基于显著性区域的红外行为识别
2019-02-25高陈强
王 灿,高陈强,杜 莲
(重庆邮电大学 信号与信息处理重庆市重点实验室,重庆 400065)
0 引 言
行为识别是智能视频监控系统的关键技术之一,也是目前计算机视觉领域的研究热点之一。它的主要任务是从包含人的视频序列中自动识别人体行为。有效的行为识别技术除了应用于视频监控系统,还可以广泛应用于视频检索、人机交互等领域。
目前大部分行为识别研究主要针对可见光视频进行处理。由于可见光是靠反射成像,因此,目前的研究成果在光照条件不佳的情况下面临诸多挑战。相比而言,依靠物体热辐射成像的红外视频监控系统不仅能排除烟、尘、雾等恶劣天气的干扰,同时能实现昼夜连续成像工作。随着红外成像设备制造成本的不断降低,其应用会越来越广泛。因此,基于红外视频的行为识别技术具有重要的应用价值和广阔的应用前景。
尽管可见光和红外在成像原理上有很大的不同,但是行为识别方法具有很大的相通性。总体上,目前提出的大部分行为识别方法可以分为以下4类:①基于人体结构模型的方法;②基于全局特征的方法;③基于局部特征的方法;④基于卷积神经网络的方法。基于人体结构模型的方法分为线图法[1]、二维轮廓法[2]和立体模型法[3],其中,线图法用骨骼节点间的连线来表示人体姿势,是最简单常用的方法。基于人体结构模型的方法将人体简化为姿势,简明直观。缺点在于行为识别效果非常依赖于姿势估计的准确性,而姿态估计本身较为复杂。基于全局特征的方法有背景减除法、光流法(optical flow,OF)[4]、运动历史图(motion history image,MHI)[5]等。在这些方法中,OF和MHI更为常用,两者均能反映人体运动特征。基于全局特征的方法对提取运动信息较为有效,但在摄像头有明显运动的情况下需要增加额外的视频稳定模块。基于局部特征的代表性方法有光流方向直方图(histogram of oriented optical flow,HOF)[6]、基于时空的梯度描述符(3-dimentional histogram of oriented gradient,HOG-3D)[7-8]、时空兴趣点(space-time interest point,STIP)[9]等。基于局部特征的识别在可见光中较易实现,但由于红外视频中缺乏色彩、纹理、角点等信息,这将导致基于局部特征的方法在红外图像中识别效果较差。基于卷积神经网络(convolutional neural network,CNN)[10]的方法是当下主流的方法。Wang等[11]结合时空轨迹和CNN,提出了利用CNN对轨迹进行特征表达的方法,极大地提高了行为特征的表达能力。卷积神经网络近年来在结构上有里程碑式的突破,网络结构趋于更深、更复杂,识别准确率也随之提升。目前,采用双通道CNN[12-14]进行行为识别研究也引起了广泛的关注。
总体上,行为识别的精度非常依赖于视频特征的提取和表达。有效的特征提取与表达对行为识别结果往往具有决定性作用。
红外视频由于自身的成像特性,其成像目标往往比较模糊,并且缺少色彩纹理信息。同时,红外图像的背景,如车辆、马路、树木等,都可能与人体目标呈现出相似的亮度,从而易与人体目标相混淆。这些因素使得传统的方法不能较好地进行特征提取与表达,进而造成行为识别准确率不高。
为此,提出了基于显著性区域的红外行为识别方法。采用有效的显著性检测技术重点关注行为发生区域,尽可能地消除背景杂波的干扰,由此,提高视频特征提取与表达的有效性。实验结果表明,与传统的方法相比,本文的方法具有较高的识别准确率。
1 本文红外行为识别方法
本文的算法框架如图1所示。第1步,对红外视频序列提取光流运动历史图(optical flow-motion history image, OF-MHI)[15]特征,用以充分挖掘原始视频的运动信息;第2步,采用类别激活映射(class activation map,CAM)[16]方法,获得图像中兴趣目标的显著性区域图,并把该显著性区域图当作兴趣目标权重图与提取的OF-MHI特征图进行融合,从而获得消除干扰的显著性区域特征图;第3步,把获得的显著性区域特征图输入CNN网络中进一步提取有效特征,作为行为视频的最终特征表达,然后采用支持向量机(support vector machine,SVM)[17]分类器完成行为分类。
1.1 OF-MHI特征
在行为识别领域,已经广泛证明视频的运动信息对行为识别的性能具有决定作用。提取运动信息可以在一定程度上减小红外视频中缺少色彩、纹理等因素的影响。同时也可以减少非运动目标的影响。本文选取流行的OF-MHI[15]视频特征。
OF-MHI方法将光流与MHI两者相结合。在传统的MHI方法中,每个被检测出来的前景像素点都会被分配一个固定的强度值τ。身体运动快和慢的部分会被分配同样的运动强度。在光流法中,时空上的光流强度s(x,y)是由每个独立的像素点(x,y)在时间上累加得到,由此产生的强度值表示该位置的历史运动速度。它能更好地描述运动物体的局部运动。光流本身也用作前景分割提取运动物体。在传统的MHI中,运动持续时间由固定参数值τ决定。它用一个指数更新过程来调节每个像素位置运动的时空变化。OF-MHI[15]的表达式为
E(x,y,t)=s(x,y,t)+α·E(x,y,t-1)
(1)
(1)式中:s(x,y,t)表示像素(x,y)在第t帧的光流强度;α是更新速率(0<α<1);运动强度E由每个像素点的光流强度s(x,y,t)自适应地给出。
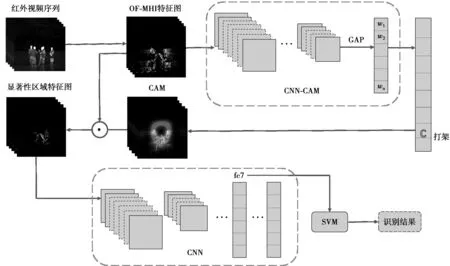
图1 本文的算法框图Fig.1 Framework of the proposed method
在OF-MHI中,前景点的像素值会被加强。如果像素点持续是前景点,则像素值会以指数权重α累加。当像素点变成背景点时,就以衰减率为α的指数衰减。较大的α值会使累计运动强度缓慢衰减,时间模板会记录下长时间的运动过程。一个较小的α值会使运动强度加速衰减,时间模板只会记录下短时间运动过程。对于场景中的缓慢移动的目标,例如走路的人,只需要一个较小的更新率(大约0.95)来描述运动。
为防止指数更新过程产生的量化误差,OF-MHI[15]的表达式定义为

