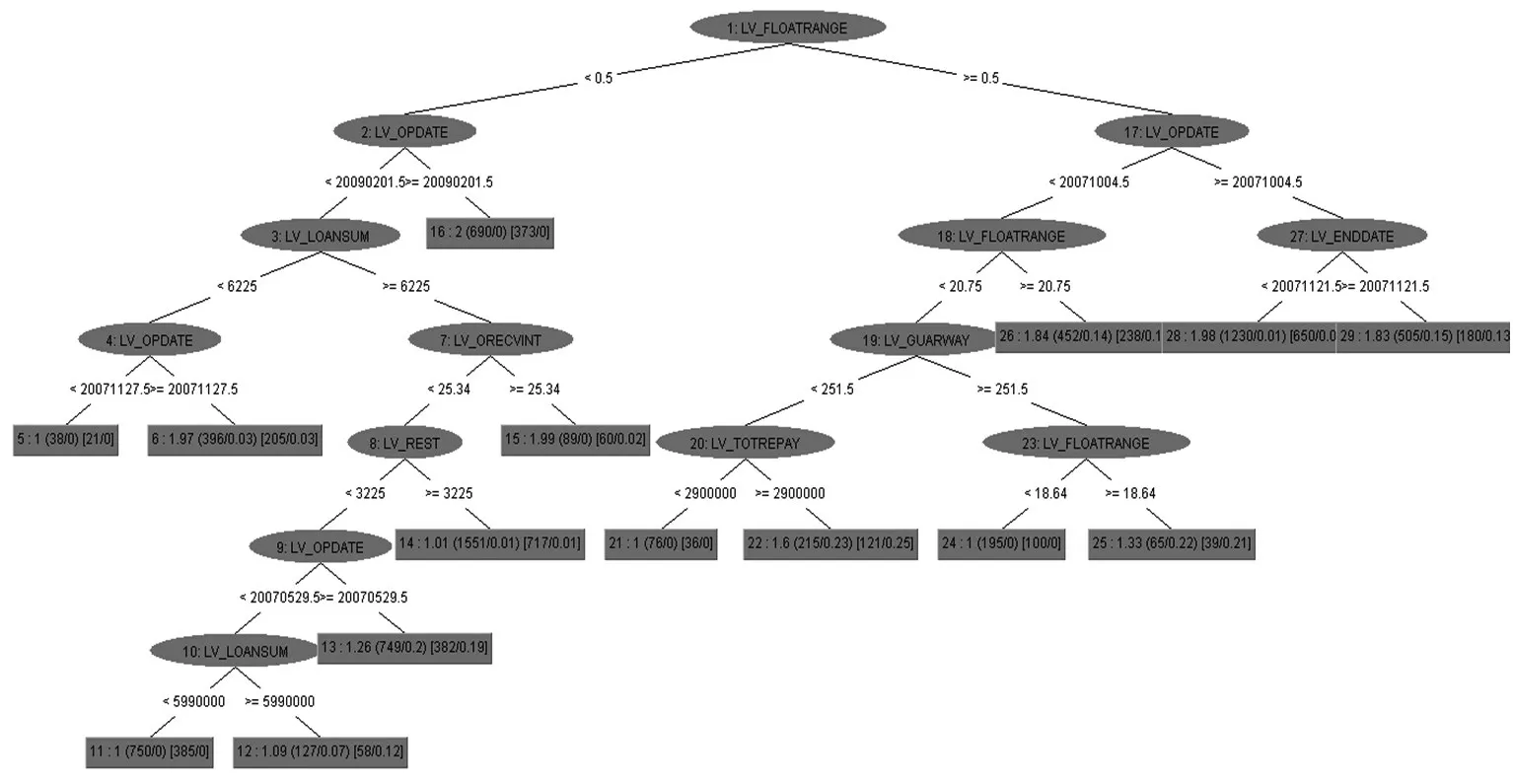
图1:银行风险等级分类规则提取决策树
决策表中的决策属性为贷款记录的正常贷款或不良贷款分类,其中正常贷款类在决策表决策属性中标记为1,不良贷款类标记为2。然后对决策表应用基于决策树的REPTree算法进行分类规则挖掘,其模型参数为trees.REPTree-M30-V 0.0010-N3-S1-L-1,为了方便解释和表述,我们将叶子结点限定的最小事件数选定为30 个,这样决策数的规模为29,即Size of the tree:29。实验构建的决策树如图1 所示,其分类规则提取表如图2所示。
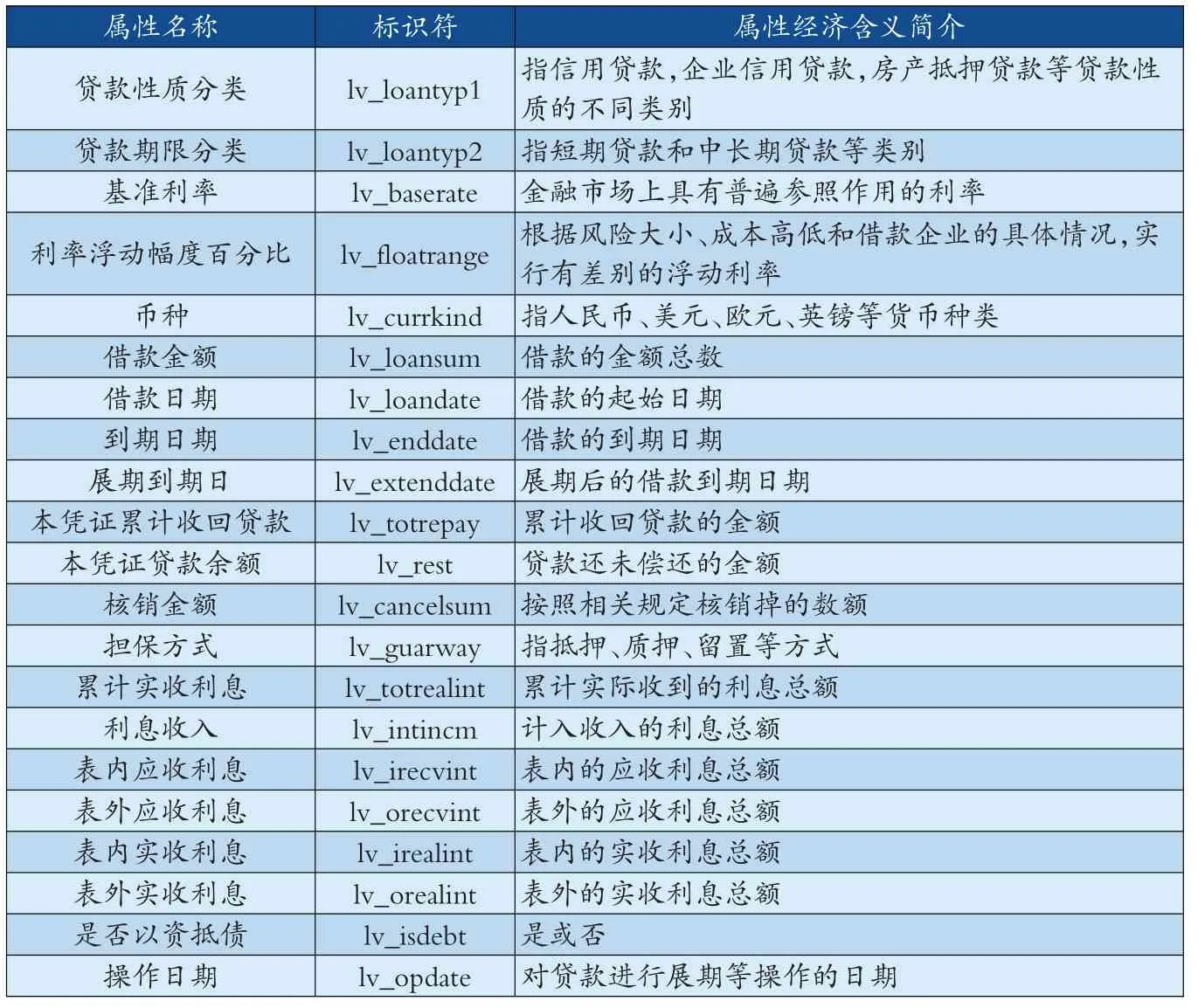
表1:实验数据属性名称英汉对照及经济含义表

图2:REPTree算法对银行风险等级分类规则提取表
(二)实验结果分析
由图2决策树可见,利率浮动幅度百分比(LV_FLOATRANGE)这个属性处于决策树的根结点上,说明在本决策表中其分类能力是最强的,其次是操作日期(LV_OPDATE)这个属性,还有借款金额(LV_LOANSUM)、本凭证贷款余额(LV_REST)、表外应收利息(LV_ORECVINT)、担保方式(LV_GUARWAY)、本凭证累计收回贷款(LV_TOTREPAY)和到期日期(LV_ENDDATE)等条件属性都对正常贷款与不良贷款具有一定的分类能力。
