云计算环境下安全的极限学习机外包优化部署机制∗
2019-03-01林加润殷建平张晓峰蔡志平明月伟
林加润 殷建平 张晓峰 蔡志平 明月伟
(1.国防科技大学计算机学院 长沙 410073)(2.中国人民解放军61070部队 福州 350002)
1 引言
在大数据和云计算时代,数据规模越来越大,数据类型越来越复杂,对计算的资源要求也随着越来越高。在丰富的动态数据的基础上,要挖掘大数据的价值,必然需要大量计算资源和高效的学习算法。在云计算环境中使用机器学习算法对大数据进行数据内容上的分析与计算,以低廉的价格调用云计算丰富的资源,分析数据模式并挖掘信息,已成为当前学术界与企业界的一种趋势。
极限学习机(Extreme Learning Machine,ELM)因为训练速度和较高的训练精度,其应用已经越来越普及。极限学习机是G.Huang等提出的面向单隐层前馈神经网络(Single Layer Feed-forward Networks,SLFNs)的学习算法[2~4]。ELM不仅学习速度极快,而且会达到训练误差最小的效果,同时具有最小输出权重规范,因而能够提供良好的泛化性能。其中,隐层节点的参数随机分配,输出权重矩阵可通过隐层输出矩阵的广义逆解析求解。
将极限学习机外包在云计算中,能最大限度地提高机器学习的训练速度,高效实现大数据的处理与分析。用户将数据或程序外包给云计算服务商的同时,也丧失了对数据或程序的直接控制权。然而,云计算服务商会有意或无意地对数据或程序进行分析,挖掘各种隐私信息,从用户的数据或程序中进一步获取潜在的利益。隐私泄露的潜在危险,使得云计算外包的发展受到了很大的阻碍[1]。云计算外包的隐私泄漏风险,使得用户很难在保证数据的安全隐私的同时充分利用云计算服务商提供的丰富资源。
