基于稻穗几何形态模式识别的在穗籽粒数估测
2019-03-06马志宏毛雨晗刘成良
马志宏, 贡 亮, 林 可, 毛雨晗, 吴 伟, 刘成良
(上海交通大学 机械与动力工程学院, 上海 200240)
随着人口的增加,水稻产量的提高已成为农业研究的重点问题.稻穗是水稻的结实器官,与水稻产量直接相关,其表型特征是水稻育种[1-2]研究中重要的量化指标,主要包括每穗籽粒数、一次枝梗数量及长度、一次枝梗籽粒数、结实率、稻穗骨架结构[3]等.目前这些特征数据主要是通过传统手工测量得到,这种方法不仅劳动强度大,而且效率低下,受人为主观性限制,重复性较差.随着技术的发展,自动化、高通量等技术运用于作物表型特征的提取,逐渐取代了传统手工测量,可以节省大量时间和人力成本.图像处理技术可以从高分辨率图像自动测得各种表型参数[4-5].针对稻穗籽粒数的测量,国内外科研人员已经开发了一些基于图像处理的自动化设备[6-7],这些设备均需要先对稻穗脱粒,再结合图像处理方法对稻穗籽粒数和其他性状参数进行测量,会破坏稻穗形态结构,不利于样本保存.
基于图像分割的方法是密集颗粒状物体计数的常用方法,在细胞计数[8-9]上颇具效果.但是对于稻穗平面图像,由于谷粒间互相遮挡和重叠较严重,谷粒之间边缘不够明显,令计数难以进行,国内外相关研究也多采用稻穗面积等特征来预测谷粒个数.P-TRAP[10]是一款用于水稻表型测量的开源软件,它采用总面积除以单个谷粒平均面积,并乘以一个修正系数加以修正的结果,作为籽粒数的测量结果,这种方法需要提前测量非重叠谷粒的平均面积,而且修正系数由人为设定,主观因素干扰大.文献[11]中采用X射线成像技术对水稻穗部籽粒数无损检测, X射线具有良好的透射特性,可以较好地解决遮挡问题,但这种方法具有放射性污染.文献[12]中采用稻穗投影面积和一次枝梗总长度进行回归预测,籽粒数预测误差为 7.9%,但只能预测整株稻穗籽粒数,不能预测每个一次枝梗所含籽粒数.
除了图像处理技术,机器学习技术也越来越多地应用到植物表型提取和测量研究领域[13-14].但是,利用机器学习结合图像形态学特征来预测稻穗谷粒数方面的相关研究尚处于空白阶段.因此,本文提出采用图像特征提取和机器学习方法,训练模型进行稻穗谷粒数预测.具体做法是,利用图像处理方法提取稻穗一次枝梗,基于支持向量机(Support Vector Machine,SVM)训练一次枝梗谷粒数预测模型,预测结果求和作为整株稻穗的谷粒数.本文认为二次枝梗为一次枝梗的一部分,且二次枝梗通常较小,使用图像处理算法提取二次枝梗难度较大,在预测籽粒数时不再区分一次枝梗和二次枝梗,这样对总粒数测量并没有影响.本文以3个品种的稻穗为研究对象,分别为粳稻日本晴、9522、籼稻9311,并通过实验验证了所提方法的有效性.
