基于空间密铺的并行Stencil算法*
2019-02-13张云泉
郭 鹏,袁 良,张云泉,黄 珊,2
1.中国科学院 计算技术研究所 计算机体系结构国家重点实验室,北京 100190
2.中国科学院大学 计算机与控制学院,北京 100049
1 引言
处理器计算性能和存储器速度之间不断扩大的差距是影响软件性能的关键瓶颈之一。为了解决这一问题,在现代CPU和GPU上,硬件架构设计人员采用越来越多的片上资源来形成硬件或软件管理的高速缓存,应用程序开发人员则利用算法的局部性来最大化缓存内的数据重用。
Stencil计算是科学和工程应用中常见的循环模式。作为十三种Berkeley motifs之一,Stencil计算也被称为“结构化网格计算”。其他领域的许多算法,如动态规划和图像处理也涉及相似的计算模式。Stencil是依照预定义的模式用邻居节点更新所有节点。Stencil计算是d维空间格点随时间迭代遍历所有格点,这些d维空间格点也被称为数据空间。数据空间沿时间维度更新,形成(d+1)维空间,称之为迭代空间。Stencil存在多种分类方法,例如格点维度(1D,2D,…),邻居节点数(3-point,5-point,…),形状(星型,盒型),依赖类型(Gauss-Seidel,Jacobi)和边界条件(常数,周期,…)。
Stencil计算的特征在于其计算密集度较低。d维Stencil的简单实现由(d+1)个循环组成,其中最外层的循环遍历时间维,d层循环遍历d维空间中的所有格点。这种方法具有较低的数据重用性,因此为带宽受限。
分块方法(tiling)是提高多重循环的数据局部性和并行性的强大转换技术之一。空间分块算法以特定顺序遍历数据空间,使得缓存内的格点在被替换出cache前可被用于更新其所有邻居节点,在2D和更高维度Stencil的单时间步内改进数据重用。但是空间分块所能利用的局部性受限于Stencil的邻居规模,为了增加数据重用,通常同时考虑时间维度与空间维度。大部分现有技术都适用于d维数据空间Stencil的(d+1)维迭代空间。
作为代表性的循环类型,Stencil的分块和代码的自动生成已经被详细研究过了。例如广泛使用的多面体模型是一个具有代表性的方法,其处理的循环嵌套上下界与数组下标为周围循环索引和预定义常数参数的函数。大多数分块方法会使用固定的分块形状和大小来进行分块。例如,时间倾斜分块(time skewed tiling)方法(在2D中为平行四边形,在3D中为平行六面体,在高维中为超平行体)[1-2]消减了分块之间的依赖关系。然而,大多数方法只用一个分块形状填充空间,经常导致流水线启动并提供有限的并发性。
存在多种方法缓解流水线启动产生的开销[3-9]。也有一些允许将空间维度切割为任意数量的研究[10-11]。这些编译器生成的代码通常在编译时需要固定的分块大小。由于运行时参数化可实现高效自动调优和性能可移植性,因此开发了一些技术来允许参数化,比如矩形[12]和2D diamond[13]。然而,这些方法仍然导致高循环开销,很少允许精细优化。更多细节将在第2章中详细讨论。
自动生成的或手工编写的支持可选优化和经验自动调优参数的代码已经被证明是实现许多科学函数高性能的有效方法,如ATLAS(automatically tuned linear algebra software)[14]。对于Stencil计算,也存在自动调整框架[15-18]和编程模型[19-20]。但是这些方法大多使用单一的超矩形分块形状[21-22],并使用冗余计算来解决分块间的依赖,同时编译器通常无法充分利用硬件资源。
像其他数学函数(例如矩阵乘法和FFT(fast Fourier transformation))一样,Stencil的定义是清晰简单的。因此,对于不同尺寸、形状、顺序和边界条件的Stencil,应该有一个简洁的并行化框架。然而,高性能社区通常采用具有冗余计算的超矩形分块,而编译器社区通常侧重于传统方法,例如多面体模型,其中大多数会产生不可读和不可修改的代码。借鉴OpenBLAS[23-25]的思路,提出一个简单而清晰的具备轻量级循环条件的并行框架,并允许精细的内核优化。
