动物实验Meta分析的数据处理
2019-03-02尚志忠姜彦彪赵冰张哲文张婷张俊华马彬
尚志忠,姜彦彪,赵冰,张哲文,张婷,张俊华,马彬
目前,开展动物实验Meta分析已被认为是探索提升动物实验对临床研究指导价值的有效途径,可有效降低其结果向临床转化时的风险[1]。但由于动物实验与临床试验间存在一定差异[2],使得动物实验Meta分析在方法学标准等多个方面与临床研究不同。在对动物实验进行Meta分析时,可参考临床试验Meta分析的方法学,但需要针对动物研究特点进行调整和优化[3]。因此,本文主要介绍动物实验Meta分析中异质性的来源、相关数据处理等问题,以期为动物实验Meta分析提供一定的指导。
1 动物实验Meta分析和临床试验Meta分析的区别
由于动物实验的特点,使得动物实验Meta分析与临床试验Meta分析在研究目的、数据效应量的选择、异质性的来源等多个方面存在差异(表1)[4]。
2 动物实验Meta分析的步骤

表1 动物实验与临床试验Meta分析的区别
动物实验Meta分析步骤主要包括5个步骤:①纳入研究间异质性评估;②数据收集及效应尺度选择;③选择合理的统计分析模型;④减小与评估发表偏倚;⑤数据结果呈现并作出相应的解释。
2.1 纳入研究间异质性评估由于动物实验Meta分析通常解决是比原始研究更广泛的研究问题[5],因此,纳入的研究在动物种属、结果类型、测量时间等方面具有多样性。为了能够对某一特定的研究问题提供有指导意义的证据,进行Meta分析的研究必须在研究对象、干预措施、实验设计和结果等方面具有充分的同质性[6]。因此,在合并统计量前,需对纳入研究进行异质性检验。通过前瞻性定义严格纳入和排除标准,并对相似研究进行合理的比较,可减少/降低异质性。此外,如果Meta分析是以研究影响总效应量的因素或关注研究特征和结局指标间的关系为目的,则可包括更多异质性较大的研究。
2.1.1 异质性的来源动物实验Meta分析中,异质性可分为研究内和研究间两方面。动物实验研究内异质性主要来自:①研究对象:同一种属或品系动物在饲养过程中因疾病或外界环境影响,在实验过程中其对相同干预措施及环境因素的反应存在差异;②动物安置:实验动物安置的不同可导致其生存条件的差异,如当饲养动物的笼子处于不同高度或位置时,其光照强度与温度等均存在细微差异,亦若在动物饲养过程中研究人员未对动物进行随机化安置,则造成动物因不同的外界环境而产生不同的反应[7]。
相较于动物研究内的异质性,动物研究间异质性更明显,主要包括:①研究对象:各研究间纳入/排除标准的差异,实验动物所代表的群体差异,实验规模的大小、实验场所不同以及对照个体的选择所造成的差异等。②干预措施:药物的剂量与剂型、给药途径与时间、干预措施的组合方式与作用时间的差异等。③实验设计:如实验动物是否随机分组、隐蔽分组是否正确、是否实施盲法、样本大小是否合理、实验动物模型是否充分一致、实验过程中对结局指标的定义和测量方法是否一致、纳入研究可能由于研究目的不同导致对实验动物的选择、数据的收集与评价的倾向性出现差异;④统计学:因随机误差和多种偏倚的存在,动物实验结果仅能近似反映研究的真实效应。若研究结果与真实效应的差异超出了随机误差的范围,则会导致各研究间存在较大统计学异质性。⑤结果合并:不同种属动物,由遗传决定的生物学基础不同,在解剖结构、代谢过程、疾病的发病机制等方面均存在差异,则需考虑合并的合理性;不同种属或品种的实验动物的结果合并后能够代表何种动物的合并结果,其代表的研究总体是否产生了更大不确定性;是否需要限定最低的样本量以使各研究具有较好的同质性和代表性;研究所得的结果及结论是否真实可靠,结果报告是否充分正确。此外,虽然使用多个种属动物模型的研究可探索或全面评估干预措施的有效性和安全性,但不同研究的动物模型是否足够标准化或是否使用了公认而稳定的模型以降低研究间异质性。
2.1.2 异质性的检验与处理Meta分析仅对符合纳入/排除标准,探索相同主题的研究进行统计合并。异质性的存在影响各研究之间效应量的合并,若不能对研究间存在的异质性加以控制,或进行合理解释和分析,将严重降低Meta分析所得结果和结论的可信度[8,9]。因此,必须对纳入研究的异质性进行评价,包括异质性检验和异质性处理两个方面。
