CPU与GPU的计算性能对比
2019-01-30韩菲李炜
文/韩菲 李炜
1 引言
随着大数据时代的到来,数据量和数据种类急剧增加,计算难度越来越大,串行计算已经难以满足超大规模复杂问题的计算需求,GPU以其全新的架构优势突破摩尔定律的束缚为计算力注入新的力量。
如图1所示,CPU在设计之初主要精力集中在控制和缓存等非计算功能,着力于低延迟,快速响应完成某个操作,优化串行计算;GPU则适合计算密集、高度并行化、高计算强度(计算/访存比)的并行计算任务主要致力于设计大量的ALU(Arithmetic Logical Unit)计算单元,使计算能力大幅度增强。
2 GPU的并行计算
2.1 GPU的硬件设计
GPU由若干个流多处理器(Streaming Multiprocessor,简称SM)组成,如图2所示,1个SM由8个标量流处理器(Stream Processor,简 称SP)、1个 指 令 单 元、1个32位的寄存器、共享存储器(Shared Memory)、常量存储器(Constant Cache)、纹理存储器(Texture Cache)等硬件组成。

图1:CPU与GPU架构的比较
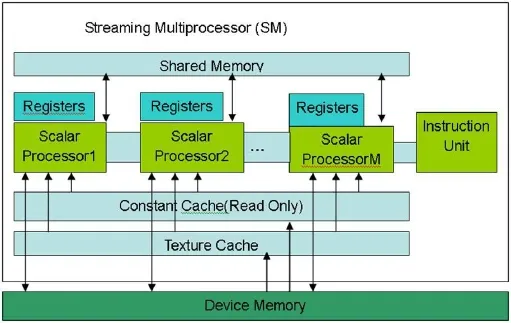
图2:SM的硬件结构
GPU的“核心”通常指的是SP的数量。而真正GPU的核心需要包含取指、解码、分发逻辑和执行单元。因此,SM被称为“GPU的核心”更加合适,SP仅仅是执行单元,不是完整的处理核心。CUDA模型中Thread对应SP,Block中的1个Thread被发射到1个SP上,8个SP组成1个SM,共用1个SM中的共享存储器,共享1个SM中的一套取指与发射单元,因此1个Block中的线程可以共享数据;1个Block必须对应1个SM,但为了隐藏延迟提高执行单元的资源利用率,1个SM可以同时有多个活跃线程块(active Block)等待执行。在SM中,线程的创建、调度和执行等操作均由硬件完成,没有时间开销,一旦1个Block执行高延迟操作,则另1个Block马上占用SM资源执行程序。
2.2 CUDA简介
NVIDIA提出了支持在GPU上做通用计算的统一计算设备架构CUDA(Compute Unif ied Device Architecture),编程人员可以利用CUDA编程模型使用扩展的C语言在开发环境下编写程序,使GPU程序轻松地运行在GPU上,大大降低了利用GPU进行通用计算的难度,降低编程门槛,省去程序员学习GPU复杂结构和底层复杂运行模式的难度,提高程序的性能,减轻早期GPU计算中存在的一些限制。
2.3 CUDA线程组织结构
CUDA程序分为主机代码和设备代码两部分。主机是CPU,主机代码一般为串行代码在CPU上执行;设备是GPU,设备代码是在GPU上并行执行的代码,被称为内核函数。该函数并发成千上万个线程,并行执行程序,1个内核函数(Kernel)对应1个线程网格(Grid),1个线程网格最多由65535个线程块(Block)组成,1个线程块最多由512个线程(Thread)组成,则512*65535=33553920是1个线程网格可以拥有的最多线程数,足够大多数程序使用。
在内核函数定义中,要建立对Block和Thread的索引,对任务进行划分。同时还建立了四个内置变量:gridDim、BlockDim、BlockIdx、ThreadIdx,对应关系如下:
3 CPU与GPU计算旅行时

