自然语言建筑设计规范条文的规则表达式自动提取方法
2019-03-02余宏亮骆汉宾
魏 然, 舒 赛, 余宏亮, 骆汉宾
(1. 华中科技大学 土木工程与力学学院, 湖北 武汉 430074; 2. 武汉科技大学 管理学院, 湖北 武汉 430081)
基于BIM(Building Information Modeling)的建筑专业施工图合规性自动审查系统借助计算机和BIM技术,利用建筑三维模型的先天优势,快、全、准地检查出BIM模型中的设计问题,改变了传统的人工审图模式,提高了审图效率。其中,将自然语言编写的建筑设计规范条文转换为计算机可理解并执行的格式,即提取规范条文的规则表达式是建立基于BIM的建筑专业施工图合规性自动审查系统的关键步骤。近年来,我国在施工图合规性自动审查领域也获得了一些成果,而规范条文的规则表达式提取方法却一直停留在人工处理或半自动化阶段。由于我国现行的建筑设计规范条文数量庞杂、自然语言表达的复杂性,造成人工提取过程容易出错、修正过程复杂且效率低下。对后续的计算机自动审查工作造成不利的影响。而将人工处理过程转换为计算机执行的自动提取过程可大大提高正确率和效率,特别在规范条文修订后能自动生成相应计算机可理解并执行的规则。
国内外专家学者对规范条文规则表达式提取问题展开了较深入研究。Lee H. 等[1,2]通过基于逻辑规则机制的管理系统KBimLogic,将自然语言规范条文转化为计算机可执行的规则集文件KBimCode;Lee J. M. 等[3,4]采用专家系统的模型,将每一条规范简化成一个产生式规则形式(IF-THEN结构),从而将规范条文构建成知识库;Uhm等[5]在自然语言的处理过程中部署了上下文无关文法,制订了计算机解读需求建议书(Request for Proposal,RFP)的规则;Guo等[6]建立了安全规范和BIM模型设计组件的编码规则,根据编码将自然语言规范和设计组件一一对应;Nawari[7]提出了一阶逻辑(First-Order Logic,FOL)作为文本规则编码的建模语言;Zhang J. 等[8]提出了一种基于语义,基于规则的自动信息提取(Information Extraction,IE)方法NLP(Natural language processing)和基于短语结构语法(Phrase Structure Grammar,PSG),利用本体识别语义文本特征从而达成自然语言的自动化处理;Zhong B. T. 等[9]提出建筑质量检验和评估元模型CQIEOntology,通过使用Protégé-OWL(Web Ontology Language)的“SWRLJessTab”插件将基于CQIEOntology中的SWRL(Semantic Web Rule Language)规范约束和OWL中的本体事实转换为Jess规则。
国内外专家学者在英文、韩文自然语言的规则表达式提取问题上已取得了丰富成果,但相较于英文、韩文,中文自然语言由于没有固定的语法结构和表达模式,上述针对英文、韩文的研究成果无法直接用于中文自然语言的处理上。而在中文自然语言规则表达式提取问题上,目前以基于本体的知识建模[10,11]和专家系统建模[12]为主。但两种方法都需要领域专家花费大量时间进行本体推理或构建模型,且面对复杂的本体推理与模型构建,容易出现纰漏。因此,本文在相关研究的基础之上,借助上下文无关文法对建筑设计规范条文进行语法分析,从最小的语法单位“语素”中推导出提取规范条文规则表达式所需要的对象和方法,通过将对象(语素)构建成语素库,根据每条规范中语素的种类及数量自动判别并选取方法库中所对应的方法,实现无需人工参与的建筑设计规范条文规则表达式自动提取方法。
1 建筑设计规范条文规则表达式提取方法概述
在建筑工程领域,我国已经形成了包含标准化主管部门颁布的标准和工程建设标准在内的完善的建筑规范体系[10],但由于规范知识的组织维度单一、约束内容分散、各规范之间内容互相引用以及规范不断发展修改等特点导致难以全面地使用建筑规范。为了解决上述问题,本文按照建筑规范的适用建筑类型选取了包括GB 50352-2005《民用建筑设计通则》、GB 50096-2011《住宅设计规范》、GB 50763-2012《无障碍设计规范》等16篇规范作为研究基础,涵盖了普通住宅、高层建筑、幼儿园、学校、医院等建筑类型,避免了规范条文的重合,又保证了约束内容的广泛性。