J.Lin等[5]首先研究了将ELM外包到云计算中的安全机制。该机制一方面保证了数据隐私,另一方面又利用丰富的云计算资源大幅度提高了ELM的训练学习速度。在求解隐层输出矩阵广义逆时,[5]采用奇异值分解(Singular Value Decomposition,SVD)算法求得。然而,该算法的复杂性较高,且会引入大量的通信开销。本文对ELM的云计算外包部署机制进行优化,提出了新的部署方案。在该优化部署方案中,采用正交投影法求解隐层输出矩阵的广义逆,在保护用户输入与输出机密性的同时进一步加快训练学习的速度,并降低客户端与云计算服务器间的通信开销。
2 极限学习机算法与云计算外包简介
在ELM中,隐层节点参数为随机分配,输出权重可通过矩阵计算解析地确定。在激活函数无穷可微的前提下,输入层权重矩阵和隐含层偏置值无需迭代式调整,而输出层权重矩阵可解析式获得。与传统学习算法和深度学习算法相比,ELM需要较少的人工干预和更少的训练时间。
任意N个不同的样本用矩阵(X,T)来表示,X=(x1,x2,…,xN),T=(t1,t2,…,tN)。文献[2~4]已经证明,在训练SLFN时,无需迭代调整神经网络中输入层与隐藏层之间的参数。相反,如果隐层的激活函数g(·)是无穷可微的,则可以随机分配隐层节点的参数。SLFN的结构如图1所示。其中(W,b)为隐含层的参数,b表示隐含层节点上的偏置矩阵。wi为连接输入层与第i个隐含层节点之间的输入权重向量,βi为连接第i个隐含层节点与输出层之间的输出权重向量,β为输出权重矩阵。N为训练样本数量,M为隐层节点的数量。
然而,在应用程序中涉及到的数据日益扩大且结构日益复杂,使得在大规模数据上运行ELM仍然是一个极具有挑战性的任务。为了应对这一挑战,研究人员已经提出了许多ELM变种。例如,M.van Heeswijk等[7]充分利用GPU资源对ELM进行并行化和加速;Q.He等[6]提出在Map-Reduce的框架上并行ELM。