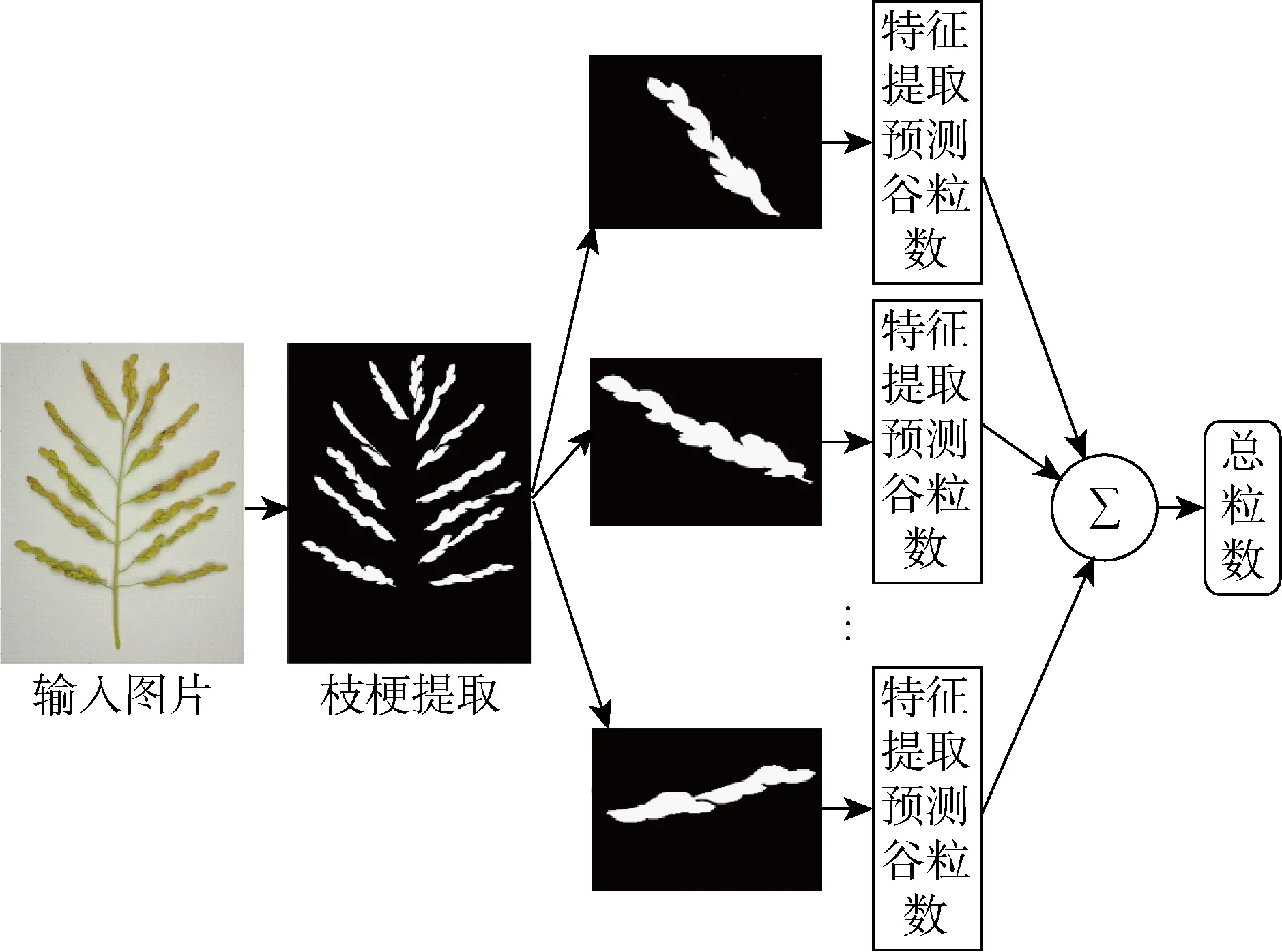
图1 稻穗谷粒数预测方法流程图Fig.1 Flow chart of rice grain number prediction method
1 研究方法
由于稻穗谷粒之间遮挡和粘连情况较严重,而且2个粘连谷粒之间没有明显的边界特征,所以基于图像分割方法的谷粒计数难以得到高精度的结果.如果采用机器学习的方法,直接使用图像处理方法从稻穗图像中提取特征,训练粒数预测模型来计算稻穗谷粒个数,则可以避免图像分割,且随着训练样本的不断扩充,理论上模型预测精度和泛化能力可以提高.文献[13]中采用稻穗投影面积和一次枝梗总长度进行回归预测,因此可以使用稻穗投影面积和一次枝梗长度作为训练特征的一部分.选择训练对象时,如果将整株稻穗作为训练对象,则存在以下问题:如果将个数预测看作分类问题,其类别会超过200个,当稻穗的样本数量较少时,模型容易出现过拟合.实际中,采集并标注超过500个稻穗样本需要耗费很大的劳动力.考虑到每株稻穗平均包含若干个一次枝梗,每个一次枝梗所包含的谷粒数大部分在40粒以内,如果将一次枝梗作为训练对象,则可以增加训练样本数量,减少类别数目,有利于对抗过拟合.因此,本文提出如图1所示的稻穗谷粒数预测方法,首先进行一次枝梗的提取,对每个一次枝梗分别提取特征并用SVM模型预测谷粒个数,随后将所有预测值相加即可得到稻穗谷粒总数.
