深度学习的视觉关系检测方法研究进展
2019-01-30丁文博许玥
丁文博 许玥


摘 要:视觉关系检测或视觉关系识别,不仅需要识别出图像中的目标以及他们的位置,还要识别目标之间的相互关系,是计算机视觉领域非常具有挑战性的任务,也是深度理解图像的基础。得益于近年深度学习的蓬勃发展,视觉关系检测技术取得了显著进步。本文介绍了近年来基于深度学习的视觉关系检测的研究进展,从主要挑战、应用领域、公开数据集、算法模型、模型评估标准、模型效果这几方面进行对比分析,并展望了视觉关系检测未来的发展方向和前景。
关键词:视觉关系 深度学习 语义模块 视觉模块
中图分类号:TP391.4 文献标识码:A 文章编号:1674-098X(2019)09(c)-0145-06
Abstract:Besides identifying the objects and their positions in the images, visual relationship detection/visual relationship recognition also requires the identification of the interactions between the objects. Although visual relationship detection is a challenging task in the field of computer vision, the recent development of deep learning and significant advances in the techniques of visual relationship detection have laid the foundation for deep understanding of the images. This paper mainly reviews the research progress of visual relationship detection based on deep learning in recent years, compares and analyzes the main challenges, application fields, open data sets, algorithm models, model evaluation criteria, and model effects, and investigates the future development for visual relationship detection.
Key Words: Visual relationships; Deep learning; Semantic module; Visual module
计算机视觉(Computer Vision,CV)是使用机器来理解和分析图像的过程。近年来,基于深度学习(特别是卷积神经网络)计算机视觉技术的进步,机器理解图像的水平大大提高,视觉技术,如图像分类、定位和分割等技术也取得了显著进步。然而,为理解一张图像,只对其中的目标进行分类或定位是远远不够的,还需要对于图像中目标与目标之间关系进行识别,即视觉关系检测。
视觉关系检测是计算机视觉领域非常具有挑战性的任务,也是深度理解图像的基础。
1 主要研究内容及挑战
视觉关系检测的重点是目标识别与分类、目标之间关系的配对、以及关联目标的关系预测。但随着研究的深入,目标检测的准确性问题日益突出。
1.1 研究内容
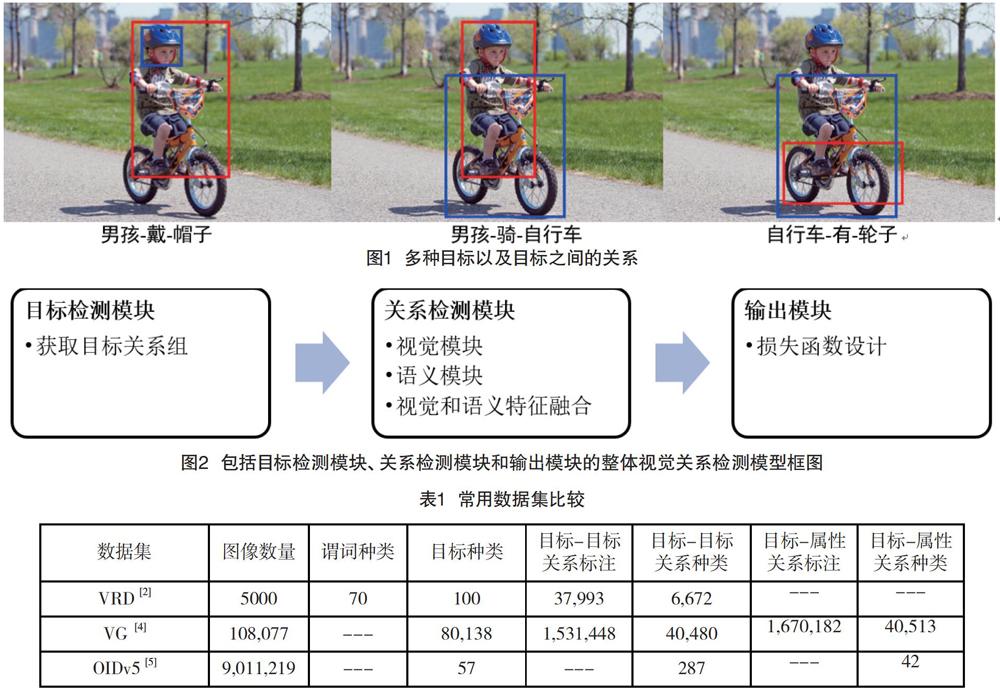
视觉关系检测与图像目标检测有差异。图像目标检测输出的是所检测目标在图像中的位置与目标的类别,通常不与其他检测目标关联;而视觉关系检测是在图像目标检测的基础上,预测物品之间的关联,关联关系通常以“主语-谓语-宾语”这样的三元组的形式来表达。并且图像通常包含多组三元组,例如在图1中男孩、自行车、帽子和轮子分别组成三组关系。
