一种提升树算法在网络故障关联分析中的应用*
2019-02-14赵运弢崔文杰左甜甜徐春雨
赵运弢,崔文杰,左甜甜,徐春雨
(1.沈阳理工大学信息科学与工程学院,沈阳 110159;2.东北大学信息科学与工程学院,沈阳 110819)
0 引言
随着机器学习技术的不断发展,人类借助机器学习深入研究数据背后的规律和存在的问题,将人所具有的学习能力、分析能力赋能于机器,代替人类完成重要的智力活动和任务,并在许多方面取得了成功[1-2]。与此同时,随着网络空间规模的日益扩大和延伸,其网络复杂度越来越高,网络管理者对网络的有效性控制面临严峻的挑战。其中,故障诊断和预测是网络管理中的重点和难点所在,如果网络的故障不能快速诊断和修复,无论对民用网络还是军事网络都将产生破坏后果。
目前针对网络故障关联分析模型已有一些研究,他们主要从特征选择和优化分类器模型两个方面来研究。文献[3]提出了基于Gb 信令的GPRS 业务的潜在投诉故障预测方法。主要是从用户投诉的信令分析入手,归纳信令特征,建立信令特征库,最后采用决策树算法作为分类器来预测用户投诉行为。文献[4]利用最小二乘SVM 模型进行网络故障诊断,并采用粒子群算法对模型参数进行寻优,最终建立模型诊断网络故障。文献[5]中将无监督的SOM 神经网络以及有监督的BP 神经网络进行结合,通过SOM 神经网络对训练样本进行聚类。文献[6]提出了基于大数据驱动的投诉预测模型,他们首先在以往预测模型的数据集中加入大量运营支持系统数据,其次运用现有机器学习算法自动学习能描述用户间关系的图特征和特征间的二阶组合特征,通过此类特征来提高模型的预测精度,最后运用并行随机森林来加快模型运行速度。文献[7]提出了基于深度学习的网络故障预测模型,运用深层网络模型深度置信网络来自动学习用户特征间的非线性组合特征。文献[8]将粗糙集理论和BP神经网络模型进行结合用于网络故障诊断中。
本文提出一种基于k-NN 的多分类器提升树算法,针对反馈与故障关联分析的弱分类问题,利用k-NN 对特征向量空间进行批量弱分类,并结合adboost 误差函数和迭代算法,通过计算加权分类误差实现多分类器决策判别,从而实现基于k-NN 的强分类器,在此基础之上,建立相应的投诉预测模型,通过预测结果可有效降低因故障投诉率与故障率。
1 基于k-NN 的多分类器提升树算法
对于故障关联分析问题来说,将多个专家的判断进行综合所得出的判断,要比其中任何一个专家单独的判断好[9]。基于k-NN 的多分类器提升树方法就是从弱学习算法出发,基于k-NN 的随机批量进行训练学习,得到一系列弱分类器(又称为基本分类器),并结合adboost[10]误差函数和迭代算法,实现多分类器决策判别,然后组合构成一个强分类器。在每一轮训练学习的过程中,改变数据的权值或概率分布,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。因此,没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器的更大关注。对于如何将弱分类器组合成一个强分类器的问题,提升树方法采取加权多数表决的方法。具体地,加大分类误差率小的弱分类器的权值,使其在表决中起较大作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
给定训练数据集为T,
其中,每个样本点由实例与标记组成。实例xi∈X⊆RN,标记yi∈Y={c1,c2,…,cK},X 是实例空间,Y 是标记集合。其中,N 维向量xi表示为
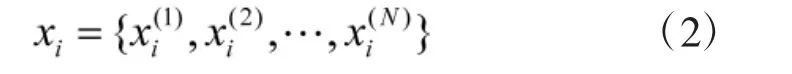
对于传统的k-NN 算法[9],实例x 所属的类y。
1)根据给定的距离测度,在训练数据集T 中获得与x 最邻近的k 个点,涵盖k 个点的x 的邻域记作Nk(x);
2)在Nk(x)中,根据分类决策规则,决定x 的类别y,

I(yi=cj)为指示函数,表示为

k-NN 算法其目标为构造一个满足式(3)的强分类器,但是由于k 值的选择会对k-NN 的结果产生重大影响。k 值如果选择较小,“学习”的近似误差会减小,但“学习”的估计误差会增大,整体模型变复杂,容易发生过拟合;k 值如果选择较大,“学习”的近似误差会增大,但“学习”的估计误差会减小,模型变得简单,但会忽略大量有用信息。在实际应用中,通常采用交叉验证的经验方法来选取最优k值,构建强分类器。
本文提出一种基于k-NN 的多分类器提升树算法,先构造一个弱分类器,