2 水稻稻穗形态图像特征提取
特征提取是机器学习的前提,也是决定模型预测精度的关键,如果特征选择不妥当,比如存在过多相关性差的冗余特征,训练结果可能出现过拟合等问题.观察稻穗样本可以看出,颜色特征跟谷粒个数几乎没有相关性,而形态特征则有显著相关性.另外,颜色特征容易受到光照环境影响,而形态特征与光照环境无关,不容易受到外界环境的干扰.因此,本文只采用形态学特征训练模型.
2.1 图像预处理
提取形态学特征前,需要将图像转换为二值图,使一次枝梗的前景像素值为1,背景的像素值为0.由于光照情况下一次枝梗周围会产生阴影,为了克服阴影带来的影响,分割出完整的一次枝梗前景,这里采用在HSV(色度、饱和度和纯度)颜色空间进行二值化操作.H、S分量可以消除亮度信息的影响,考虑本研究中由于光照不均匀,一次枝梗周围会产生阴影,影响一次枝梗前景二值化,故可采用S通道抑制阴影.利用OSTU自适应阈值的方法对S通道图像二值化,再通过开运算进行形态学滤波,去除二值图中的噪点,同时消除一次支梗头尾部多余的细枝,得到二值图(见图2(b)).随后计算距离变换图,距离变换是计算并标识空间点(对目标点)距离的过程,它最终把二值图像变换为灰度图像(其中每个像素的灰度值等于它到最近目标点的距离),使用欧式距离变换方式,对二值图进行处理得到图2(c),图中颜色越接近黑色,表示离最近点距离越大,越接近白色,表示离最近点距离越小.它能反映图像的某些形态学特征,如果配合骨架信息,能得到一次枝梗沿轴线上不同部位谷粒的分布密度.为此,先提取二值图的骨架,使用细化算法进行骨架提取,得到骨架图,骨架图与距离变化图相乘得到图2(d),记为骨架距离图,由图2(d)可以看出一次枝梗沿轴线上不同部位谷粒的分布密度.

图2 一次枝梗形态学特征图Fig.2 Morphological features of primary branches
具体实现过程使用基于Python 3.5语言编写的程序.使用OpenCV(版本2.4.9)工具进行HSV颜色空间转换、二值化、开运算、轮廓提取、细化、距离变换等操作.其中,二值化阈值采用函数Threshold计算,方式参数为OSTU,形态学操作的结构元素设置半径为3的圆盘结构,距离变换方式为欧氏距离,细化操作使用Hilditch算法[15]实现.
2.2 特征提取
对于一次枝梗形态学特征,最直观的是投影面积和一次枝梗长度特征[12],在此基础上,又提取了二值图前景的轮廓和最小外接矩形,计算出周长,最小外接矩形长、宽、长宽比,矩形度(区域面积与最小外接矩形面积之比),骨架曲线长度这些特征.另外,根据一次枝梗的形状特点,设计了骨架距离平均值和骨架距离方差,前者计算沿骨架上每一点的距离值平均值,容易发现,这个平均值一定程度上反映了一次枝梗的平均半径.设二值图为B(x,y),距离变换图为D(x,y),骨架图为T(x,y),骨架距离图为H(x,y),则H(i,j)=D(i,j)T(i,j),i=1,2,…,w,j=1,2,…,h,其中w是图像宽度,h是图像高度.特征计算公式如下:
(1) 投影面积.投影面积可以直接从一次枝梗二值(图2(b))反映,这里以一个像素点代表单位面积,投影面积则是对二值图求和
(1)
(2) 周长.周长即轮廓长度,设一个闭合轮廓坐标点序列为{(x1,y1),(x2,y2),…,(xn,yn)},记xn+1=x1,yn+1=y1,其中n为序列长度,则周长为
(2)
(3) 最小外接矩形长宽比,主轴长度.提取最小外接矩形,得到其最小外接矩形2个边长,记为l1,l2,则长宽比为
f3=max{l1/l2,l2/l1}
(3)
使用最小外接矩形长边作为主轴长度
f4=max{l1,l2}
(4)
(4) 矩形度.矩形度表示区域面积与其最小外接矩形面积的比值
f5=f1/(l1l2)
(5)
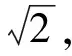
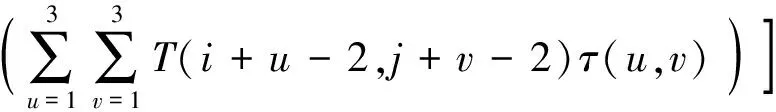
(6)
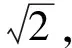
(6) 骨架距离均值.遍历骨架上点,求骨架点所对应的距离值的均值,公式为
(7)
以上所有特征都具有旋转不变性,平移不变性,但是某些特征不具有缩放不变性.因此需要保证训练样本的像素比和测试样本的像素比相同,否则同一个一次枝梗在不同像素比的图像中,提取的特征可能会有较大差异.本文实验均为同一平台,所得到图像的像素比均为 0.118 mm/像素.而实际应用过程中,图像可能来自其他成像平台,对于这些图像,提取特征前需要先将图像等比例缩放到固定的像素比,使得像素比的值等于训练集图像的像素比 0.118 mm/像素,才能用本文算法得到正确的结果.
