一种基于桶重构的差分隐私直方图发布方法*
2019-03-05徐文涛李林森钮佳超张凌轩
徐文涛 , 李林森 ,钮佳超 , 张凌轩
(1.上海交通大学 网络空间安全学院,上海 200240;2.国防大学 政治学院,上海 200433; 3.上海市信息安全综合管理技术研究重点实验室,上海 200240)
0 引 言
进入21世纪,随着互联网的快速发展,应用信息技术的出现和不断普及,各种数据库应用系统存储了大量数据。这些数据拥有巨大的社会价值,可以用于资源分配、医学疗法评估、了解疾病的传播和改善经济效用等。对于科研机构、企业以及政府统计部门而言,数据是非常有价值的资源。对这种资源强烈的需求,也大大推动了人们对数据的收集、储存、分析和分享。然而,许多数据中往往存在着一定的隐私信息,如果不采用适当的隐私保护技术而直接发布数据,很容易造成个体隐私信息的泄露[1]。
近年来,国内外频频出现隐私泄露事件,给个人、家庭和社会造成了一定恐慌,如2018年8月爆出的华住酒店集团数据泄露事件。据媒体报道,有人在境外兜售华住旗下酒店的开房记录,涉及共计约5亿条公民个人信息,有1.3亿个身份证信息,在社会上造成了极坏影响。为了有效保护个人隐私,近年来出现了许多隐私保护模型,如k-匿名[2]、z-多样性[3]和t-邻近性[4]等。然而,这些典型的隐私算法在定义时都局限了攻击者的背景知识,且只针对特定的攻击模型才有效。而在实际操作中,攻击者拥有的背景知识远远超过其假设,他们只需要通过细致的推理,就可以攻击到用户的个人隐私信息。
为了能够定量地控制隐私信息的泄露,尽量使隐私保护方法不依赖于攻击者的背景知识,2006年微软研究院的德沃克(Dwork)与卡玛利拉(Kamalika)等人提出了差分隐私保护模型[5],通过向查询结果或分析结果中添加噪声来达到更强的隐私保护。
基于直方图结构的数据发布方法是目前最常用的一种数据发布方法。由于它形象地显示了数据分布形式,因此其统计结果可以为实现计数范围查询提供理论依据。在直方图发布过程中,为了满足差分隐私并提高数据发布的准确性,通过重新划分桶的思想,合并原始直方图邻接相似的桶进行重构,并添加拉普拉斯噪音来满足差分隐私的要求。然而,针对原始直方图中存在离群点的情况,会产生较大的全局敏感性。直观来讲,离群点是在数据集中偏大或偏小的值,也可以说离群点与数据集中其他值差的绝对值要远远大于普通值之间差的绝对值。例如,在统计身高的数据集中,高于2 m的人群就是一个相对非常小的计数值,即一个典型的离群点。现有的针对此类数据集的差分隐私直方图发布算法虽然可以保证数据发布的精度,但是执行效率不高。因此,针对此类携带离群点的数据集,在保证发布数据质量和可用性的前提下,设计出高效的差分隐私直方图发布算法具有重要的意义。
1 相关工作
差分隐私保护模型提出后,迅速引发了各个领域的研究热潮。目前,国内外对差分隐私的研究主要集中在两个重要领域,即数据分析和数据发布,而差分隐私研究的核心问题是如何实现满足差分隐私要求的数据发布。一个实现差分隐私发布机制的是文献[6]提出的拉普拉斯(Laplace)机制。该机制主要通过向确切的查询结果中添加服从拉普拉斯分布的独立噪声来扰动真实的查询结果。文献[7]中提出一种叫做PMW(Private Multiplicative Weights)的发布机制。PMW机制主要结合差分隐私保护技术与机器学习中的加权多数算法(Weighted Majority Algorithm),通过投票机制构建了一个复合算法。