我们注意到,ELM最大的特点是隐层节点的参数是随机分配的,因此ELM特别适合外包给云计算服务商。[5]将ELM中最为耗时的计算部分(即,隐层输出矩阵的广义逆求解)外包到云计算中,并采用SVD算法求解广义逆。目前最优的SVD算法的复杂性为O(C1N2M+C2M3)。训练集规模庞大时,N≫M,ELM的训练学习速度会大幅度下降。
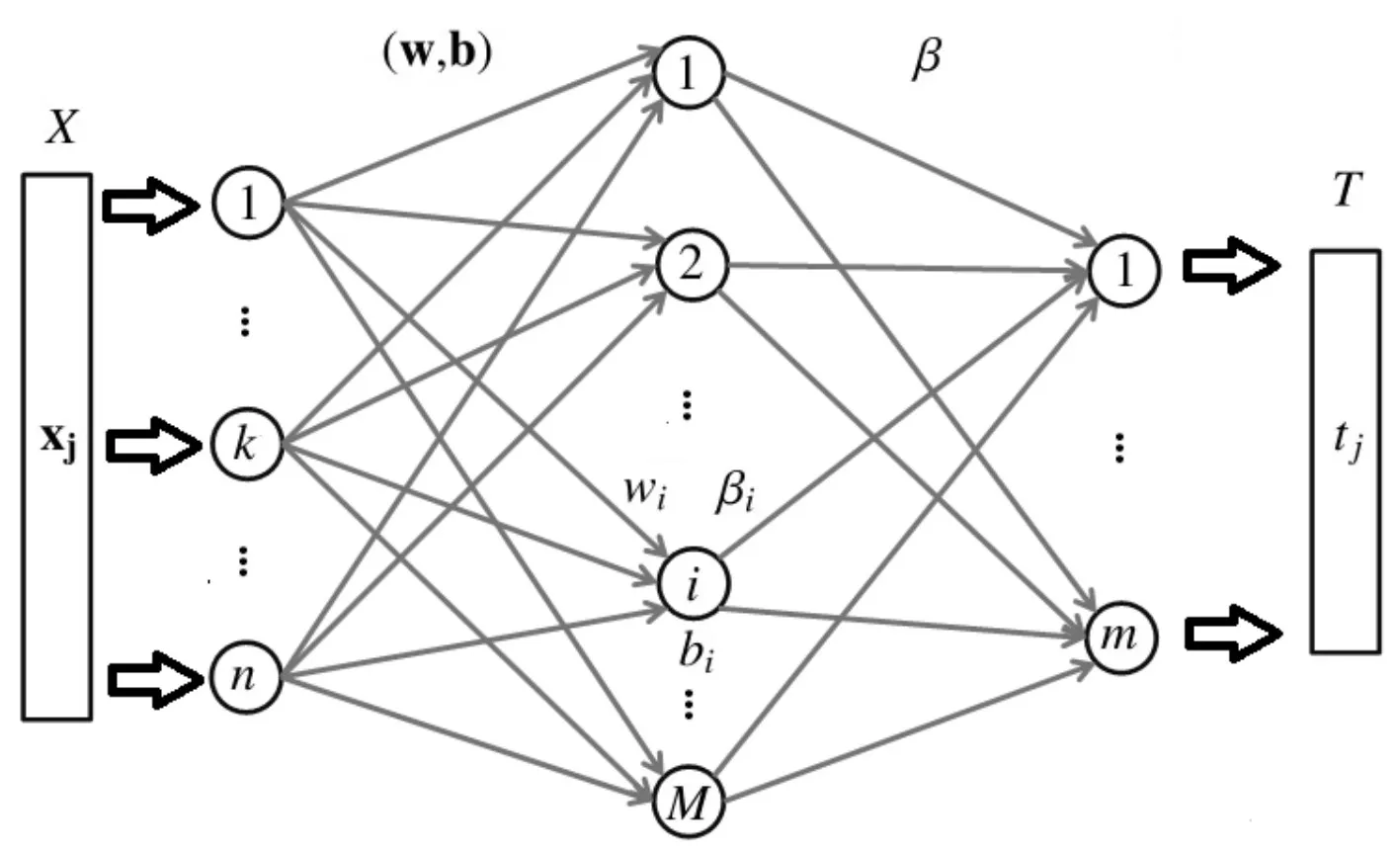
图1 极限学习机的SLFN结构
将隐层输出矩阵标记为H,H的大小为N×M :

本文采用正交投影法计算隐层输出矩阵广义逆。G.Huang在文献[2~4]中证明,当 HTH 或者HHT矩阵为可逆时,可采用正交投影法来计算广义逆;添加一个正则化项,可提高ELM学习算法的泛化性能,并使得解决方案更加健壮。
隐层输出矩阵H的广义逆H†为
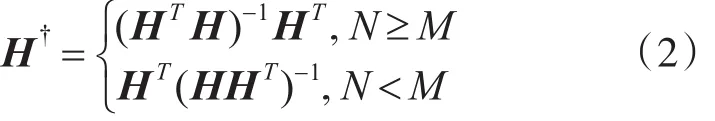
由于样本数据的大小往往要比隐层节点数量大,甚至要远远大于隐层节点数量,因此本文后续只讨论N≥M的情况。
为提高ELM算法的泛化性能与健壮性,添加了一个正则化项。即
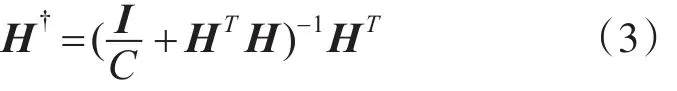
则输出权重矩阵为

我们定义一个中间矩阵Ω为
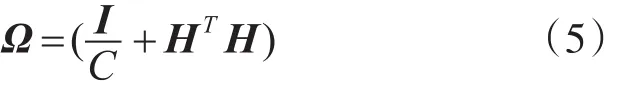
则

其中中间矩阵Ω的大小为M×M,远远小于H†的大小。考虑到多矩阵乘法的优化,更好地提高训练速度,可先计算HTT再与Ω-1相乘,即

3 云计算环境下ELM外包的优化部署机制