从弱分类器出发,通过“学习”训练得到一系列弱分类器,改变训练数据权值分布,构建最终分类器,算法步骤主要包括:
1)根据L1范式,定义近邻距离,
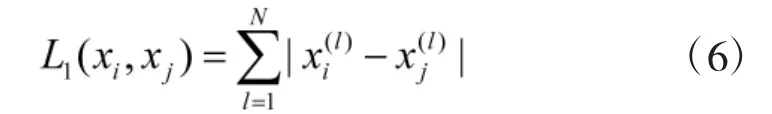
在训练数据集T 中,标记为yi的分类归属于x最邻近的k 个点,涵盖k 个点的x 的邻域记作;
2)根据式(2)~式(4),构造初始弱分类器G(mx),弱分类器应满足,
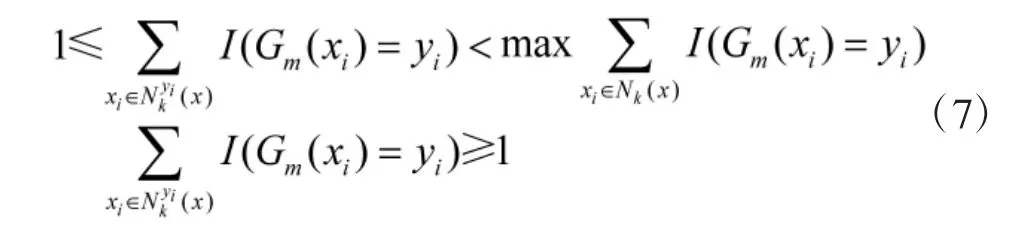
即,构造的弱分类器在邻域Nk(x)中不为空。
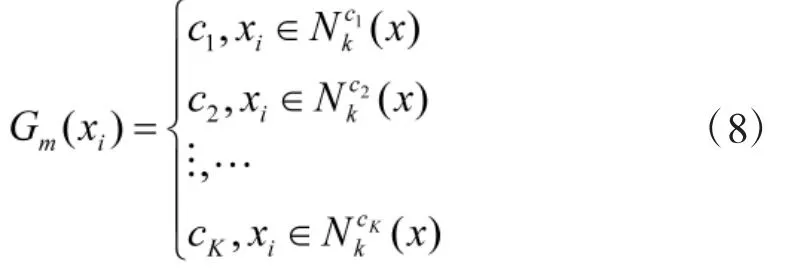
3)计算分类器Gm(x)在训练数据集上的分类误差率

根据式(2)~式(7),得0<em<1。
4)计算Gm(x)的系数

5)更新训练数据集的权值

其中,wm+1,i表示为
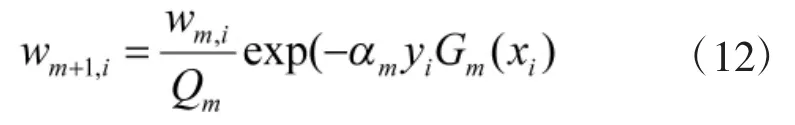
这里,初始化的wm,i为相等权值,Qm为归一化因子
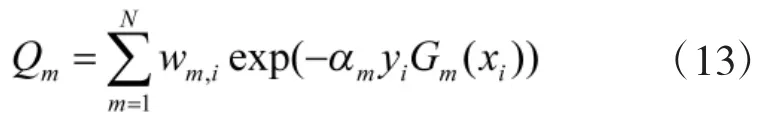
6)并计算权值分类误差

选择em+1<em的一个分类。
7)构建基于线性组合的基本分类器f(x)

8)重复4)~7)过程,直到分类器学习完毕。
9)得到最终分类器
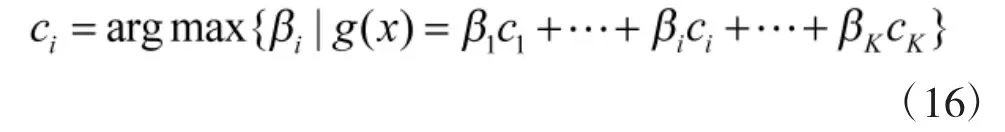
其中,g(x)是分段函数f(x)的展开式。
2 实验结果与分析
本文以某市移动运营网络一个月的反馈工单数据与故障数据作为研究对象,投诉列表中共有6 103 个样本以及27 个属性,删除取值唯一(如反馈城市)以及取值分散(如客户姓名)此类属性后,保留12 个属性进行探究。利用基于R 语言可视化12 个属性之间的关系,散点图矩阵如图1 所示。