近年来,一些学者在差分隐私直方图发布研究领域取得了丰硕的研究成果。最早的差分隐私直方图发布方法是德沃克提出的LP(likelihood procedure)方法[6]。为了提高发布数据的准确性,文献[8]提出了基于后置噪音优化处理的差分隐私直方图发布方法Boostl,采用树结构代表一个查询序列,其中树中的每个节点代表一个计数范围查询,最后通过一致性约束后置处理技术对添加噪音后的树节点进行求精处理。为了响应较长范围的查询,东北大学的许等人在文献[9]中提出了NoiseFirst方法和StructureFirst方法。NoiseFirst方法采用动态规划技术,通过合并邻近相似桶的方法,对LP产生的等宽直方图进行重构;而SructureFirst方法的思想是先对动态规划技术产生的优化直方图的桶边界进行微调,形成不等宽的直方图,然后向每个桶中添加适当的噪音,形成满足差分隐私的直方图。虽然该方法降低了噪音误差,但是产生了新的重构误差。为了平衡噪音误差和重构误差,加拿大康科迪亚大学的陈等人[10]提出了采用自顶向下层次聚类的方法动态寻找最佳合并后的桶个数k。实验证明,这种方法在时间效率和数据发布准确性上,较StructureFirst方法都有显著提高。
本文针对差分隐私直方图发布方法中原始直方图存在离群点的问题,提出一种差分隐私保护下携带离群点的直方图发布的R-G-I方法。该方法在实现差分隐私保护直方图发布数据的基础上,有效地解决离群点存在的问题。此外,通过实验与同类算法的对比,证明了本文所提方法在保证发布数据质量和可用性的前提下,在准确性上具有明显优势。
2 基础知识与相关定义
定义1 差分隐私(Differential Privacy)[6]:假设有相邻数据集D1和D2(若有数据集D1和D2,其差别除了最多相差一条记录外,结构与属性都相同,那么称D1和D2为相邻数据集),随机算法A的值域为dom(A),该算法的任意输出O∈dom(A),如果满足Pr[M(A)∈S]≤eε×Pr[M(A*)∈S],就称算法A满足ε差分隐私。隐私披露风险由函数A决定。其中,Pr[·]表示算法随机性输出的概率,ε为差分隐私预算。参数ε用于衡量隐私保护的强度,大小由使用者设定。更小的ε表示需要添加幅度更大的噪声,从而带来更强的隐私保护。显然,差分隐私保护强度与发布数据的可用性之间是一对矛盾。一般地,ε是一个接近于1的公开实数,通常取值为0.01、0.1、l、ln2和ln3等,也可根据实际需要取值。
差分隐私保护主要有两种机制——Laplace机制和指数机制。本文主要使用Laplace噪声机制,将其分别应用于数值和非数值数据。因此,主要介绍Laplace噪声机制。Laplace机制主要是通过服从Laplace分布的噪声将其应用于隐私数据的保护,从而干扰真实输出结果来实现差分隐私保护。
定义2 Laplace机制:给定一个数据集D和一 个 查 询 函 数f∶D,其 中γ~Lap(Δf/ε)为 随 机 噪声,敏感度为Δf,则满足ε-差分隐私的随机算法A(D)=f(D)+γ,服从参数为Δf/ε的拉普拉斯机制[6]。
