机器学习在学生成绩预测中的应用
2019-02-14徐铭希
徐铭希
(南京市第十三中学,江苏南京,210036)
1 研究背景
我国正处于实现中华民族的伟大复兴的最关键时期。发展是是十分重要的,而科技是发展的前提,要想科技发展,教育是最重要最根本的。教育领域急需像人工智能这样的尖端技术手段来注入活力。人与人之间的竞争随着社会的发展、进步变得越来越激烈。每个人都为了自己的前途打拼,大家都在用功,不仅在成人的职场上,更在我们学生的校园里。这场竞争像一场竞速赛,赛场上瞬息万变,每一秒钟都有人超越别人或被别人超越。同学们对于自身的定位没有准确及时的把握,过高或过低估计自己的情况经常发生,平常学习的松懈可能会导致成绩下滑而自己感觉不到,当真正意识到的时候,再想追赶,已经不容易了。同时科技的发展使得社会日新月异,每天都变得更好更方便,特别是计算机网络方面,人工智能从上世纪五十年代崛起到现在成为生活中必不可少的一部分,让我们看到了人工智能的巨大潜力和广阔的发展前景。人工智能已经在许多领域里面得到了应用,它的每一次应用都会带来前所未有的改变,本文将把人工智能领域机器学习方面的相关知识应用到教育领域中,通过一些模型来预测学生的学习成绩,从而为学生的学习提供一定的指导。
2 研究方法
本次研究将采用多种机器学习算法对学生的成绩进行预测,包括逻辑回归、决策树、随机森林、xgboost。通过对各个模型的对比,最终选择出一个最优的模型,并根据该最优模型为学生的学习提供一定的指导。下面我们介绍一下每个模型的原理及思想。
■2.1 逻辑回归
逻辑回归(Logistic Regression),又称为对数几率回归,它是一种分类算法,可以处理二元或多元分类。该算法的核心思想体现在Sigmoid函数,如式(1)所示。该函数限定预测值的区间为[0,1],这样我们可以根据预测的值的大小与指定的阈值进行对比,大于该阈值为一类样本,小于该阈值为另一类样本。根据处理任务的不同,应采用不同的损失函数来对模型进行优化,其中在处理回归任务时一般采用均方差损失函数;在处理分类任务时一般采用交叉熵损失函数。
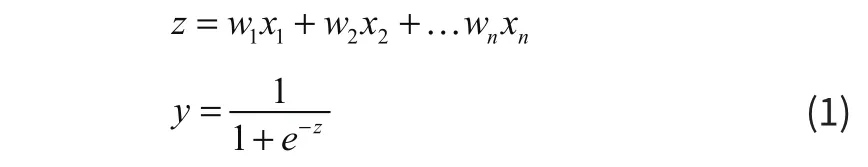
■2.2 决策树
决策树(DT),该模型是在已知各种情况发生概率的基础上,通过求取净现值大于等于零的概率来评价项目的风险并判断其可行性的决策分析方法。由于根据这种决策分析方法画出图形很像一棵树,所以我们一般称它为决策树。一般来说,一棵决策树包括一个根结点、许多内部结点和叶结点。叶结点代表决策结果,内部结点代表属性测试,而根结点代表样本全集。决策树主要分为决策树ID3、决策树C4.5、CART这三种。决策树的核心就在于如何去选择一个最优的特征进行结点分裂,其中ID3采用信息增益作为度量,该度量倾向于特征值比较多的特征;于是C4.5算法在信息增益的基础上引入了信息增益比作为衡量特征重要性的度量;但是信息增益比所涉及到的计算是非常大的,进而CART又引入了基尼指数这一新的度量方式,从而使得决策树在计算特征重要性是只涉及平方运算,不再涉及耗时的对数运算,同时,CART决策树在结点分裂时,只分裂为二叉树,这样也比较适合计算机的运算模式,能够提高计算速度。
■2.3 随机森林
随机森林(RF),它是集成学习的一种。集成学习,是通过将多个单个学习器集合到一起使它们共同完成学习任务。它博采众长,结合多个弱学习器组成了强学习器。如果个体学习器是同种的, 那么这个集成是同质的。如果个体学习器是不同种的,那么它是异质的。而根据个体学习器生成方式的不同可以将其分为两大类。一种是串行化方法,这种方法具有很强的依赖关系,必须在个体学习设备之间串行生成,这种方法以Booke级数算法为代表;另一种是不存在强依赖关系的并行化方法,它可以在单个学习设备之间同时生成。它是用套袋系列算法来表示的。随机森林是它的一个拓展变体,弱学习器采用CART决策树,它的核心思想体现在“随机”二字,即相对于传统决策树依次计算所有特征的重要性,随机森林首先会随机选择一部分特征,然后在这些特征中再通过基尼指数选择出最重要的特征作为分裂结点。该模型的特点是比较简单易于实现,而且计算量相对比较小,是数据挖掘领域经常使用到的算法。
■2.4 xgboost
上文在介绍随机森林时,有提到集成学习Boosting系列算法。Boost系列中一个比较典型的算法是GBDT(梯度提升树),它也是一种表达能力比较强的算法。而xgboost可以看作是G B DT的一种优化版本。相对于G B DT,xgboost引入了一些新的特质,使得模型的训练速度更快、更好的避免过拟合、有更强的扩展性等。如xgboost的弱学习器支持其它线性分类器(LR),它引入了一些正则化方法与采样技术,可以更好的避免过拟合现象,它引入了“Shrinkage”思想,降低前一棵树的学习效果,从而为后续的决策树提供更多的学习空间;此外,xgboost还引入了特征并行的方法,大大提高了训练速度。xgboost是当前机器学习领域的一个非常优秀的模型。
3 实验过程
■3.1 实验数据
本次研究中用到的数据集为xAPL-Educational Mining Dataset。它是一个多变量数据集,该数据集中样本的属性可以分为三个类别:人口统计学特征,如性别国籍等;学术背景属性,如学习教育阶段、分数段等;表现特征,如举手次数、学习公开资料次数等。
■3.2 数据处理与探索
首先修正数据中一些列名大小写的不规范。然后进行数据探索,查看标签各个类别的数目,观察发现各个类别的数量相对均衡;通过可视化工具作图查看数据的分布,实验数据为两个学期的数据,经观察我们发现学生在第二学期成绩会更优秀、女生表现的比男生好、越高年级学生观看学习资源越多等现象。通过PairGrid图观察数值型特征之间的关系,如图1所示,可以发现女同学在学习方面表现的相对积极,如举手次数、观看学习资源次数等。