①异质性检验的方法异质性检验的方法包括定性和定量两种,其中定性方法有图示法,包括森林图、拉贝图、星状图,可以直观观察研究之间是否存在异质性[10];定量统计分析方法包括Q检验,I2和H检验,可准确检验异质性大小[9]。若经上述方法检测出研究间存在较大异质性(P<0.05或I2>50%[11]),可通过亚组分析、Meta回归分析等方法探索异质性的来源并对异质性进行处理[12]。
②异质性处理动物实验研究的亚组分析是根据一定的研究水平变量(如研究设计、研究对象、干预措施的种类等)将研究分为若干亚组,然后对每个亚组分别进行效应量的合并以探讨异质性的来源[13]。亚组分析等同于Meta回归分析中实验水平上的分类协变量。一次亚组分析仅能分析一个变量,而动物实验通常样本量较小而异质性较大[4],过多亚组分析会导致Meta分析变得复杂而难以理解,因此,宜采用Meta回归分析探索异质性的来源以简化分析步骤。
Meta回归分析是以研究结果的估计为因变量,一个或多个研究水平变量为自变量,采用回归分析的方法探讨各变量对Meta分析中合并效应的影响,以明确各研究间异质性的来源的研究[13,14]。因其属于Meta分析的一部分,需遵守Meta分析的一般规律,符合Meta分析的特点;同时,也要符合回归分析的一般规律,如样本量不能过小,否则会降低检验效能。此外,Meta回归分析也存在局限性,包括混杂偏倚、测量误差、无法获取所需的全部信息资料,假阳性结论等[15,16]。
2.2 数据收集及效应尺度选择[17,18]
2.2.1 二分类数据及效应尺度选择对于各实验组只有两种结果,如死亡或存活、治疗成功或失败等,可选择比值比(OR)、相对危险度(RR)、危险差(RD)为合并统计量。若不能获得总样本量和目标事件发生数,仅报告OR或RR值及其95%可信区间(CI)、标准误(SE)或P值,则可通过经典的方差倒数法合并数据[3]。OR、RR值作为相对效应尺度指标,其不受基线风险的影响,具有较好的一致性。但某些情况下相对指标不能反应事件的真实风险情况,易夸大研究结果的效应,如实验组中某种不良反应的发生率为0.8%,对照组为0.08%,此时RR=10,此时若单独报告RR=10,则意味着非常强的联系,难以接受干预措施的风险,但如果计算RD,其数值仅为0.72%。RD值适用于研究对象的基线特征具有较好的一致性,当所研究的结局事件在实验组或对照组中全部发生或为0时,此时不能计算OR和RR,可计算RD值。
2.2.2 连续型数据及效应尺度选择若纳入研究中可提取的数据为各实验组测量结果的均数、标准差和测量结果的研究对象的数目,则可选择均数差(MD or WMD)、标准化均数差(SMD)或正态化均数差(NMD)合并统计量。①MD和WMD是以各研究间的结果测量方法或单位相同为基础计算合并效应量的大小,消除了研究间绝对值大小的影响,以原有的单位真实地反应实验效应。MD和WMD作为绝对效应尺度指标,其结果易于解释。但因其易夸大研究效应且需纳入的各研究间结果测量方法和尺度相同,导致可推广性受到限制,如某一干预措施的干预效果,使得脑梗塞体积在小鼠模型中减少10 mm3,该结果与在灵长类动物模型中同样减少10 mm3相比,小鼠疾病模型的干预效果要明显优于灵长类动物疾病模型。②NMD是将实验组干预措施产生的效应与对照组动物自身的效应进行比较,其应用的前提是对照组的动物是未接受任何干预措施的“正常”动物,且获得自身效应,同时实验组和对照组之间的效应可用比例尺度进行量化比较。NMD的计算公式为:其中和分别代表研究中对照组和干预组的平均效应,代表未接受任何干预措施的“正常”动物的平均效应。NMD的优势在于将实验组的效应与正常动物相比较,可更好地揭示干预措施的效应。但由于动物实验的样本量通常较小,且易受到随机误差的影响,导致实验效应的夸大,此时要使用矫正方法计算NMD,其具体计算方法详见 Vesterinen等[3]。若无法得到正常动物的效应,如每个高倍视野中的神经元数量,或者自发的运动行为等,此时可计算SMD[3]。③SMD既不受研究间绝对值大小的影响,也不受测量单位的差异对结果的影响,适用于各研究间相同干预措施采用不同的测量方法,也适用于研究间均数差异过大的情况。
有时原始研究数据报告并非标准和充分,如研究中仅报告中位数而未报告均数;有些仅报告标准误、可信区间、四分位间距、甚至最大值、最小值而未报告标准差;有些研究报告的结局指标也不同,如有些研究报告干预前后的差值,有些报告原始数值,有些报告对数值等。因此,需要对纳入研究的数据处理后再进行Meta分析[3,16,19]。