为了实现这一目标,本文为Stencil计算设计了一种新的两层密铺算法。与以前直接对整个迭代空间进行分块的技术不同,首先使用不同块类型密铺数据空间,然后沿时间维度对块进行扩展密铺整个迭代空间。本文贡献如下:(1)针对Stencil计算的一种新的两层密铺算法,使得数据空间的分块可以并行执行;(2)本文密铺算法的实验分析与其他算法的比较。
本文的其余部分安排如下:第2章概述相关工作,并讨论其缺陷。提出的密铺算法将在第3章描述。第4章介绍实现和优化。第5章介绍性能结果。第6章为本文的总结。
2 相关工作
2.1 分块方法
分块方法[26-28]是提高多重循环嵌套的数据局部性和并行性的最有效的转换技术之一。Wonnacott和Strout对现有分块算法的可扩展性进行了对比[29]。接下来本文对Stencil计算的一些相关工作进行总结。
overlapped tiling:hyper-rectangle tiling[21-22]通常用于涉及高性能的手动调优。通过计算多个时间步,分块之间的依赖将会被冗余计算抵消[30],这种方法也被称为 overlapped tiling[8]。Phillips和 Fatica[31]提供了一份GPUs上手写的3.5D分块手动调优代码实现。这种3.5D分块方法通过时间平铺提升了空间受限的2.5D切分算法。虽然hyper-rectangle的规则性使得高并发和更精细的优化成为可能,但是有时候冗余操作过多反而掩盖了性能提升。因此,本文将专注于零冗余算法。
time skewed tiling:该方法(所产生的块,在2D时为平行四边形,在3D时为平行六面体,在高维时为超平行体)[1-2]可以消除冗余计算,但是大部分的方法只使用一种分块形状来填充整个空间,并总是导致流水线启动和受限的并发。类似接下来要介绍的分块技术,本文提出的密铺算法使得完全并行成为可能,同步中的所有数据块都可以并发执行。
diamond tiling:Bondhugula等[32]首先提出了用于1D Stencil的diamond分块。之后Bandishti等[3,9]将其扩展到了高维Stencil。Grosser等[7]粗化了菱形的尖端,使其在2D成了六边形,在3D变成了八面体。从本质上来说,diamond分块方法通过平行六面体切割和旋转空间得到最大并行,并行执行的分块波阵面共同组成了一个正交向量平行于时间维度的超平面。这种方法的主要优势在于它可以实现同时启动。
cache oblivious tiling:为了在未知内存结构参数的情况下充分利用数据局部性,提出了很多关于Stencil的cache oblivious(缓存无关)算法。Frigo和Strumpen提出了第一个串行[33]和并行[34]缓存无关Stencil算法。缓存无关平行四边形分块方法同时切分空间和时间维度,可以看作是带波阵面并行的缓存无关版本时间倾斜算法。Pochoir[11]实现了同时切割所有空间维度的超平面切割法,与串行算法相比,它在提高并行性的同时保证了相同缓存复杂度。
split tiling:为了避免波阵面并行中的流水线启动开销,split tiling方法识别出每个分块中没有依赖的子块并使其并发执行,然后将结果发送给继承者使其他区域也可以并发执行[8]。Grosser等[10]提出了另外一种类似于超空间切割的缓存无关范式,这种循环切割方法可以递归地在所有的空间维度上进行切割。