1.2 挑战
虽然近几年出现的一大批目标识别和目标检测算法大大提高了目标检测的精度和速度,视觉关系检测技术仍面临着诸多挑战:
在判定目标的类别与位置时,预测的些许偏差便可能会导致关系检测失误;
视觉关系理解的类别数远超目标检测任务中的目标类别数,这对视觉关系检测方法的迁移拓展能力提出了要求;
数据集的标注数据不完全,如在多目标图像中,只有小部分目标被标注,或只有部分目标之间的关系被标注,或被标注的目标对只与一个谓词关联[1];
同一个关系视觉外观差别很大,例如“人-开-门”与“人-开-箱子”,以及“人-骑-马”与“人-和……一起走-马”。
2 基准数据集
过去几年,出现了一些适用于大规模视觉关系检测的数据集,如:视觉关系检测数据集(VRD,Visual Relationships Detection dataset)[2],视觉基因组数据集(VG,Visual Genome dataset)[3-4],以及開放式图像数据集(OIDv5,Open Images Dataset v5)[5]。这些数据集是视觉关系检测技术取得重大进展的最重要因素之一。表1为这些数据集的比较。
为了能够具体分析各数据集的表现,会从以下三个角度计算评价指标:
谓词检测:输入为图片及图片中所含目标的位置,输出为预测目标之间有可能的关联。以这种方式验证数据集在不受目标检测性能限制的情况下预测视觉关系的难度。
短语检测:输入为图片,输出为“主语-谓语-宾语”的关系三元组及包含整个关系三元组的边界框,且预期得到的边界框与事实框的重合度高于0.5。
关系检测:输入为图片,输出为“主语-谓语-宾语”的三元组,并且主语和宾语的边界框与真实的标注框重合度高于0.5。
评价指标包括召回率(Recall@K)和平均精度(mAP)。通常人们选择采用Recall@50(R@50)及Recall@100(R@100)作为指标并对实验结果进行考量,R@K表示K个最自信的预测结果中正确结果所占的比例。同时,由于数据集标注的不完全的特性,一张图像中,并不是所有存在的关系都会被标注出来,mAP会惩罚那些被模型正确预测但数据并未标注出的关系。因此,在大多研究者的实验中mAP不作为评价指标使用。在2019年的OpenImage挑战赛中,就采用了对不同评价指标——如关系检测mAP、关系检测Recall@K和短语检测mAP——加权平均以进行视觉关系检测[6]。
这些数据集和评估指标是衡量和比较不同视觉关系检测方法性能的基础。更多更具挑战性和实用性的数据集不断出现,揭示了现实世界中的实际需求,并可在更真实的环境中激发对视觉关系检测的研究。
3 基于深度学习的方法
尽管在计算机视觉领域不断涌现出新的数据集和研究成果,视觉关系检测仍然是视觉领域中非常复杂的问题,为了应对本文第二部分提到的挑战,研究者设计了不同模型以进一步提升视觉关系检测的召回率Recall和平均准确率mAP。近年来所有工作都采用了基于深度神经网络的框架,图2展示了一个从多项研究工作中抽象出的视觉关系检测模型。
为实现视觉关系检测,首先要定位并识别出图像中的各类目标,通过目标检测模块(主要是卷积神经网络)提取包括整体图像特征、目标区域图像特征、目标位置信息特征、目标类别语义特征等作为关系检测模块的基础特征信息。关系检测模块使用这些特征作为输入,经过视觉和语义特征融合,输出预测的三元组标签以及位置。在输出模块通过有针对性的定义模型的损失函数,达到更优的训练效果。表2和表3给出了近几年使用深度神经网络框架完成视觉关系检测的方法在VRD和VG数据集上的性能表现(由于OIDv5数据集较新,暂无对比结果)。这些公开的视觉关系检测方法大都在关系检测模块上探索了不同的网络结构,小部分尝试对目标检测模块和输出模块的目标函数进行了设计。
3.1 目标检测模块