表1:CPU与GPU运行时间对比
3.1 CPU串行计算旅行时
GPU最广泛的应用领域之一就是地震勘探。地震波传播时遇到断棱或不整合面上的突变点后将变为新震源,发出球面波向四周传播形成的波被称为绕射波。为计算旅行时,设采样点5000个,采样间隔0.002s,CDP 200个,道头文件包含炮点横纵坐标Sx、Sy,检波点横纵坐标Rx,Ry四个信息,坐标文件包含地下反射点横纵坐标coorx、coory两个信息。对每个CDP的每个时间点进行计算,nt0代表采样点,ncdp代表cdp数,算法步骤如下:
S1:0=>i
S2:读入反射点坐标,炮点检波点坐标
S3:反射点地面横坐标-炮点横坐标=>炮点反射点地面横向距离
S4:反射点地面纵坐标-炮点纵坐标=>炮点反射点地面纵向距离
S5:炮点反射点横向距离平方+炮点反射点纵向距离平方=>炮点反射点地面距离的平方
S6:反射点地面横坐标-检波点横坐标=>检波点反射点地面横向距离
S7:反射点地面纵坐标-检波点纵坐标=>检波点反射点地面纵向距离
S8:检波点反射点横向距离平方+检波点反射点纵向距离平方=>检波点反射点地面距离的平方
S9:0=>j
S10:i*nt0+j=>当前cdp的时间采样点
S11:对当前点获取速度
S12:求取当前速度的倒数
S13:求取倒数的平方
S14:求取炮点旅行时
S15:求取检波点旅行时
S16:炮点旅行时+检波点旅行时=>总旅行时
S17:j+1=>j
S18:如果j<5000,返回S9,否则执行S19
S19:i+1=>i
S20:如果i<200,返回S2,否则算法结束

图3:GPU计算反射点旅行时流程
CPU计算旅行时花费的时间:344.60000s
3.2 GPU并行计算旅行时
通过对CUDA的并行机制的分析,作出以下分块策略。根据计算旅行时的实际数据需求,时间采样点nt0=5000个,cdp数200个,因此首先将5000个t(x,y)的计算与1个Block对应,设200个Block,1个Block(x,y)计算1个t(x,y),并行计算直到200*5000个t(x,y)计算完毕,之后将计算结果传回CPU,通过循环输出1000000个点的旅行时。
每一个线程处理一个炮点旅行时ts和检波点旅行时tg的计算,得到一个总旅行时t值,当计算点增大时,不会受到线程数量限制的影响。具体计算流程如图3。
GPU计算旅行时花费的时间:25.30000s
计算旅行时的GPU算法理论带宽:
Theoretical Bandwidth=效地对算法进行加速,在累加和算法中采用最优化方法时GPU是CPU的14倍左右。
(2)结合GPU的硬件特点对大数据量的并行计算是非常有效的。当计算的数据量较小时,GPU算法中,启动的线程计算量不满载,大部分时间花在了系统调度开销上,GPU并行计算的优势没有展现,时间与CPU计算时间差别不明显;随着计算的数据量增大,每个线程的计算渐渐满载,时间花在系统调度的比例降低,GPU并行程度提高,加速比上升。=143.36GB/s (Tesla C2075内存时钟为1120MHz,内存接口宽度为512 bit)。
实际带宽距离理论带宽还有一定差距,算法中还存在一定的瓶颈。
除此之外,本论文还计算了采样点=500个,CDP=20个的反射点旅行时,CPU与GPU运行效率对比如表1。
4 结论
(1)CPU的串行计算是通过多次循环逐一计算各点旅行时,因此时间为所有循环结束后的总时间,而GPU的并行计算时间为计算一点旅行时的时间加上主机与设备间互相传递参数的时间。当计算量小时,CPU与GPU的计算时间差别不大,但随着计算量的逐渐加大,GPU的并行计算逐渐体现其优势,它可以有