3.1 云计算威胁模型
为减少ELM在大规模数据上的训练时间,可将其瓶颈计算外包到计算资源丰富的云计算中。然而,用户选择外包也意味着放弃对数据和应用程序的直接控制,而数据和应用程序中可能包含敏感信息。
ELM外包机制中,数据的安全威胁主要来自云计算服务商内部。云计算服务商是“诚实但好奇”的(也被称为半可信模型)。该假设被国内外研究学者广泛接受[1,9~10]。云计算服务商会有意或无意地对数据进行分析,挖掘用户的潜在信息和隐私。在本文中,我们假定,云服务器可能会有不诚实的行为。它可能会在希望不被发现的同时欺骗用户,以节省资源或减少执行时间。我们首先假设云服务器诚实执行计算,然后讨论结果的验证,以确保云计算服务商诚信地运行用户外包出去的业务。
3.2 ELM外包的体系结构
在体系结构中,云计算外包涉及两种不同的实体:云计算用户与云计算服务器。前者有若干计算量较大的ELM问题。后者拥有丰富的计算资源,如图2所示。
由于篇幅有限,本文暂只考虑云计算中ELM的外包机制,省略了登录验证过程等并假设两者之间的通信渠道是可靠且高效的。
在本文中,我们显式地将ELM算法分解成一个公共部分和一个私有部分。私有部分除负责产生随机参数(W,b)和计算隐层输出矩阵外,还负责按式(5)计算中间矩阵Ω。用户在本地计算Ω后,将其发送到云计算服务器。云计算服务器负责公共部分,主要计算在此过程中最为耗时的Ω-1求解。云服务器计算出Ω-1后,将其发送回用户。用户在本地用户端通过式(7)获得所需要的输出权重β。
Ω的求逆运算的算法复杂度为O(M3),也远小于SVD算法的复杂度,从而提高ELM的训练学习速度。
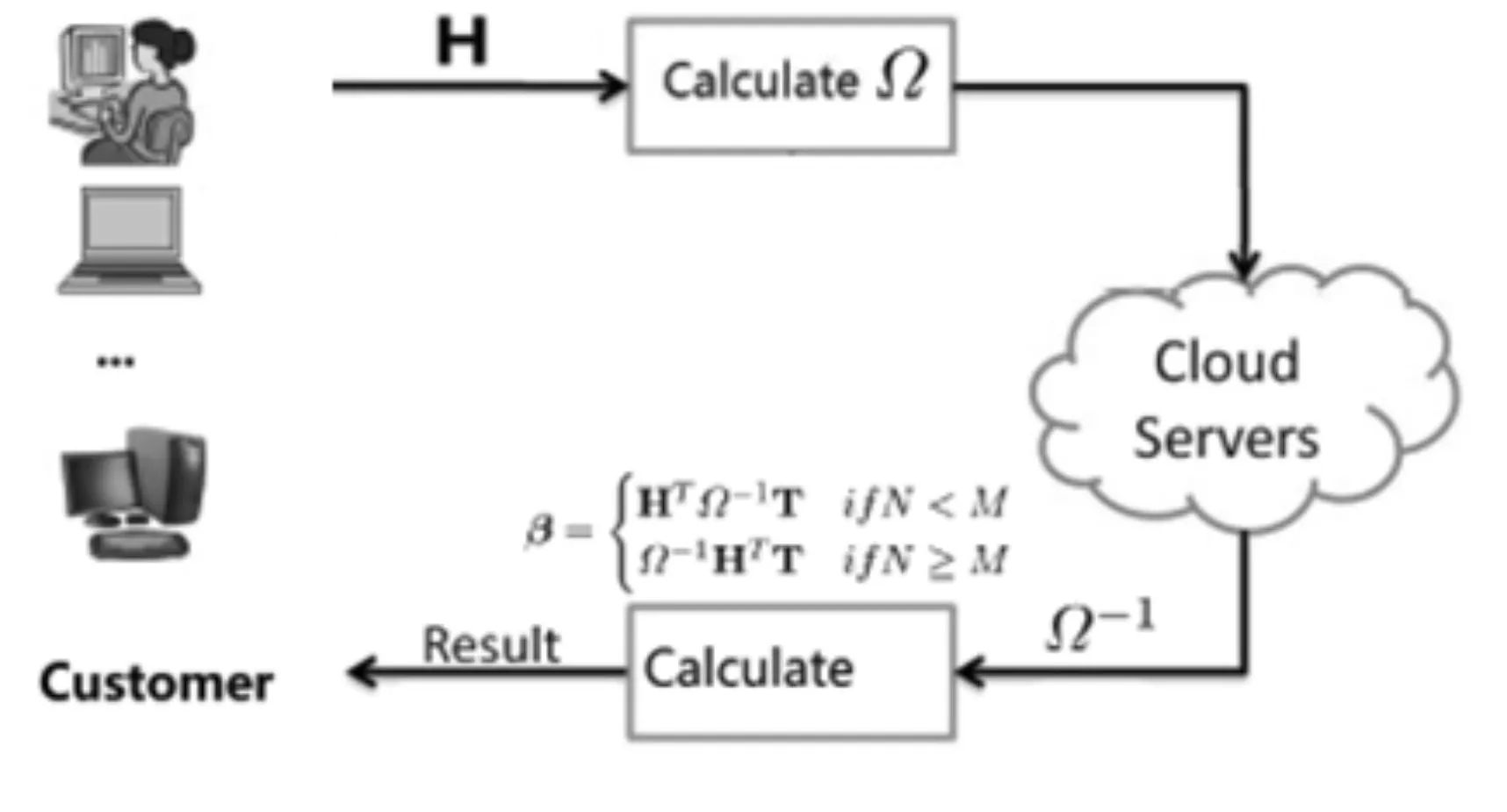
图2 云计算中ELM外包机制的体系结构