hybrid tiling:Strzodka 等[35]结合diamond分块、平行四边形分块和流水线处理,提出了CATS(cache accurate time skewing)算法。Grosser等[6]介绍了混合六边形和平行四边形分块算法。这些算法将迭代空间分解为两部分,在时间维度和一个空间维度上使用hexagonal tiling或者diamond分块,在其他空间维度上使用时间倾斜分块。hexagonal tiling相当于在空间维度上拉伸分块的传统diamond分块,保证了在高阶Stencil中每个分块最多依赖于三个前置,是hybrid tiling的扩展。hybrid split-tiling则是nested split-tiling和时间倾斜分块的结合。
2.2 局限性
上述提到的diamond分块[3]、hyperspace cut(cache oblivious tiling)[11]和 nested split-tiling[10]都是最近发展出的能够实现最大并发的方法。下文将说明这些方法的一些缺点,值得一提的是,本文的密铺算法是由一个能够展现清晰的图形分块算法的数学框架得出,能够克服如下这些问题。
diamond分块是一种基于多面体模型的编译器转换技术。为了实现运行参数化以达到高效的自动调优和可移植性,在编译运行时分块大小固定是它的主要限制之一。Bertolacci等[13]发展出在2D上的参数化版本,但是这并没有解决它在自动代码生成上的问题。diamond分块的另一个缺点是它需要处理位于diamond尖端的小尺寸数据块。Grosser等[7]提出在2D中diamond可以扩展为六边形分块,并选择截断的八面体作为3D中diamond的扩展。但是他们并没有给出高维(3D或更高维度)的分块图形模型。最后,diamond分块用skewed hyper-rectangles填充整个迭代空间,很难找出合适的分块大小以保证同时启动。同时,也很难设计出适应于多层内存的多层次版本。
常见的缓存无关实现总是受限于递归的开销并且只能达到有限的速度提升[36]。此外,很难将诸如SIMDization、数据打包、数据预取、数据填充、NUMA-aware调度、指令选择(缓存旁路存取)等进一步的优化加入到递归控制结构中[37]。同时,由于缓存无关算法中没有统一的数据块形状,粗化也很难实现。
hyperspace cut算法采用交错的时间和空间切割,这些算法的递归分治实现引入了子块之间的人为依赖关系[37]。Tang等[38-39]提出cache oblivious wavefront可以消减这些错误的依赖并且提高并行度,缩短算法的关键路径。然而,对波阵面数据结构的检查不可避免地会引发运行时间开销。
nested split-tiling最大的问题就是其过高的同步开销,以d维的Stencil为例,需要同步2d次。需要指出,虽然Tang等[11]正确地证明了与本文算法相同的同步开销。但是,在仔细研究了他们的代码后,发现这个基于普通的缓存无关递归框架的实现采用了部分和nested split-tiling一样的策略,同样将在d维的Stencil中同步2d次。虽然可以采用动态队列减少同步开销,但是运行时调度的成本可能会将其抵消。
3 算法
本文使用 1 阶星型 Stencil(1D 3-point,2D 5-point以及3D 7-point)作为例子,将展示这种方法适用于所有类型的Stencil。由于Gauss-Seidel Stencil强制45°并行启动,且不能通过分块方法提升至完全并发启动[8],因此本文只讨论Jacobi Stencil。
3.1 重构1D Stencil
首先介绍一种重构1D diamond分块的方法,这种方法是新的两层n维Stencil分块方法的基础,可以看作是用不同形状的分块对迭代空间进行密铺。