3 籽粒数预测SVM模型
籽粒数预测的目标是一个非负整数,在有限样本下,这个非负整数有上界U,此时粒数预测可以看成一个分类问题,其类别数为U个.本文算法的模式识别部分选择作为分类器, SVM是建立在统计学习理论VC维理论和结构风险最小化原理基础上的机器学习方法.它在解决小样本、高维和非线性模式识别问题中表现出许多独特的优势,而且具有坚实的理论基础[16].
通常,一个SVM基本分类器只能完成二分类任务,对于对分类任务,一般采用多个SVM集成预测,通常采用的训练策略有一对余型SVM、一对一型SVM等,如果类别数为n,一对余型SVM需要训练n-1个SVM基本分类器,一对一型SVM需要训练n(n-1)/2个SVM基本分类器.考虑到粒数预测值为连续整数的特点,本研究设计了一种集成SVM预测模型训练策略.设训练集中一次枝梗粒数的最大值为k粒,最小值为1粒,则设计这样一个分类器,它由(k-1)个二分类SVM组成,第i个SVM的输出表示粒数是否超过i,其中i=1,2,…,k-1.训练第i个SVM分类器Fi时,正样本对应大于i粒的一次枝梗,负样本对应少于或等于i粒的一次枝梗,则一次枝梗谷粒数预测值为
(8)
相比于一对余型SVM的训练策略,上述方法需要的SVM个数同样为n-1.不同的是,只有对位于两头的SVM训练时,训练集样本不平衡问题才会比较显著,所以这种策略相对一对余型SVM可以更好地解决样本集不平衡问题,相对于一对一型SVM有预测速度的优势.
训练对象是一次枝梗图像(见图2(a)),需要将每个一次枝梗摘下,分别拍照并手工计数标记.以9个一次枝梗为一组,将其按3×3的九宫格位置均匀摆放在背景板上,背景板尺寸为300 mm×240 mm,每个小方格可容纳的一次枝梗长度为100 mm,可容纳大多数长度的一次枝梗.使用500万像素的工业相机,调整相机高度和焦距,使相机的视野刚好完整包含背景板,随后进行一次拍照,采集图像.然后,翻转每个一次枝梗,再进行一次拍照,这样,总共得到2张照片,故一组一次枝梗可以得到18个训练样本,在摆放枝梗的同时,手工数出籽粒个数,按图像名记录在表格,随后经过图像裁剪,得到所有一次枝梗图像的训练样本,根据表格标记对应的籽粒数.实验所用稻穗为3个不同的品种混合而成,分别为粳稻日本晴、9522、籼稻9311.实验中总共采集了 2 688 幅稻穗一次枝梗图像,裁剪后分辨率为800 pixel×600 pixel,每幅一次枝梗图像仅包含1个一次枝梗.采集所用的相机为中国大恒公司生产的MER-500-7UM/UC-L型工业数字相机,实验软件基于Python 3.5,计算机的配置为处理器 Intel(R) Core(TM)i7-6700@3.40 GHz,内存8 GB.
训练时,采用径向基核函数,将 2 688 个样本分为训练集和测试集,大小分别为 2 190 幅,498幅,最大一次枝梗谷粒数为26粒,最小为1粒,故k=26.在训练时,使用交叉验证策略,将训练集分为5份,其中 1 752 幅用来训练,438幅用来验证,以交叉验证的平均预测误差为优化目标,寻找最优惩罚参数C和核函数参数σ.

