基于模糊支持向量机上市公司财务风险评级
2019-03-06王岩张佩瑶
王岩 张佩瑶

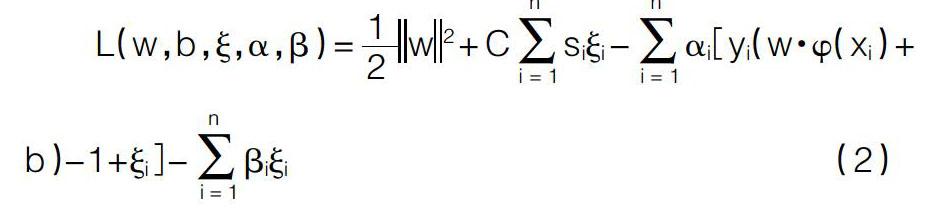

【摘 要】 高新技术产业已成为或正在成为国家和地区新的经济增长点。研究企业财务风险可以提前预测风险并降低破产的可能性。支持向量机在财务风险预警问题的研究中已经取得了成功,但传统的支持向量机存在过拟合的问题,对于数据集中的噪声点十分敏感。为改进上述不足,使用遗传算法对模糊支持向量机参数进行最优化选择,构建了基于KNN隶属度模糊支持向量机算法对上市公司财务数据进行多分类研究。实证结果表明:模糊支持向量机可以更好地解决过拟合问题,提高分类准确率。
【关键词】 财务风险评级; 模糊支持向量机; 模糊隶属度; 遗传算法
【中图分类号】 F275 【文献标识码】 A 【文章编号】 1004-5937(2019)02-0061-04
一、引言
随着经济的快速发展,企业为了扩大规模,提高自身知名度,增加竞争力,纷纷选择上市。上市公司数量与规模日益增加,成为我国经济结构中的重要组成部分。高新技术产业在促进产业结构优化升级、提高国家或地区的国际竞争力方面发挥着重要作用,所有国家都在积极采取措施鼓励高新技术产业的发展,以刺激本国经济。随着中国高新技术产业快速发展及对经济增长的贡献,如何客观、系统地评价高新技术产业的发展水平,明确高新技术产业发展的影响因素显得尤为重要。但是单纯地开发技术、采用新的生产方式,不能更好地改善公司的经营状况,关键是要对财务状况做深入的分析。
企业的财务风险控制是企业在生产经营过程中必不可少的重要环节。财务风险是客观存在的,为了保证企业的正常运行,降低破产的可能性,企业的管理者需要采取一系列有效措施来降低企业财务风险,因此怎样才能建立科学的风险评级体系,成为了企业财务管理过程中的一个重要问题。
美国学者Beaver首先利用财务指标对财务困境进行了预测,此实验结果可以预测接近破产的企业,被称为单变量模型的开创性研究。Martin在此基础上提出了利用Logistic模型来预测银行的破产概率,之后Ohlson将Logistic回归模型运用到企业的财务困境预测。国内对财务风险预测的研究起步比较晚,最初是将统计技术用于财务风险的评估,如单变量模型、多重判别分析等。吴世农和卢贤义[ 1 ]以我国上市公司财务数据为样本,利用统计方法研究财务预警的准确度,得出Logistic模型的误判率最低。传统的风险评级方法有层次分析法、灰色關联分析等,然而随着企业规模的扩大,传统方法已经不能满足企业的需求,神经网络、遗传算法、支持向量机和粗糙集等数据挖掘方法开始应用于企业财务风险预警的研究。邸红娜[ 2 ]利用BP神经网络对制造业的财务信息建立危机预警模型,该模型准确率高达92.5%。甘敬义[ 3 ]应用Adaboost算法对制造业的财务数据构建了BP神经网络模型和Logistic回归模型,结果显示BP_Adaboost模型对财务风险的预测有较高准确率。荆双喜等[ 4 ]应用支持向量机在做好特征抽取的情况下,将模型运用到异步电机转子断条故障诊断的研究中,取得了很好的分类效果。
本文借鉴已有研究,提出了基于模糊支持向量机的高新技术产业上市公司财务数据多分类评级方法。利用KNN隶属度的鲁棒性设计了模糊支持向量机的模糊隶属度函数。实证研究结果表明,相比传统的支持向量机分类模型,模糊支持向量机模型构造的隶属函数可减少不可分区域,达到解决问题的目的,具有较高抗干扰能力和分类准确率。可以利用该模型对企业财务数据进行风险预测,及早发现企业中潜藏的风险,采取相应的措施来规避风险,避免财务危机的发生,保证企业正常运行,提高企业竞争力。
二、模型构建
(一)模糊支持向量机原理
支持向量机是将样本通过寻找到的最优超平面,划分为不同的两类,但实际中并不是每个样本都可以被完全地划分到某一类,其中可能存在有噪声点,会降低分类器的泛化能力[ 5 ]。可通过对样本赋予不同的隶属度,构造模糊支持向量机,提高泛化能力。
已知样本(xi,yi,si),i=1,…,n,y∈{+1,-1}。其中xi为训练样本,yi为样本类别,0≤si≤1为样本的隶属度。模糊支持向量机可通过求解以下问题进行优化。
其中:b∈R是偏差;惩罚因子C为大于零的常数,表示对于误差的容忍度;si?孜i为带权的误差项。
为求上述问题,构造拉格朗日函数:siC表示对易错分样本的重视程度,siC越大样本xi被错分的可能性越小。因此,对于噪声点或野值点,应减小其对应的siC值,则此类样本在训练中的作用将随之减小,从而降低他们对分类面的影响,提高分类精度。
