基于深度学习的场景识别系统
2019-02-14张正阳
张正阳
(西安市铁一中学,陕西西安,710000)
0 前言
在上世纪20年代,机器人”robot”首次被提出来,几十年来,人工智能也在飞速发展[1]。在这几年,计算机领域中的人工智能越来越引起了人们的注意,而其中最具有热度的便是机器人,它能够代替人类完成许多繁琐的工作。由于当今劳动力成本快速上升,机器人的这一特点更加显示出它的重要性。例如在一些空巢家庭,老年人行动不便,需要在帮助下才能及时的完成一些繁琐的家务活动;在一些医院中,护工的费用越来越高,而他们完成的也只是一些技术含量不高而比较繁琐的低成本工作。服务型机器人便由此而生。属于服务型机器人领域的家庭服务机器人,主要的功能即帮助人们完成一些简单的服务类工作。而基于深度学习的场景识别系统则相当于机器人的眼睛。
机器人领域中,如何使机器人识别所处环境是一个重要问题,经过实践表明,传统的识别系统有着内存大,在环境变化或者光照变化等情况下无法识别的缺点[2],而基于深度学习的识别系统可以有效的消除这些缺点。本文在学习和借鉴现有的技术基础之上,提出了一套基于深度学习的视觉识别方法,在回环检测的部分使用基于深度学习的场景识别系统,抛弃传统的词袋法而建立的机器人场景识别系统。在设计原理的基础上详细分析了具体的实现途径和技术路线。并且对结果进行了功能试验,肯定了此原理的可行性与正确性。
1 场景识别研究现状
当机器人在某个陌生环境中的陌生场景中完成任务时,如何使机器人识别其所在的工作环境场景是机器人以及计算机视觉领域的重要研究课题[3]。识别自身的工作环境对于机器人进行下一步工作任务的执行有着重要意义。机器人的场景识别问题不同于简单的图像分类,其不同工作场景图像的内部元素种类繁多,即使是同类场景,在不同时间,不同外界影响因素下其内部元素往往也存在着较大差别。因此场景识别问题会十分复杂,而场景识别的关键则在于如何找出一种能完全表示同一类场景中的结构信息和语义信息的特征。
2 回环检测算法
基于深度学习的SLAM场景识别系统主要分为前端对局部描述符的构建和后端对于所构建地图的优化与回环检测,对于SLAM前端工作的改进包括使用基于深度学习的局部描述符相机位姿直接进行计算和对目标加速特征点的匹配总而言之,SLAM前端主要提供了特征点的提取、负责相机位姿的计算和局部地图的构建。但仅仅通过这些并不能精准的实现机器人的自动建图和定位,这些数据中含有大量的“噪声”,导致计算的结果会有一定的误差,并且这些误差会不可避免的积累到下一个环节,导致最终结果随着时间的积累误差越来越大,地图和行走轨迹不吻合,并且发生极大的变化,因此无法保证其与现实情况一致。于此,SLAM后端则是对数据的优化。SLAM后端分为两个部分:后端优化和回环检测。本章主要介绍回环检测在SLAM系统中的作用管理。
回环检测则为解决减小机器人在SLAM前端工作时所积累的误差问题提供了很好的思路方法[4]。不妨以我们人类在一个陌生环境中如何建立周围的环境地图为例,人的位置不断发生改变,从而在脑海中积累了大量图像,形成一个由这些图像累计而成的一个地图,但长时间过后,这些图像中的部分微小误差经过累计导致结果与实际情况产生较大的差异,对于这个情况人类也无法分辨自身在此刻朝向哪个方向,与最初起点的相对位置如何。假如在此刻人恰好回到了之前某个时刻经过的位置(设这个人对环境比较敏感),他便能够意识到这个事实,并在此基础上修正此前对环境判断造成的误差。此时便如同于检测到了一个回环。我们知道人是通过将眼前的图像与脑海中残存的图像进行对比,从而意识到自己所处的这个回环。同理,在SLAM中也是通过对比当前图像与之前关键图像的相似度,当这个相似度到达某一设定值后就可以判断出此时机器人检测到了回环。
为此,回环检测的重点在于场景识别,正确的回环检测为机器人的定位与建图提供了保障,尤其是在机器人长时间的工作之后,累积了大量的误差,此时系统就可以通过回环检测不断修正自己的轨迹和地图[5]。又因为回环检测将历史与实时的数据进行对比和联系,所以当系统丢失的时候也可以通过回环检测来进行重合。
如图1,左图中由于机器人SLAM前端提取的特征点中误差的长时间积累导致了机器人对定位与建图的估计不再准确,因此便有了对误差进行回环检测和全局校正的需求,右图即是通过回环检测校正后的图像,将产生误差的地图进行修正使之与行进轨迹重合后的结果。
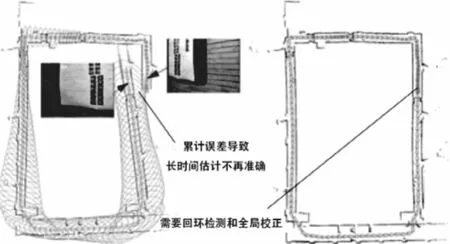
图1 回环检测修正地图,左图为修正前,右图为修正后
■2.1 回环检测与场景识别
回环检测的本质就是机器人对于自己所在位置的场景识别,对于人类来说场景识别的过程很自然,然而这个问题对于机器人来说却十分有挑战性—让机器判断自己所在位置是否是自己先前经历过的场景。为了解决这个问题,场景识别需要具备以下两个能力:
(1)含有与输入数据进行对比的数据集,此数据集可以是关键帧或者一些特征点的集合,并且该数据集需要不断更新以保持其实时性。
(2)拥有能够计算输入数据与数据集间相似度的评分机制。
拥有这两个功能,便能进一步改善传统场景识别BOW模型的无法识别光照等环境变化的缺点。
■2.2 数据集建立
神经网络需要经过一个训练,例如我们在室内随机挑选了相似图片,提取其中的相似点与不相似点。利用AlexNet以及将relu作为CNN网络的激活函数,用CUDA来加速深度神经网络的训练,再通过GPU强大的并行计算能力,接下来经过卷积神经网络权值共享,采用Max pooling将图像缩小,(Max polling也可以将图像降维),随后经过多次卷积和Max pooling,通过全连接提取图像特征。在训练时,采用三个相同的Alexnet网络提取图像特征,比较特征之间的距离,通过triplet loss缩小相似特征之间的距离,然后使其小于不相似特征间的距离。
如图2,x指一个图像特征,x+的图像特征与该图像特征比较相似,特征点之间的距离较小,相反x-的图像特征与该图像特征之间距离较大,输入的图像各自经过共享权值的相同网络,利用公式(1)计算出特征之间的距离,经过tripletloss缩小x+与x之间的距离使之小于x-与x之间的距离,以此达到识别出相似场景的效果。
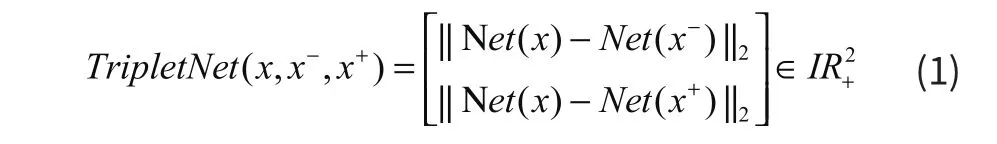

图2 三重网络结构
■2.3 损失函数
所谓场景识别系统,即将高维空间的图像映射成一个维度较低的空间中的描述符,映射过程中我们需要低维度的描述符可以保持图像之间的相似关系。因此我们采用triplet形式的损失函数来对网络进行训练。我们为提取到的样本特征选取邻近的同类样本特征和邻近的异类样本特征,以此来构建一个三元组,对于N个训练样本,可以随机产生大量的三元组,本文涉及到的基于三元组约束的距离度量学习模型(point to point Relative Distance Constrained Metric Learning,RDCML)要求同类样本特征的距离和异类样本特征的距离被一个大的间隔分开。基于上述的描述,我们的损失函数为公式(2),其中α为正负样本之间的间隔,即正样本之间的距离至少要小于负样本的距离α以上。在训练过程中α由人为指定,α越小网络越容易收敛,然而效果会比较差,α越大网络越难收敛会导致训练时间变长甚至不收敛,但是效果会比较好,因此我们需要在训练过程中对训练时间和精度进行权衡。
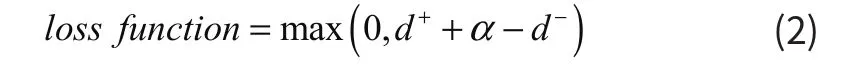
如图3表示了点与点之间三元组约束的意义,对于一个三元组,黄色与蓝色两个样本之间的异类距离d和黄色与黄色两个同类样本之间的同类距离要被一个大的间隔分散开,从而使同类样本之间的距离小于异类样本之间。
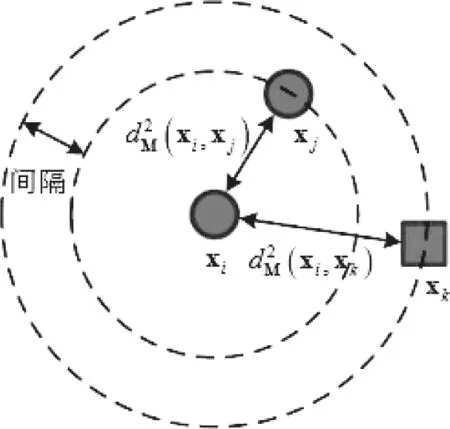
图3 点与点之间的三元组约束示意图
3 总结
机器人视觉领域研究问题的主要目的是让机器人拥有眼睛一样的功能,而场景识别也正是是视觉领域一个重要的研究课题,它能够有效的帮助机器人进行自主定位与构建所在环境的地图,对接下来的工作具有重要意义。然而现有的传统场景识别系统存在着空间大并且无法识别光照等环境变化的缺点,效率也较低,造成了研究者时间和精力的浪费。基于此,本文将能够使机器人自动提取图像特征的深度学习应用到场景识别中。
在本文的场景识别系统中,主要包含了以下几个部分:采用回环检测的方法修正SLAM前端采集的数据的误差因时间积累而产生的偏差,因为回环检测的关键步骤在于场景识别,本文摒弃了场景识别传统的BOW模型,以人对场景识别的原理为出发点,为机器人赋予了建立数据集与计算输入数据与数据集间相似度的评分机制两个功能,这两个功能可以有效改善传统的BOW模型。在回环检测中阐述说明了基于三元组约束的距离度量学习模型,该模型需要将采集的样本中同类样本的距离与异类样本特征之间的距离用一个很大的间隔隔开。
本文的识别方法对于机器人在实际情况中进行场景识别时可能会出现识别出错的情况,为了进一步提高机器人对于场景的识别准确率,可以从多个方向与角度拍摄图像对场景进行识别,然后将多次识别出的结果进行整理。本文仍需大量实验来提高识别的准确率。
4 工作展望
本次研究提出了基于深度学习的场景识别方法,避免因光照等环境变化而无法准确进行场景识别的问题。但只进行了思考与对模型的设计,缺乏利用实际情况来进行检验与验证。未来可结合实际实验的结果对设计进行再一次突破并向其中添加优化策略。