图3 稻穗形态特征图和一次枝梗提取效果Fig.3 Extraction effect of morphological features of panicle and primary branches
为保留有效特征,减少不重要特征数量,避免过拟合,本文使用ReliefF算法[17]先对特征进行重要性分析和排序,并根据特征权重,选择若干组特征组合分别进行训练,特征权重和不同特征组合的训练结果如表1所示.由表1可知,误差最小的2组特征分别为组合4(f1,f2,f4,f5,f6)和组合5(f1,f2,f3,f4,f5,f6),两者误差相等,但前者比后者少一个特征f3,可以减少一点计算量,故最终选择前者作为训练特征.
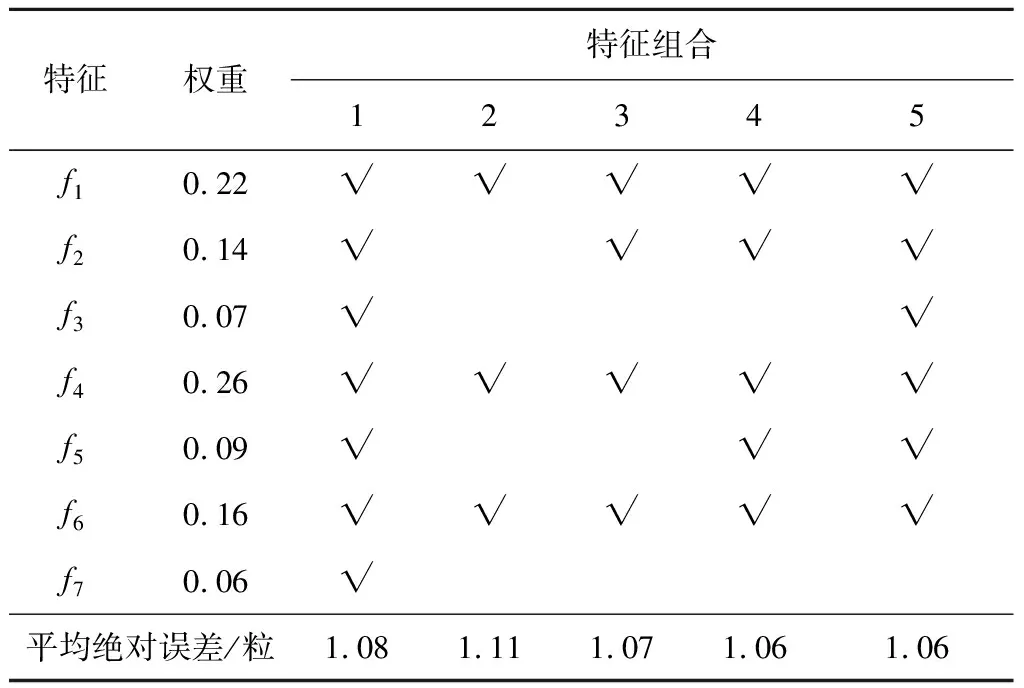
表1 不同特征组合的预测结果Tab.1 Prediction results of different feature combinations
4 一次枝梗提取和测量
本文的训练对象是一次枝梗图像,而实际中测量对象往往是整株稻穗.稻穗在自然状态下具有收缩内敛的趋势,直接成像往往会导致大量谷粒被遮挡,因此实际中,通常需要将稻穗平展铺开再进行成像,如图3(a)所示.为了提取稻穗上所有的一次枝梗,需要剔除茎秆和芒,文献[10,12]中直接进行形态学开操作的方式去除直径较细的茎秆和芒,开操作首先对二值图进行腐蚀运算,再进行膨胀运算,而腐蚀运算会将所有半径较小的区域剔除,半径较大
的区域则保留,目的性较差.开操作结构元素半径过小,不能剔除较粗的茎秆,半径过大容易过度腐蚀,导致一次枝梗断裂,如图3(c)所示.所以采用这种方法通常需要二次判别筛选,将非目标区域剔除.本文根据稻穗形状特点,提出基于局部距离方差的一次枝梗区域提取方法.这里,局部距离方差指以稻穗骨架上一点为中心,一定长宽的圆形领域内,所有骨架点在距离变换图上的距离均方差,如图4所示.
