基于GSM-熵值法和TOPSIS排序的系统风险评估模型∗∗
2019-03-06张于贤杨梦珂
张于贤 杨梦珂
(桂林电子科技大学商学院,广西桂林541000)
近年来,随着中国从制造大国向制造强国转型,国内汽车企业愈发重视零部件质量管理。一辆整车由成千上万个零部件组成,零部件质量与消费者息息相关。很多学者对汽车零部件的质量风险防范做出了大量研究。答建成[1]综述了传统工艺在汽车零部件表面强化上应用的工艺优缺点及研究现状;徐兰[2]构造了汽车零部件制造商与整车厂商之间的演化博弈论模型,从零件的供应源头控制汽车零部件质量;李铸国[3]提出了应用统计过程质量控制理论对汽车零部件进行质量控制,该方法融入了过程质量控制的理念以保证产品制造过程中的精度要求;李翱[4]为了弥补传统检测和质量控制的不足,开发了一种新的计算机辅助检测和质量控制系统,实现零件质量分析和控制管理的一体化;刘明周[5]构建了面向再制造质量目标的复杂机械产品装配分组优化约束函数,模拟退火遗传算法求解出动态规划优化配置方案以提高机械装配质量稳定性。
显然,大多数学者是基于宏观控制的角度提高产品质量,很少考虑产品参数的问题会造成的整个产品出现故障。汽车零部件的质量考核,需要对特征参数进行检测,以达到风险防范的作用。罗绵辉[6]利用对不同故障类型的振动信号的特征矢量所具有的概率密度进行建模。高斯函数(gaussian function)用于统计学以描述正态分布,对大规模、标准化生产下汽车零部件来说,特征参数是固定的,且加工过程中数据波动较小,可视为单模态背景。因此本文采用单高斯模型来描述其特征参数的分布。并根据零部件的组成划分子系统,提出一种反熵法与GSM结合的方法来分析各组成之间的风险大小。
逼近理想解排序(TOPSIS)最早是由 Hwang和Yonn[7]提出的,认为决策单元的优劣可以通过相对距离排序得到。最优方案是最小化与正理想解的距离、最大化与负理想解的距离。
在传统TOPSIS方法中,决策矩阵中的决策信息以精确数形式表现。然而在现实的多属性群决策中,决策者可获得的信息经常是不精确和模糊的。因此本文基于故障模式影响分析(FMEA),建立风险指标的三角模糊数决策矩阵[8],利用TOPSIS法对产品子系统进行风险排序。最后给出了组合两种方法的风险排序算法公式。
1 基于GSM-熵值法的故障风险排序
根据汽车配件规模化生产的特点,将汽车配件作为一个系统,主要组成部分视为各子系统。子系统所需满足的特征参数记为一组参数向量,其参数向量在参数空间中的部分是一个随机过程,因此可以通过建立高斯概率模型对零件的特征向量进行描述。相比较带有主观性质的赋值法,熵权法[9]具有较高客观性,能够更好的解释所得到的结果。然而熵权法确定权数依赖于样本,每一次计算都会抛弃前面的样本,而汽车配件的制造属于大批量生产,重复多次计算得到的权数会发生变化。因此结合GSM模型[10],可以更有效利用样本数据,确定各子系统的权重。
1.1 多维单一高斯模型(GSM)
获取大量样本数据的情况下,多维变量X服从高斯分布,可以用多维单一高斯概率密度函数(GSM)来对其进行描述,记为N(x,μ,∑)。GSM模型相对位置可以由样本均值μ来表示,模型分布的走向和形状变化由样本协方差∑来表示,其概率密度函数如下式:

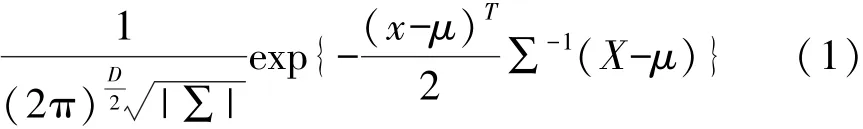
式中:D表示X的维度,∑表示D×D的协方差矩阵,定义为:

1.2 偏离程度模型
利用车间标准化生产下连续加工n次所获的样本数据建立GSM模型,作为后期检测新的产出零件的量化标准。对于新输入样本子系统i的特征参数向量Xi,GSM计算其概率密度p(Xi),表示Xi属于标准生产状态的概率大小。考虑到概率值的波动范围,采用对数似然概率(LLP)作为偏离程度的指标[11]。p(Xi)越大,代表属于标准生产状态的概率越大,生产稳定性越好,其偏离程度越小。记子系统加工状态的对数似然概率为:

1.3 熵值法确定故障风险排序
假设配件分为n个子系统。为了研究配件各个组成部分的加工稳定性,子系统参数偏离标准程度越大,对整体系统的影响程度越大,越应该得到重视。为了更好地应用拟合函数,对研究对象采取抽样的方法,样本数N>30。因此记样本的概率密度p(Xi)t(t=1,2,…,N)。根据公式(3)可以求出样本中子系统i的特征指标数据距标准模型的偏离程度,记为LLPit(t=1,2,…,N)。 即得到矩阵:
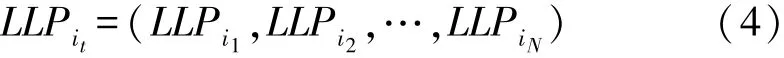
整体偏离程度的离散度越小,代表该组样本越稳定,工艺质量更符合标准状态,失效的风险性越小,权重越小。因此,这里采用反熵法确定权重。设子系统i与高斯混合模型的偏离程度的熵值为hi,权重为Gi:

权重Gi值越大,该子系统的出故障的可能性越大。记故障风险率Ti代表各子系统对整体系统的影响程度:

2 基于FMEA的逼近理性排序法
逼近理性排序法(TOPSIS)[12]可是一种按照相对接近度排序的评价方法,通过定义评价方案中的最优解和最差解,计算各方案与最优解和最差解的距离,从而根据相对接近度进行优劣排序。故障模型影响分析(FMEA)[13]是常用的风险评估方法,风险优先数R越大,潜在风险越高。风险优先数R是事件发生的严重度S、发生频度O和被检测难易度D三者的乘积。因此这里引用严重度、发生频度和被检测难易度为评价对象的风险评估指标。
严重度S是对失效模式严重后果的评价等级,等级划分见表1。频度O是指在某一特定失效发生的可能性,等级的区别重在描述发生失效的情况,例如不太可能发生和反复发生的等级不同,而不是具体的数值等级划分见表2。探测度D是指探测出失效起因或机理的难易程度,等级划分见表3。专家根据风险评估指标评估准则进行打分时,往往较难做出准确的判断。因此引入三角模糊函数a=[aw,av,au],将专家的主观判断给出模糊判断量:最低可能值aw,最可能值av,最高可能值au。根据三角模糊函数的运算性质,严重度、频度和探测度的三角模糊数值见表1~3。

表1 汽车严重度评估准则及其三角模糊数描述
基于FMEA的TOPSIS计算步骤如下:
(1)设对m个评价对象进行排序,评价指标为严重度S、发生频度O和被检测难易度D。其中第i个评估对象的第j个指标的评分值为rij(i=1,2,…,m;j=1,2,…,n),得到各个评价对象的指标模糊矩阵R=(rij)m×n。
(2)基于FMEA对评价对象进行风险评估,数值越小越好,因此采用成本型的规范模糊矩阵方法,把指标模糊矩阵R=(rij)m×n转化为规范矩阵Z={zij}=,即:


表2 发生频度评估准则及其三角模糊数描述
(3)评价指标定权。假设有L位专家对严重度S、发生频度O和被检测难易度D进行重要性决策,得到矩阵E=(eij)t×3;然后对矩阵进行归一化得到矩阵F=(fij)t×3。 第j项指标权重:
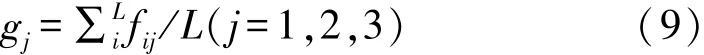
(4)将指标的权重作为加权向量g=(g1,g2,g2)τ,对规范矩阵进行修正。每一指标权重与其对应的矩阵元素相乘:

(5)确定正理想解X+与负理想解X-。设正理想解X+的第j个指标值为,负理想解X-的第j个指标值为xj-,则:
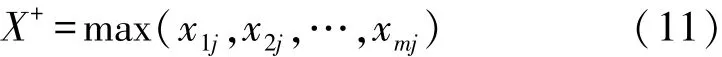

(6)计算各评估对象到正负理想解的距离:

(7)根据相对接近度的计算公式,可得到各子系统的相对接近度均为正数,因此0<Ci<1,记:值越大,即相对接近度越差,表明该评价对象综合评估结果越差,对整体系统的风险影响程度越大。


表3 被检测难易程度评估准则及其三角模糊数描
3 建立组合排序的系统风险评估模型
3.1 组合风险排序
由公式(3)~(7)可以得到抽样配件的各子系统故障风险率值。故障风险率的大小代表对整体系统的风险影响程度,可以认为是客观状态下得到的风险排序。由改进的逼近理想排序法,得到专家根据FMEA指标打分后的各子系统对整体影响程度,可以认为是主观状态下得到的风险排序。因此,这里综合两种排序的结果,得到组合风险排序值Wi:

对公式(17)中的δ求二阶导得到:成立,即y(δ)存在最小值。
令公式(17)中的δ求一阶导为零:

当dy/dδ时之间的差异最小,求得松弛因子δ:

3.2 系统风险评估流程
基于组合排序的系统风险评估流程见图1。评估流程可以分为以下几个阶段:(1)将某汽车配件看为一个整体系统,划分出配件的主要组成部分,视为各子系统;(2)根据先前样本数据建立各子系统特征参数的GSM模型;(3)基于GSM模型的改进熵权法确定各子系统的客观风险排序;(4)基于FMEA的逼近理性排序法确定各子系统主观风险排序;(5)综合两种排序方案,得到系统风险评估的组合排序结果。


表4 子系统的特征参数及其均值和协方差
4 实例计算及分析
以S工厂产出的某轿车4档变速器为例,将其作为整体系统。将此款变速器的风险较高的主要组成部分划分为子系统,如图2所示。针对各子系统的特征参数,采集S工厂2018年2月至5月的生产数据,计算各参数的均值和协方差,得到子系统的多维高斯模型,见表4。
抽取6月份生产的变速器45件,作为决定GSM-熵权排序的样本。根据公式(1)将各子系统的特性参数值作为向量Xi(Xi1,Xi2,Xi3…),输入该子系统所对应的GSM概率密度函数,得到概率密度p(Xi);将p(Xi)代入公式(3)得到某次样本中子系统i的对数似然概率LLPi。取样本容量N=45,得到概率密度p(Xi)t(t=1,2,…,45)和对数似然概率LLPit(t=1,2,…,45),如表5所示:
将表5的结果代入公式(4)~(7)求出各子系统的故障风险率值Ti,并对其进行排序:

根据表1~3,集结S工厂的5位专家和工程人员,对变速器的各子系统(常啮合齿轮、一档齿轮、二档齿轮、三档齿轮、四档齿轮、同步器)进行风险指标三角模糊数描述,见表6。

表5 子系统的概率密度和对数似然概率
该4档变速器的各子系统基于严重度、发生频度和被检测难易度的决策矩阵:

根据公式(8)将决策矩阵转化为规范决策Z:


表6 变速器子系统风险指标的三角模糊数描述
根据5位专家和工程人员提供的风险指标S、O、D决策信息,可以得到矩阵E=(eij)5×3,并对其进行归一化得到矩阵F=(fij)5×3,根据公式(9)得到风险指标的权重向量g,即:

根据公式(10)确定加权规范矩阵X=gZ,即

根据式(11)、(12)确定正负理想解:

根据式(13)、(14)计算各子系统的风险指标值到正、负理想解的欧式距离:



根据式(16)~(18)将Ti和进行组合,求得各子系统的组合风险排序值:

通过组合基于GSM-熵值法确定的故障风险率和基于FMEA的TOPSIS结果,实现对变速器各子系统的风险大小排序。由结果可知,同步器(β6)是整体系统的薄弱部分,风险最大。尽管该部分故障的严重度偏低,但发生频度较高,且加工过程的故障风险率高,使其居于风险评估顺序的最前端,应得到S工厂的重视,对其加工流程进行改善,降低故障发生频度。四档齿轮(β5)的风险最小,因为其故障发生频度低,且加工过程偏离标准的概率较低,故障风险率低,综合来看风险最小,对于变速器属于较稳定的子系统。
上述案例给出了汽车变速器基于GSM-熵值法确定的故障风险率排序,基于FMEA的TOPSIS排序和组合模型排序。显然,三者的排序结果一致,但通过定量计算,组合模型的评估结果更为准确,综合了两种的方法,具有主观和客观兼并的优点。基于GSM-熵值法确定的故障风险率主要依赖现场生产数据,更加真实且符合工厂近期生产现状。基于FMEA的TOPSIS排序充分利用了过程控制的优点,通过三角模糊函数打分的方法对子系统进行风险评估,解决了对某一子系统难以定分的问题,代表了专家对各子系统的主观风险评判。
5 结语
(1)利用高斯模型对大批量、标准化模式下的子系统加工工艺参数的故障风险进行模拟,可以得到新样本相对生产标准的偏离程度,以子系统偏离标准的离散程度评估其故障风险。离散度越大,子系统的工艺质量稳定性越差,故障风险越大。该模型的建立充分利用了工厂生产数据,具有客观真实的特点。
(2)用模糊理论将专家打分和PMEA风险评估指标建立联系,可以减少专家评判子系统对于3个风险指标的定分难度,将具有一定模糊性的不确定评估结果用三角模糊数表示,提高了专家评判的准确性和可信度,再利用TOPSIS法进行风险评估。排序的结果表明了子系统对于整体的危害程度,排序越靠前危害越大,即风险越大。
(3)通过组合两种风险评估方法的计算结果,得到最终的风险排序。组合模型引入松弛因子,调整了两种评估结果的差异。以S工厂生产的汽车变速器作为整体系统,变速器的组成子系统作为子系统,由结果可知,该组合模型综合了子系统在工艺质量和故障影响两方面的风险评估,且最终评估结果与单一评估结果相同,证明了该评估模型的可行性和有效性。