提取规范条文规则表达式的关键在于从规范条文中推理出提取的方法[5]。在自然语言中谓语动词是对动作或状态进行陈述说明,决定了一条语句的逻辑规则。由于中文复杂的表达习惯,同一个谓语动词所处语境不同,其表示的关系也不同。如规范“车站应设置无障碍电梯”和“单人病房应设置四个窗户”,前者“设置”表示存在关系;后者“设置”表示数量关系。因此本文根据谓语动词所表示的关系来判断推理以规范条文规则表达式的提取方法。
提取建筑设计规范条文规则表达式的最大挑战是面对庞杂的中文建筑设计规范条文。面对数量如此庞大的规范条文,必然要对规范进行分类。本文通过对动词的分析,将规范按照动词所表达关系的不同分为元素存在类、元素数量类、空间距离类、空间位置类及属性约束类,从一个句子的规则表达式的提取推广为这一类规范的提取方法,解决了建筑设计规范数量大的问题。
2 建筑设计规范条文规则表达式提取方法
2.1 规范条文预处理
考虑到部分规范条文句子中含有不止一个设计规则,如GB 50352-2005《民用建筑设计通则》第6.8.1条规定3:单侧排列的电梯不宜超过4台,双侧排列的电梯不宜超过2×4台;电梯不应在转角处贴邻布置。本文首先将这些包含多个设计规则的规范条文筛选出来并人工进行规范条文的预处理,使之成为仅含有一个设计规则的句子。
通过分析规范条文可以得出判断依据:一般地,除了单个句子中存在几个条件的情况下,当一个规范句子中出现两个及以上的建筑构件或建筑构件属性的自由组合时,那么这个规范句子包含两个及以上的设计规则。
借助中文分词系统 (Instituteof Computing Technology,Chinese Lexical Analysis System,ICTCLAS)对文档中的事实和关系识别、标注,并利用文本工程通用框架(General Architecture for Text Engineering,GATE)进行知识抽取[13],可实现规范条文的自动预处理。
此外,还存在部分表格形式的规范,这些表格的内容已通过专业人士精炼且以计算机可理解的形式整理在表格中,故表格类的规范不作为本研究的规范条文基础。
2.2 基于上下文无关文法的规范条文语法分析
文法是语言语法的描述工具,是描述语言语法结构的形式规则。Chomsky将文法分为:0型文法、1型文法、2型文法、3型文法。其中应用最广泛的是2型文法,即上下文无关文法。上下文无关文法是一种所定义的语法范畴(或语法单位)是完全独立于这种范畴可能出现的环境的一种文法。本文使用此文法进行语法分析,可避免中文句子中各词之间相关联而造成歧义的问题。且上下文无关文法拥有足够强的表达力来表示绝大多数程序设计语言的语法,更利于后续的程序开发。
在完成规范条文的预处理后,本文借助上下文无关文法将规范条文进行语法分析。如图1所示,名词“车站”和“无障碍电梯”是规则表达式所需要的对象,而动词“设置”表示一种存在关系,情态词“必须”表示语气的强度。因此计算机可理解的该规范条文的知识内容为:“车站”中必须存在“无障碍电梯”。

图1 基于上下文无关文法的语法分析
通过查阅规范发现,存在一类规范如“候梯厅深度不得小于1.50 m”缺少了谓语动词。通常一个完整的句子结构应包含主语、谓语、宾语。一个句子若没有谓语动词,那么我们无法从该句子中分析出“方法”。为此,本文对规范“候梯厅深度不得小于1.50 m”构建语法树,结合规范的英文译文,按照名词、动词、介词等将中英文句子成分一一对应,如图2所示。通过比较观察可以发现除了动词“be”没有相对应的中文词语,其余中英文词语皆可一一对应,可以得出省略掉的中文谓语动词为“是”。
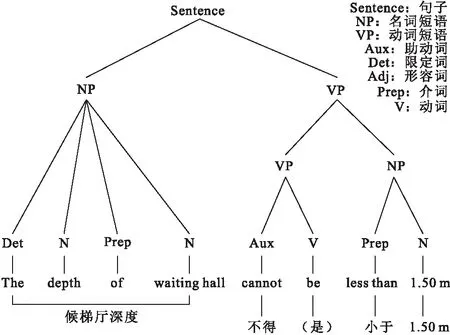
图2 基于上下文无关文法的语法分析
该规范条文中,“候梯厅”“深度”“1.50 m”是规则表达式所需的对象,“不得”和“小于”分别表示否定语气和比较关系,省略掉的动词“是”表示属性约束关系。因此该规范条文计算机可理解的知识内容为:“候梯厅”的几何属性“深度”的数值不得小于“1.50 m”。
2.3 规范条文语素分析