ω(i,j,r)=sgn(r2-i2-j2)
(9)
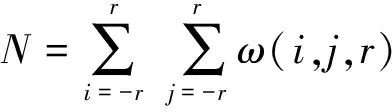
(10)
E(x,y,r)=
(11)
E(x,y,r)T(x,y)]2
(12)
式中:x,y为骨架点坐标;r为邻域半径;H(x,y)为骨架距离图(见图3(e));ω(i,j,r)表示圆形模板,当i,j在以(0,0)为中心,半径为r的圆内时,输出为1,其余为0;E(x,y,r)为骨架点半径为r的领域内距离均值;S(x,y,r)为骨架点半径为r的领域内距离方差.
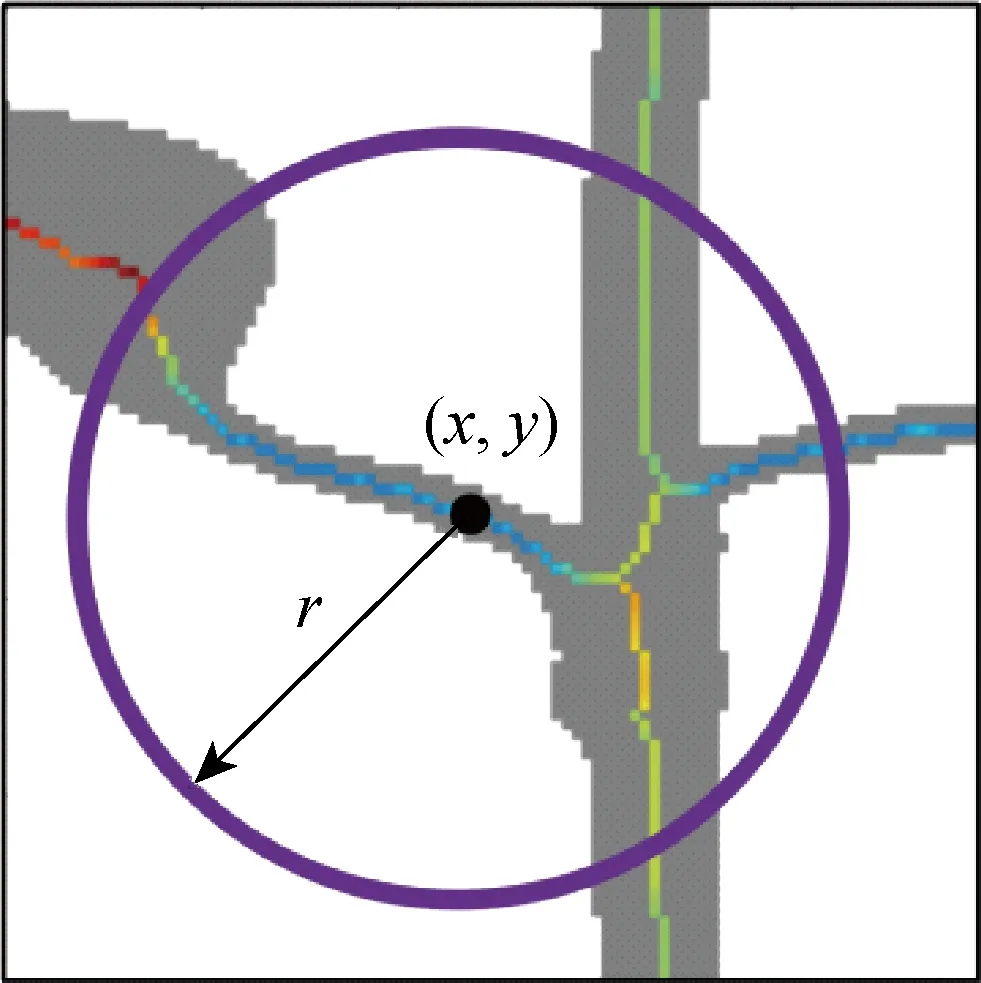
图4 局部距离方差示意图Fig.4 Schematic of local distance variance
经过实验,取阈值α,以r半径的邻域内距离方差小于α,并且当前点距离值小于β时,将这点周围以1.5倍的距离值为邻域的区域置为背景像素值,否则,不操作.如图4所示,(x,y)表示当前需要处理的像素点坐标,点(x,y)的局部距离方差是指,在以此点为圆点,半径为r的圆内,计算所有骨架上的像素点对应的距离值的方差,图4中灰色区域为稻穗前景,细线条状像素点表示骨架,其颜色代表像素点对应在距离变换图中的距离值,越接近黑色,表示距离值越小,越接近白色,表示距离值越大.当遍历完整个骨架像素点时,所有非目标物都被剔除,如图3(f)所示,后面采用连通域查找算法即可提取所有一次枝梗的二值图.经过实验,α取6.5,β取10,r取40时效果最佳.