在拉普拉斯机制实现差分隐私算法的过程中,注入的噪声分量Lap(Δ/ε)的样本分布与算法敏感度Δ和隐私预算ε参数密切相关。算法敏感度是衡量一个算法针对不同输入数据时算法输出的变化程度,而隐私预算ε是基于差分隐私模型拟定的一个用来指示隐私保护级别或程度的一个数据量。包含n个单元桶的直方图,实际上就是n个独立的范围计数查询。假设其中一个单元桶的频数值为X,从数据集中删除一条记录后该桶的频数值为X´,那么||X-X´||=1,则直方图每个桶的计数查询敏感度Δf=1。通过向直方图每个桶的统计频数中注入少量服从拉普拉斯分布的独立噪音,就可以满足差分隐私的要求。
直观来说,离群点就是在数据集中明显偏大或偏小的少数值。也可以说,离群点与数据集中其他值差的绝对值要远远大于普通值之间差的绝对值。例如,对于一个频数序列H={19,6,300,28,13},直觉告诉人们300为该序列中的离群点。通过计算也很容易发现,300与其他频数差的绝对值要比其他频数之间差的绝对值大很多。因此,考虑采用比较数值之间差值的关系,来形象定义离群点和交替分布度等概念。
3 差分隐私直方图发布算法
3.1 问题描述
直方图是一种有效的统计报告图,采用一系列高度不等的桶来表示相应查询范围内的统计信息情况。令A表示数据表E中的某一个属性,a∈A为属性A中的任一属性值,count(a)代表数据表中属性值为a的记录个数,则直方图为一系列统计属性值个数的计数序列。每个计数值代表直方图相应桶的频数,用频数序列H={H1,H2,…,Hn}表示,其中为数据表中的记录个数。任何一个数据表都可以根据某个属性映射成相应的直方图。
在直方图发布过程中,为了满足差分隐私并提高数据发布的准确性,通过重新划分桶的思想,合并原始直方图邻接相似的桶进行重构,并添加拉普拉斯噪音来满足差分隐私的要求。本文在相关工作中提到的目前基于差分隐私的直方图发布,主要有NoiseFirst方法、StructureFirst方法和P.HPartition方法等。然而,这些方法在重构过程中都忽略了原始直方图频数中存在离群点的问题。原始直方图中存在离群点的情况会产生较大的全局敏感性,且由于原始直方图的邻接桶频数相差过大,很少有相似的桶相互合并,这就失去了重构的意义,因此分析离群点十分必要。
这里引入以下四个定义[11]。
定义3 标准梯度值:给定一个数据集D和一个原始直方图H,是它的有序频数直方图,记集合则D的标准阶梯特征值L=count(U)+1。其中,count(U)表示集合U中元素的个数,δ为离群长度。
定义4 实际梯度值:在原始直方图H={H1, H2,…,Hi,…,Hn}中,仍 记 集 合U={i||Hi-Hi-1|}>δ,且M=count(U)+1,则称M为实际阶梯特征值。
定义5 交替分布:对于一个原始直方图H,如果M=L,则称该原始直方图满足均匀分布;如果M>L,则称该原始直方图满足交替分布。
定义6 交替分布度:给定一个原始直方图H,如果它的标准阶梯特征值为L,实际阶梯特征值为M,则定义H的交替分布度为ADD=M-L。