在语法分析的基础上,本文将上下文无关文法分解产生的语素进行详细分析,包括名词、情态词、比较词、形容词和动词,用于构建对象(语素)库和方法库。
名词是用来表示人或事物实体存在的词。本文根据IFC(Industry Foundation Classes)标准并结合《建筑设计术语标准》将规范中的名词分为空间(Space)、元素(Element)、属性(Property)和数值(Value)。空间指实际上或理论上的一个领域或体积,如“房间”;元素指建筑物的结构和空间分隔系统,如“窗户”;属性指建筑构件的属性,如“深度”;数值则是由数字及单位所构成,如“1.50 m”。
情态词,用来表达人对这一动作或状态的看法或主观设想,是一个表示语气的词。由于中文规范的表达形式没有统一标准,加上中文的复杂性,不同语气程度条件下的情态词表现形式也有所不同。如宜、不宜等表示建议;应该、不应该表示要求;必须、禁止等表示命令。导致了情态词的例子多不胜数。但在实际的规范检查中,这些词往往仅分为两类:一是表达肯定,如宜、应该、必须等都表达了肯定的、正确、允许的意味;二是表达否定,如不宜、不应该、禁止等,虽然语气轻重不一样,但都表达了否定、错误、禁止的内涵。通过分析,确定了表达肯定性质的计算机可理解并执行的情态词表达为“=”;否定性质的计算机可理解并执行的情态词表达为“!=”。
比较词,用来表示二者的关系大小,常与数值连用。包括大于、等于、小于等。
形容词,用来描写或修饰名词或代词,表示人或事物的性质、状态、特征或属性。在规范句子中,修饰名词形成专业名词,在本研究中将形容词与名词所构成的专业名词作为名词考虑。如无障碍电梯。
动词是用来表示人或事物的动作或一种动态变化的词。规范条文中的动词连接了句子的主语和宾语,表现了主语的存在、主语与宾语的关系等。本文根据动词所表现的关系不同,将动词分为:元素存在类、元素数量类、空间距离类、空间位置类及省略了动词“是”的属性约束类。将动词所表现的关系转换为方法的方式主要有两种:一是Boolean型,例如可以用“hasElement”方法检查规范“车站必须设置无障碍电梯”,若空间“车站”中存在元素“无障碍电梯”,则函数返回“True”;若不存在,函数返回“False”。二是Long型,例如检查规范“单人病房应设置四个窗户”,可以用“getNumberOfElement”方法,如果病房中窗户的数量为4,则函数返回“True”,反之返回“False”。且两种函数返回的结果“True”和“False”与施工图审查结果“合规”和“不合规”高度符合。
2.4 规范条文规则表达式推理
在语法分析及语素分析的基础之上,对各类别建筑设计规范条文规则表达式进行推理。虽然五种类别分别包含大量的规则句子,但每种类别所依据的算法思路、所用到的关键方法函数都高度相似[14],只要能解决一种类别中的一个规则句子的规则表达式提取方法,那么这一类的规则表达式提取问题都能得以解决。
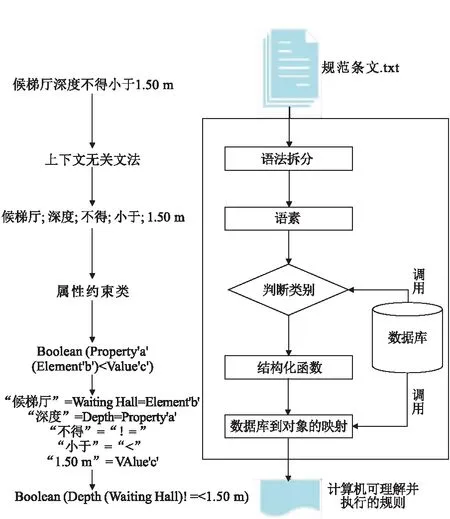
以属性约束类规范 “候梯厅深度不得小于1.50 m”为例。省略掉的动词“是”表示属性约束关系,结合情态词“不得”和比较词“小于”的计算机可理解并执行的表达“!=”和“<”,得出规则表达式为:Boolean(Depth!=<1.50 m);属性“深度”不是单独存在,而是用于描述元素“候梯厅”的几何属性,因此最终的规则表达式为:Boolean (Depth(Waiting Hall)!=<1.50 m);那么,属性约束类规范的规则表达式为:Boolean (Property‘a’(Element‘b’) 表1 各类别规范的规则表达式 本文选取了GB 50352-2005《民用建筑设计通则》和GB 50763-2012《无障碍设计规范》中电梯相关规范条文作为一个案例,来阐述自然语言建筑设计规范条文规则表达式提取如何实现。 首先,本文将名词按照元素、属性、空间和数值四种类型,情态词按照性质肯定或否定及比较词根据计算机可理解并执行的表达构建语素库;其次,将五种类别的规则表达式及其自动判断依据构建方法库;最后,导入的规范条文TXT文本通过调用方法库,自动判别规范类别并调用该类别规则表达式,调用语素库,实现表2到实体的映射,完成规范条文规则表达式的自动提取。 采用Java(hibernate框架)实现从类对象到数据库的映射。