2.3 有序数据及效应尺度选择各研究对象被分为几个有自然顺序的类别,如病情程度的“轻、中、重”等。此外,还有一种常用于测量行为及认知功能的量表所得到的“得分”的特殊类型有序数据,可作为连续型数据或有序数据进行提取。如果分类等级较少,可采用比例优势模型进行Meta分析;如果分类等级较多,可作为连续型数据进行Meta分析,也可以选取适当的切割点将其转换为二分类数据。
2.4 计数数据及效应尺度选择部分研究中报告的是事件发生的次数,如癫痫发生次数等,此类数据即为计数数据。可分为罕见事件数据和常见事件数据。对于罕见事件数据,常采用的指标是“率”,“率”常与观察时间跨度内事件发生的次数有关。对于常见事件数据,可作为连续型数据提取。当获得的频数为小概率事件时,若可获得发病率,则计算RR或RD;当频数为非小概率事件时,可将频数当作连续性变量处理。
2.5 时间事件(生存)数据及效应量的选择对于以死亡、疾病进展等某些重要事件发生的时间为结局的观察性动物实验,最好联系作者获得个体化数据,重新分析得到logHR及其标准误,然后进行Meta分析。
总之,进行Meta分析时,纳入研究的不同类型的数据均需转化为二分类或连续性变量合并分析。
3 选择合理的统计分析模型
随机效应模型和固定效应模型是基于不同的假设对研究结果进行合并的两种统计方法。固定效应模型假设纳入研究间的差异仅由随机误差引起,各研究具有相同的潜在真实效应;随机效应模型允许各研究间因研究特征等方面的差异而存在不同的潜在效应[20],其比固定效应模型具有更宽的可信区间。
统计分析模型的选择取决于纳入研究间异质性的大小。若各研究间存在的异质性较大,则需通过亚组分析、Meta回归分析等探索异质性的来源,使之达到同质后再使用固定效应模型;若经过异质性分析和处理后,各研究间的异质性依旧较大,则考虑选择随机效应模型。动物实验因其研究性质和多样性,导致各研究间通常具有较大的异质性,宜选择随机效应模型进行统计分析[2]。
4 减小与评估发表偏倚
虽然发表偏倚在动物实验和临床试验中均可能出现,但在动物实验中可能更为严重[21]。相较于阳性结果,阴性或中立实验结果被发表的概率较低,因此对阴性或中立实验结果的不报告会导致高估干预措施效果[22]。Sena等[23]基于发表在CAMARARDS上的急性缺血性卒中动物实验系统评价发现:约14%的原始动物实验未被发表,这些未发表的原始动物实验导致的缺失数据使其结果比实际值高估了30%。
系统化地全面收集与当前研究问题有关的全部资料是控制发表偏倚的唯一措施。对动物实验而言,除必检数据库PubMed、EMbase和Web of Science外,还应检索BIOSIS Previews等相关数据库[24]。此外,会议摘要、灰色文献、参考文献目录检索都是必要的补充检索手段。同时,可借鉴临床试验Meta分析的发表偏倚评估方法,如漏斗图法、失安全数法、剪补法、森林图法等识别动物实验的发表偏倚。
5 数据结果呈现并作出相应的解释
作为Meta分析结果的主要呈现形式,森林图中的相对效应尺度指标(RR和OR)的无效竖线的横轴尺度为1,绝对效应指标(如RD、MD、SMD)的无效竖线的横轴尺度为0。若某个研究95%CI的线条横跨无效竖线,则该研究无统计学意义,反之,则该研究有统计学意义。每条横线直观地表示各研究的95%可信区间范围的大小,线条中央的小方块为统计量的位置,其方块大小代表该研究权重大小。以ZHOU等[25]的关于白藜芦醇对脓毒症动物模型组织中丙二醛影响的Meta分析结果为例。如图1所示,图中“菱形”为合并效应量的图示结果,“-3.10(-5.27,-0.93)”表示合并效应量及其95%CI;“Z=2.80,P=0.005”,表示假设检验中的统计量及其P值。“χ2=30.20,df=3,P<0.00001”,表示异质性检验的Q统计量、自由度及P值,异质指数I2=90%(图1)。
6 结论
相比较于单个实验动物研究,基于高质量动物研究的Meta分析的结果更为可靠,不仅可以有效评估和优选最佳的实验动物模型,避免卫生资源的浪费和实验动物的重复利用,亦可在即将开展的临床试验中计算效能时增加估计疗效的精度,降低假阴性结果的风险,从而降低动物实验结果向临床试验转化时的风险,促进其成果的转化和利用。
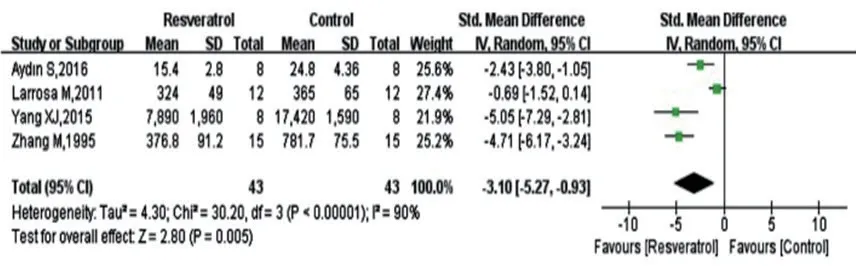
图1 白藜芦醇对脓毒症动物模型组织中丙二醛的影响的森林图