例如,对于一个给定的原始直方图H={31,15,14,34,12,3,16},设δ=10,那么H的标准阶梯特征值为3,而实际阶梯特征值为6,则H的交替分布度ADD=6-3=3。交替分布度是原始直方图的固有属性,定量地刻画了该原始直方图离群点的分布状态。交替分布度越大,表明原始直方图中离群点个数越多,分布得越分散,原始直方图总体分布越不均匀。离群点会产生很大的全局敏感性,离群长度δ越大,误差值越大,且随着离群点个数的增多,会使原始直方图形成阶梯分布特征,即原始直方图成交替分布。随着交替分布度的增大,对误差的影响也越大,即使现存的高效率重构方法也很难对这类原始直方图进行有效重构。总之,无论是离群点还是交替分布对直方图重构的影响,最根本的解决办法是降低交替分布度,使序列回归原始梯度。
3.2 基于桶重构的差分隐私直方图发布方法(R-G-I方法)
为了解决原始直方图中存在离群点的问题并提高数据发布精度,将差分隐私方法引入直方图发布。这种方法是在桶重构的基础上实现的,记为R-G-I分布法。在后文中将对该方法的有效性和准确性进行验证,下面对该方法的操作步骤进行简单介绍。
(1)将隐私预算参数ε划分为两部分,一部分记为ε1,一部分记为ε2。其中之一在步骤(3)中使用,使用贪心算法对相似的桶进行选择并做合并处理;另一部分在完成重构后,将拉普拉斯噪声加于直方图桶中。
(2)借助调用梯度回归算法(Gradient Regression)对原始直方图的频数序列进行满足差分隐私的排序预处理,从而降低原始直方图中离群点的影响;
(3)通过调用合并相邻桶的贪心算法(Greedy Algorithm),对进行预处理后的原始直方图进行桶重构处理,并用红黑树优化桶重构的过程;
(4)向经过步骤(3)处理后直方图的桶频数中添加适量的独立噪声进行扰动;
(5)向直方图的桶频数调用保序回归算法(Isotonic Regression)提高发布精度。
该方法主体为三个依次执行的算法,分别为梯度回归算法(Gradient Regression Algorithm)、合并相邻桶的贪心算法(Greedy Algorithm)和保序回归算法(Isotonic Regression Algorithm),取三个算法的关键词英文首字母,简称该方法为R-G-I发布方法。下面对R-G-I发布方法的三个算法进行详细介绍。
3.2.1 梯度回归算法(Gradient Regression)
下面对梯度回归算法进行介绍。
算法1:Gradient Regression(H,δ,ε)
输入:原始直方图H={H1,H2,…,Hn},δ,ε//δ为离群长度参数
输出:满足均匀分布的原始直方图H´={H1´,H2´,…,H´n}
步骤:
(1)对原始直方图H={H1,H2,…,Hn}进行升序 排序;
(2)对原始直方图的交替分布度ADD进行准确计算;
(3)分析ADD的值,若大于0,则对原始直方图的前n-1个频数进行计算和检验,当(Hi+Lapi(1/ε))-(Hi+1+Lapi+1(1/ε))>0时,需要将相邻两个H进行交换;
(4)继续重复执行上述步骤(3),当相邻两个H不能交换时停止;
(5)原始直方图H´={H1´,H2´,…,H´n}满足均匀分布的情况下将其返回;
(6)否则,直接给出原始直方图H={H1,H2,…, Hn}。