以名词为例,定义名词类为类A,A中的成员变量有三个。第一个是pri,定义为String型,用来存储Element,Property,Space,value;第二个变量是comp,是list集合类型的变量,用于存储{候梯厅,电梯,...}、{深度,宽度,...}、{房间,住宅,...}、{1.50 m,60 cm,...};第三个变量是Translate集合类型的变量,与第二个一一对应,{Waiting Hall,Elevator,...}、{Depth,Width,...}、{Room,Resident,...}、{1.50 m,60 cm,...},并且构造定义类的get和set方法,用于读取数据和操作数据。 Public class A { Private String pri; Private ArrayList Private ArrayList Public long getPri() { 在高速公路沥青路面施工过程中,考虑到道路上下层结构的铺设需要使用不同配比的沥青材料,所以,上下层沥青材料的生产过程必须分开进行,为了提高施工效率,可以通过同时运转2台搅拌机来生产不同配比的沥青材料,从而为高速公路沥青路面的施工提供合格的施工材料,进一步保障高速公路沥青路面施工的质量。 return pri; } Public void setPri(long pri){ this.pri=pri; } Public ArrayList Return comp; } Public void setComp(ArrayList this.comp=comp; } } 配置类与数据库的映射。定义一个数据库的表与类完成映射,X为表名,定义表中的属性与类成员变量一一对应,其中pri变量对应表的主键Prj。 定义一个初始化类,构造一个初始化方法,完成写库操作,这里使用的数据库为Oracle数据库,客户端使用的是Navicate,最终保存的数据库如表2所示。 表2 数据库X 在语素库的基础上,根据推理出的各类规范规则表达式及其判断依据使用Switch语句来自动判断规范条文的类别。 虽然规范条文各不相同,但每一类规范条文中的元素(E)、属性(P)、空间(S)、数值(V)以及比较词(C)的数量是一定的。因此通过判断各类规范中元素、属性、空间、数值以及比较词的数量,间接判断了规范的类别。首先设置表达式n(通常是一个变量)。如case属性约束类,元素的数量为1;属性的数量为1;空间的数量为0;数值的数量为1;比较词的数量为1。其余的判断依据如表1所示。随后表达式的值会与结构中的每个 case 的值做比较。如果存在匹配,则与该 case 关联的代码块会被执行。将五类判断依据构建至方法库中,实现了规范条文规则表达式的自动判别与调用。 在已构建的语素库与方法库的基础上,通过将经过预处理后的电梯相关规范条文TXT文本导入系统,如图3所示。 图3 规范条文TXT文本的导入 系统根据规范条文中的元素(E)、属性(P)、空间(S)、数值(V)以及比较词(C)的数量,自动判别规范的类别,进而得出每一条规范相对应的规则表达式。通过调用数据库,实现表到实体的映射,完成规范条文规则表达式的自动提取。导出结果如图4所示。 图4 规则表达式的导出 以规范条文“候梯厅深度不得小于1.50 m”为例,详细介绍系统内部处理过程。调用数据库,通过判断句子中各类词的数量,得出该规范条文属于“属性约束类”,决定了最后的输出规则表达式形式为Boolean (Property‘a’(Element‘b’) 图5 系统处理流程 本文阐述了一种支持中文自然语言的建筑设计规范条文规则表达式自动提取方法。通过借助上下文无关文法对规范条文进行语法分析,得出“属性约束”类规范因表达习惯而省略的谓语动词“是”,解决了该类规范没有动词无法进行“方法”推理的问题;对语素进行分析,将建筑设计规范条文分为了五类,推理出各类计算机可理解的规则表达式及其自动判别方法,并构建了语素库和方法库,实现了建筑设计规范条文规则表达式的自动提取,尤其在规范条文增加或修订后,仅需确认是否需要向语素库中添加新的语素,即可实现新增规范条文规则表达式的自动提取。
3 应用案例
3.1 构建语素库

3.2 构建方法库
3.3 规范条文规则表达式自动提取

4 结 语