1D 3-point Stencil的diamond分块方法如图1(a)所示。每个diamond被平行于x轴的横线划分为两个大小相等的子三角形,迭代空间被正三角形和倒三角形填充,整个执行过程为正三角形和倒三角形的交错计算。每条横线代表一次同步,横线上每个格点都更新了相同的时间步长。两条横线之间为一时间分块(time tile),其中每个网格点在相同的时间维度开始计算并更新相同的时间步。观察正三角形和倒三角形开始计算的维度,可以看到,正三角形完全基于起始的7个格点进行计算,而倒三角形起始于一个格点,基于这个格点和正三角形中已经更新了一定时间步的格点进行计算。正三角形和倒三角形起始维度的两种形状对迭代空间完成了密铺。
每个正三角形和倒三角形可以通过各个格点在时间维度上更新的次数来表示。以图1(a)为例,对于包含7个数据格点的数据块(三角形在数据空间上的投影),按照各格点在该数据块中更新的时间步数可表示为(0,1,2,3,2,1,0),其中心点更新了3次且其邻居的更新步长与其到中心的距离成反比。观察倒三角形的结束维度,其更新时间步数为(3,2,1,0,1,2,3)。这样,当正三角形和倒三角形计算完毕所有格点到达横线位置,所有的格点都更新了3次。整个执行过程如图1(b)所示。
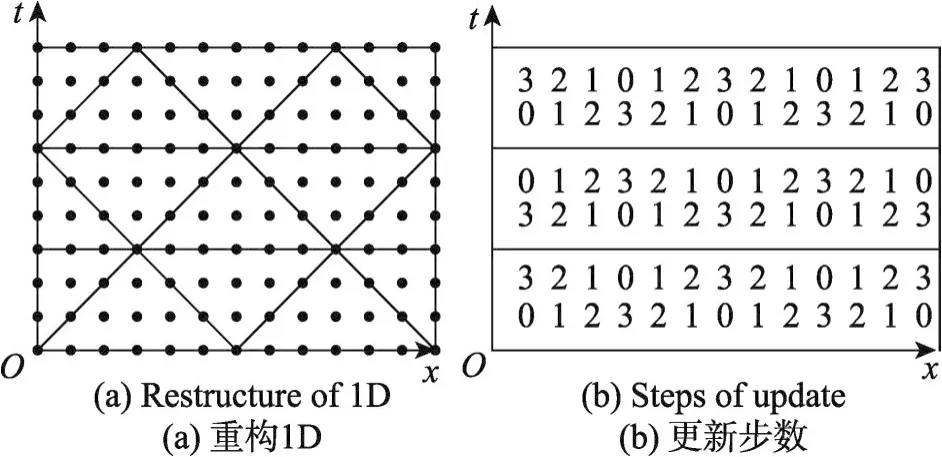
Fig.1 Tiling of 1D Stencil图1 1D Stencil的分块
当扩展到更高维时应注意两个问题。第一,虽然正三角形和倒三角形的投影形式相同,但是其执行过程不同。正三角形中,所有的格点同时开始计算,而倒三角形中所有的格点同时结束计算。第二,可以通过重用时间分块之间的块消除分割线上的同步。
3.2 2D Stencil密铺
首先介绍最大更新的基本思想,最大更新即给定一个块,其中每个点沿着时间维度向上更新直到无法满足Stencil定义的依赖关系。形式化而言,对于任意格点a,当存在至少一个邻居格点a′∈neighbor(a)使得a′所在时间维度严格小于a,即time[a′]<time[a]或a′∉Bi时停止更新。当给定一个d维数据空间块Bi,通过关联每个格点的更新时间步数来生成其(d+1)维扩展块,记为Bi。
由于Bi之间的转化是高度对称的,因此可以在B0的子块上讨论整个迭代空间的密铺算法。具体来说,假设有一B0块,其中心点位于坐标系的原点,则只考虑其中位于第一象限的点。在第i阶段最大更新完成后,记这个子块为B+i。将每个Bi块中第一个(最后)时间步更新的格点构成的区域称为起始(结束)区域。
与前述的1D diamond分块相似,将2D Stencil的迭代空间划分为若干时间分块,所有的格点在一个时间分块开始时位于相同时间维度,在一个时间分块结束时更新相同的时间步。每个时间分块中包含三个阶段,即三种块形状。2D Stencil的三种阶段块形状以及其转化过程的俯视图如图2所示。其中B0是一个正方形,每个B0沿着x维和y维分割(虚线)为4块,每个子块包含B0的一边,每两个共享同一边的子块合并形成B1。需要注意的是,虽然所有的B1有相同形状,但分别是从两个方向构造出来的,在这里不妨记x轴方向两B0块之间的为B11,平行于y轴的两B0块之间的为B12。将每个B1沿着其与合并维度正交的维度划分,四个相邻的子块结合在一起形成了B2。
2D 5-point Stencil某一时间分块中的更新过程如表1所示。表中第二、三、四和五行分别为B0块、B11块、B12块和B2块的更新展示,其中b=3。第二列为各阶段块完成最大更新后的对应更新步数,之后的第三、四和五列依次为各阶段块在对应时间步更新的区域,为了方便理解在最后一列给出各阶段块的形状。阶段块在各个时间步的计算都是数据空间中的一个矩形,而且当前时间步矩形区域范围可由前一时间步矩形区域计算得出,因此在笛卡尔坐标系中当给定起始区域坐标范围,即可确定整个块各个时间步的计算范围。可以看到,B0块在给出起始区域后,其计算范围在x和y维度依照Stencil依赖递减,而B11块和B12块在某一维度减小时另一维度增加,B2块两个维度都在增加,这是由Stencil的依赖关系决定的,在计算B0块时,只能根据起始区域的值进行计算,而计算B11块、B12块和B2块时,虽然起始区域给定,但是B0块已经将其起始区域外的依赖点计算完毕,因此可以计算起始区域之外的点。可以看到在整个计算过程中,同类分块间不存在依赖关系,任一分块中不存在无用格点,即不存在冗余计算。