例如,原始直方图为H={31,15,14,35,12,1,17},其中设定δ=10。由于原始直方图H的ADD=3,通过算法1的计算结果为H´={1,12,15,14,17,31,35},此时H´的ADD值等于0,实现了交替分布度减少的目标。对相邻的桶频数进行加噪处理是梯度回归算法的重要步骤,而不是直接对真实的桶频数进行排序。以差分隐私条件为基础,如果原始直方图满足差分隐私所规定的条件,则可以对其做一个近似排序,输出结果以真实桶频数进行。因此,在排序过程中,隐私预算并不参与其中,也不会消耗。算法1中,进行直方图频数排序过程中,即使情况最差,对应的时间复杂度最大为O(n2)。所以,算法1的时间复杂度为O(n2),其中n为原始直方图中桶的个数。梯度回归算法通过降低ADD的值,最大程度地降低了离群点对直方图重构的影响。
3.2.2 合并相邻桶的贪心算法(Greedy Algorithm)
在进行直方图发布时,对相邻近似的桶进行合并处理,以差分隐私技术为基础,适当加入拉普拉斯噪音,从而提高数据发布的准确性。设原始直方图H={H1,H2,…,Hn},有一个包含k个桶的桶划分方案H*={B1,B2,…,Bn}中,每个桶Bj=(lj,rj,cj),其中lj为每个桶的左边界,rj为每个桶的右边界,每个桶所赋予的值用cj表示,其值可以取前j个桶的频数之和的平均值。设有k个不同的桶和序列H={H1,H2,…, Hn},将这些序列分别装入这些桶中,装入时序列的元素要满足{Hi|lj≤i≤rj}。可以看出,如果桶划分策略不同,那么分布数据将会有不同的结果,进而产生不同的误差。为了详细分析误差,定义桶划分的误差。
定义7 桶划分误差:设H={H1,H2,…,Hn}为原始直方图,H*={B1,B2,…,Bn}为桶划分方案,桶划分以划分方案为准,将划分后的直方图序列记为H´={H1´,H2´,…,H´n}。由于H´和H之间存在误差,因此将这种误差记为Error(H*,H),也就是桶划分误差。
由于上述误差有正有负,因此为了比较不同桶划分方案的合理性,需要对误差平方处理,最终以平方和误差(SSE)表示。对于每个桶,误差用Error(Bi)表示,相应的计算公式为:
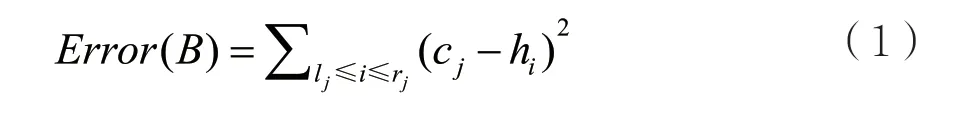
所以可以给出Error(H*,H)的计算公式:
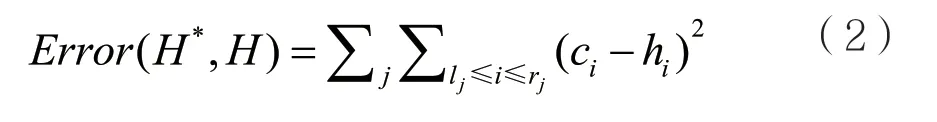
贪心策略是降低桶划分误差的一种有效方法,所以在桶合并过程中将使用贪心策略。划分过程中,如果两个相邻的桶误差最小,则将这两个桶作为合并的对象。
定义8 相邻桶的距离:将相邻两个桶进行合并必然存在一定误差,而误差会出现累计作用,将这种作用称为误差增益,即相邻桶的距离,表示为dis(Bj,Bj+1),计算公式如下:
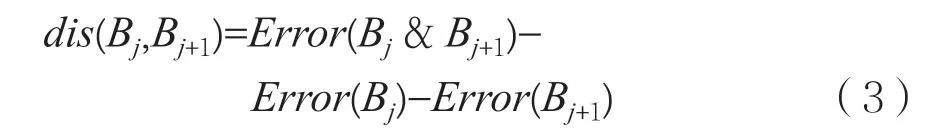
将两个相邻且欲合并的桶分别记为Bj与Bj+1,则合并后的新桶记为Bj& Bj+1。两个桶分别产生的误差分别记为Error(Bj)和Error(Bj+1),而两个桶合并之后的误差记为Error(Bj& Bj+1)。
数据的失真程度会因桶划分策略的不同而不同。相关文献中对桶划分策略进行了设计[9],但是由于算法采用动态规划策略寻找最优的桶划分方案,算法执行效率不高。如何设计有效的桶划分策略且不使数据失真,是本文研究的重点。
本文首先考虑将原始直方图H的m个数据放进m个桶,此时m和k相等。其次,对两个相邻的桶进行合并,采用的策略是贪心策略。众多桶被合并后,桶的数量逐渐减少,最终形成m个不同的合并桶,相应的需要使用m个不同的划分策略,将这些划分策略分别记为Hm,Hm-1,…,H2,H1,。由于优劣程度不同,因此总会存在一个最优策略。为此需要从中选择一个最优的划分策略,并对其他策略的优劣进行评价。采用文献[9]中的方法进行评价,即:
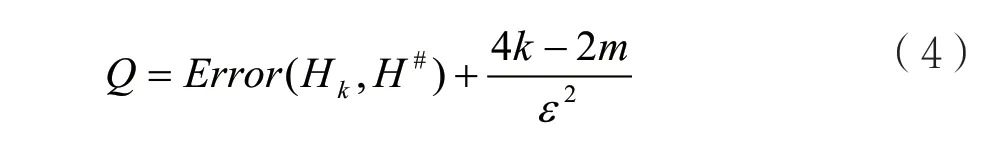
桶划分策略越好,对应的Q值越小。实际选取时,桶可能不是最相邻的。因此,为了保证两个桶是相邻的,需要对两个桶的距离进行计算,将两个桶分别记为Bj与Bj+1,则距离表达式为dis(Bj,Bj+1),具体操作方法如下。
算法2:桶划分贪心算法(Greedy Algorithm)
输入:原始直方图H,差分隐私参数ε
输出:经过优化处理后的带噪声计数序列H#作为输出。
步骤:
(1)设k为桶的数量,初始化时k=m,把H的m个数据序列元素分别放入k个桶中;
(2)对两个桶的距离dis(Bj,Bj+1)进行计算,采用贪心算法,最终将两个最相邻的桶进行合并处理,从而使总桶的数量减少1个;
(3)重复操作上述步骤(2),如果满足k=1,则停止,同时将Q最小的取值记为k*;
(4)求得桶内所有元素的平均值,并将该值赋予给桶内每个元素,然后将m个新值赋予到M´,并对该值进行输出;
(5)向新生成的直方图M´的每一频数添加独立拉普拉斯噪声Lap(1/ε),得到矩阵H#;
算法2的时间复杂度涉及到下面几个方面:原始数据表T首先需要转换为初始直方图H,该过程需要消耗一定的时间,将相应的时间复杂度记为O(n);将拉普拉斯噪声加入到序列M中,可以得到序列H#,该过程也需要消耗一定的时间,将相应的时间复杂度记为O(m);采用多种不同的桶划分策略,这里将其数量记为m,在具体寻找两个相邻的桶时,需要使用枚举法,从而对两个桶机进行合并处理,该过程需要消耗一定的时间,相应的时间复杂度记为O(m2)。因此,可以将上述时间复杂度进行综合,从而可以得到算法2的时间复杂度表达式应是O(n+m2)。
3.2.3 保序回归算法(Isotonic Regression)
在重构序列中添加噪声进行扰动达到隐私保护的需求,但这个过程不仅对每一个序列值造成了一定的信息丢失,而且破坏了序列的排序约束[12]。如果在噪声扰动后的序列上按照原始序列的排序约束进行校正,不会对直方图的隐私特性有任何破坏,反而可以提高直方图序列的精确度,从而提高直方图的查询精度。依照排序约束进行序列校正的过程是采用保序回归算法实现的。
保序回归[13](Isotonic Regression)是数值分析中经常用到的一个方法,使用一个最小的数据校正量来保证数据的有序性。将保序回归算法运用到基于差分隐私的直方图发布中,这里设一个任意序列为S,欲得到的有序序列为s´。两个序列满足||ss´||最小。当1≤i≤n时,s´[i]和s´[i+1]满足关系s´[i]≤s´[i+1]。下面介绍序列s´的确定过程。首先对序列s的第一个元素进行校验操作,遇到无序子序列时,求该子序列的平均值,进而用平均值进行替换,然后将其和后一个数值进行比较,判断是否有序。重复上述步骤,直到完成所有数据的检验。该操作过程可以用算法表示,具体如下。
算法3:基于差分隐私的保序回归算法
算法输入与输出:原始序列S、有序序列s´
步骤:
(1)记录下序列S的原始序列和S的升序形式R;
(2)对原始序列S进行加噪得到加噪后的序列S*;
(3)记录序列S*的升序形式R*;
(4)查看R*中失序的数值,将所有失序的数值去掉,以其平均值取代每一个失序的数值,生成新的序列R**;