准确检测出图像中的目标,是正确识别 “主语-谓语-宾语”三元组关系的前提。大多数研究都采用FasterRCNN[19]作为检测模型。FasterRCNN引入了区域候选网络,检测速度更快,精度更高。 在参考文献12和17中分别尝试了采用VRD和FasterRCNN,实验结果表明,采用FasterRCNN的模型无论是在关系检测还是短语检测的召回率上均有大幅的提升。可见,提升目标检测模块的模型性能,是整体提升视觉关系检测效果最简单最直接的方法。
3.2 关系检测模块
关系检测模块是目标检测模块的下游,负责处理视觉和语义特征,也是整体模型的核心。
VRD[2]利用了R-CNN[20]目标检测模型的输出得到所有的目标候选框,然后经过视觉模型和语言模型分别得到每一对目标对的关系似然度。关系似然度相乘即得到每一个可能的三元组的关系似然得分,按照关系似然度的大小排序即可得到最可能的关系预测。视觉模型即利用一个卷积神经网络模型提取目标对的视觉特征,语言模型将目标对的两个目标类别名通过词嵌入的方法投影成为嵌入空间的一个k维向量。VRD验证了语言先验知识的有效,但由于VRD的视觉特征是单独训练的,与最终的关系检测任务无直接关系,且该模型对视觉及语言特征的融合方法较为简单,模型性能仍有提升空间。
与VRD不同,VTransE[12]是一种端到端的模型,其将目标的视觉特征映射到低维的关系空间中,然后使用转移向量来表示目标之间的关系。参考文献[10]提出了一种深度变化结构强化学习的方法,利用全局上下文线索,顺序发现图片中的目标关系。通过强化学习,提升了语义空间的搜索效率。CAI则使用主语和宾语的语言表示作为上下文信息引入模型[14]。
DR-Net[8]方法将更多的特征纳入模型:目标对区域的视觉特征、目标的空间结构特征(以一种双空间模板的方式将每个目标对的空间结构特征表示为一个64维的向量,而不是简单的几何度量(如候选框的大小、位置等))、统计关系特征(主语、宾语和谓词出现情况的统计概率)。
在视觉模块上提取目标之间的视觉联系的特征,能够让模型更好的理解目标间的关联,因此也是模型优化的方向,ViP-CNN模型考虑了主语、谓语、宾语在视觉特征上的联系,提出了一个名为PMPS的信息传递机制,通过不同模型在同一层间的信息传递,建模目标之间、目标与谓语关系之间的关联[9]。
Zoom-Net[16]中提出了SCM-A模块,将多个SCM-A模块堆叠组成视觉模块主体,对局部的目标特征和全局的谓语关系特征进行深层次的信息传递,实现对主语、谓语、关系视觉特征的深度融合。实验证明,该SCM-A模块能够移植到已有的方法并提升原方法的性能。此外,在语义模块中,构建目标和谓词类别的语义层次树,度量目标类别内部和谓词类别内部的关联性。
在视觉关系的语义空间非常大而训练数据量有限的情况下,提升语言先验能力是提高视觉关系检测模型整体效果的重要方法,特别是对只有极少训练数据的处于长尾分布末端的三元组关系,提升模型在语义空间的表现能力对模型泛化有帮助。在参考文献[15]中,作者除了从VRD或VG的训练数据的标注中建模语言模型外,还利用公开语料数据如维基百科语料数据,计算在给定“主语”和“宾语”的情形下,不同谓词出现的概率。在训练视觉模块时,上述语言模型以一种知识蒸馏的方法辅助训练,得到了更好的泛化性能。實验证明,可通过引入大量语料数据提升语言模型,并使用语言模型辅助视觉模块训练,如VRD零样本测试数据集上的召回率从8.45%提升到19.17%。类似的将语义特征以知识蒸馏的方式加入整体模型的思路也出现在参考文献[21]中。
通过引入语言先验,能提高关系检测准确率,并提升模型泛化能力、零样本学习能力,丰富可预测关系组的多样性。值得注意的是,虽然语言先验对于视觉关系的判定帮助很大,但同时可能会使得关系预测更倾向于频繁出现或语义上更可能的关系,而忽略了视觉方面的信息。因此在这些研究中,设计关系检测模块的结构时,兼顾了语义模块和视觉模块特征的平衡,通过特征传递、知识蒸馏等方式完成了语义和视觉特征等的融合。可以预见的是,在融合方法上会涌现更多的研究成果。