由图2可见,REPTree算法共提取出15条银行风险等级分类规则。以规则LV_FLOATRANGE <0.5 and LV_OPDATE <20090201 and LV_LOANSUM < 6225 and LV_OPDATE >=20071127: 1.97 (396/0.03) [205/0.03]为例,该项分类规则的含义是在决策表中条件属性满足利率浮动幅度百分比(LV_FLOATRANGE)小于0.5,操作日期(LV_OPDATE)在2007年11月27日和2009年2月1日之间,且借款金额(LV_LOANSUM)小于6225 万元的事件共有604 个,其中属于第2类(不良贷款类)的有396 个,属于第1 类(正常贷款类)的有205 个,该项关联规则在全体样本集中发生的概率为(396+205)/10693=5.62%,即其支持度为5.62%,其置信度为396/(396+205)=65.6%,也就是说,当某一条记录满足上述分类规则的条件时,那么该条贷款记录属于不良贷款的可能性是65.6%。
再以规则LV_FLOATRANGE >=0.5 and LV_OPDATE <20071004 and LV_FLOATRANGE >= 20.75 : 1.84(452/0.14)[238/0.12]为例,该项分类规则的含义是在决策表中条件属性满足利率浮动幅度百分比(LV_FLOATRANGE)大于0.5 且小于20.75,且操作日期(LV_OPDATE)在2007年10月4日之前的事件共有690 个,其中属于第2 类(不良贷款类)的有452个,属于第1 类(正常贷款类)的有238 