(2)
(2)式中,
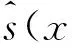

如果光流长度s(x,y,t)非常小,表明像素点(x,y)是一个背景点。εs是一个阈值参数。本文通过实验确定该阈值为0.85时,可以取得较好的效果。由于运动目标在相邻帧之间的光流变化并不明显,本文通过调节实验参数观察特征图效果,选择将原始光流长度s(x,y,t)按照初始值20放大4倍,这个参数设定下特征图的效果最明显。
1.2 显著性区域的获取
OF-MHI提取的是所有运动信息,在这些运动信息中还包含很多干扰信息,比如场景中走动的与行为无关的行人、运动的车辆、晃动的树木等。这些干扰信息往往会影响视频特征的描述能力。为此,引入显著性区域检测机制来重点关注行为发生的区域。
本文采用CAM[16]方法获取显著性区域,其流程图如图2所示。对于行为类别c,该类行为的CAM表示通过CNN得到的与该类行为密切相关的区域显著性程度激活映射图。本文中将得到的CAM转换为0~255的二维权重矩阵使用。
CAM提取显著性区域的主要过程是首先选择一个主要由卷积层(convolutional layer)构成的网络模型。本文中用的是VGG-16网络模型。然后去掉原网络模型的全连接层(fully connection layer),得到新的网络模型VGG-CAM。在最后的输出层(softmax层)之前,对卷积特征图作全局平均池化(global average pooling,GAP),输出的是最后一个卷积层的每个单元的特征映射的空间平均值。将得到的特征作为全连接层的特征来产生理想的输出。再把输出层的权重值映射回卷积特征图上。最后,通过计算最后一个卷积层的特征映射的加权和来生成需要的CAM。下面针对softmax层具体地介绍这个过程。