算法基于局部距离方差的一次枝梗分离算法

Input: image,α,β,r#输入稻穗图像和参数
1:B=binarization(image) #图像预处理和二值化
2:D=distanceTransform(B) #距离变换
3:T=thining(B) #细化
4:H=DT#矩阵D和矩阵T对应元素相乘,得到矩阵H
5: Forxfrom 1 to width
6: Foryfrom 1 to height
7: IfH[x][y] > 0 andH[x][y]<βthen
8:s=S(x,y,r) #计算以(x,y)为中心的局部距离方差,见式(12)
9: Ifs<αthen
10: drawCircle(B,x,y,1.5×H[x][y])
#在图B上以点(x,y)为中心,1.5×H[x][y]为半径画圆,填充灰度为0
11: End if
12: End if
13: End for
14: End for
Output:B
由于这一步已经进行了距离变换和细化操作,后面提取一次枝梗形态学特征时不必重复做这2个步骤,一定程度上节省了时间.所以,对于整株稻穗的谷粒计数算法伪代码如上述算法所示,通过二值化,形态学预处理,基于局部距离方差的一次枝梗区域提取,对每个一次枝梗提取特征,并预测籽粒个数,最后对所有预测结果求和,得出整株稻穗的籽粒预测数.从图3(f)可以看出,本文算法可以有效去除支秆,完整保留一次枝梗,并且不会造成一次枝梗断裂(见图3(c)),可以保证一次枝梗形态学特征提取的准确度,提高一次枝梗谷粒数的预测精度.
5 实验结果与分析
实验选取62株完整的稻穗来测试本文算法的预测效果,这些稻穗样本品种来源与训练样本相同,不同之处为训练样本是将稻穗剪切成若干一次枝梗,而测试样本则为完整稻穗.每株稻穗包含的一次枝梗数目为7~18个,总谷粒数在40~200粒.稻穗铺开后在同一实验平台(即采集训练样本的平台)下进行图像采集,并手工数粒进行标记.
为了体现算法的预测稳定性,将测试样本随机分成3组,每组约20个稻穗,记为样本1, 2, 3.实验时,分别对3批样本单独测试1遍,然后对3批样本合起来测试1遍.表2显示了测试结果,可以看出最大平均误差为 6.72%,优于文献[12]的测量误差.为了体现本文算法的优越性,同时使用一对余型SVM进行训练和预测.由表2可见,一对余型SVM所得到的误差略高于本文算法,说明本文提出的SVM训练策略较好地解决了数据不平衡问题.
图5所示为一组稻穗测试样本的谷粒数预测结果和一次枝梗提取效果.结果显示,大部分稻穗一次枝梗均能准确提取,但是当2个一次枝梗之间没有充分分开,有粘连情况,则会将2个一次枝梗误判为1个一次枝梗,因此稻穗摆放时需要保证每个一次枝梗互不粘连.

表2 稻穗谷粒数预测实验结果Tab.2 Experimental results of panicle grain number prediction

图5 稻穗测试样本的谷粒数预测结果和一次枝梗提取效果Fig.5 The prediction results and primary branch extraction effects of rice grain numbers of test samples
6 结语
本文提出的使用形态学特征进行模型训练来预测谷粒数的方法,在实验中最大平均误差为 6.72%,说明本文方法可以成功应用在稻穗谷粒数预测上;而形态学特征对颜色和光照环境不敏感,鲁棒性较高,若稻穗发生霉变或其他原因造成稻穗颜色变化,只要形状不发生变化,依然能得到相同测量结果;此外,基于局部距离方差的一次枝梗提取方法能够较好地避免一次枝梗断裂的问题,保证了一次枝梗特征提取的准确度和稳定性.不足之处是必须人工将稻穗充分铺开,否则会出现较大误差.同时,人工铺开稻穗耗费时间和体力,因此本文方法只适合小批量样本的测量.后续工作中,稻穗的铺开方式还有进一步优化空间,采用自动化或半自动化方式铺开稻穗,可以减少人力劳动成本,提高本文方法的实用性.
