图谱方法实现DLBCL信息基因的提取与分类①
2019-02-15左常玲夏百花
左常玲, 夏百花
(安徽三联学院电子电气工程学院,安徽 合肥 230601)
0 引 言
在基因表达谱数据中,与肿瘤相关基因只占极少数,大量基因在不同肿瘤、肿瘤亚型以及正常状态下表达几乎没有变化。或受外界环境污染、技术限制、人为读数错误等影响而出现异常值,通常把这些基因记为噪声。如果分析整个基因表达谱,则会使信息基因(能识别肿瘤类型的基因)被噪声所淹没,使之无法有效从微阵列数据中获取分类信息。
为更有效获取信息基因,降低后续处理复杂度以及除去噪声的影响,研究分为两步:异常值基因的初步处理和基于图谱性质的信息基因的选取。
1 异常值基因的初步处理
弥漫大B细胞淋巴瘤(DLBCL)的基因表达谱数据可描述为一个MatrixG=(gi,j)M×N,M、N分别为样本规模和基因变量规模,首先进行归一化处理,如式(1)所示:
(1)
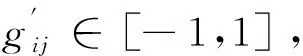
(2)

(3)
若(3)式成立,则消去该基因,从上式可以看出T是衡量一类中基因表达值偏离均值水平程度,T越大,表明该基因的表达情况越偏离均值水平,则视为异常值。实验中T取值1.1。
2 基于图谱性质的信息基因选取
(1)构建关系矩阵
对任意基因gj=[g1,jg2,j…gM,j]T,M表示样本规模,将基因gj在样本中的表达值看作为一个点,其点间边的权值wi,k为高斯权函数,如(4)式所示:
(4)
接着构建Laplace 矩阵:
(5)
则得到一个M×M关系矩阵R,该矩阵展现了基因在各样本中表达值之间的亲近关系。
(2)对关系矩阵进行奇异值分解(SVD)
(3)构建理想分类模板
分类问题(只关注二分类问题,多分类可以类推),其实可以看成是与分类模板之间的匹配问题,提出的分类模板描述为:假设有若干样本分属A与B两类,每个样本有N个特征。A类有M1个样本;B类有M2个样本。针对某一特征可以设计出这样一个分类模板:
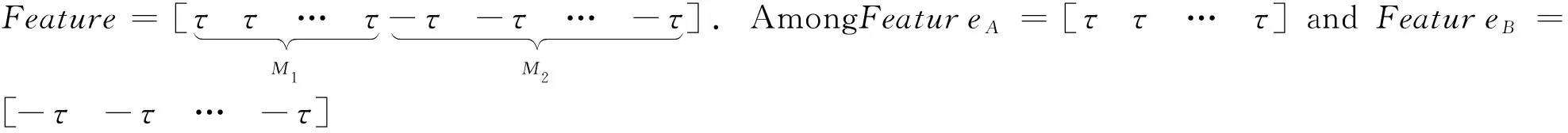
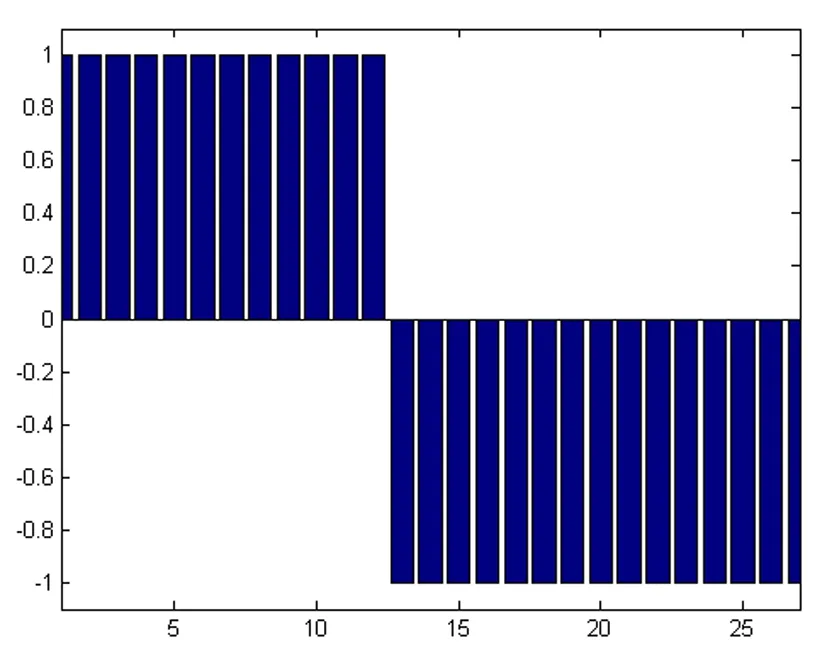
图1 理想分类模板示意图
可以根据该特征来判定一未知样本属于A类,或者B类。
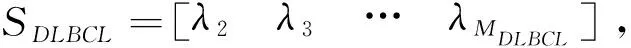
(6)
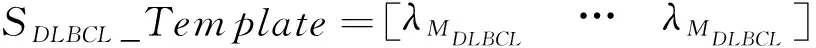
(4)计算模板与谱特征夹角系数

