基于ETL工具的系泊监测数据回传方式
2019-02-23张鹏
张 鹏
(中海油能源发展股份有限公司采油服务分公司 天津 300000)
引言
单点系泊是中国海上油田FPSO作业期间普遍采用的一种系泊方式,通过单点系泊装置实现FPSO定位,井液输送,电力、控制、通讯信号输送。同时,FPSO在单点系泊装置的牵引下,做风向标运动,使其在各种风浪流作用下的应力达到最小。[1]因此,单点系泊装置成为保障FPSO连续安全作业的关键设备。
从近十几年国内应用效果来看,围绕单点系泊装置引发的生产安全事故时有发生,单点液压紧固件损坏导致单点舱透水的事故,系泊锚链断裂导致生产立管损坏的事故,甚至发生过单点塔架倒塌导致FPSO解脱漂移的严重事故,造成重大经济损失和不良社会影响。海上油田作业者愈发认识到对作业期间的单点系泊装置进行监测、预警是十分必要的,陆续开展对在役FPSO加装系泊数据监测系统的工作,同时要求新建FPSO建造期间同期安装。[1,2]
最近几年,中国海油旗下FPSO运营公司对标国际,围绕系泊技术开展了一系列基础工作,从锚链更换到滑环维修再到参与单点设计及滑环研制,逐步形成了系泊技术方面的经验积累。从2017年,以公司系泊技术方面的工程技术人员为基础开始筹备组建国内首家系泊技术实验室,长期开展FPSO系泊数据监测、分析、诊断、评估工作成为实验室的核心业务之一。因此,能够连续抓取分布于中国各个海域内的FPSO系泊监测数据,并实现数据转换整合的数据回传方式,是实验室前期建设的重要课题。
1 系泊数据监测系统基本情况调查
目前,中国海上油田现役FPSO共计13艘,分布于渤海、南海,其中6艘已安装功能较为完善的系泊数据监测系统,5艘可以长期提供稳定、全面、可靠的数据源(表1)。

表1 部分在役FPSO系泊数据检测系统安装情况
1.1 系统功能及构架
标准的系统监测功能包括:系泊力、运动姿态、环境条件三大类。[2]通用数据采集范围涉及17项参数(表2),有些FPSO会根据单点形式和海域环境特点设置个性化参数。数据采集频率5HZ、1HZ。系统主要设备包括传感器、数据采集器、上位机。上位机安装监测软件和数据库,实现监测预警、中间过程计算、数据存储。

表2 测量参数类型
1.2 对外通讯方式及质量
截止2017年底,中国海域内海上油田已实现微波网络全面覆盖,海陆联接带宽10-30MBps,平均延迟<3mS。上述6艘FPSO的系泊数据监测系统满足接入海油专网的条件,可实现海陆数据联通。南海部分系泊数据监测系统还考虑到了躲避台风期间,人员撤离后,FPSO断网断电的特殊情况,这时监测系统可以依靠专属UPS供电继续工作3-7天,期间可以通过海事卫星与外部进行通讯连接。
2 ETL技术原理
ETL(Extract-Transform-Load)是用来描述将数据从来源端经过抽取、交互转换、加载至目的端的过程。[3]这一概念来自于数据仓库,是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。伴随着数据仓库,ETL技术已经发展了近30年,从纷繁复杂逐步走向标准化,其技术日趋成熟。
2.1 ETL的实现方式
ETL的实现有多种方法,常用的有两种。[4]一种是通过SQL编程方式实现。其优点是灵活,可实现复杂的功能应用,执行过程高效,但是编码复杂,技术要求高,后期维护过程有一定的难度,且不容易扩展。另一种是借助ETL工具实现。ETL工具是数据库厂商或第三方开发的专业工具软件,借助工具可以快速建立起ETL过程,屏蔽了复杂的编码任务,提高了开发效率,降低了技术难度,但是缺少一定的灵活性,不过这也是当前大数据时代普遍采用的一种方式。