图2 显著性区域检测过程Fig.2 Process of saliency region detection
给定一帧图像,fk(x,y)表示最后一个卷积层上第k个单元在空间位置(x,y)的激活程度。对于第k个单元,全局平均池化之后的总激活程度为
(x,y)
(3)
所以,对于给定的行为类别c,输入到softmax层的对应类别分数为
(4)
(5)

(6)
定义Mc为行为类别c的CAM,每个空间元素则是
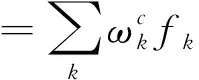
(7)

1.3 CNN-SVM行为识别
得到显著性区域特征图之后,将其缩放到227×227大小,输入VGG-16网络,取倒数第2个全连接层(图1中fc7层)的输出作为最后的视频特征表达。之后用SVM对其进行行为分类,得出每个视频的行为识别结果。
1.4 算法实现细节
在对输入的原始视频流提取OF-MHI特征时,尝试了对参数α取不同值比较特征图效果,如图3所示。当α=0.96时,特征图中运动信息最为丰富。α值越小,运动信息越不明显。

图3 不同参数值设置下的特征图对比Fig.3 Comparison of feature maps of differentparameter values
本文的算法实现中,用到了2个CNN网络,分别是原始的VGG-16和VGG-CAM。在微调(fine-tune)网络这个步骤,本文不采用传统微调网络的方法,即对网络的所有层进行微调。本文方法首先是固定其余层的参数,对VGG-CAM网络的前3层卷积层进行微调。训练适当轮数后,再对整个网络进行训练。VGG-16也用同种方法进行微调。表1中为用不同方法微调网络,最终选取网络模型的softmax层对测试数据计算出的准确率。结果表明,本文采用的网络微调方法能取得更高的识别准确率。
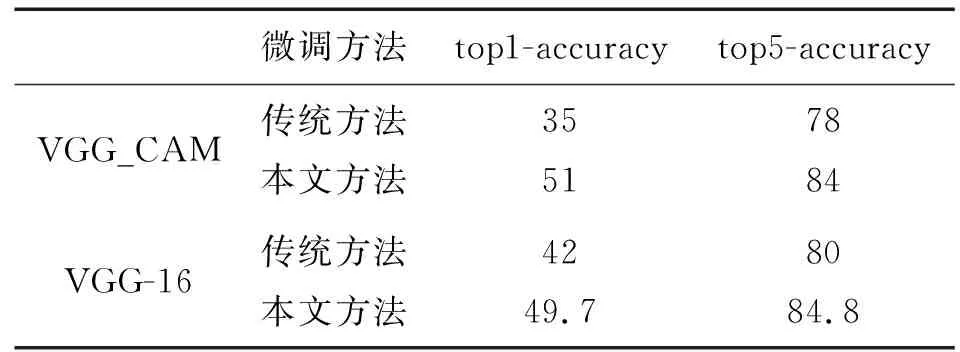
表1 网络反馈结果对比
在网络的训练过程中,为防止过拟合现象,在确保训练、测试样本均能体现背景复杂度及季节变化等前提下,我们从每个行为类别中随机选取35个视频作为训练样本,其余15个作为测试样本。VGG-CAM与VGG-16所使用的训练样本和测试样本一致。在最后的SVM分类步骤,也用同样的训练、测试样本。
2 实验结果分析
我们在红外行为识别数据集InfAR[18]上对本文提出的方法进行了测试。该红外数据集包含12类动作:wave1,wave2,handclap,walk,jog,jump,skip,fight,handshake,hug,push,punch,如图4所示。每类动作有50个视频样本,每个视频样本持续时间为3~7 s,帧率为25帧/s,分辨率为293×256 。视频的拍摄场景贴合实际情况,体现出了背景复杂度、季节差异、行为的类间差异、遮挡的有无以及视角的变化等。