3.3 输入与输出的安全性分析
ELM是非常适合于外包的,而且能确保神经网络训练样本和所需参数的机密性。ELM算法的输入为训练集(X,T),输出为ELM算法所训练的SLFN网络参数(W,b,β)。
在ELM的私有部分,隐含层节点的参数(W,b),作为所训练的SLFN神经网络的所需参数的一部分,是随机分配的。这些参数必须由用户自身产生。注意到,无穷可微的激活函数g(·)是无穷多的。而且,正则化常数C也是未知的,因此,云计算服务提供商单从所接收到的Ω是无法推算出确切的X或者(W,b)。
需要注意的是,即使云计算服务商知道具体的激活函数 g(·)与正则化参数C并能推导出矩阵HTH、隐层输出矩阵H以及矩阵WX+b,也仍然无法推导出ELM算法的输入或者输出,因为X和(W,b)对于云计算服务商来说都是未知的。云计算服务商只负责计算H的广义逆H†,并将其发送回用户。而T也一直保留在本地,并未暴露给云计算服务商。ELM算法的另外一部分输出β是在本地按照式(7)计算的,因此云计算服务商也无法推导出β。
总之,在整个外包过程中,云计算服务商始终无法获取所训练的SLFN神经网络的参数(W,b,β)或者(X,T)。ELM算法输入和输出的安全性在本文提出的外包优化部署机制中得到了保证。
3.4 结果验证
本文到目前为止一直假设云计算服务商虽然对隐藏的信息感兴趣,但仍然诚实地执行用户所指定的操作。然而,实际上,为了节省资源或减少执行时间,云计算服务商可能并不会始终诚实地执行,而选择返回近似的计算结果。因此,外包机制必须确保用户能够验证结果的正确性和可靠性。
在本文提出的外包机制中,从云计算服务器返回的计算结果,也就是SLFN神经网路中中间矩阵Ω的逆Ω-1本身可以作为验证结果正确性和可靠性的证据。根据矩阵逆的定义,只需引入少量的计算开销就能验证结果的正确性和稳健性,而无需引入额外的通信开销。