(二)模糊隶属度设计
模糊隶属度的设计对模糊支持向量机的分类性能有很大的影响,反映了样本对训练的重要程度,目前还没有一个一般性的准则可遵循。一般的基于样本与类中心距离的隶属度设计[ 6 ],忽略了样本的分布情况。针对各公司财务数据样本分布的分散性问题,本文选取基于KNN的模糊隶属度度量方法来确定模糊隶属度si,该方法具有较强的鲁棒性。其计算如下:对于每一个训练样本xi,找到与其最近邻的K个点并组成集合Di={d1,d2,…,dk},其中dj(j=1,2,…,k)表示训练样本xi到第j个最近邻点的距离。计算出训练样本xi到集合Di的平均距离daidai=。dai中的最大值与最小值分别为dmax与dmin。本文的模糊隶属度为:其中:?兹<1为足够小的正数,用于控制隶属度下限;f为控制函数变化的参数。
由此可见,当daj趋近于dmax和si趋近于?兹时,xi是噪声点的可能性最小。基于KNN的模糊隶属度度量方法可以更好地计算每个样本对分类的影响,提高分类准确率。
(三)遗传算法优化FSVM模型参数
在模糊支持向量机模型的分类过程中,模型中参数的选择对分类结果有很大的影响,如何选择模型的参数也是提高预测准确率的关键。
遗传算法(GA)[ 7 ]是基于自然选择和基因遗传学的一种全局寻优的优化算法。首先对于随机产生的一组经过基因编码的初始解(种群),根据所需问题的适应度大小进行个体的随机选择,通过对遗传算子进行组合交叉和变异,产生更适应环境的新的种群,逐代演化产生种群问题的最优解。
适应度值用来衡量种群中个体的优劣,遗传算法(GA)采用适应度函数来确定个体的适应度值,有助于适应性好的个体得到繁衍的机会,找到最优解。选择的目的是为了从种群中选出优异的个体,使其中的某些特性可以遗传给子代,减少了基因缺失,提高全局的收敛性。选择就是种群中个体优胜劣汰的过程,它是建立在个体适应度评价基础上的。常用的方法有轮盘赌法、排序选择法等。交叉是遗传算法的核心,它是生成新个体的主要方式,最常用的有单点交叉算子、均匀交叉算子等。变异与选择和交叉结合起来,确保了遗传算法(GA)的有效性,提高了算法的搜索效率。
遗传算法(GA)是一种近似算法,相比传统优化算法直接利用控制变量实际值进行优化,遗传算法是通过控制变量的编码作为运算对象,利用概率变迁规则引导问题的搜索方向,其效率远远高于传统的优化算法,具有十分强的鲁棒性。本文利用遗传算法上述特性来确定FSVM分类模型中的两个参数:惩罚因子-c和核函数因子-g。遗传算法(GA)优化FSVM参数的基本算法过程如图1。
三、实证分析
(一)样本和指标的选取
考虑到样本的时效性与可得性,本文的数据选自CCER中国经济金融数据库。为了避免行业不同所带来结果的差异,选取近五年594家高新技术产业上市公司的财务数据作为研究对象。通过混合分类模型对企业财务数据进行风险评级,将数据分为三类:健康企业、危机企业(ST企业和*ST企业)和破产企业。
在财务风险评级的实证研究中,指标参数目前还没有确定的选取标准,本文依照以往的经验[ 8 ],初步从每股指标、盈利能力、偿债能力、现金流量和净利润增长率5个方面选取了25个备选指标,如表1。
(二)LLE降维
企业在生产和运营过程中产生了大量的数据,这些数据包含了大量的信息,利用该信息可以大大提高实验精度。但是大量的数据意味着增加了实验的复杂性和时间,为了从这些大量的数据中找到有用的信息,有必要将数据进行降维处理。流形学习的目的是发现显著特征和从高维采样数据中恢复低维流形结构,实现数据维数的简约化或可视化。
本文利用SPSS软件对25个财务指标进行KMO和Bartlett的球形度检验,检验变量之间的相关性,结果显示不是正定矩阵,无法通过球形检验,因此不能用因子分析法来进行特征提取。用于建立金融风险模型的降维方法大多是非线性方法,在现实生活中,指标之间的关系也呈现出非线性关系,如果此时要反映出线性关系,会得出不准确的结论。因此,本文在MALTAB中,采用局部线性嵌入(LLE)方法来降低原始数据的维数[ 9 ]。
(三)模型实现与结果分析
1.训练集与测试集的选择
在选取的594个企业样本中,将三种类别重新分类组合,最终选取396个样本作为训练集用于训练分类器模型,198个样本作为测试集用于测试分类器的准确率。
2.数据预处理
利用分类器模型进行训练之前,为了加快訓练速度,可以将数据进行归一化操作,本文采用[0,1]区间归一化:
其中,x,y∈Rn,xmin=min(x),xmax=max(x),yi∈[0,1],i=1,2,…,n。归一化的结果是将原始数据规整到[0,1]区间内。
3.参数寻优与结果分析
本文采用改编的台湾大学林智仁教授开发设计的LIBSVM工具箱来进行数据分类。关于参数选取,国际上没有统一的最好标准,常用的方法是在一定范围内选取c和g的值。为了得到比较理想的预测结果,基于CV原理,本文采用遗传算法分别对惩罚参数c和核函数参数g进行参数的最优化选择。实验中的核函数选用应用广泛的RBF核函数:
在遗传算法寻优中,设置种群数目为20,选择概率为0.9,编码方式选择二进制编码,终止条件为达到最大迭代次数200。实验得到最优参数值“-c 89.2925”,“-g 97.7023”。通过遗传算法找到了最优惩罚参数c和核函数参数g以后,利用最佳的参数进行FSVM网络训练,得到测试集的实际分类和预测分类如图2和图3。
如表2所示,通过实验得到GA-FSVM的分类准确率为83.3%,没有使用优化算法的FSVM模型分类准确率为72.7%,而传统的SVM分类模型的准确率仅为63.6%。通过对比可以发现,基于KNN隶属度函数构造的FSVM算法的分类准确率要高于传统的SVM分类算法。结合图2与图3可以看出,模型的参数选择非常关键,利用遗传算法寻优后的FSVM模型的分类准确率要高于未寻优的模型,提高了FSVM的泛化能力,从而可以反映风险变化,对企业的财务风险进行较为准确的预测。
企业可以根据财务风险评级结果,对自身做出相应的战略调整。如评级为健康企业,说明企业的竞争能力较强,市场前景也较好,应该优先发展,以维持自身在市场中的有利位置;如评级为困境企业,管理者则需要调整战略,树立风险意识,健全企业内部控制制度,使企业的生产经营活动符合总体战略目标;如评级为破产企业,说明企业的市场前景黯淡且竞争力较弱,应尽快收缩或放弃经营。
四、结论与展望
本文针对高新技术产业在生产经营过程中产生的模糊性和不确定性,提出了基于KNN模糊隶属度的模糊支持向量机算法,并利用GA对FSVM分类模型的参数进行最优化选择,对选取的财务数据进行风险评级。实证研究结果表明,本文提出的优化后的FSVM分类模型比起传统的SVM分类模型具有更强的分类效果,克服了传统支持向量机分类精度不高的问题,能够提高管理者对决策制定的可靠性。
虽然优化分类器在实证研究中取得了良好效果,但仍有进一步改进的可能。未来的研究可以突破KNN算法的局限性,选择其他隶属度函数。对于样本属性的选择,可以根据不同行业的标准选择不同的样本,避免行业不同造成结果的不准确。
【参考文献】
[1] 吴世农,卢贤义.我国上市公司财务困境的预测模型研究[J].经济研究,2001(6):46-55.
[2] 邸红娜.基于BP神经网络的我国制造业上市公司财务困境预警研究[D].暨南大学硕士学位论文,2006.
[3] 甘敬义.基于BP-Adaboost和Logistic模型的制造业上市公司财务风险预警研究[D].江西师范大学硕士学位论文,2012.
[4] 荆双喜,赵行宇,郭松涛,等.异步电机转子断条故障诊断研究[J].河南理工大学学报(自然科学版),2016,35(2):224-229.
[5] 马芳芳,仝卫国,宋雨倩.模糊支持向量机的研究与应用[J].电脑与信息技术,2013,21(1):25-29.
[6] 朱健,刘斌.基于FSVM分类算法的动脉硬化病分类[J].电子测试,2015(13):30-31.
[7] 边霞,米良.遗传算法理论及其应用研究进展[J].计算机应用研究,2010,27(7):2425-2429.
[8] 王飞,王娇娇.指标选取方法对财务预警准确率的影响研究[J].武汉理工大学学报(信息与管理工程版),2017, 39(3):348-352.
[9] 马瑞,王家廞,宋亦旭.基于局部线性嵌入(LLE)非线性降维的多流形学习[J].清华大学学报(自然科学版),2008,48(4):582-585.
【基金项目】 国家自然科学基金(61502150);河南理工大学博士基金(B2015-42);河南省高等学校重点科研项目(16A120013)
【作者简介】 王岩(1980— ),男,河南西华人,博士,河南理工大学讲师,硕士生导师,研究方向:数据挖掘、信息系统建模、商务智能;张佩瑶(1994— ),女,河南孟州人,河南理工大学硕士研究生,研究方向:金融风险分析、信息系统设计与优化