2.2 ETL工具架构
ETL工具有两种技术架构,ETL架构和ELT架构,区别如下:[5]
2.2.1 ETL架构
在ETL架构中,数据的流向是从源数据流到ETL工具,ETL工具是一个单独的数据处理引擎,一般会在单独的硬件服务器上,实现所有数据转化的工作,然后将数据加载到目标数据仓库中,如果要增加整个ETL过程的效率,则只能增强ETL工具服务器的配置,优化系统处理流程。ETL架构的特点包括:
(1)ETL可以分担数据库系统的负载。
(2)ETL相对于ELT架构可以实现更为复杂的数据转化逻辑。
(3)ETL采用单独的硬件服务器。
(4)ETL与底层的数据库数据存储无关。
2.2.2 ELT架构
在ELT架构中,ELT只负责提供图形化的界面来设计业务规则,数据的整个加工过程都在目标和源的数据库之间流动,ELT协调相关的数据库系统来执行相关的应用,数据加工过程既可以在源数据库端执行,也可以在目标数据仓库端执行。当ELT过程需要提高效率,则可以通过对相关数据库进行调优,或者改变执行加工的服务器就可以达到。ELT架构的特点包括:
(1)ELT主要通过数据库引擎来实现系统的可扩展性。
(2)ELT可以保持所有的数据始终在数据库当中,避免数据的加载和导出,从而保证效率,提高系统的可监控性。
(3)ELT可以根据数据的分布情况进行并行处理优化,并可以利用数据库的固有功能优化磁盘I/O。
(4)ELT的可扩展性取决于数据库引擎和其硬件服务器的可扩展性。
(5)通过对相关数据库进行性能调优。
3 基于ETL工具的数据回传方式设计
3.1 ETL工具的选择与对比
近年来大数据概念席卷全球,围绕大数据的相关应用如雨后春笋。能够实现快速部署的数据集成业务推动了ETL工具快速发展。常用的ETL工具主要包括国外商业品牌,开源工具、国产商业品牌这三类(表3)。国外商业品牌工具功能强大,尤其是大型数据库厂商开发的自有工具能够与其数据库完美配合,但产品费用和后期维护成本高昂,适合大型数据工程。开源工具可以免费获取,代码公开透明,能够实现快速部署,实施过程几乎没有成本,但后期维护没有技术保障,对于维护人员的技术水平有较高的要求,适合个人应用或者搞数据实验。国产商业品牌工具最近几年也有了相当不错的进步,内核多基于国外开源工具,产品费用相对低廉,后期维护能够获得技术支持,适合中小型数据工程。

表3 部分常用ETL工具
3.2 ETL工具基本配置方法
使用ETL工具可以快速实现数据抓取、整合的工作(图A),避免了开发专业软件的复杂过程。ETL工具对于使用者像一个遮蔽的黑盒,无需关心其内部代码执行过程,使用者只需把精力投入到参数配置过程。
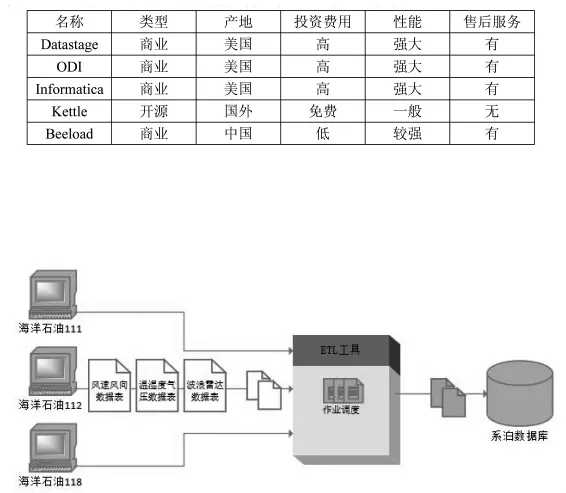
图A 系泊数据回传系统架构
ETL工具通常都具备图形化操作界面,使用过程像搭建流程图一样快捷、简便、直观。以Beeload软件为例,通过以下步骤表4可以实现数据回传的基本需求。

表4 ETL工具配置步骤
3.3 优化设计分析
通常,经过以上配置过程就可以实现数据回传的基本需求,但要保持高效、稳定的运行还需要从以下几个方面进行深入细致的调优设计。
3.3.1 ETL工具的部署