cos(SDLBCL,SDLBCL_Template)=
(7)
cos(SFL,SFL_Template)=
(8)
综合DLBCL类与FL类谱特征与模板夹角系数:
cos(S,S_Template)=κ×
cos(SDLBCL,SDLBCL_Template)+(1-κ)×
cos(SFL,SFL_Template)
(9)
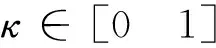
(5)建立评价函数,选取信息基因子集
好的信息基因,在不同类别中,d越大越好;同类中,cos(S,S_Template)越大越好,故构建以下评价函数,实现对信息基因的选取:
F_cost=η·d·cos(S,S_Template)
(10)
其中,η是放大因子,实验中η=100,便于评价函数的比较。对每个基因都进行上述(1)~(5)步的计算,选取F_cost较大的作为信息基因子集,实现对基因表达谱数据的降维与噪声的降噪处理。
3 实验流程
利用当前流行的分类器SVM进行分类实验,其核函数采用高斯核函数,Sigma为高斯噪声的标准差,实验步骤如下:
Step 1:对DLBCL数据进行归一化处理;
Step 2:对DLBCL数据的异常值初步处理;
Step 3:按照基于图谱性质的信息基因选取的(1)~(5)步骤实现信息基因的提取;
Step 4:运用SVM实现DLBCL数据的分类,并作出分析。
4 实验结果及分析
4.1 模拟实验
图谱方法作为一种新手段应用于DLBCL的分类,实验了模拟数据以验证其可行性。模拟数据是由四组点集构成,每组分两类即A类与B类,数据是随机产生,具体如表1所示:

表1 四组模拟数据
AB0、AB2、AB10和AB40四组数据的平面显示,其A类与B类的可分性越来明显,如图2(a)所示;图2(b)给出了对应点集的特征值分布。

图2(a) AB0、AB2、AB10和AB40点集分布图。x、y表示点的坐标;图2 (b) 为(a)对应点集构造Laplace图后经SVD分解得到的特征值分布,横坐标是特征值序号,
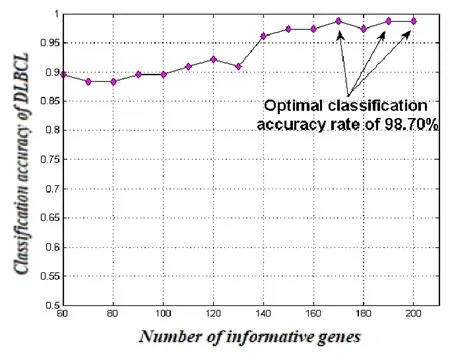
图3 选取不同信息基因数时,SVM(Sigma=45)
对DLBCL数据的分类结果
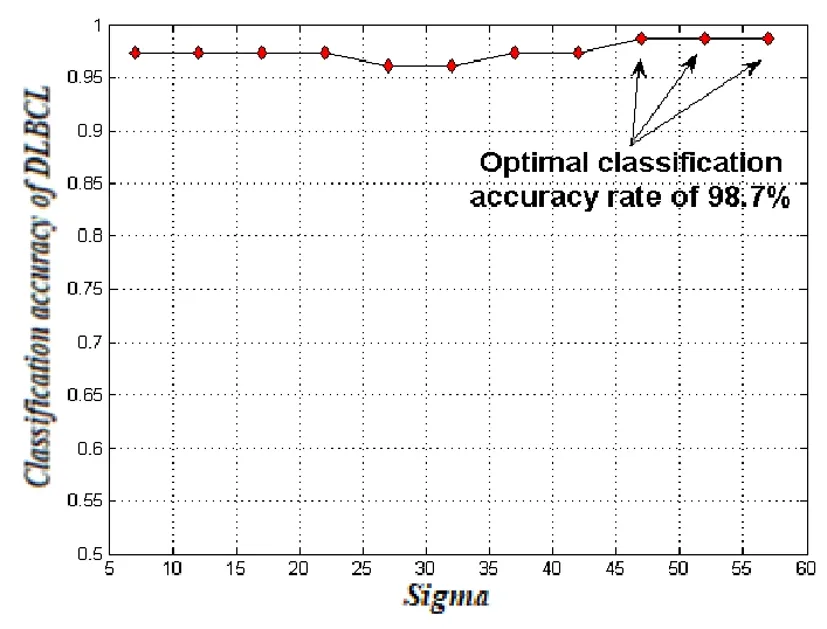
图4 选取170个信息基因,SVM高斯核中Sigma的不同
取值对分类正确率的影响
从模拟数据可以看出,类内点越近,类间点越远,则特征值分布展现出的两条带状——A类与B类越明显,从而验证了图的谱特征分布可以很好的识别不同样本类型。
4.2 DLBCL实验结果
如图3所示,运用提出的方法选取信息基因,在信息基因数L=60时,准确率已达到近90%,随着信息基因数的增加,分类准确率越来越高,当L=170时,77个样本仅有1个被错分,随后准确率趋于稳定。而图4展示了变量Sigma变化对分类结果影响不大,分类准确率都大于95%。
从图3和图4中可知,信息基因选取170时,分类正确率达到最好的效果,表明了这170个基因包含了最多分类信息,故对这些基因分析其变化幅度如图5所示:

图5 170个信息基因的平均变化幅度
(每个基因都归一化到-1到1之间),即MCAGE

图6 不同变化幅度范围内,信息基因数统计
根据图5对信息基因的平均变化幅度进行统计,MCAGE值可根据|μj,DLBCL-μj,FL|/2计算。如图6所示,在DLBCL和FL类中,信息基因的MCAGE主要在0到0.15之间,占信息基因总数的81.77%,大于0.15的只有极少数,并且MCAGE最大不超过0.35。
5 结 论
图谱理论应用于生物信息学是一个新的研究方向。基于图谱方法分析基因表达谱数据,对基因构图,获取图的谱特征分布,并将其作为刻画该基因与肿瘤类型相关性的新途径。模拟实验和真实实验结果可以验证此研究方法是可行的和有效的。DLBCL数据实验中,无论信息基因选取的多少,还是分类器中参数的调整,分类准确率都在85%以上,其最优分类准确率是98.7%,结果是令人满意的。
对选取的信息基因的分析中,MCAGE反映了每个信息基因在DLBCL类和FL类中表达值的平均变化幅度。由图6显示,与DLBCL类别判定有关的基因有80%变化幅度范围在0.15以下,变化幅度越大,信息基因数越少。经上分析,在一定程度上图5和6给出了与DLBCL类型识别有关的信息基因的表达规律,以辅助肿瘤专家识别和治疗DLBCL。