CDDN框架用语义图构建语义模块,用空间场景图构建视觉模块,并设计了一个图扩散网络作为语义和视觉融合的方法[18]。类似的,另一篇研究设计了一种损失函数,将视觉模块和语义模块二者提取的特征映射到共同的特征空间中[17]。
弱监督视觉关系检测也通过上述三大模块进行网络结构设计,但由于当前视觉关系检测方法强依赖于数据集和监督学习,在参考文献[11]和[13]中虽然提出了一些方法,但在效果上仍远差于监督学习的方法。
3.3 输出模块
无论是VRD还是VG数据集,谓词的种类都是有限的,并非对应现实生活中完全开放的词汇表。因此,一种比较简单但扩展性差的做法是设计一个神经网络分类模型,将目标检测模块得到的一对目标的特征(包括图像特征、检测框位置特征、类别名特征等)作为输入,输出为该对目标对应的谓词。由于谓词数量有限,关系检测模块只需作为一个输出谓词的分类器。分类器模型的关系检测模块,通常使用交叉熵损失函数来优化模型。
与关系检测模块中网络结构相对应,经过设计的损失函数能够得到更好的模型训练效果。针对一张图片上除了被标注的关系之外还有其他潜在三元组关系,以及一对目标对可能同时对应多种谓词关系的问题,参考文献[10]提出了一种结构排序损失方法,迫使被标注的关系比其余潜在的关系得分更高,其相比于使用交叉熵損失函数更加灵活和鲁棒。
参考文献[17]中修改了传统的三元组损失函数以更好的学习视觉和语义的交叉特征。三元组损失函数用于训练差异较小的样本,如在人脸识别中的应用[22]。传统的三元组函数可使相同标签的样本在嵌入空间中距离尽可能近,不同标签的样本在嵌入空间中距离尽可能远,修改后的损失函数具有更强标签样本嵌入能力。
4 应用与展望
目前,视觉关系检测技术已能运用于多种图像理解任务,如目标检测、图像检索[23]和描述、以及VQA(视觉问答)[24-25]等。未来,还将有更加广阔的应用前景。
在目标检测中,可以利用目标间的关系、所处场景来提高目标检测的准确率。参考文献[26]提出了一种新的结构推理网络,使用经典检测网络提取图片中目标的外观特征的同时,还利用图模型结构将图片中的目标作为图模型中的一个节点,目标之间的关系作为图模型的边,有效利用了图片中场景信息及目标间关系,在PASCAL VOC和MS COCO数据集中的目标检测任务准确率有所提升。参考文献[27]则提出了将关系建模为注意力转移,更好的利用目标间的关系来定位目标,不仅在 CLEVR、VRD 和 Visual Genome三个数据集上均优于现有方法,并且具有可解释性。
根据相关的图像输入或自然语言描述输入,图像检索会在图像库中检索出符合条件的图像,图像描述则会对输入图像进行自然语言的描述。这两项应用都要求能够提取出图像目标并描述目标间的相互关系。
在VQA应用中,所有的问答题目首先都依赖于目标之间关系的存在,如果目标之间没有关联,那问题也不会出现,例如:“树下的人穿着什么颜色的衣服?”这个问题中出现的目标有四个:树,人,衣服和颜色。只有清楚的了解图像中目标间的相互关系,读懂题目并找到所提问的对象,才可能根据图像正确地回答问题。
未来,还可在以下方向进一步拓宽视觉关系检测的应用研究:扩大识别关系集合,提高关系检测准确度、召回率和零样本学习能力;多目标关系建模(比如男孩-爬-树-摘-苹果);多场景应用(如图像及视频内容检测、搜索、视觉问答)。
参考文献
[1] Liang, Kongming, et al. "Visual relationship detection with deep structural ranking." Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[2] Lu, Cewu, et al. "Visual relationship detection with language priors." European Conference on Computer Vision. Springer, Cham, 2016.