ETL工具可以直接部署在目标数据库服务器上,这种布部署能够减少硬件投入,提高网络I/O效率。也可以独立部署在一台专用服务器上,这种布部署能够加强系统安全性和独立性,避免与其他系统争夺CPU和内存资源。当清洗转换过程不需要太多的计算,而对网络响应速率有要求的时候,可以选择直接部署在目标数据库服务器上。
3.3.2 数据源的选择
数据源的质量是实现有效回传的前提,应该对数据进行充分分析。例如,ETL工具能够提供多种数据源接口,包括结构化和非结构化的数据,但还是要尽量选择结构化的数据资源以提高抓取效率。如果有可能,可以对源数据做进一步的改造。
3.3.3 目标数据库的设计
目标数据库结构应根据源数据结构统一成为合理的、关联的、分析型的新结构,其结构应该能最大化地承载关键业务数据,便于查询和发布。设计过程要重视数据标准化定义,实现统一的编码、统一的分类和组织。
3.3.4 数据清洗转换
数据清洗转换是建立源数据到目标数据字段映射的过程。由于数据源的多样性,需要建立规则统一数据类型、祛除脏数据,以免给后期数据装载带来麻烦。通过ETL工具自带的函数集可以实现复杂的转换规则,也可以实现中间过程量到最终结果的计算。如果转换清洗算法复杂,计算量大,ETL工具应该独立部署在一个服务器上。
3.3.5 数据同步
数据同步是ETL过程中重要的环节,规则设定的优劣直接影响传输效率。数据同步要求源数据的变化能够映射到目标数据库中。数据同步模式包括:全量同步模式和增量同步模式。[6]全量同步模式将源数据无差别全部复制到目标数据库中,随着数据记录的增多同步过程会消耗大量时间,造成网络堵塞,通常只用于初始数据同步或者源数据记录少且增长不大的同步过程。增量同步模式将源数据与目标数据进行比对,仅对差异部分进行同步更新,适用于源数据记录不断增加的同步过程。增量模式又包括:差异增量模式、时间戳模式、触发器模式。差异增量模式通过逻辑主键逐行比较源数据和目标数据,源数据在目标数据表中不存在则插入,存在且信息不同则更新目标数据,目标数据在源数据表中不存在则删除目标数据,能够实现无差别同步。同步过程期间需要大范围比较,效率比较低,不适合大数据量的同步过程。时间戳模式要求源数据表中存在至少1个字段(时间戳),其值随着时间变化不断累计,同步过程中,程序通过时间戳对数据进行过滤,结束后程序记录时间戳信息。这种模式适合源数据只增不减,不断累积的同步过程。触发器模式要求在源数据库中创建触发器和临时表,触发器捕获新增、修改、删除的数据到临时表中,程序从临时表再同步到目标数据表,同步过程效率高,由于源数据服务器分担了一部分工作使得ETL服务器负荷大大降低,但是这种模式对源数据库有较高的要求。数据同步过程还需要作业调度配合,以实现自动定时抓取数据。作业调度设计要求充分考虑同步频率、数据采集密度与传输效率之间的矛盾,同步频率高,采集密度大容易造成网络堵塞。对实时性要求不高,可以降低同步频率,甚至可以选择T+1同步(隔天同步)。对实时性要求高,可以通过数据筛选降低采集密度。
结语
使用ETL工具抓取数据已经成为业内比较成熟的解决方案。通过ETL工具实现系泊监测数据回传优势明显:①实施过程简易高效,能够快速达到数据整合的目的;②相比较专业开发,节省人力物力;③后期维护过程稳定可靠,不需要投入太多精力;④具备很强的扩展能力,随时可以加入新的数据源。目前,国产部分ETL工具软件进步很快,在业界积累了一定的成功经验,足以应对中小型数据工程的基本需求,是一个性价比不错的选择。