3.5 通信开销分析
在文献[5]提出的ELM外包机制中,ELM用户和云计算服务器之间的通信开销为Td=2×,B为用户与云计算服务商之间的通信带宽。在本文提出的ELM优化部署方案中,通信开销为
由于在数据规模非常庞大时,N≫M,本文提出的ELM外包部署机制引入的通信开销将远远小于文献[5]中提出的ELM外包机制所引入的通信开销。
4 实验结果与分析
使用t0和t来分别标记原始ELM算法和在本文所提出的外包机制下ELM的训练时间。t主要为两个部分,即客户端和云计算服务器端的计算时间,分别用tl和tc来表示。定义非对称加速比为λ=t0tl。λ表示用户端计算资源的节约数量比,且仅与ELM问题的规模大小相关,而与云计算的资源丰富程度无关[1]。
使用一个普通工作站(英特尔酷睿i5-3210M CPU,2.50GHz,4GB RAM)模拟客户端。云计算服务器由一个英特尔酷睿i5-3470 CPU工作站(3.20GHz,6GB RAM)模拟。通过将ELM中最耗时的瓶颈计算从一个具有较少计算资源的工作站外包到另外一个资源较为丰富的工作站,可以评价本文提出的外包优化部署机制,而无需真实的云计算环境。我们的外包机制关注于提高训练速度,不影响原先ELM算法的训练准确率和测试准确率。
我们在CIFAR-10[11]数据集上进行实验。该数据集由50000个训练彩图(32×32)和10000个10级的测试图像组成。为了减少属性的数量,首先将彩色图像转化为灰度图像。对每个M进行了5个试验并取平均值,随机选取两个集合作为训练样本和测试样本。实验结果如表1所示。
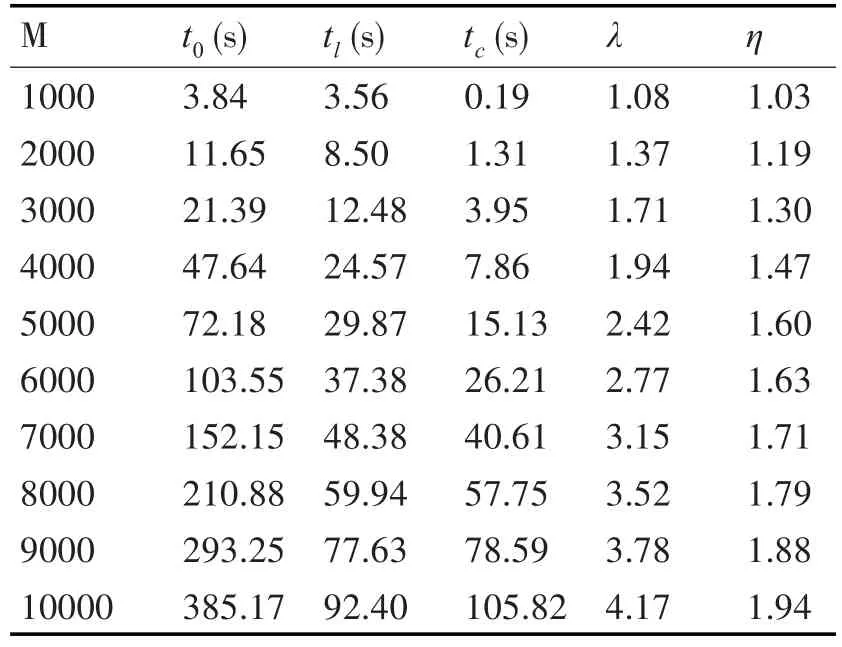