图1 属性散点仿真图矩阵
相关系数在对角线的上方。在对角线上,直方图描绘了每个特征的取值分布。对角线下方的散点图带有额外的可视化信息。每个散点图中呈现椭圆形的对象称为相关椭圆,它提供了一种变量之间是如何密切相关的可视化信息。位于椭圆中心的点表示x 轴变量的均值和y 轴变量的均值所确定的点。两个变量之间的相关性由椭圆的形状所表示,椭圆越被拉伸,其相关性越强。
指定相关系数的值在0.1~0.3 为弱相关,在0.3~0.5 为中相关,超过0.5 为强相关。因此,筛选掉3 个与其他高度相关的属性,只留下9 个属性。同时删除错误数据以及空白数据达到对数据的清洗。
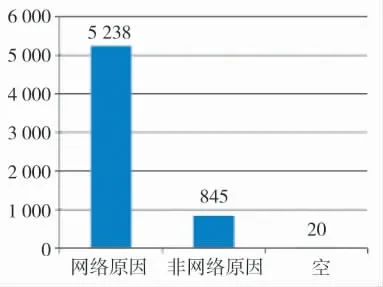
图2 网络/非网络原因分析直方图
通过对清洗后的投诉工单做统计分析,例如对问题原因属性的分析,如图2、下页图3 所示。

图3 基于网络原因的主属性分析直方图
从条形图可以直观地看出问题原因中网络原因占主要比例,网络原因中“覆盖盲点”是用户投诉的主要因素。同样还能得到其他主要因素:投诉场景中的“农村”、“居民区”,客户品牌中的“全球通”,客户级别中的“三星客户”。
通过对投诉分类的预测来分析用户投诉与故障发生的相关关系。对上述投诉表处理产生的结果,将处理完成的数据集随机打乱并分为两部分:训练集(5 071 条)和测试集(1 000 条),并对属性进行编码。通过多次实验,证明“用户归属地”、“工单性质”和“网络标识”这3 个属性区分效果不明显,故保留剩下的6 个属性,以“投诉分类”作为类标签,利用分类器(提升树,决策树,RIPPER,SVM)进行分类。
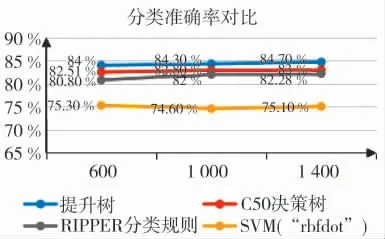
图4 分类准确率对比
如图4 所示当测试集分别为600,1 000,1 400时,应用4 种代表性分类算法的分类准确率对比,可见提升树的分类准确率最高。
通过上述研究,最终将故障划分为3 类,分别是:基站退服故障、覆盖盲点、非网络原因(客户主观原因)。将原始的投诉表按这3 种类型进行分割,其中基站退服故障包含1 598 条投诉,覆盖盲点包含3 337 条投诉,非网络原因包含835 条投诉。对这3 种故障分别通过提升树进行建模分析。
2.1 基于基站退服的故障分析
将基于基站退服故障的1 598 条投诉记录,其中1 498 条作为训练集,100 条作为测试集。通过提升树对测试集预测结果的交叉校验输出结果如图5所示。

图5 基于基站退服交叉校验输出结果图
正确分类的有87 条,其精度达到87%。
2.2 基于覆盖盲点的故障分析
对基于覆盖盲点投诉的3 337 条投诉记录,其中2 737 条作为训练集,600 条作为测试集。通过提升树对测试集预测结果的交叉校验输出结果如图6所示。

图6 基于覆盖盲点的交叉校验输出结果图
正确分类的有536 条,其精度达到89.3%。
2.3 基于非网络原因的故障分析
对基于非网络原因投诉的835 条投诉记录,其中735 条作为训练集,100 条作为测试集。通过提升树对测试集预测结果的交叉校验输出结果如图7所示。

图7 基于非网络原因的交叉校验输出结果图
正确分类的有79 条,其预测正确率达到79%。
3 结论
在网络大数据的背景下,为了提高因故障反馈分类的准确率,提出一种基于KNN 多分类器的提升树算法,采用k 近邻对特征向量空间划分,结合adboost 误差函数和迭代算法,构建基于k-NN 的强分类器,实现基于故障反馈数据的决策分类和归属判别,并将因故障反馈原因分为3 类:基站退服故障、覆盖盲点故障、非网络原因故障。构建3 种反馈故障的预测模型。通过真实数据实验分析,该算法能够有效预测网络运行故障,进而降低因故障投诉率与故障率。