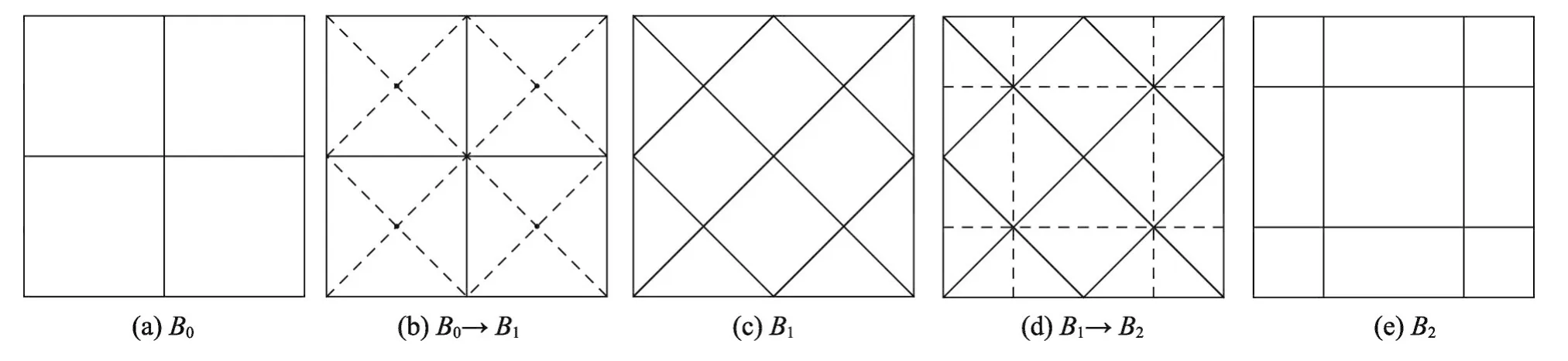
Fig.2 Tessellating data space of 2D Stencil图2 2D Stencil数据空间的密铺
为了形式化描述2维Stencil的这些分块,如图3所示,在空间中引入笛卡尔坐标系。令一个B0块的中心点为原点(0,0),则其他B0块的中心点为(2k0b,2k1b),其中ki为整数。此B0在非负象限相邻的B11块、B12块和B2块的中心点坐标分别为 (b,0)、(0,b)和(b,b),将坐标为0的维度记为起始维度,把其他维度称为结束维度。选取B0中一点a(a0,a1),其在第i阶段的最大更新时间可以表示为Ti(a0,a1),点a在B0坐标系统里的新坐标为(a0,a1),在B11坐标系统里的新坐标为 (b-a0,a1),在B2坐标系统里的新坐标为 (b-a0,ba1)。在阶段i,当时间等于点a在结束维度到中心点的最大距离值时,a开始更新,当时间等于其在开始维度到中心点的最大距离与b的差值时结束更新。以点a(2,1)为例,将各块中心点移动至原点,则a点坐标取正后为(2,1)、(1,1)和(1,2)。用圆圈圈出点a在各阶段所处更新位置,如表1中所示,B0块中a点在第1步时更新了1步,在B1块中y维为起始维度,第2步时更新了1步,在B2块中第3步时更新了1步。

Fig.3 Cartesian coordinate systems图3 引入笛卡尔坐标系
3.3 高维、高阶和周期边界
本节将密铺扩展至高维和高阶Stencil,并讨论周期边界的问题。d维Stencil每个时间分块的计算都包含d+1个阶段。记d+1个阶段中镶嵌于d维数据空间的d+1种数据块为Bi(0≤i≤d),即在阶段i,使用Bi镶嵌数据空间。其中B0为超立方体(在1D时为线段,2D时为正方形,3D时为立方体,4D时为超立方体,…)。

Table 1 Tessellating data space of 2D Stencil表1 2D Stencil的密铺迭代
令B0中一点a(a0,a1,…,ad-1),其在第i阶段的最大更新时间可以表示为Ti(a0,a1,…,ad-1)。不失一般性的,假设包含a的B0块的中心点为 (b,…,b,0,…,0),其中前i个坐标为b。点a在Bi坐标系统里的新坐标为 (b-a0,b-a1,…,b-ai-1,ai,ai+1,…,ad-1)。则开始计算时间步和结束计算时间步为:
将其合并可以得出:
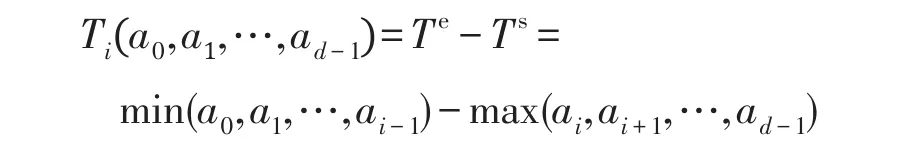
特别的:

高阶Stencil在实际应用中十分常见。如果Stencil中某一维度上的阶数为m,可以将每m个点结合在一起,称之为超级节点。这样就将超级节点中的m-阶依赖减小为了1阶依赖。在图4中给出了在x维上m=2的例子。对高阶依赖的所有其他维度进行类似操作就可以使用Bi对这些1阶依赖的超级节点执行密铺操作,而超级节点中所有格点的更新步数与其在Bi中的更新步数相同。
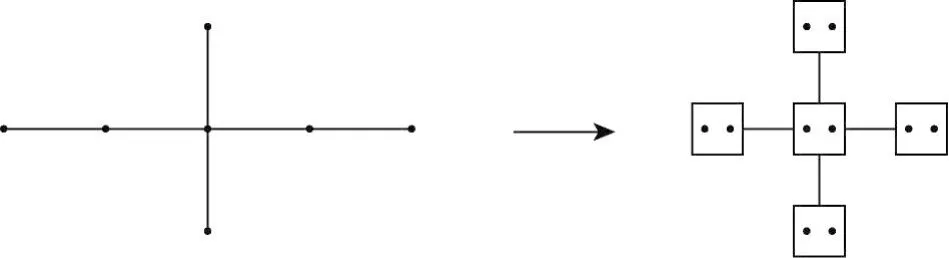
Fig.4 Handle high-order Stencil图4 处理高阶Stencil
对于周期边界的情况,需要将一侧边界的一个块或高维中的多个块进行拉伸。输入尺寸不是块大小整数倍的1D Stencil例子如图5所示,其中灰色点为边界格点额外需要的数据。通过将一个diamond块沿着空间维度拉伸而产生了一个六边形块,保证在两侧边界的子块为相同类型分块。
4 实现