表1 在部分CIFAR-10数据集上ELM外包优化部署机制的实验结果
从实验结果可以看出,M越大,ELM问题的规模越大,内存逐渐成为瓶颈资源,云计算下ELM的外包机制所获取的非对称加速比也在显著上升。也就是说,随着问题规模的增大,本文提出的外包优化部署机制能获取更高的非对称加速比λ,即能够更好的节约本地的计算资源。整体加速比与云计算的计算资源息息相关,随着问题规模的增大,整体加速比也稳步提升,如图3所示。
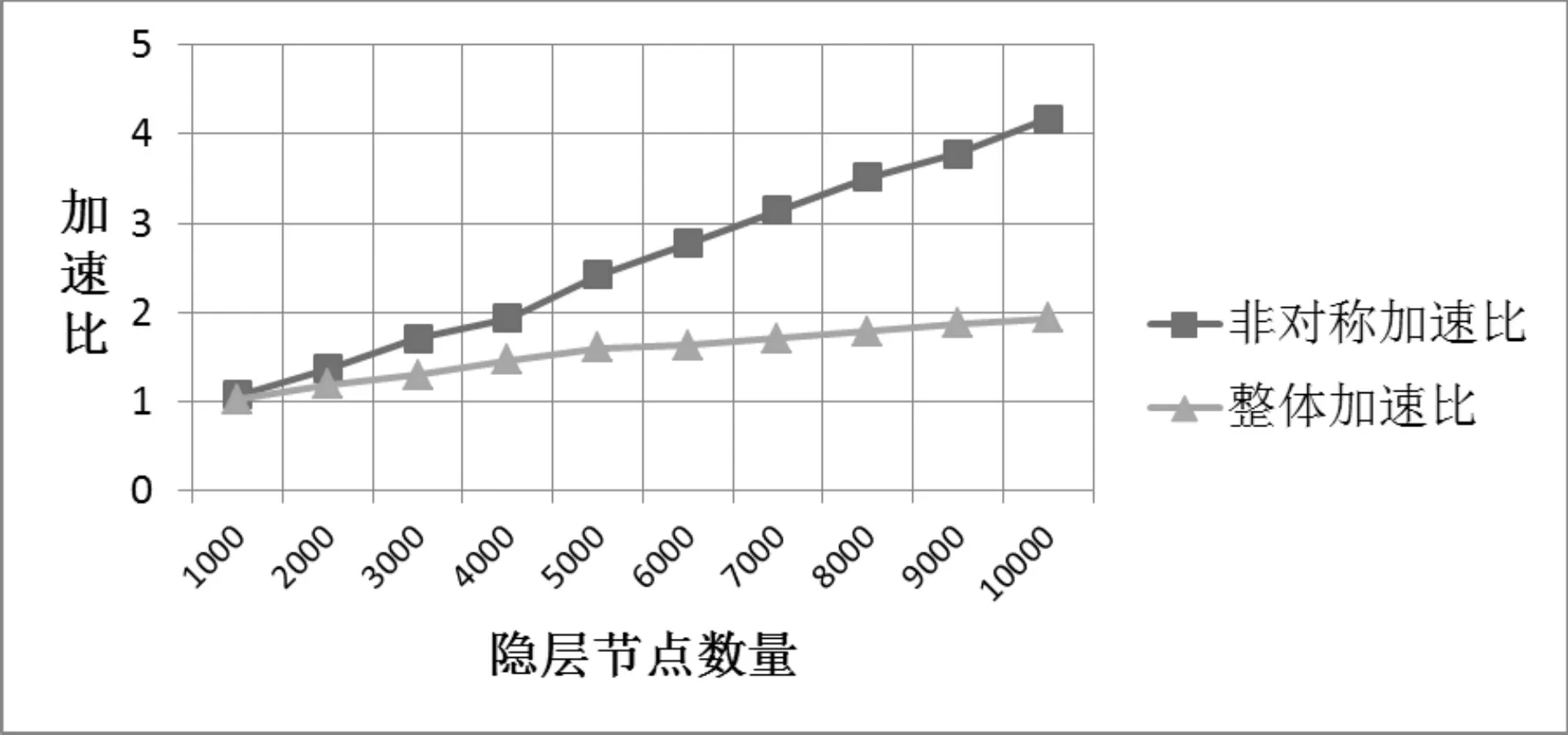
图3 非对称加速比与整体加速比对比图
从一些列的实验可以看出,训练准确率随着隐含层节点数量的增加,从83%稳步增加到95%,测试准确率在80%到84%之间变化。在本文实验中,M=2000时ELM能获取最高测试准确率,为83.45%。需要注意的是,本文提出的云计算环境下的ELM外包优化部署机制并不影响ELM学习的训练准确率和测试准确率,仅提高训练学习的速度。
为了确定M值使得ELM算法取得最高的测试准确率,用户可能需要在不同M值下测试多次试验。在这种情况下,用户可将同一训练集下的多个ELM问题同时外包给云计算服务提供商,从而更加充分地利用云计算服务器的丰富计算资源和存储资源。
5 结语
本文提出了一个在云计算环境下外包ELM的优化部署机制,在降低训练时间的同时,保证了输入与输出的安全性。本文提出的优化部署机制并未将整个隐层输出矩阵的广义逆求解外包给云计算,而仅将中间矩阵的求逆外包,降低了通信延迟开销,进一步提高了ELM训练学习的速度。中间矩阵的逆可用于在不引入额外通信开销的同时验证结果的正确性和可靠性。理论分析和实验结果表明,本文提出的ELM外包优化部署机制可有效地使用户从繁重的计算释放出来,并有效保护用户数据的安全与隐私。