(5)对R**中的数值按照S的初始序列恢复,生成有序序列s´,算法结束。
下面举例说明差分隐私直方图发布中保序回归算法的实现,计算中数据保留两位小数。
(1)假设加噪声前的原始序列S为{3,2,2,5,4,1,2};
(2)对S的值按照升序排列则变为{1,2,2,2,3,4,5};
(3)加噪后的原始序列变为{3.12,2.03,1.98,5.25,4.17,2.53,2.21};
(4)对加噪后的序列再按升序排列,结果为{2.53,2.03,1.98,2.21,3.12,4.17,5.25}。显然,加噪后由于噪声大小存在一定的随机性,S中最小的数1变成了2.53,超过了S中比1大的三个数2.03、1.98和2.21。
(5)根据保序回归算法3,以其平均值2.19取代乱序的四个频数2.53、2.03、1.98和2.21。
(6)那么加噪后由小到大的序列变为{2.19,2.19,2.19,2.19,3.12,4.17,5.25},恢复了正常序列。
(7)对步骤(6)中产生的序列按照初始序列S的顺序进行恢复,得到算法的最终序列s´={3.12, 2.19,2.19,5.25,4.17,2.19,2.19}。
序列s´的排序约束是全部过程实现的基础。为了保证噪声干扰后的分量和干扰前的排序相同,需要引入最小校正分量。采用上述方法可以获得噪声误差 E rror ( D,)=2.186 4,该误差是没有使用保序算法的误差,而经过保序算法处理后的噪声误差记为Error(D,Hs),相应的值为1.293 2。因此,和没有经过处理的相比,降低明显。误差降低的幅度和付出的代价相比是合理的。对于实际的应用,保序回归算法更具有价值。
4 实验结果与分析
基于本课题为上海市科委“科技创新行动计划”项目——基于大数据的慢病管理平台数据安全和隐私保护的子课题,因此实验数据源选用项目合作方上海万达信息有限公司的慢病数据库中的病历数据。
为了使数据具有代表性,采用的实验数据采用3种不同的数据集。数据集Age是慢病数据库中的年龄属性的统计集,记录数量为10 247 691,分为103个桶,分别对应103个年龄;数据集Location是数据库中慢病病人的户籍所在地的统计集,共186 461个记录,精确到村或者街道,分为3 829个桶,对应3 829个镇或者街道;数据集Social network为数据库中糖尿病病人相互之间的亲友关系的统计集,共81 793条记录,对应18 639个桶,也就是18 639个病人,如表1所示。

表1 数据集规模
实验的硬件环境为Intel(R)Core(TM)i7 CPU,8 GB内存,操作系统平台为Windows 7操作系统,采用Python语言实现所有方法。
为了说明本文提出的R-G-I方法能够在差分隐私保护下保证发布携带离群点直方图数据的准确性,本实验将R-G-I方法分别与NoiseFirst、StructureFirst、P.HPartition三种方法进行比较(以下分别简称RGI、NF、SF、PHP方法)。采用MSE(MSE为查询指定范围内各种算法输出的直方图与原直方图各个桶频数的查询误差平方和的均值)指标来衡量在不同查询范围内数据发布的准确性。为了使实验更具说服力,每种算法均运行20次,取总次数实验结果的均值作为该算法的最终结果。因此,在同样的隐私保护级别下,本实验更关注数据发布结果的准确性。