基于上述清晰的数学描述,可以直接得出对应代码。在第5章,将提供手工实现的性能结果。当然,自动代码生成的工具也很容易实现,这将是下一步的工作内容。
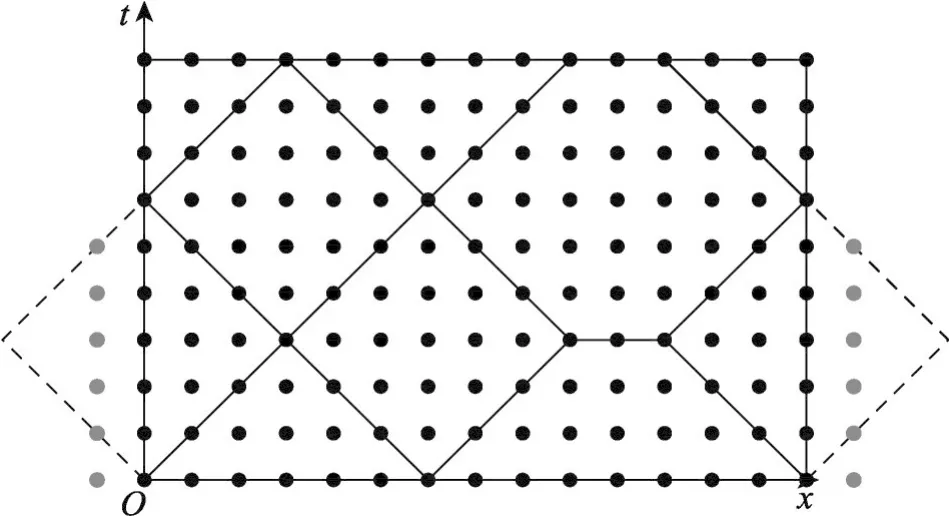
Fig.5 Handle periodic boundary condition图5 处理周期边界
因为同一阶段的所有块都可以同时执行,可以很容易地实现密铺算法的并行化。因此只在共享内存的设备上使用了OpenMP pragma parallel for指令。
4.1 粗化
对于3D或者高维Stencil,其各个维度的尺寸通常都小于1 000。为了更好地利用硬件预取功能,现有的做法通常是将单位跨度的维度切掉。但是这样就会限制并发性。此外,时间维度的尺寸b(由最大更新产生)通常受限于一个块各个维度中最小尺寸,因此在空间维度不相等的划分可能会引发时间维度上受限的数据重用。
粗化的另一个驱动因素是本文的密铺算法可能会导致无效的数据访问模式。以2D为例,如表1中所示,两个四面体B1块在第一个或者最后一个时间步会产生行主数组的列中的元素的更新,这种低效的空间位置使用可能会降低性能。
密铺框架是高度可修改的,它允许对各个维度块尺寸的修改,并通过沿着各个维度拉伸来实现粗粒度化。为了便于解释,2D Stencil的粗粒度化如图6所示。为了改善空间局部性,B0的结束区域(图6中的深灰色区域)和Bd的起始区域(图6中的黑色区域)粗化为相同大小的2D块。
如上所述,在第一阶段和最后一阶段的数据块有相同的形状。在合并时段之间的Bd和B0可以减少同步并提高数据重用。通过实验可以得出,如图6所示,两个B0在某一维度上的间距等于B0结束时在这个维度上的大小。这也就保证了B0的结束块形和Bd的起始块形完全一致。
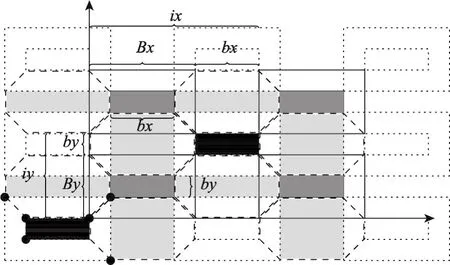
Fig.6 Realization of 2D Stencil图6 2D Stencil的实现
4.2 具体实现
本节以数据规模为N2的非周期2D Stencil为例介绍算法的具体实现。由于算法支持任意阶数的Stencil,因此参数化其在x轴、y轴方向的斜率分别为XSLOPE和YSLOPE,因此数组计算范围为XSLOPE~N+XSLOPE-1。
如图6所示,在算法中,所有Bi中的每个时间步计算的数据空间都是一个矩形,根据Stencil计算本身的依赖关系和最大更新的思想,当前时间步的矩形可由前一时间步的数值以及斜率计算得出,由前述可知,在同一时间分块中,各阶段块规律分布,因此由某一阶段块起始区域的(xmin,ymin)即可计算得出该阶段块各时间步需要计算的数据空间大小,同时计算得出当前时间段所有相同阶段块的所有信息。
Bx和By分别为B0块中起始区域在空间维度中的长度,tb为更新步数,这三个参数也是算法的主要调优选项之一,由这三个参数可计算得出其结束区域的区块大小:
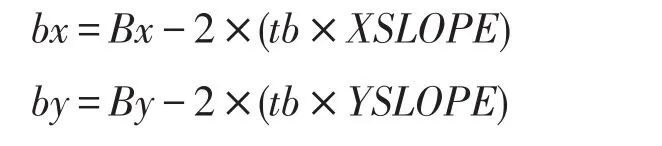
如前所述,为了实现算法粗粒度化,B0以及B2分块之间在x和y方向的距离分别为Bx+bx和By+by,记为ix、iy,则在x轴、y轴方向各有B0块个数。
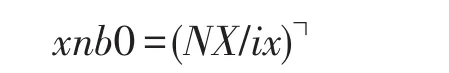
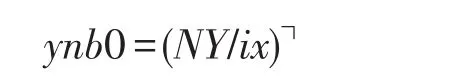
其中,┐表示向上取整。对于B11块和B12块,观察图6中形状可得出:
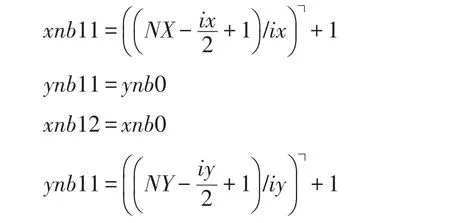
因为只要存在B0或B1块,必定有B2块使其达到最大更新,故:
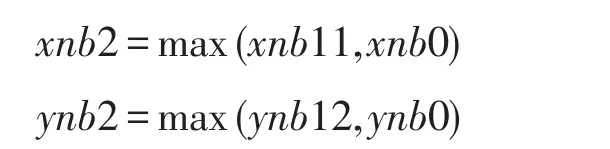
不考虑越界问题,由图可以确定各块的点坐标,选取起始区域左下角块的左下角点作为索引点,例如,B0块的索引点为:
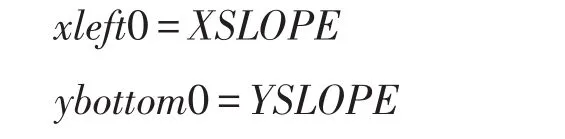