图4 InfAR 红外行为数据集的12类动作Fig.4 12 action types of the InfAR dataset
2.1 网络微调策略
在基于深度学习技术的识别中,对现有网络进行微调是一个重要的步骤。对于本文的方法,在采用1.4节介绍的方法对VGG-CAM网络进行微调时,有2种选择,即采用原始红外图像进行微调和采用OF-MHI特征图像进行微调。
图5为2种数据微调网络获得的显著性区域图的对比。图5a为红外原图;图5b为基于红外图像的微调结果;图5c为基于运动特征图的微调结果。由图5c可知,基于OF-MHI特征图的微调策略可以获得更干净的背景,其显著性区域更加准确可靠。表2中为基于2种数据微调网络的网络结果与最终结果比较。进一步说明这种显著性区域检测可靠性对最终行为识别算法准确率的影响非常明显。

图5 不同数据微调网络获得的显著性区域图Fig.5 Saliency regions based on different networktraining data

%
2.2 对比实验
为了验证本文方法的有效性,选取常用的几种行为识别方法与本文算法的结果进行比较,包括基于运动历史图的梯度特征(motion history image-histogram of oriented gradient,MHI-HOG)[19],密集轨迹特征(dense trajectory,DT)[20],HOF[6],HOG-3D[7]与STIP[9]等特征提取方法,获取特征之后,采用目前效果较好的Fisher Vector编码方法[21]进行特征编码,最后用SVM分类器进行分类识别,得出识别准确率。此外,还有基于双通道CNN的Two Stream方法[22]。以上方法均是对整张图像提取特征。
此外,为了验证显著性区域对行为识别效果的重要性,在本文方法基础上移除显著性区域提取模块,再构造了一种对比方法。该算法框图如图6所示,首先对红外视频流直接提取OF-MHI特征,微调VGG-16网络后,再把特征图输入VGG-16网络中进一步提取特征,最后输入SVM分类器进行识别。本文采用行为识别领域通用的识别准确率(又称查准率)作为算法的评价标准,即分类正确的样本数占样本总数的比例。

图6 本文方法移除显著性区域检测模块后的算法框图Fig.6 Proposed method without saliency region detection module
为了保证实验对比的公平性,所有对比方法的训练集与测试集的选取均与本文方法一致。各种方法的实验结果如表3所示。从表3中可以看出,相对于所有对比方法,本文提出的方法性能得到了显著性的提高。在所有的对比方法中,密集轨迹特征方法的识别效果最好,为66.7%。这是因为该方法具有较为强大的特征表达能力。尽管如此,这些传统方法的特征表达仍然面临背景杂波干扰的影响。本文的方法加入了显著性区域检测模块,重点关注行为发生的区域,从而减少背景杂波的干扰。因此,本文方法可以达到最高的(74.4%)的识别准确率。而移除显著性检测模块后,算法的性能明显降低(见表3倒数第2行)。这进一步验证了显著性区域检测模块在视频特征提取中的重要性。

表3 不同方法的实验结果对比Tab.3 Comparison of experimental results of different methods %
表4中为本文方法在每类行为分类上的准确率,并与同样采用深度学习技术的Two Stream[21]方法进行了对比。由表4可知,由于walk,wave1和wave2动作的简单重复性,2种方法在其上均取得较高准确率。而punch和push动作复杂且互相难以区分,2类方法在其上取得的准确率较低。本文方法在绝大部分行为类别上的识别准确率均比Two Stream方法更高或者持平。

表4 每类行为识别准确率Tab.4 Recognition accuracy of each action type %
我们对算法的运行时间做了评估。实验环境为Linux操作系统的PC机,其中,CPU为Intel I7,GPU为Nvidia Geforce GTX TITAN X,内存64 GByte。测试样本共有180个视频,共有29 858帧,在Matlab平台下总运行时长为3.299 h,处理速度为2.519帧/s。
3 结束语
提出了一种基于显著性区域的红外行为识别方法。该方法将运动特征OF-MHI与显著性区域结合,最大可能地消除背景杂波与行人的干扰。同时,采用深度学习技术提取有效的特征表达。实验结果表明,与传统的行为识别方法相比,提出方法具有较高的准确率。在未来的研究中,将对算法进行进一步优化,提高算法的运算速度。