图1
■3.3 模型构建
该部分分别采用了逻辑回归、决策树、随机森林、Xgboost进行了实验,并从各个指标观察模型的性能。其中,各模型的准确率对比如表1所示。

表1
接下来我们应用网格搜索法对随机森林与Xgboost进行参数调优,主要对弱学习器的个数、每一个叶子节点上样本个数、树的深度与学习率等参数进行调整。对参数调优后,随机森林与Xgboost的准确率为表2所示。

表2
可以看到经过参数调优后,Xgboost模型的效果最好,准确率为81.94%。我们分别看一下由Xgboost得到的特征重要性(图2)与由随机森林得到的特征重要性(图3)。

图2
可以看到图1中观看学习资源次数、参与讨论次数、看公告次数和举手次数是最重要的特征;图2中观看学习资源次数、举手次数、看公告次数和缺勤次数是最重要的特征,而参与讨论的重要性仅次于它们。而性别特征与国籍特征对学生成绩的影响不大。
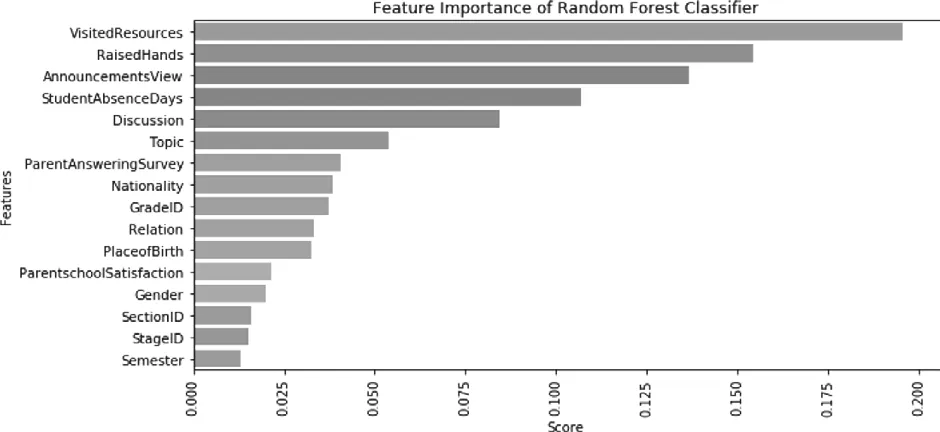
图3
4 总结
本文通过多个模型对学生成绩进行预测,并对影响学生成绩的各个因素进行了分析,根据实验分析结果可以为学生、家长及老师提供一些意见与建议。后续我们可以收集更大量的、更多种类的数据,并采用更复杂的模型优化预测结果。在此基础上,还可以针对模型结果为学生制定学习计划,提出不同的建议,进为学生定制个性化作业,针对弱点劣势查缺补漏。由此看来,机器学习在教育领域的应用前景光明,需要更多深入的研究来助其进一步发展。