[3] Krishna, Ranjay, et al. "Visual genome: Connecting language and vision using crowdsourced dense image annotations." International Journal of Computer Vision,2017(1): 32-73.
[4] VisualGenome, visualgenome.org/data_analysis/statistics.
[5] Open Images Dataset Stats V5. Accessed July 29, 2019. https://storage.googleapis.com/openimages/web/factsfigures.html.
[6] Open Images Evaluation Protocols, storage.googleapis.com/openimages/web/evaluation.html#visual_relationships_eval.
[7] Plummer, Bryan A., et al. "Phrase localization and visual relationship detection with comprehensive image-language cues[J]. Proceedings of the IEEE International Conference on Computer Vision,2017.
[8] Dai, Bo, Yuqi Zhang, and Dahua Lin. Detecting visual relationships with deep relational networks[J]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017.
[9] Li, Yikang, et al. Vip-cnn: Visual phrase guided convolutional neural network[J]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
[10]Liang, Xiaodan, Lisa Lee, and Eric P. Xing. Deep variation-structured reinforcement learning for visual relationship and attribute detection[J]. Proceedings of the IEEE conference on computer vision and pattern recognition,2017.
[11]Zhang, Hanwang, et al. PPR-FCN: weakly supervised visual relation detection via parallel pairwise R-FCN[J]. Proceedings of the IEEE International Conference on Computer Vision,2017.
[12]Zhang, Hanwang, et al. Visual translation embedding network for visual relation detection[J]. Proceedings of the IEEE conference on computer vision and pattern recognition,2017.
[13]Peyre, Julia, et al. Weakly-supervised learning of visual relations[J]. Proceedings of the IEEE International Conference on Computer Vision. 2017.
[14]Zhuang, Bohan, et al. Towards context-aware interaction recognition for visual relationship detection[J]. Proceedings of the IEEE International Conference on Computer Vision,2017.
[15]Yu, Ruichi, et al. Visual relationship detection with internal and external linguistic knowledge distillation[J]. Proceedings of the IEEE International Conference on Computer Vision,2017.
[16]Yin, Guojun, et al. Zoom-net: Mining deep feature interactions for visual relationship recognition[J]. Proceedings of the European Conference on Computer Vision (ECCV),2018.
[17]Zhang, Ji, et al. Large-scale visual relationship understanding[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019(33):13.
[18]Cui, Zhen, et al. Context-dependent diffusion network for visual relationship detection[J]. 2018 ACM Multimedia Conference on Multimedia Conference. ACM, 2018.
[19]S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks[J].In NIPS,2015:91-99.
[20]Girshick, Ross, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[J]. Proceedings of the IEEE conference on computer vision and pattern recognition,2014.
[21]Plesse, Fran?ois, et al. Visual relationship detection based on guided proposals and semantic knowledge distillation[J]. 2018 IEEE International Conference on Multimedia and Expo (ICME)[J].IEEE, 2018.
[22]Schroff, Florian, Dmitry Kalenichenko, and James Philbin. "Facenet: A unified embedding for face recognition and clustering.[J].Proceedings of the IEEE conference on computer vision and pattern recognition, 2015.
[23]N. Prabhu and R. Venkatesh Babu. Attribute-graph: A graph based approach to image ranking[J]. In ICCV, 2015:1071-1079.
[24]Kulkarni, Girish, et al. Babytalk: Understanding and generating simple image descriptions[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(12):2891-2903.
[25]Xu, Kelvin, et al. Show, attend and tell: Neural image caption generation with visual attention[J]. International conference on machine learning,2015.
[26]Liu, Yong, et al. Structure inference net: Object detection using scene-level context and instance-level relationships[J].Proceedings of the IEEE conference on computer vision and pattern recognition,2018.
[27]Krishna, Ranjay, et al. Referring relationships[J]. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018.