个,该项分类规则在全体样本集中发生的概率为(452+238)/10693=6.45%,即其支持度为6.45%,其置信度为452/(452+238)=65.5%,也就是说,当某一条记录满足上述规则的条件时,那么该条贷款记录属于不良贷款的可能性是65.5%。
由于我们为了控制决策树的规模,将叶子结点限定的最小事件数选定为30个,从而限制了其提取分类规则的置信度。如果我们将叶子结点限定的最小事件数选定为2 个,那么其决策树的规模将大幅增加为231,在分类规则置信度提高的同时,其相应的支持度也大幅下降。
三、基本结论及研究展望
确性,因此,对类似不纯数据的提纯处理是该领域未来进行深入研究的一个重点。
本文的实验结果在一定程度上揭示了商业银行信贷资产风险等级分类的相关规律,有助于增强金融审计人员对不良贷款和正常贷款分类数量特征的理解。由于本研究采用的商业银行实际生产数据中,可能存在一小部分不良贷款和正常贷款之间被相互错分的情况,即商业银行为使不良贷款率达标,将不良贷款人为错分为正常贷款的情况;也可能存在少部分将正常贷款人为错分为不良贷款的情况。这在一定程度上会干扰决策树算法对分类规则提取的正

黄石市西塞山区审计局党支部深入田园社区,认领社区困难群众的“微心愿”,把温暖送到居民手中。通过到困难群众家中走访慰问,为残疾或单亲困难家庭儿童送去书包等学习用品,详细了解他们的生活现状与学习情况,鼓励他们积极面对生活,用点滴善举温暖困难群众,使他们切实感受到党和政府的关怀。
(梁倩倩 摄影报道)