观察图6可以看出,B0块更新后B1块、B2块依次更新,完成一次最大更新,之后在B2块的结束区域继续向上更新,需要注意的是这时对应之前B2块的位置已经变为B0块,B11和B12的位置也发生了互换,在这里引入level,在其奇偶发生变化时B0和B2、B11和B12的位置相互转换,为了提高代码的可读性,令T从 -tb开始,将所有B0块和B2块融合在一起记为B02,将其坐标进行整合:
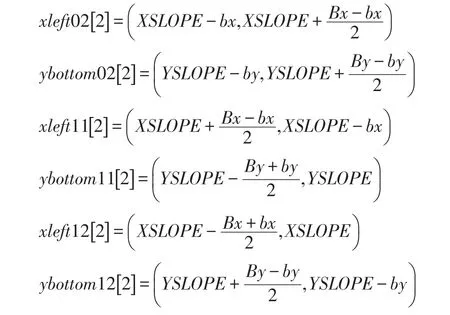
所有6个索引点如图6中黑点所示。
算法的主体代码如算法1所示,其中包含4层循环。最外层循环控制时间分块以tb递增,第一层循环内包含两个3层循环,其中第一个用于计算B0块和B2块,第二个用于计算B1块。如前文所述,算法将B0块与B2块结合在一起形成B02块,B02块从原B2块的起始区域开始计算,到其对应的B0块的结束区域为止结束计算,其计算的时间步长为2×tb,需要计算的块个数根据level不同为B0或B2块个数。需要注意的是,虽然令时间步从-tb开始,但是实际计算中需要用max(tt,0)限定其计算范围。如图6所示,当给定块编号n,结合x轴和y轴方向间距ix和iy以及索引点坐标(xleft02,ybottom02),即可确定当前块的索引坐标 (myxmin,myymin)进而确定 (myxmax,myymax),对于B2块,其x轴和y轴方向的计算范围随时间步都向外扩张,B0块恰好相反,其x轴和y轴方向的计算范围随时间步都向内收缩,由于其变化幅度恰好互负,可以简单地通过abs(t+1-tt-tb)×SLOPE来确定当前时间步的计算区域。对于B1块,其起始时间步比B02高tb,(myxmin,myymin)和(myxmax,myymax)的计算方式与B02块相同,由于B11块和B12块形状不同,其在x轴方向和y轴方向的变化恰好相反,在这里分开计算,可以使用一个简单的判断语句,令前#B11个块去计算B11块,剩下的#B12个块去算B12。如前文所述,Bi块的每个时间步计算区域都是矩形,当确定了各时间步(myxmin,myymin)和(myxmax,myymax)的计算方法,之后就是简单的两层循环更新格点了。
算法12D Stencil


5 实验结果
5.1 实验环境
实验环境为配置有两个2.70 GHz的Intel Xeon E5-2670处理器的机器,并在单核到24核上进行了测试。单核L1和L2大小分别为32 KB和256 KB,一个socket上的12个核共享30 MB的L3 cache。ICC版本为16.0.1,优化选项为“-O3-openmp”。
将密铺算法和上文提到的三种高度并行方案中的两种进行了比较,即Pluto和Pochoir。其中Pluto采用diamond分块方法,Pochoir采用hyperspace cut分块方法。将split tiling代码和本文方案进行比较是不合理的,因为它们采用了额外的有效向量化方法。本文只比较具有相同编译选项的原始核心代码,由编译器本身来完成向量化。
测试包括四种星型Stencil(Heat-1D 3-point、Heat-1D 5-point、Heat-2D 5-point和Heat-3D 7-point)以及两种盒型Stencil(Heat-2D 9-point和Heat-3D 27-point)。各种测试的用例如表2所示,其中周期边界与非周期边界的数据规模相同。Benchmark测试参数大小与文献[3]中的参数大小一致,保证数据规模大小能够真实反映算法性能同时不会导致过长的测试时间。由于密铺方案的代码包含更多的可调参数,将其他参数设置为分块大小的一半或两倍,使其与Pluto和Pochoir中的分块近似。
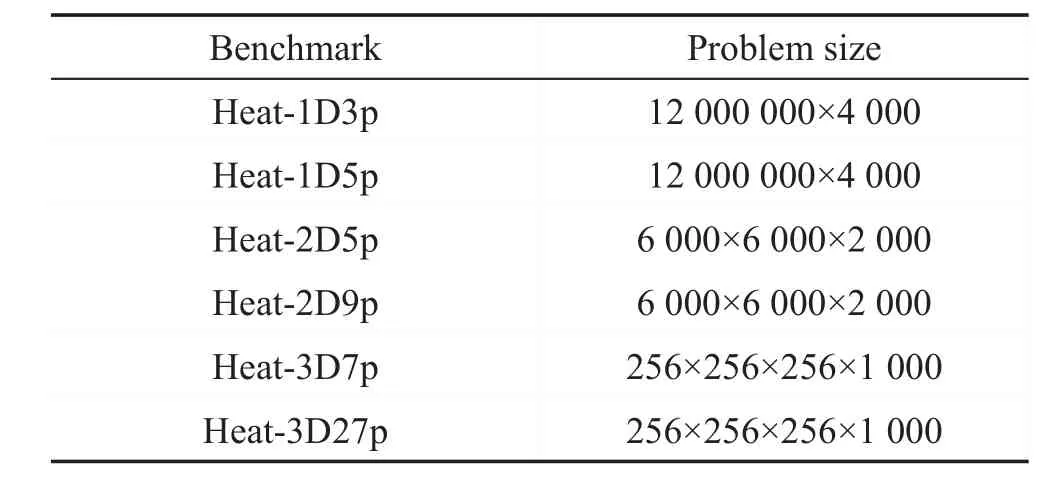