4.1 验证R-G-I方法中降低交替分布度算法(Reduce ADD)的有效性
针对含有离群点的原始直方图,为了消除离群点产生较大的交替分布度对直方图重构的影响,本文给出了梯度回归算法。本组实验主要用梯度回归算法分别将传统的直方图发布算法(NF、SF、PHP)输入的原始直方图进行预处理,并且通过对比预处理和未预处理后的实验结果,验证梯度回归算法的有效性。实验结果如图1~图3所示。

图1 Location数据集上对比实验结果(ε=0.01)
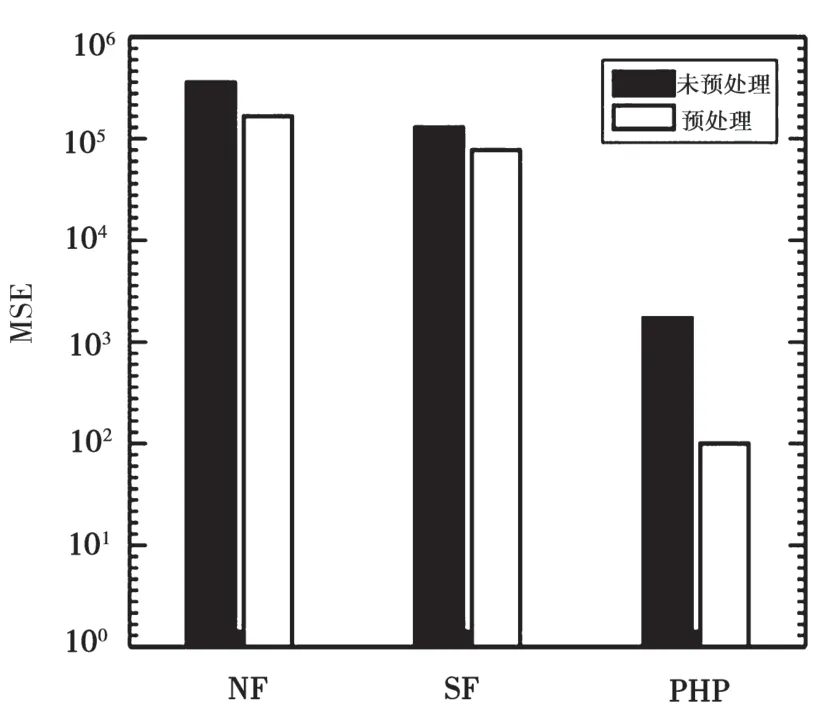
图2 Location数据集上对比实验结果(ε=0.1)
可以看到,深色柱代表直接采用现存的直方图发布算法作用在Location数据集上的MSE误差值,空柱代表将Location数据集先采用Reduce ADD算法进行预处理后,再采用NF、SF、PHP三种方法的MSE误差值。由于隐私预算ε越大,说明隐私批漏风险越大,隐私保护程度越小,则数据发布准确性越高,因此可以发现参数ε越大,所有方法的MSE误差值越小。然而,无论参数ε(O.01、0.1、1)取何值,对数据集进行预处理的MSE值都要小于未进行预处理的MSE值。因此,本实验验证了梯度回归算法通过降低交替分布度最大程度地降低了离群点对直方图重构的影响。
4.2 验证四种方法作用在四类不同的数据集上的MSE值的差异
MSE越小,表示数据发布的准确性越高。每种方法设置隐私预算参数分别为0.01、O.1、1。设计数据集Location、Social Network的查询范围为100~500,Age的查询范围为0~100且间隔相同的查询函数。
本组实验中,主要检验各个方法在不同查询范围下的查询结果,该组实验中采用MSE衡量数据发布的准确性。图4~图6给出了不同隐私预算下作用在四种数据集的MSE结果。其中,横坐标代表三种数据集,纵坐标代表误差值。ε越大,表明隐私保护水平越低,数据发布的准确性越高,MSE值也相对越小。实验结果可知,R-G-I方法的MSE值较其他三种方法明显要小,显著地提高了数据发布精度。
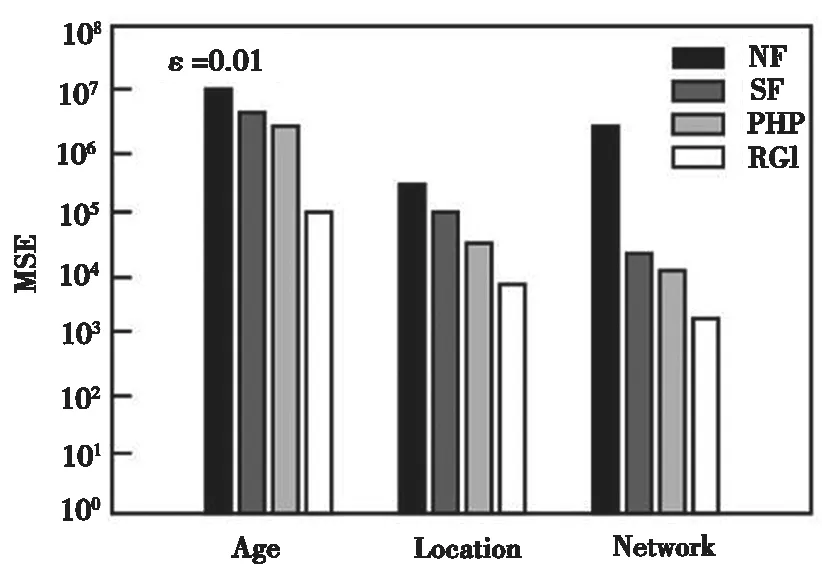
图4 四种方法的MSE值比较(ε=0.01)
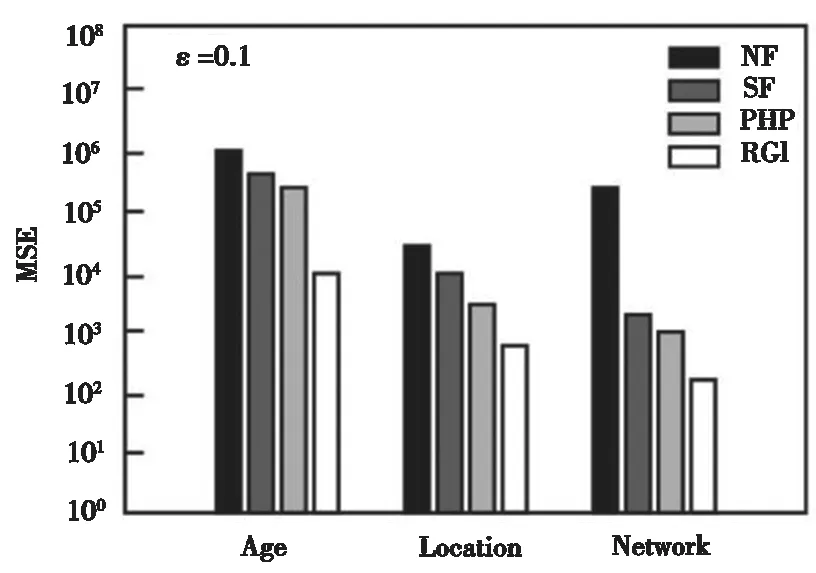
图5 四种方法的MSE值比较(ε=0.1)
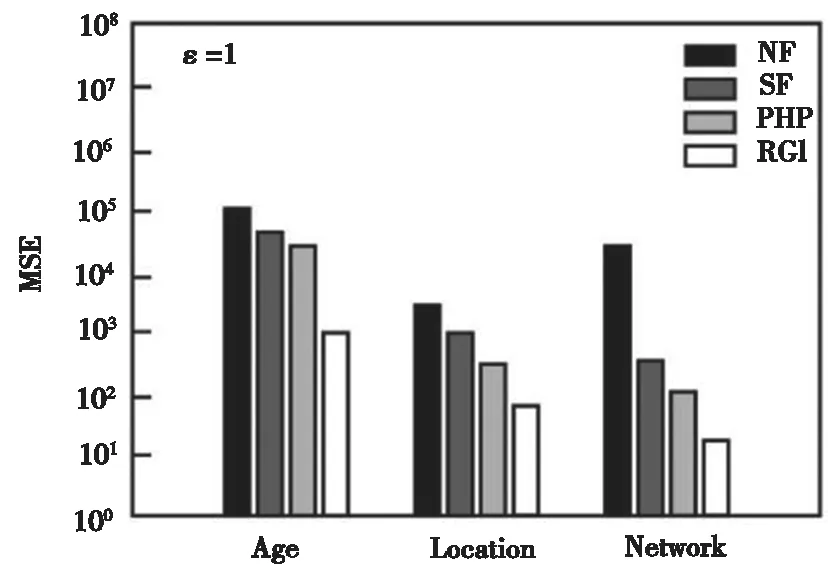
图6 四种方法的MSE值比较(ε=1)
5 结 语
本文针对存在离群点的差分隐私直方图发布,提出了一种基于桶划分的R-G-I方法。该方法包括三个重要的算法——梯度回归算法、基于桶重构的贪心算法和保序回归算法。其中,梯度回归算法主要是对原始直方图进行满足差分隐私的排序,从而减小交替分布度;贪心算法主要采用指数机制每次选择直方图中最相似的两个邻近桶进行合并,最后通过加入拉普拉斯噪声对重构后的新桶频数进行扰动;保序回归算法在噪声扰动后的序列上,按照原始序列的排序约束进行校正,提高了直方图序列的精确度,从而提高了直方图的查询精度。最后,采用不同特点的真实数据集进行实验,实验结果验证了提出的R-G-I方法针对含有离群点的数据集的准确性和有效性。