Table 2 Problem size of Benchmark表2 问题规模
5.2 分析
总体来说,本文算法在星型Stencil上获得了有竞争力的性能数据,并且在盒型Stencil上表现出更好的性能。Pluto和Pochoir展示了在文献[3]中相似的性能趋势。Pochoir表现出比Pluto更好的可扩展性,而Pluto经常获得更好的性能。密铺的代码实现了更好的加速和可扩展性。
1D Stencil的结果如图7(a)和图7(b)所示。所有的这三种方案都显示出了线性可扩展性。新算法的性能和Pluto的性能相似,并优于Pochoir的性能。这是因为密铺算法和Pluto产生相同的菱形划分代码,而Pochoir利用动态调度方法生成不同大小的梯形块。

Fig.7 1D non-periodic boundary condition图7 1D非周期边界

Fig.8 2D non-periodic boundary condition图8 2D非周期边界
图8(b)和图8(a)中显示的是非周期2D Stencil的性能结果。对于Heat-2D 5-point Stencil,本文的代码和Pochoir展现出相似的性能表现和可扩展性。Pluto则如文献[3]中提到的受限于负载不均衡。在24核时,Pluto只比另两种高不到5%。对于2D 9-point Stencil,Pluto和Pochoir表现出了和5-point Stencil中相同的趋势。但是本文的代码平均比他们提升了14%和20%。周期边界2D Stencil的结果如图9(b)和图9(a)所示。最高性能比Pochoir提升了10%和20%。
非周期的3D Stencil的性能结果如图10(a)和图10(b)所示。本文的代码和Pochoir的代码相比于Pluto有更好的可扩展性。和2D星型例子相似,在超过21核时Pluto表现出优于Pochoir和本文的性能。但是在3D 27-point Stencil中,本文的代码性能显著优于Pluto和Pochoir,最高提高74%和100%,平均提升达30%和99%。周期边界3D 7-point Stencil和3D 27-point Stencil的结果如图11(b)和图11(a)所示。最高性能比Pochoir提升了25%和40%。
6 结论
本文提出了一种新的针对Stencil的高并发的并行框架。这是一种基于新的两层时间分块的算法。通过一系列块来镶嵌空间维度,然后这些块的扩展密铺了整个迭代空间。密铺算法提供了简洁的并行化框架,并揭示了网格点的坐标和更新时间步长之间的关系,该算法可以最大化并发执行,在执行过程中没有冗余计算,有简洁的循环条件并可以适应Stencil不同的尺寸、形状、阶数和边界条件。实验结果表明,该方案在星型Stencil上实现了相当的性能,在盒型Stencil上表现出更好的性能。对于1D Stencil,由于密铺算法表现为和Pluto相同的diamond分块,性能与其持平,对于2D Stencil和3D Stencil密铺算法都有更好的性能表现,其中在非周期3D27p Stencil中,相较于Pluto有12%的性能提升,周期边界3D27p Stencil相较Pochoir的性能最高提升40%。
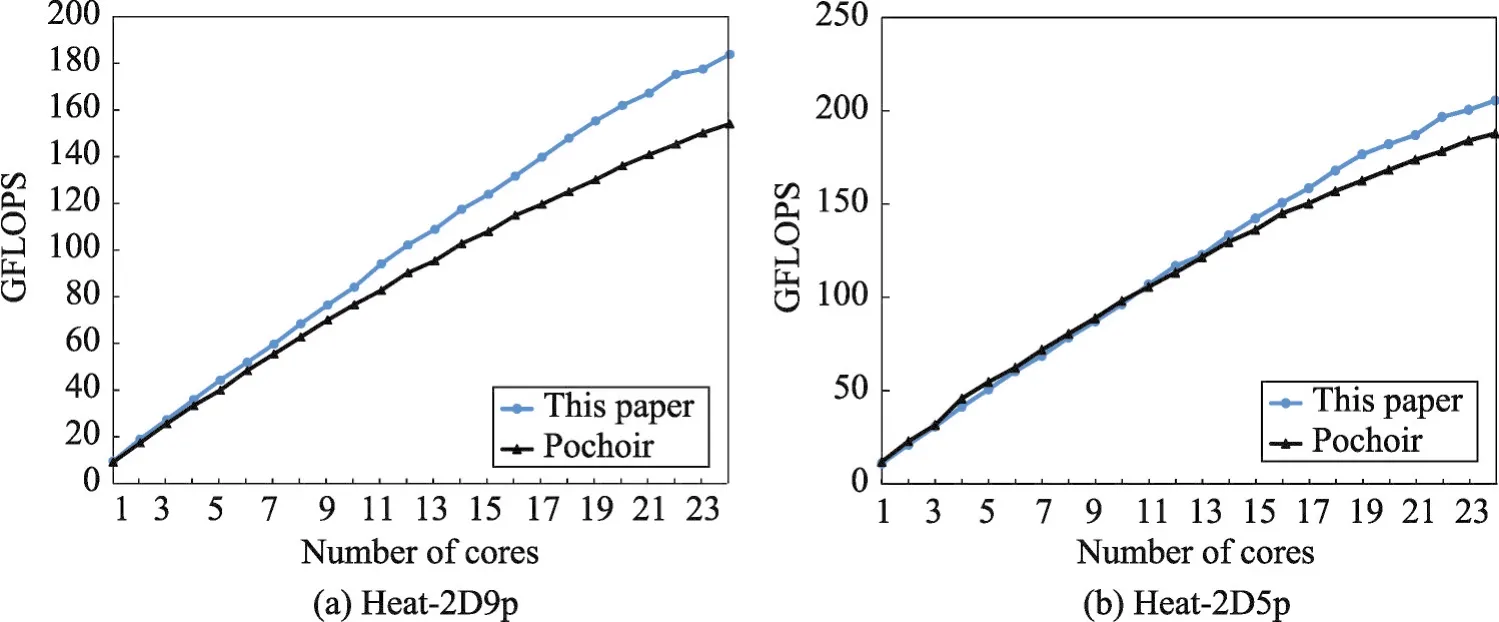
Fig.9 2D periodic boundary condition图9 2D周期边界
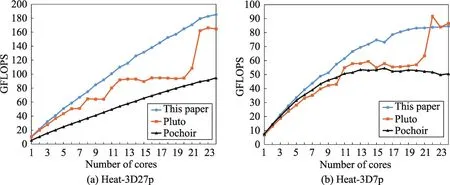
Fig.10 3D non-periodic boundary condition图10 3D非周期边界

Fig.11 3D periodic boundary condition图11 3D周期边界
未来将基于该框架设计一套自动代码生成工具。由于其中包含相较于其他方法更多的参数,现在的工作正致力于寻找可以自动找出最优分块大小的方法。
